
Redis之集群模式
1. Redis 集群模式的演变
大规模数据存储系统都会面临的一个问题就是如何横向拓展。当你的数据集越来越大,一主多从的模式已经无法支撑这么大量的数据存储,于是你首先考虑将多个主从模式结合在一起对外提供服务,但是这里有两个问题就是:
- 如何实现数据分片的逻辑?
- 在哪里实现这部分逻辑?
业界常见的解决方案有三种:
- 一是引入 Proxy 层来向应用端屏蔽身后的集群分布,此时服务端由多个主从模式的集群构成,各个主从模式的集群之间互相无感知, Proxy 层来进行请求转发和 Key 值的散列从而进行数据分片(一致性hash),客户端对分片逻辑无感知。这种方案会损失部分性能但是迁移升级等运维操作都很方便,业界 Proxy 方案的代表有 Twitter 的 Twemproxy 和豌豆荚的 Codis;
- 二是客户端分片,即将分片的逻辑放在客户端做,此时服务端仍然相当于多个主从模式的集群,各个主从模式的集群之间互相无感知,客户端根据维护的映射规则和路由表直接访问特定的 Redis 实例,但是增减 Redis 实例都需要客户端重新调整分片逻辑。
- 三是类似于Redis Cluster采用的服务端分片,此时服务端还是由多个主从模式的集群构成,但各个主从模式的集群之间互相是有感知的,客户端可以对分片逻辑无感知(但这样效率不高,会收到MOVED错误),客户端也可以感知分片逻辑。
1.1 Redis Cluster 简介
Redis 3.0 版本开始官方正式支持集群模式,Redis 集群模式采取了去中心化的集群模式,集群通过分片进行数据共享,分片内采用一主多从的形式进行副本复制,并提供复制和故障恢复功能。在官方文档 Redis Cluster Specification 中,作者详细介绍了官方集群模式的设计考量,主要有如下几点:
| 性能 | Redis 集群模式采用去中心化的设计,即 P2P 而非之前业界衍生出的 Proxy 方式 |
|---|---|
| 一致性 | master 与 slave 之间采用异步复制,存在数据不一致的时间窗口,保证高性能的同时牺牲了部分一致性 |
| 水平扩展 | 文中称可以线性扩展至 1000 个节点 |
| 可用性 | 自动故障检测和自动故障转移,自动进行master选举和 failover |
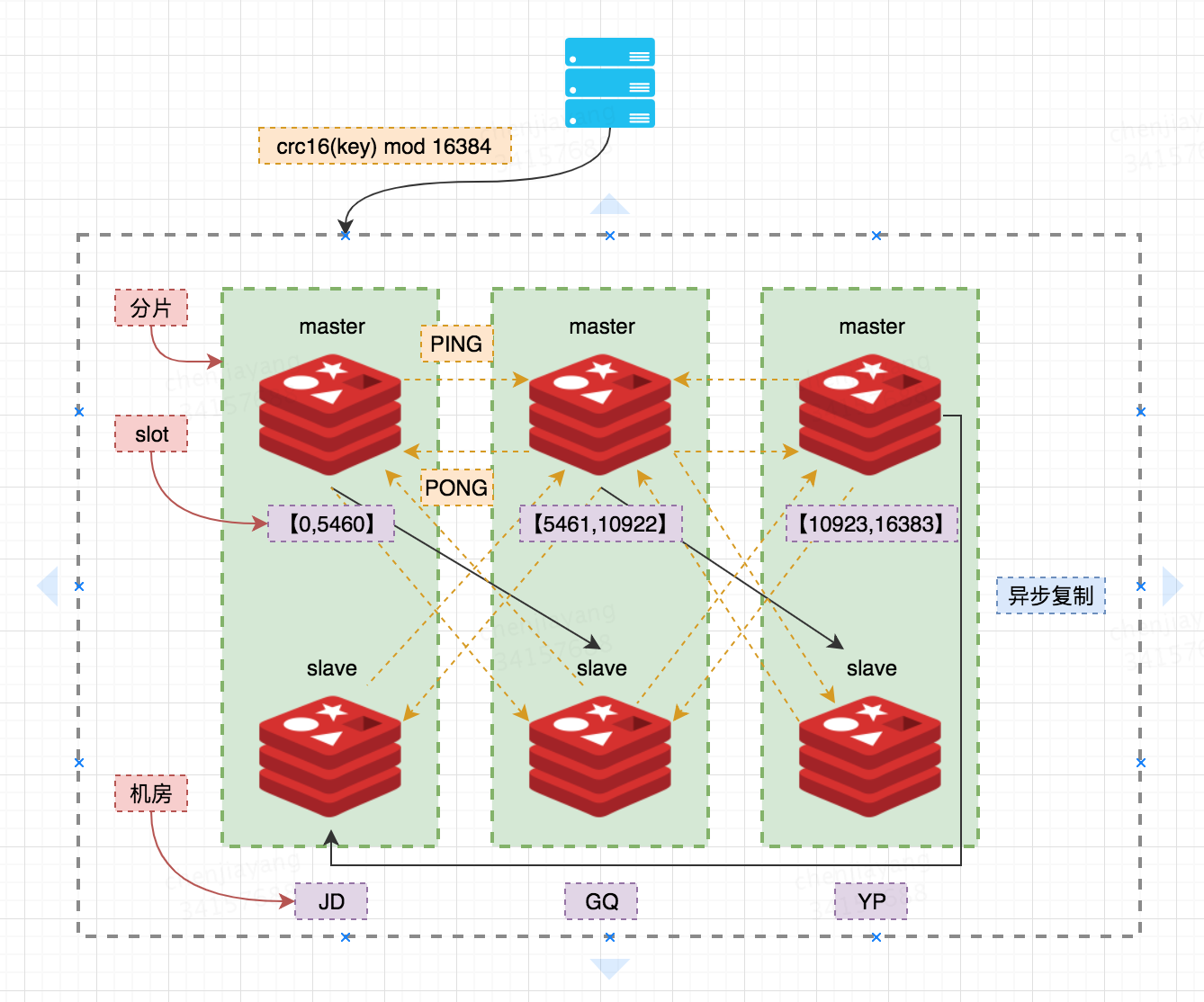
下图是一个三主三从的 Redis Cluster,三机房部署(每个一主一从构成一个分片,之间通过异步复制同步数据,一旦某个master掉线,则分片上的 slave 会被自动提升为 master 从而可以继续提供服务) ;每个 master 负责一部分 slot,数目尽量均摊;客户端对于某个Key的操作先通过CRC16 mod 16384 计算出所映射到的 slot,然后直连某个分片,写请求一律走 master,读请求可以走slave。
1.2 三种集群方案的优缺点
| 集群模式 | 优点 | 缺点 |
|---|---|---|
| 客户端分片 | 没有中间层,少了分发环节,性能更好,分发压力与分片逻辑在客户端,服务端无压力增加 | 1、一般client实例数目较多,当集群状态改变时(某个节点挂了或者新增节点时),这么多client难以在短时间内完成集群状态更新,client容易存在集群状态信息不一致; 2、由于服务端各个节点间互相无感知,当扩容缩容导致key迁移时,如果client的集群状态信息更新不及时(client不知道正在扩缩容),导致请求打到错误的节点上,不会得到任何提示(Redis 集群模式有MOVED和ASK提示),难以做到平滑的扩缩容 |
| 代理层分片 | 运维成本低。客户端不用感知分片逻辑,跟操作单点 Redis 实例一样。 | 1、代理层多了一次转发,性能有所损耗 2、与客户端分片方案一样,由于服务端各个节点间互相无感知,当扩容缩容导致key迁移时,如果client的集群状态信息更新不及时(client不知道正在扩缩容),导致请求打到错误的节点上,不会得到任何提示(Redis 集群模式有MOVED和ASK提示),难以做到平滑的扩缩容 |
| 服务端分片(Redis Cluster) | 无中心节点,数据按照 slot 存储分布在多个 Redis 实例上,平滑的进行扩容/缩容节点,自动故障检测与故障转移(节点之间通过 Gossip 协议交换状态信息,进行投票机制完成 slave 到 master 角色的提升)降低运维成本,提高了系统的可扩展性和高可用性 | 开源版本缺乏监控管理,原生客户端太过简陋,failover 节点的检测过慢,维护 Membership 的 Gossip 消息协议开销大,无法根据统计区分冷热数据 |
2. Redis的虚拟槽分片方案
2.1、数据分片方案介绍
数据分片一般有三种方式:
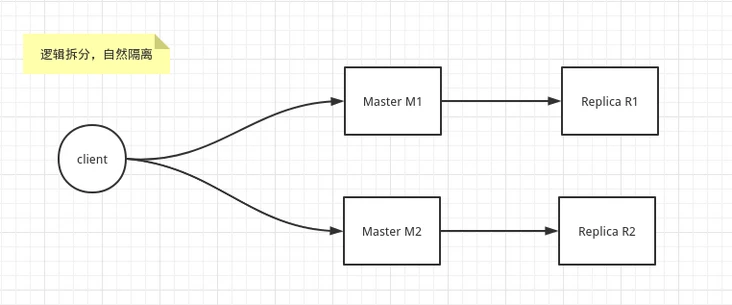
2.1.1、逻辑拆分
逻辑上能拆分,比如 Redis 中的 M1 节点 存储 A服务需要的业务数据,而 Redis 中的 M2 节点存储 B服务需要的业务数据。
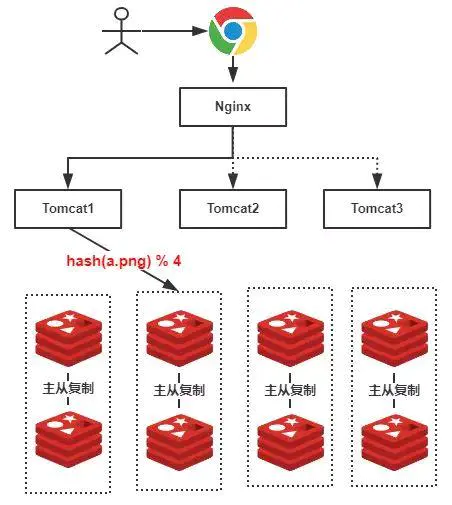
2.1.2、哈希分区
当逻辑上不能拆分,那么只能用数据本身来拆分,需要保证客户端读和写的数据位置一致。
因此需要一个高效快速的数据结构来路由对应的Master节点。
最容易想到的就是类比 Java 中的 HashMap, 采用 哈希算法分区,快速找到,快速设置。
哈希分区又分为以下三种方案:
hash取模分区
给定key,根据节点数量N,使用公式:hash(key) % N 计算出一个0 ~(N-1)值,用来决定key映射到哪个节点上。即哈希值对节点总数取余。余数x,表示这条数据存放在第x个节点上。
这种方案常用于数据库的分库分表规则,根据数据量规划好分区数,保证可支撑未来一段时间的数据量,分区数不轻易改变。
但这种方案的问题是,当服务器数量变动的时候,需要对集群所有的key重新计算hash值,计算量大,且大部分缓存的位置都要发生改变!

按名字取模后分布如下:

现在需要扩容一台redis4、第五个节点,扩容后的数据分布如下(其中蓝色的节点表示扩容后不需要迁移的数据)

可以看到,不需要迁移的数据只占20%,80%的数据需要迁移。
一致性哈希
优点:一致性hash可以极大降低扩缩容需要迁移的数据量,并且在扩缩容时只会影响一个节点。增加节点时,只会影响顺时针的节点,删除节点时,只会影响逆时针的节点,而不是影响全部的节点。
缺点:增加节点时,需要重新计算受影响的节点中的key的hash值,找出需要迁移的key,删除节点不会有这个问题。Redis Cluster的虚拟槽分区不会有这个问题
当节点数量较少时,可能造成数据分布不均衡,可以通过增加虚拟节点解决。
参考:https://www.cnblogs.com/lpfuture/p/5796398.html
https://www.jianshu.com/p/ae4139bdbbc4
虚拟槽分区(Redis Cluster)
虚拟槽分区使用哈希函数(slot = CRC16(key) mod 16384)把所有数据映射到一个固定范围的整数集合中,整数定义为槽(slot)。这个整数集合范围一般远远大于节点数,比如 Redis Cluster 槽范围是0~16383(为什么是16384个?)。槽是集群内数据管理和迁移的基本单位,采用大范围槽的主要目的是为了方便数据拆分和集群扩展。
可以将槽看作一致性哈希中的虚拟节点,槽是介于数据和实际节点之间的虚拟概念。引入槽以后,数据的映射关系由数据hash->实际节点,变成了数据hash->槽->实际节点。槽解耦了数据和实际节点之间的关系。数据先映射到槽,节点只需维护与槽位的映射关系。在扩缩容的情况下,需要迁移的key的数量与一致性hash算法类似,比如集群原来4个节点(每个节点负责16384/4 = 4096个槽),需要增加一个节点(每个节点负责16384/5 = 3277个槽),新增一个节点需要迁移的槽位是3277个,假设每个槽位内的key的数量相等,也就是整个key空间的20%需要迁移。但由于虚拟槽分区并没有规定哪些槽位应该指派给哪些机器,系统管理员可以设计自己的槽位分配方案,槽位分配的灵活性导致key的分配相比一致性hash更加灵活。
一致性hash算法可以看成是有2^32 (32位hash值)个槽位的,槽位分配方法固定的虚拟槽分区方案
| hash分区方案 | 优点 | 缺点 |
|---|---|---|
| hash取模分区 | 实现简单,一次hash计算即可确定数据位置 | 1、扩缩容需要迁移的key的数量较多;2、扩缩容需要对所有key重新计算hash,计算量大 |
| 一致性hash | 扩缩容需要迁移的key的数量较少,新增或减少一台机器,需要迁移的key数量一般为 key总数/机器节点数 | 1、当机器节点和hash算法确定后,每台机器负责的key区间就确定了,不能根据key的大小和流量动态将某些key分配/迁移给某些机器节点,解决大key,热key问题; 2、扩容需要对受影响的那一台机器的所有key重新计算hash值以确定是否需要迁移 3、扩缩容时,需要迁移的key的空间和迁入迁出节点是固定 4、一致性hash一般用于客户端分片或proxy分片,也具有客户端分片或proxy分片的扩缩容信息更新不及时导致请求失效的缺点 |
