Django中ORM操作
目录
Django ORM操作
ORM定义
全名:对象关系映射
作用:能够让一个不用sql语句的小白也能够通过python 面向对象的代码简单快捷的操作数据库
不足之处:封装程度太高 有时候sql语句的效率偏低 需要你自己写SQL语句
类 表
对象 该行记录
对象属性 记录某个字段对应的值
创建新表
1.先去models.py中书写一个类
class User(models.Model): # user是表名 必须继承models.Model类
# 等价于 id int primary key auto_incremen
id = models.AutoField(primary_key=True, verbose_name='主键') # verbose_name是给字段加解释
# 等价于 username varchar(32)
username = models.CharField(max_length=32, verbose_name='用户名')
# 等价于 password int
password = models.IntegerField(verbose_name='密码')
2.数据库迁移命令(特别重要)
# 在pycahrm自带的命令行Terminal中执行以下操作
python3 manage.py makemigrations # 将操作记录记录到小本本上(migrations文件夹)
python3 manage.py migrate # 将操作真正的同步到数据库中
******************只要你修改了models.py中跟数据库相关的代码 就必须重新执行上述的两条命令*******************