| 虚拟槽分区 | 1、扩缩容需要迁移的key的数量较少,与一致性hash类似 2、槽位分配的灵活性使得key的分配和迁移具有灵活性 | 槽位的分配信息是一种配置,这种配置相比一致性hash更大且需要在各个节点之间同步,各个节点之间需要同步或交换的数据量更大 |
2.1.3、顺序分区
顺序分布就是把一整块数据分散到很多机器中,如下图所示。
正常顺序分区是按照平均分配的规则,当然也可以根据不同机器分配,内存大一点的可以多分配一些。
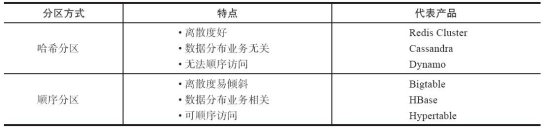
哈希分区和顺序分区只是场景上的适用。哈希分区不能顺序访问(类似数组,逻辑相邻的元素存储地址也相邻),比如你想访问1~100,哈希分区只能对遍历到的每个key计算出其hash值才知道其存储位置,同时哈希分区因为做了hash后导致与业务数据无关了。
2.2 槽位指派
2.2.1 槽位指派命令
集群刚上线时,集群状态是FAIL,需要手动为16384个slot指派绑定的节点,槽位指派信息会被保存到配置文件中,集群下次重启会读取Redis自动保存的配置文件,不再需要指派。使用客户端登陆到某台机器,执行CLUSTER ADDSLOTS <slot> [slot ...] 将指定的槽位绑定到当前节点(myself)
127.0.0.1:7001> CLUSTER ADDSLOTS 0 1 2 3 4 ... 10000
OK
127.0.0.1:7001> CLUSTER NODES
70dfc72c9044301b2c8294971810e891e8761738 127.0.0.1:7002@17002 master - 0 1644820143508 1 connected 10001-16383
e293eda907d480c74ccb392dbee71612f44f2e6c 127.0.0.1:7001@17001 myself,master - 0 0 0 connected 0-10000
CLUSTER ADDSLOTS 命令只能将没有master负责的槽位绑定到当前机器,不能从其他master抢占slot,因为没有增加 configEpoch。如果一个slot无人认领,当一个master声称自己负责这个slot时,当前节点会认为这个slot由这个master负责,不用比较configEpoch。
CLUSTER DELSLOTS 只是删除当前节点(myself)上的槽位配置信息,让原本负责这个槽位的节点不再负责这个槽位,这个命令一般不推荐使用。当一个节点不再负责某个slot时,应该通过槽位迁移命令让其他节点负责这个slot,否则集群状态将是FAIL,另外DELSLOTS命令没有增大configEpoch,当通过DELSLOTS命令把某个槽位删除后,虽然这个节点广播出去的包中显示没有节点负责这个槽位,但其他节点还是会认为这个节点仍然在负责这个槽位。见clusterUpdateSlotsConfigWith和clusterProcessPacket
2.2.3 槽位指派实现
Redis 集群中每个节点都会维护集群中所有节点的 clusterNode 结构体,其中的 slots 属性是个二进制位数组,长度为 2048 bytes,共包含 16384 个 bit 位,节点可以根据某个 bit 的 0/1 值判断对应的 slot 是否由当前节点处理。每个节点通过 clusterStats 结构体来保存从自身视角看去的集群状态,其中 nodes 属性是一个保存节点名称和 clusterNode 指针的字典,而 slots 数组是一个记录哪个 slot 属于哪个 clusterNode 结构体的数组。
typedef struct clusterNode {
// 节点当前的配置纪元,用于实现槽位抢占和故障转移
// 集群模式启动时,会有退避算法保证每个节点的configEpoch不一样
uint64_t configEpoch; /* Last configEpoch observed for this node */
// 这里的slots与clusterState中的slots有所不同,这里以bit的索引作为slot值,以该bit的状态标识该clusterNode对应的节点是否负责该slot。总共需要CLUSTER_SLOTS个bit
unsigned char slots[CLUSTER_SLOTS/8]; /* slots handled by this node */
sds slots_info; /* Slots info represented by string. */
int numslots; /* Number of slots handled by this node, master的numslots才可能大于0*/
int numslaves; /* Number of slave nodes, if this is a master */
// 当前节点(myself)与clusterNode所代表的节点之间的outgoing连接
// 对于集群中的其他节点,当前节点上会有两个ClusterLink,一个是incoming的,这个 ClusterLink -> node一直是NULL
// 另一个是outgoing的,是自己主动建立的,这个 ClusterLink -> node不是NULL,且ClusterNode->link总是指向outgoing的
clusterLink *link; /* TCP/IP link with this node */
// 集群中认为这个结点可能发生故障的结点列表
list *fail_reports; /* List of nodes signaling this as failing */
} clusterNode;
typedef struct clusterState {
clusterNode *myself; /* This node */
// the greatest configuration epoch currently detected among nodes
uint64_t currentEpoch; // 集群当前的配置纪元,用于实现故障转移 currentEpoch 是所有节点中configEpoch的最大值
// 当数据库中的16384个槽都有节点在处理时,集群处于上线状态(ok);相反地,如果数 据库中有任何一个槽没有得到处理,那么集群处于下线状态(fail)。
int state; /* CLUSTER_OK, CLUSTER_FAIL, ... */
int size; /* Num of master nodes with at least one slot */
// 每个节点都有一个定时任务clusterCron,其中会遍历nodes字典,检测其中的clusterNode的link是否建立,
// 如果没有建立连接,那么会主动连接该clusterNode所代表的节点建立连接。如果nodes字典中没有某个节点clusterNode结构,那么便不会与它建立连接。
dict *nodes; /* Hash table of name -> clusterNode structures 自己、slave结点也会在这个dict中 */
dict *nodes_black_list; /* Nodes we don't re-add for a few seconds. */
// 说明当前节点是迁出节点:这个slot之前由我负责,但我正在把这个slot迁移给其他节点负责,此时还没迁移完
// 对于一个节点,如果migrating_slots_to[slot] 不为NULL(对于一个slot,集群只能有一个节点的 migrating_slots_to 不为NULL),cluster->slots[slot] 则必须是myself
clusterNode *migrating_slots_to[CLUSTER_SLOTS];
// 当前节点是迁入节点:这个slot之前不是由我负责,但我以后要负责这个slot,当前正在迁移,此时还没迁移完
// 对于一个节点,如果importing_slots_from[slot] 不为NULL,cluster->slots[slot] 一定不是myself
clusterNode *importing_slots_from[CLUSTER_SLOTS];
// slots[slot]存储着负责该slot的master节点的clusterNode结构的指针。每一个节点上都拥有该slots数组,因此在任意节点上都可以查找到负责某个slot的主节点的信息。
// slots相当于分区表,在Redis中,当分区表发生变化时(某个slot被指派给其他node负责),client是不能实时知道
// 分区表的变化的,只有当发起请求收到MOVED错误后才会被动知道,可以采用的zookeeper来存储分区表,分区表变化时可以及时通知client。
clusterNode *slots[CLUSTER_SLOTS]; // CLUSTER_SLOTS:16384
uint64_t slots_keys_count[CLUSTER_SLOTS];
/* The slots -> keys map is a radix tree. */
rax *slots_to_keys;
} clusterState;
2.3 槽位迁移
迁移槽位命令的执行顺序:
1、先去迁入节点使用 CLUSTER SETSLOT <slot> IMPORTING <source-node-id>
- IMPORTING 会检查 server.cluster->slots[slot] 一定不是myself,然后设置 server.cluster->importing_slots_from[slot] 为迁出节点的ClusterNode
- 这条命令可以不用在slave上执行,原因是主从同步中,master发过来的命令slave都会执行,不会经过getNodeByQuery函数判断;又因为迁出节点及其slave的ASK响应是将请求导到迁入节点,而不会将请求导到迁入节点的slave上,所以迁入节点的slave一般来说不会收到带有ASK标志的请求,所以迁入节点的slave的importing_slots_from可以为NULL,迁入节点的slave可以不用知道槽位正在迁移。但是,也可以设置迁入节点的slave的importing_slots_from[slot],这样当client收到ASK响应后可以不用总是请求迁入节点,而请求迁入节点的slave,降低迁入节点的读负载。
2、去迁出节点(及其slave) 使用 CLUSTER SETSLOT <slot> MIGRATING <destination-node-id>
- MIGRATING 会检查 server.cluster->slots[slot] 必须是myself,然后设置 server.cluster->importing_slots_from[slot]为 迁入节点的ClusterNode
- 因为gossip消息格式中没有slot迁移的信息,所以除了迁入迁出节点,它们的slave和其他节点都不知道这个槽在迁移。这条命令需要在slave上执行的原因是:迁出节点执行migrate命令后,slave会收到DEL命令从而删除这个key,所以需要主动去slave设置 migrating,让slave在没找到这个key时也能回复ASK给client,让client到迁入节点去再查询一次。
- 但是目前Redis6.2的代码中,CLUSTER SETSLOT MIGRATING 命令并不能在slave上执行,由于迁出节点的slave无法感知到槽位迁移,如果client请求一个已被迁移的key,迁出节点的slave会回复null而不会回复ASK,槽位迁移时会出现严重的数据失效问题,所以这里需要优化,让这条命令能够在slave上执行,让slave的表现和master类似。
3、去迁出节点上多次使用GETKEYSINSLOT 和 MIGRATE 命令迁移
- 先使用 CLUSTER GETKEYSINSLOT <slot> <count> 获取这个slot指定数量的key,Redis内部用Trie树存储slot -> key 的关系,Trie树中元素的前两个字节(16384个slot,用16位够了)存储slot,后面存储可变长度的key。Trie树上有下面的操作:slotToKeyAdd(入参key,算出key的两字节slot,拼在key前面作为新key,将新key插入Trie树), slotToKeyDel(入参key,算出key的两字节slot,拼在key前面作为新key,从Trie树删除新key),getKeysInSlot(入参slot和count,从Trie树中找到slot的起始位置,遍历count个key返回),delKeysInSlot(入参slot,从Trie树中找到slot的起始位置,依次遍历取出所有key,调用dbDelete(key)删除这个key)。
- 使用 MIGRATE host port "" destination-db timeout KEYS key [key ...] 将批量的key原子地迁移到目标节点的0号db(集群模式下,节点只能使用0号数据库),MIGRATE命令比较耗时,会先主动和目标节点建立TCP连接(如果有缓存的连接会使用缓存的),然后在for循环中向目标节点发送 RESTORE-ASKING key TTL value命令(添加ASKING标志,否则接收方不会执行不属于自己slot的命令),每个key都发送一条RESTORE-ASKING命令(key、value是RDB格式的序列化数据,如果key的size太大,这条命令也会很大,会很耗时),同时迁入节点的slave也会收到RESTORE-ASKING命令并执行,所有命令发送完在for循环中同步等待读取response,每收到一个key的正确回复,说明这个key已经在接收方的数据库中,从本地数据库删除这个key,将MIGRATE命令替换成DEL命令写入AOF文件和slave。migrate命令使用的是同步send和recv,且整个migrate命令执行完才能在发送方退出,保证了接收方数据库有这个key的信息后,发送方才会删除这个key,且发送方从构造 RESTORE 命令到删除key的过程中,key的值没有变化,保证原子性。如果MIGRATE失败(比如超时),这个key一定存在于发送方,需要管理员主动检查这个key是否存在于接收方中,值是否相同,这里需要人工干预。
- redis 大部分地方是异步IO,只有sync 和 migrate 使用的是同步IO,migrate命令是阻塞指令,迁入节点和迁出节点处理migrate命令时不会处理其他请求,如果一个key很大,比如zset或者dict的size很大,那这条命令执行时间会很久,容易导致迁入节点,特别是迁出节点出现服务卡顿。
4、去迁入节点使用 CLUSTER SETSLOT <slot> NODE <node-id>命令
- 这条命令会清空server.cluster->importing_slots_from[slot],设置server.cluster->slots[slot] = myself,增大currentEpoch(currentEpoch是所有节点中configEpoch的最大值)并让myself->configEpoch = currentEpoch,立即在outgoing link上向所有节点广播PONG(这里不发送PING包的原因是,对于PING和MEET消息,其他节点都需要回复PONG),让自己发出去的消息有更高优先级,去抢占这个slot。集群中其他节点(包括迁出节点及其slave、迁入节点的slave)收到这个PONG包后在clusterUpdateSlotsConfigWith中会将自己的server.cluster->slots[slot] 设为迁入节点,如果迁出节点(及其slave)发现自己负责的所有槽位都转移给了迁入节点,会成为迁入节点的slave。槽位所属关系修改后,迁出节点(及其slave)收到关于这个slot的请求将不再回复ASK而是MOVED,但迁出节点(及其slave)的 server.cluster->migrating_slots_to[slot] 还是指向迁入节点,需要在第5步手动清空。
- 在clusterUpdateSlotsConfigWith中,迁入节点的slave收到迁入节点的PONG包后会让迁入节点抢占slot,但slave并不会像其master那样增大并广播confitEpoch。因为只有master才能抢占槽位,槽位只能归属于master
- 为了减少槽位迁移结束时集群中UPDATE包的数量,迁移结束后,迁入节点最好先向迁出节点发送PONG包(让迁出节点后续发出去的包中不再有迁出节点负责这个slot的信息),再向其他节点发送PONG包,这样可以避免集群中的其他节点向迁出节点发送大量UPDATE包。如果先向集群中的其他节点发送PONG包,其他节点会将这个槽位交给迁入节点负责(迁入节点槽位抢占成功),等其他节点收到迁出节点的PING包时,此时迁出节点的PING包中仍然显示迁出节点负责这个槽位,但因为迁出节点的configEpoch较低,槽位抢占失败,其他节点会向迁出节点发送大量UPDATE包。
- 执行这条命令后,对于client的ASK请求,迁入节点仍能正确处理。
5、去迁出节点(及其slave)使用 CLUSTER SETSLOT <slot> NODE <node-id>命令 或者是 CLUSTER SETSLOT <SLOT> STABLE 命令
- 这一步的目的是设置 server.cluster->migrating_slots_to[slot] = NULL; 虽然不执行这一步好像也没什么问题,因为此时迁出节点及其slave上的 server.cluster->slots[slot] 已经指向迁入节点,关于这个槽位的请求已经能正确转向。
- 目前Redis的源代码,这两条命令都无法在slave上执行,需要优化。
对于步骤(1)和(2),如果集群状态在(2)(4)之间,client请求打到集群其他节点,其他节点会让client MOVED到迁出节点,迁出节点会让client 去ASK迁入节点,迁入节点此时能正常回复client。如果(1)和(2)顺序调换,先去迁出节点执行后,请求打到迁出节点,对于不存在的key,迁出节点会让client去ASK迁入节点,但迁入节点由于importing_slots_from为NULL,会让client MOVED到迁出节点,出现踢皮球现象。
对于步骤(4)和(5),如果集群状态在(4)(5)之间,client请求打到集群其他节点,其他节点如果收到迁入节点的包,会让client MOVED到迁入节点,否则会让client MOVED到迁出节点。client请求打到迁出节点,如果迁出节点没有收到迁入节点的包,会让client去ASK迁入节点,否则,会让client MOVED到迁入节点(即便此时迁出节点的server.cluster->migrating_slots_to[slot] 仍然指向迁出节点)。如果(4)和(5)顺序颠倒,先去迁出节点执行后,请求打到迁出节点,迁出节点会让client MOVED到迁入节点,client之后请求迁入节点并不会带上ASK标志,这样迁入节点会让client MOVED 到迁出节点,出现踢皮球现象。
2.4 用户请求处理
Redis的主节点负责集群状态信息的维护和处理写请求,从节点复制主节点的数据及状态信息,并处理读请求。
2.4.1 节点处理用户请求流程
getNodeByQuery函数。对于slave,master执行过的命令不会经过getNodeByQuery函数判断,slave一定会执行,保证slave和master的一致性,见processCommand。
另外,注意MOVED和ASK都是将流量导到master,而不是slave。
1、如果有多个key,判断这些key的slot是否属于同一个slot,如果不是返回CROSS_SLOT错误
- Redis需要返回CROSS_SLOT的原因是,如果用户请求多个slot,其中一个slot需要返回ASK,那client无法分清ASK是针对哪个槽位的。
2、如果这个slot当前没有节点负责,返回CLUSTER_REDIR_DOWN_UNBOUND错误
- 此时集群状态一定是FAIL,但返回的并不是CLUSTER_DOWN_STATE错误
3、如果集群状态是FAIL,拒绝写请求(返回CLUSTER_DOWN_STATE错误),根据cluster_allow_reads_when_down参数允许读请求
- 此时这个slot一定有节点负责,但这个节点的状态可能是fail, 一个节点处于fail说明集群有多数节点无法ping通这个节点,但还是可以让客户端自己去试试)
4、如果(这个slot由自己负责 && 这个slot正在迁出 && 至少有一个key没有找到),返回 ASK迁出节点
- 返回ASK的条件是 server.cluster->slots[slot] == myself && server.cluster->migrating_slots_to[slot] != NULL,在槽位迁移结束后,如果先去迁出节点执行SETSLOT命令,就会导致迁出节点向client返回MOVED,当client请求迁入节点时不会带上ASK标志,导致迁入节点最后向client返回MOVED迁出节点,出现踢皮球现象。
5、如果 (client带ASK标志 && 这个slot正在迁入):
client如果有ASK标志可以访问正在迁入的槽位,否则只能访问正常的槽位或者收到MOVED回复。
- 如果 (只有一个key || 所有key都找到了),返回自己处理的结果
- 如果 (有多个key && 至少有一个key没有找到),返回TRY AGAIN(UNSTABLE)
这个两个条件保证槽位迁移时,master上单个key的读写一定正确执行,但多个key的读写存在数据失效问题。分为:
- 单个key的读:按照先去迁出节点读,再去迁入节点读的顺序,如果存在一定能读到,如果不存在,迁入节点最终会返回NULL
- 单个key的写:如果修改一个已经存在的key,修改一定成功,可能在迁出或者迁入节点修改成功;如果key不存在,迁出节点会返回ASK,最后在迁入节点插入成功
- 多个key的读:如果这些key同时存在于迁出或者迁入节点,能正确读到。否则(可能有些key压根就不存在),迁出节点会返回ASK,迁入节点会返回TRY AGAIN,导致数据读失效。
- 多个key的写:如果这些key同时存在于迁出或者迁入节点,能正确修改。否则,迁出节点会返回ASK,迁入节点会返回TRY AGAIN,导致数据修改失效。另外多个key的插入也会失败
6、如果(自己是slave && 当前请求是读请求 && 这个slot由自己的master负责),返回自己处理的结果
7、如果这个slot不是由自己负责,返回 MOVED目标节点,否则返回自己处理的结果
2.4.2 客户端如何应对MOVED和ASK
客户端为了能直接定位某个 key 所在的节点,需要缓存槽位配置信息,由于槽位迁移后Redis服务器并不会通知客户端,客户端与服务器的槽位配置信息会存在不一致的情况,需要纠正机制来调整和更新客户端的槽位信息,而MOVED和ASK就是这个纠正机制。
MOVED和ASK的区别是什么:
-
MOVED错误的重定向是永久的,代表槽的负责权已经从一个节点永久转移到了另一个节点,在客户端收到关于槽slot的MOVED错误之后,客户端以后每次遇到关于槽slot的命令时,都 应该 将命令直接发送给MOVED错误所指向的节点,因为该节点很大概率就是目前负责槽slot的节点,收到MOVED错误客户端需要立即刷新slots缓存。
-
ASK错误的重定向是临时的,只是说明这个slot当前正在迁移,不知道何时迁移完成。当客户端收到关于槽slot的ASK错误之后,虽然这说明以后这个slot将由ASK指向的节点负责,但由于短时间内这个slot的迁移还没结束,在迁移还没结束之前,客户端遇到关于槽slot的新命令时,应该 像以前那样先访问迁出节点,如果又收到ASK再访问迁入节点,直到客户端收到MOVED才说明这个slot已经迁移结束了,此后可以直接访问迁入节点。收到ASK错误客户端不必刷新slots缓存。
如果客户端每次都随机连接一个节点然后利用 MOVED 或者 ASK 来重定向其实是很低效的,所以一般客户端会在启动时通过解析 CLUSTER NODES 或者 CLUSTER SLOTS 命令返回的结果得到 slot 和节点的映射关系缓存在本地,一旦遇到 MOVED 或者 ASK 错误时会再次调用命令刷新本地路由(因为线上集群一旦出现 MOVED 或者是 ASK 往往是因为扩容分片导致数据迁移,涉及到许多 slot 的重新分配而非单个,因此需要整体刷新一次),这样集群稳定时可以直接通过本地路由表迅速找到需要连接的节点。
3、故障检测
3.1 消息交换频率与格式
跟大多数分布式系统一样,Redis Cluster 的节点间通过持续的 heart beat 来保持信息同步,不过 Redis Cluster 节点信息同步是内部实现的,并不依赖第三方组件如 Zookeeper。集群中的节点持续交换 PING、PONG数据,这两种数据包的数据结构一样,都会携带一定数目的其他节点的信息,之间通过 type 字段进行区分。
clusterMsg是节点之间交换集群信息的格式,其中的myslots表示当前节点(或自己的master)负责的slot。
// 注意这个结构没有正在迁移的槽位的信息,因此其他节点,包括master自己的slave都不知道哪些槽位正在迁移
typedef struct {
char sig[4]; /* Signature "RCmb" (Redis Cluster message bus). */
uint32_t totlen; /* Total length of this message */
uint16_t ver; /* Protocol version, currently set to 1. */
uint16_t port; /* TCP base port number. */
uint16_t type; /* Message type */
uint16_t count; /* Only used for some kind of messages. */
uint64_t currentEpoch; /* The epoch accordingly to the sending node. */
uint64_t configEpoch; /* The config epoch if it's a master, or the last
epoch advertised by its master if it is a
slave. */
uint64_t offset; /* Master replication offset if node is a master or
processed replication offset if node is a slave. */
char sender[CLUSTER_NAMELEN]; /* Name of the sender node */
// myslots是发送节点或者发送节点的master节点对应的clustreNode结构中的slots,用于同步各个节点的slots信息
// CLUSTER_SLOTS = 16384
unsigned char myslots[CLUSTER_SLOTS/8];
char slaveof[CLUSTER_NAMELEN];
char myip[NET_IP_STR_LEN]; /* Sender IP, if not all zeroed. */
char notused1[32]; /* 32 bytes reserved for future usage. */
uint16_t pport; /* Sender TCP plaintext port, if base port is TLS */
uint16_t cport; /* Sender TCP cluster bus port */
uint16_t flags; /* Sender node flags */
unsigned char state; /* Cluster state from the POV of the sender */
unsigned char mflags[3]; /* Message flags: CLUSTERMSG_FLAG[012]_... */
union clusterMsgData data;
} clusterMsg;
union clusterMsgData {
/* PING, MEET and PONG */
struct {
/* Array of N clusterMsgDataGossip structures */
// 数组长度由消息头中的count字段表示。
clusterMsgDataGossip gossip[1];
} ping;
/* FAIL */
struct {
clusterMsgDataFail about;
} fail;
/* PUBLISH */
struct {
clusterMsgDataPublish msg;
} publish;
/* UPDATE */
struct {
clusterMsgDataUpdate nodecfg;
} update;
/* MODULE */
struct {
clusterMsgModule msg;
} module;
};
// 每一个clusterMsgDataGossip实例都表示了一个发送节点知道的节点的信息(比如结点是否在线)
// 这个结构不包含这个node的slot信息
typedef struct {
// 这个node的nodename
char nodename[CLUSTER_NAMELEN];
uint32_t ping_sent;
uint32_t pong_received;
char ip[NET_IP_STR_LEN]; /* IP address last time it was seen */
uint16_t port; /* base port last time it was seen */
uint16_t cport; /* cluster port last time it was seen */
uint16_t flags; /* node->flags copy 包括 MASTER SLAVE PFAIL FAIL HANDSHAKE */
uint16_t pport; /* plaintext-port, when base port is TLS */
uint16_t notused1;
} clusterMsgDataGossip;
Redis 集群中的每个节点都会定期向集群中的其他节点发送 PING 消息,以此来检测对方是否存活,并将自己当前知道的集群其他节点的状态信息广播出去,每个PING/PONG包中包含的其他节点数目是 集群节点总数(不区分master、slave) /10 + 所有处于PFAIL状态的节点,发送PING包的频率是:
- 每秒会随机选取5个节点,找出最久没有通信的节点发送ping消息
- 每100毫秒(1秒10次)都会扫描本地节点列表,如果发现最近一次接收到某个节点的pong消息的时间大于cluster-node-timeout/2, 则立刻向这个节点发送ping消息
clusterProcessGossipSection中,对于已知sender发送的PING/PONG包中包含的当前节点不知道的节点,当前节点会将这些未知节点加入server.cluster->nodes中,后面在ClusterCron函数中会为这些未知节点建立连接,如果PING/PONG是一个master发来的,还会处理其中的FAIL/PFAIL信息
3.2 节点状态检测
3.2.1 如何判断一个结点FAIL?(多数节点没有ping通)
- clusterCron中发现很久没有收到某个node的消息时,先标记这个node为pfail状态(主观下线)。
- 如果有其他master在gossip类型消息中(只有PING、PONG、MEET会带gossip信息,但MEET中报告的pfail和fail信息现在是忽略的)报告某个node处于fail或pfail状态,将这个master加入这个node的fail_reports队列,然后检查这个node的状态,如果这个node已经处于pfail状态(如果node不处于pfail状态,不会判断为FAIL),进一步检查其fail_reports队列长度是否超过集群master size的一半,标记这个node处于FAIL(客观下线),清除其pfail标志,向所有节点(包括slave)广播这个node的fail类型消息(客观下线可以传播),slave也可以发送FAIL消息
- 其他节点收到这个node的fail消息时,立即标记这个node为fail状态(如果这个node是自己,忽略这个消息,自己不能标记自己是FAIL的),清除其pfail标志(如果自己能ping通这个节点,那自己不会发送FAIL类型消息,但如果自己收到FAIL消息,还是得标记为这个节点为FAIL,以确保集群状态的统一)
3.2.2 节点处于fail或pfail状态后可以取消
如果收到一个节点的PONG消息,会清除其pfail状态。
清除fail状态的情形:
- 如果该节点此时是slave 或者 不负责任何slot(node->numslots==0,只有master节点的numslots才可能大于0),直接清除。
- master失败后,正常会有slave接替并负责这个master之前负责的所有slot,这个master重新上线后会发现自己的槽位都被抢占完而变为slave,会在这里清除其FAIL标识。
- 如果该节点是master,且其node->numslots > 0,且失败的时间已经够久了,清除其fail标志。
- 但如果这个master重新上线后,发现自己之前负责的slot没有被抢占完,可能是:
- 还没有slave去接替他(发生网络分区后,少数部分的集群没有办法提升slave为master)
- 有slave去接替他,但slave没有将master之前负责的slot全部抢占完,那这个master可以重新上线,集群的状态可以变为OK
- 但如果这个master重新上线后,发现自己之前负责的slot没有被抢占完,可能是:
3.3 集群状态检测
Redis会在clusterCron函数中周期性的检测集群状态,以及在集群状态改变时(节点的flag发生变化(master转变为slave,设置或清楚FAIL或PFAIL),slot的归属发生变化)立即在clusterBeforeSleep中检测集群状态。
检测的标准是:
- 如果所有slot都有非fail状态的master在负责,集群状态就是OK的。如果存在没人认领的slot(只有master才能认领slot),或者有一个以上fail状态的master(且这个master有负责的槽位),集群状态就是fail
- slave failover后会抢占slot,这样旧master虽然是FAIL状态但不负责槽位,这样集群状态也会恢复OK
- 处于pfail状态的master的数量不超过集群master数量的一半也是OK
- 这个条件是为了脑裂。发生网络分区时,集群会被分为多数部分和少数部分,少数部分虽然会标记节点为PFAIL,但由于少数部分节点数量不够(判断一个节点为FAIL需要超过一半master认为其是PFAIL的),不会标记节点为FAIL,如果只有条件1,少数部分就无法判断集群状态为FAIL。有了这个条件,少数部分也会设置集群状态为FAIL,避免脑裂问题的出现。
Redis节点处理请求时,如果集群状态是FAIL,会拒绝所有写请求,但可以允许读请求(可以正常返回MOVED和ASK)
4、集群模式下的主从切换
4.1、自动failover流程
开启条件:clusterCron会周期性调用clusterHandleSlaveFailover做检查,如果slave发现自己的master是FAIL状态,这个slave开启竞争成为master的failover流程。
- 设置自己发送 failover_auth包 的时间是:当前时间 + [500ms, 1000ms]內随机值 + 1000ms * rank(按主从复制偏移从大到小排序,自己能排第几,第0是最适合接替master的),在outgoing link上向master下其他的slave发送PONG包,PONG包中包含自己的主从复制offset,让其他slave准确计算自己的rank。
- 此时不会立即发送failover_auth,这个等待很关键,需要等待其他slave发现自己master是FAIL的,并开启failover流程
- 等待期间,如果发现自己rank增大,增大发送failover_auth包的等待时延
- 准备发送failover_auth包,slave增大自己的currentEpoch(投票轮数),这里没有增大自己的configEpoch,向所有节点发送 failover_auth包(含有自己的currentEpoch),设置 server.cluster->failover_auth_epoch = server.cluster->currentEpoch;
- 在clusterProcessPacket中,每次收到包时,会先更新自己的currentEpoch和发送节点的configEpoch。其他master收到某个slave的 failover_auth 包后,如果failover_auth包的currentEpoch < 自己的currentEpoch,说明这个failover_auth包的投票轮数较低,忽略这个 failover_auth包。如果自己之前针对这个投票轮数投过票(server.cluster->lastVoteEpoch == server.cluster->currentEpoch),也会忽略这个包,因为每个master在一轮投票中只能投一次票。否则会向这个slave投票,发送failover_ack,设置 server.cluster->lastVoteEpoch = server.cluster->currentEpoch;
- 如果发送failover_auth的slave的master是存活状态,且这个master收到了自己slave发送的failover_auth包,这个master不会投票。因为投票的前提是这个slave的master是FAIL状态,但一个节点不会标记自己是FAIL的,即便收到其他节点关于自己的FAIL消息
- slave计算是否得到超过多数master的投票,如果没有继续等待(一轮投票中,一个slave节点只能发送一次failover_auth包),如果已经超时,忽略本轮的后续投票,准备新一轮的投票。如果获得多数投票,设置自己为master,设置自己的configEpoch = server.cluster->failover_auth_epoch(投票轮数),向所有节点广播PONG,去抢占旧master的slot。旧master其他的slave收到新master的包后,会发现旧master的槽位全部被新master抢占而成为新master的slave
- 注意发生网络分区时,少数部分的slave由于无法获得多数master的投票,无法完成failover。
算法总结:
- 采用Raft算法选主。master挂了以后,主从同步时延低的slave递增currentEpoch(投票轮数),先发起投票。每轮投票一个slave只发送一次failover_auth包,然后等待结果。如果本轮投票超时了,忽略后续收到的failover_ack包,准备发起下一轮投票
- 对于master,每轮投票只投一次票,谁先发就投给谁。对于投票轮数低的failover_auth包,master不会投票。
- 一个节点修改自己的configEpoch必须得到多数master的同意(除了手动提升slave为master),其实configEpoch比 currentEpoch重要,因为它可以抢占slot,集群模式启动时,会有退避算法保证每个节点的configEpoch不一样。
- 有没有可能两个slave都认为自己是新的master?可能,但这两个slave的configEpoch一定不相同,这种情况是 last failover wins rule 原则。 slaveA 和 slaveB 发现自己的masterA挂了后,都准备发送failover_auth, 由于slaveA优先级高,slaveA先发,(1)slaveA增大currentEpoch后广播出去(2)超过一半master收到消息并回复同意,(3)slaveA增大自己的configEpoch,广播自己是新master。但在(2)和(3)之间,slaveB由于没有收到slaveA成为新master的消息,slaveB发起新一轮投票(salveB之前已经收到了slaveA广播的投票消息,已经更新自己的currentEpoch,此时slaveB广播的currentEpoch比slaveA广播的大),slaveB获得多数master的投票后,也广播自己是新master。此时其他master会先发现slaveA顶替了masterA(由slaveA负责masterA之前负责的slot)、然后发现slaveB顶替了slaveA,因为slaveB的configEpoch更高,会从slaveA中抢夺slot,最后slaveA收到slaveB的消息会设置slaveB是自己的新master
- 从Redis的failover流程可以看出,当一个master挂了以后,集群状态是FAIL的,并且只能由这个master下的slave来顶替,然后集群状态才能恢复OK。因此,需要让集群每个master下的slave数量尽量相等。Redis的每个slave会做周期性检查, 如果集群有孤儿master,且有master拥有2个以上正常slave,会把拥有slave数量最多的master下的一个slave(id最小的)迁移到另一个没有slave的master下面,避免master孤儿的出现
- 如果master挂了以后,顶替master的slave的数据没有master的那么新,那就会出现数据不一致。如果顶替master的slave的主从复制偏移不是最大的,那最大主从复制偏移的slave无法和新master进行增量同步,只能全量同步
- 写命令一般是发给master执行,为了避免主从之间的不一致,redis有个wait命令可以等待多少个slave确认后才返回,等待过程中会block client https://redis.io/commands/wait
4.2、手动failover流程(manual failover)
管理员可以在某个slave上输入CLUSTER FAILOVER [FORCE | TAKEOVER] ( https://redis.io/commands/cluster-failover/ ) 让slave主动接替其master,即便此时master是正常状态。
- slave向master发送MFSTART消息
- 如果有force参数,slave不会和master沟通,即便slave的主从复制偏移没有追上master,也会在获得多数master的投票后切换为master。
- master收到MFSTART消息后会暂停执行(pauseClients)所有client的写命令,并且master发出去的包中会带有PAUSED标志
- slave收到master的带有PAUSED标志的包后,从包中取出master的主从复制偏移(主从复制偏移是clusterMsg Header中的信息,是一直有的)
- slave检测自己的主从复制偏移是否已经追上master,调用clusterHandleSlaveFailover开启failover流程。由于是manual failover,clusterHandleSlaveFailover中即便master是正常状态也会开启failover,slave增大自己的currentEpoch,立即发送failover_auth包(不会等待),同时failover_auth包中会带有flag强制要求其他master投票(正常情况下只有这个slave的master是FAIL状态,其他master才会投票)
- slave得到多数master的投票后,提升自己为master,提高自己的configEpoch,向所有节点广播PONG。旧master及其slave收到新master的包后,会成为新master的slave
- 如果有takeover参数,slave不会向其他master发送failover_auth包,slave会在没有获得多数master投票的情况下直接增加configEpoch。takeover参数不建议使用。
5、Redis Cluster的消息种类
#define CLUSTERMSG_TYPE_PING 0 /* Ping */
#define CLUSTERMSG_TYPE_PONG 1 /* Pong (reply to Ping) */
#define CLUSTERMSG_TYPE_MEET 2 /* Meet "let's join" message */
#define CLUSTERMSG_TYPE_FAIL 3 /* Mark node xxx as failing */
#define CLUSTERMSG_TYPE_PUBLISH 4 /* Pub/Sub Publish propagation */
#define CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST 5 /* May I failover? slave接替master时使用 */
#define CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK 6 /* Yes, you have my vote slave接替master时使用 */
#define CLUSTERMSG_TYPE_UPDATE 7 /* Another node slots configuration */
#define CLUSTERMSG_TYPE_MFSTART 8 /* Pause clients for manual failover */
#define CLUSTERMSG_TYPE_MODULE 9 /* Module cluster API message. */
#define CLUSTERMSG_TYPE_COUNT 10 /* Total number of message types. */
// master节点判定一个节点离线时发送,消息体仅包含离线节点的nameid。
typedef struct {
char nodename[CLUSTER_NAMELEN];
} clusterMsgDataFail;
// 发送结点通知接收节点去更新消息体中nodename指定的节点负责的slots。
typedef struct {
uint64_t configEpoch; /* Config epoch of the specified instance. */
char nodename[CLUSTER_NAMELEN]; /* Name of the slots owner. */
unsigned char slots[CLUSTER_SLOTS/8]; /* Slots bitmap. clusterMsg消息头
中有发送者的slots,这里还有一个slots数组*/
} clusterMsgDataUpdate;
union clusterMsgData {
/* PING, MEET and PONG */
struct {
/* Array of N clusterMsgDataGossip structures */
// 数组长度由消息头中的count字段表示。
clusterMsgDataGossip gossip[1];
} ping;
/* FAIL */
struct {
clusterMsgDataFail about;
} fail;
/* UPDATE */
struct {
clusterMsgDataUpdate nodecfg;
} update;
......
};
5.1、PING、PONG、MEET
Note that the PING, PONG and MEET messages are actually the same exact kind of packet. PONG is the reply to ping, in the exact format as a PING, while MEET is a special PING that forces the receiver to add the sender as a node (if it is not already in the list).
redis会监听port端口,用于接收客户端的连接和主从同步连接。如果开启集群模式,会用port+10000作为集群模式的端口,每台机器会监听这个端口,accept新的连接,创建clusterLink,并注册clusterReadHandler用于处理各个节点间的集群通信消息。
Redis中,当前节点(myself)与其他节点(remote node,对应一个ClusterNode结构)都会建立两条连接,分别是incoming link和outgoing link,共对应两个ClusterLink结构。当前节点的outgoing link 对于 remote node来说是 incoming link。outgoing link是由当前节点主动发起建立的,节点主动发送消息时都是在自己的outgoing link上发送(比如PING、MEET,UPDATE,FAIL,节点也可能在outgoing link上主动发送PONG(槽位迁移结束,slave failover结束)),另一个节点则是在自己的incoming link上收到消息,如果这个消息需要回复,另一个节点就会在这个incoming link上回复(在哪个link上收到消息,就会在这个link上回复,比如PONG)。对于一个节点来说,其 incoming link 是由remote node发起建立的,incoming link 的 ClusterLink->node 总是为 NULL。因此从incoming link 上收到packet后,不能直接通过 ClusterLink -> node 找到这个 ClusterNode,而要通过packet中的名字(header -> sender)去 server.cluster->nodes 这个dict中找,找到则是已知节点,否则是未知节点。
虽然meet消息和未知sender(通过packet中的名字,在自己的server.cluster->nodes 这个dict中是否能找到这个ClusterNode)发的PING和PONG消息可能会包含很多当前节点不知道的节点,但 clusterProcessGossipSection 函数不会处理,clusterProcessGossipSection只会为已知sender发送的PING、PONG中的未知节点创建 ClusterNode结构,然后clusterCron才会与这些未知节点创建连接。
MEET消息与双向连接建立流程
-
当用户在节点A输入MEET节点B的IP地址后(CLUSTER MEET IP PORT), 节点A会调用 clusterStartHandshake 为节点B生成 ClusterNode 结构,由于此时节点A不知道节点B的名字id,先随机生成node->name(集群中每个节点的名字是写在集群配置文件中的,没有配置文件就每个节点启动的时候自己随机生成),设置节点B的IP PORT信息,设置节点flag(节点状态)为HANDSHAKE 和 MEET状态,将ClusterNode加入 server.cluster->nodes这个dict中
-
节点A的clusterCron会遍历 server.cluster->nodes,如果某个ClusterNode没有绑定link,会为其创建outgoing link,创建成功后设置 ClusterNode -> link指向这个outgoing link,设置这个outgoing link 的ClusterLink -> node指向这个ClusterNode(代表 remote node)。节点B accept连接后,创建一个incoming的Clusterlink(incoming link的node指针总是NULL)
-
link创建成功后会调用clusterLinkConnectHandler处理,如果node的 flag 含有MEET,节点A会发送MEET(同时去除MEET标志),否则发送PING。
-
节点B在自己的incoming link上收到节点A的MEET消息后,会在这个incoming link上回复PONG。然后会为节点A创建一个ClusterNode结构,先随机生成一个名字,根据packet header中的信息设置节点A的IP PORT信息,设置节点标志为 HANDSHAKE(此时没有MEET标志,名字未知的节点都有handshake标志,只有收到PONG包才会确定节点的名字(ClusterNode->name),然后去除handshake标志,成为已知节点,同时连接才真正建立),将这个ClusterNode加入 server.cluster->nodes这个dict中。
- 即使节点A发送的MEET消息中含有节点B不知道的节点,节点B此时也不会处理。clusterProcessGossipSection
-
节点A在自己的outgoing link上收到节点B回复的PONG后,由于节点B此时具有handshake标志,属于未知节点,会根据header中的的名字信息更新节点B ClusterNode结构中的名字(link->node->name),同时去除节点B的 HANDSHAKE 标志,至此节点A会认为节点B是已知节点,节点A到节点B方向的连接已经建立。
- 只有收到未知节点的PONG包后,未知节点才能变成去除HANDSHAKE标志变为已知节点。
- 虽然PONG可能包含很多当前节点不知道的节点,但此时不会使用
-
节点B的clusterCron会遍历 server.cluster->nodes,为节点A这个node创建 outgoing link,设置nodeA -> link为新创建的outgoing link。节点A accept连接后,创建一个incoming的Clusterlink。由于节点A的flag中没有 MEET标志,节点B会在自己的outgoing link上发送PING给节点A。
-
节点A在自己的incoming link上收到节点B的PING包后,会在这个link上回复PONG
- 正常情况下,第7步在第5步以后,因此此时节点A会认为节点B是已知节点,会调用 clusterProcessGossipSection 处理这个PING包。对于已知sender(节点B)报告的自己(节点A)不知道的节点,节点A会用节点的name创建一个node(这些节点的name已经确定了,这些节点创建时没有handshake和meet标志),加入server.cluster->nodes(key是node->name),clusterCron中会尝试建立连接,第一次握手的时候发送的是PING,收到PONG时因为remote node是已知节点,不会再更新其name。但需要注意的是,此时对于这些已知节点而言,虽然回复了PONG,但仍没有为当前节点(myself)建立 ClusterNode结构(目前只有MEET消息会让remote node也为本节点创建 ClusterNode结构), 其会认为当前节点仍然是未知节点。只有等到这些已知节点收到其他已知节点关于当前节点(myself)的gossip信息后才会主动建立连接。
- 如果第7步在第5步之前发生,节点A收到PING包时会认为节点B是未知节点,对于未知sender发的PING包,目前只会回复PONG,不会为这个未知sender建立 ClusterNode结构(因此也不会在 ClusterCron中主动建立连接),目前创建 ClusterNode结构的地方只有三个,一个是节点执行 CLUSTER MEET命令时,另一个是节点收到并处理MEET消息时,最后是处理已知sender发送的PING/PONG包中的未知节点时。
-
节点B在自己outgoing link上收到节点A回复的PONG后,由于节点A此时具有handshake标志,属于未知节点,会根据header中的的名字信息更新节点A ClusterNode结构中的名字,同时去除节点A的 HANDSHAKE 标志,至此节点B会认为节点A是已知节点,节点B到节点A方向的连接已经建立。
5.2、FAIL消息的处理
节点FAIL消息发送条件:当一个节点(可以是slave)判断另一个结点处于FAIL时,向集群所有节点发送FAIL消息。
节点收到FAIL消息时:如果一个已知sender(sender可以是slave)认为一个已知node是fail状态,自己立即标记这个node是fail状态,同时去除其pfail状态
5.3、槽位抢占与UPDATE消息
节点(节点A)发出去的packet会有自己负责的槽位信息(slave发送包的时候用的是master的configEpoch和slots),其他节点(节点B)收到后这个packet后,如果发现节点A是master(槽位抢占只会发生在两个master之间),会调用clusterUpdateSlotsConfigWith,依次检查packet中节点A声称自己负责的slot,如果这个槽位目前没有节点负责,或者如果这个槽位由其他节点负责(槽位冲突)且节点A的configEpoch比当前负责这个槽位的节点的configEpoch高,就把这个槽位交给节点A负责,此时节点A成功抢占这个槽位。如果当前节点或者当前节点(slave)的master所负责的槽位都被节点A抢占,当前节点会成为节点A的slave。
UPDATE消息用于处理抢占槽位失败的情况。其他节点(slave也可以发送UPDATE)收到sender发送的packet后,如果发现sender(可以是slave)负责的slot目前正由其他节点负责(槽位冲突节点),但sender的configEpoch较低,会向sender发送UPDATE消息,消息中包含与sender冲突的节点名字(Id)、冲突节点的configEpoch、冲突节点负责的槽位,尝试让sender修复槽位冲突问题。注意UPDATE消息体中的冲突节点一定是master,因为只有master才能负责槽位。
节点(可以是slave)收到UPDATE消息后,如果发现自己观察到的冲突节点的configEpoch > UPDATE消息中的confitEpoch,会忽略这个UPDATE消息,这说明自己之前收到过关于这个冲突节点的更大configEpoch的消息,且当时已经进行过槽位抢占了。否则会用UPDATE消息中的configEpoch和slots,更新冲突节点的配置信息,然后执行槽位抢占流程,让冲突节点去抢占槽位。
对于节点A在自己的packet中说自己不负责某个槽位,但其他节点发现这个槽位目前是由节点A负责的情况,目前没有处理。其他节点会一直认为这个槽位由节点A负责,直到有其他更高configEpoch的master来抢占这个槽位,比如槽位迁移结束后
6、Redis集群模式优缺点
由于数据分布在不同节点中,导致一些功能受限,包括:
- key批量操作受限
- 例如mget、mset操作,只有当操作的key都位于一个槽时,才能进行。
- 针对该问题,一种思路是在客户端记录槽与key的信息,将用户的单个mget拆分成多个mget,每个mget只针对一个槽;
- 另外一种思路是使用Hash Tag。Hash Tag原理是:当一个key包含 {} 的时候,不对整个key做hash,而仅对 {} 包括的字符串做hash。
- 事务/Lua脚本
- 事务及Lua脚本要求涉及的所有key必须在同一个节点。Hash Tag可以解决该问题。
- 键是数据分区的最小粒度,不能将一个很大的键值对映射到不同的节点,比如很大的dict
- 数据库数量
- 单机Redis节点可以支持16个数据库,集群模式下只支持一个,即db0。
- 不支持嵌套的主从复制结构,只支持一层复制结构。
Gossip协议
https://cloud.tencent.com/developer/article/1662426
https://blog.csdn.net/chen77716/article/details/6275762
1、Gossip定义
以给定的频率,每个节点随机选择一批节点发送消息,最终所有节点的状态都会达成一致。
Gossip不能保证某个时刻所有节点都收到消息,只是理论上最终所有节点都会收到消息,因此它是一个最终一致性协议。”最终“是一个现实中存在,但理论上无法证明的时间点。
Gossip不适用于强一致性的场景,Gossip牺牲了一致性C,保证了A和P。
由于是随机选择节点,因此存在消息冗余问题:同一节点多次接收同一消息,增加消息处理的压力,浪费网络带宽。
Gossip协议是一个多主协议,写操作可以由不同节点发起,并且同步给其他节点。Gossip的节点都是对等节点,是非结构化网络,完全去中心化。
2、Gossip协议的两种模式
- 反熵传播Anti-Entropy
每个节点周期性地随机选择其他节点,然后通过互相交换自己的所有数据来消除两者之间的差异。交换所有数据会带来非常大的通信负担,但收敛较快,因此不会频繁使用,通常只用于新加入节点的数据初始化。 - 谣言传播
节点之间只交换新到达的数据。这些新数据被称为谣言,谣言消息在某个时间点之后会被标记为removed,不再被传播。缺点是系统有一定的概率会不一致,通常用于节点间数据增量同步。
3、Gossip节点间的三种通信方式
- push(节点将自己的消息发给其他节点)
A节点将数据及对应的版本号(key,value,version)发送给B节点,B节点更新A中比自己新的数据 - pull(节点主动从其他节点获取消息)
A仅将数据key,version推送给B,B将本地比A新的数据(Key,value,version)推送给A,A更新本地 - push/pull
与pull类似,只是多了一步,A再将本地比B新的数据推送给B,B更新本地
4、性能
假设每个节点在每个通信周期都能选择(感染)一个新节点,则Gossip算法的收敛速度为2^n,收敛时间为log2(N)。这是理论上最优的收敛速度,实际中很难达到,但可以认为Gossip算法是指数级收敛的。设每个节点在每个通信周期都能感染p个新节点(0<p<1),则收敛速度为 (1+p)^n,收敛时间为log(1+p)(N)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号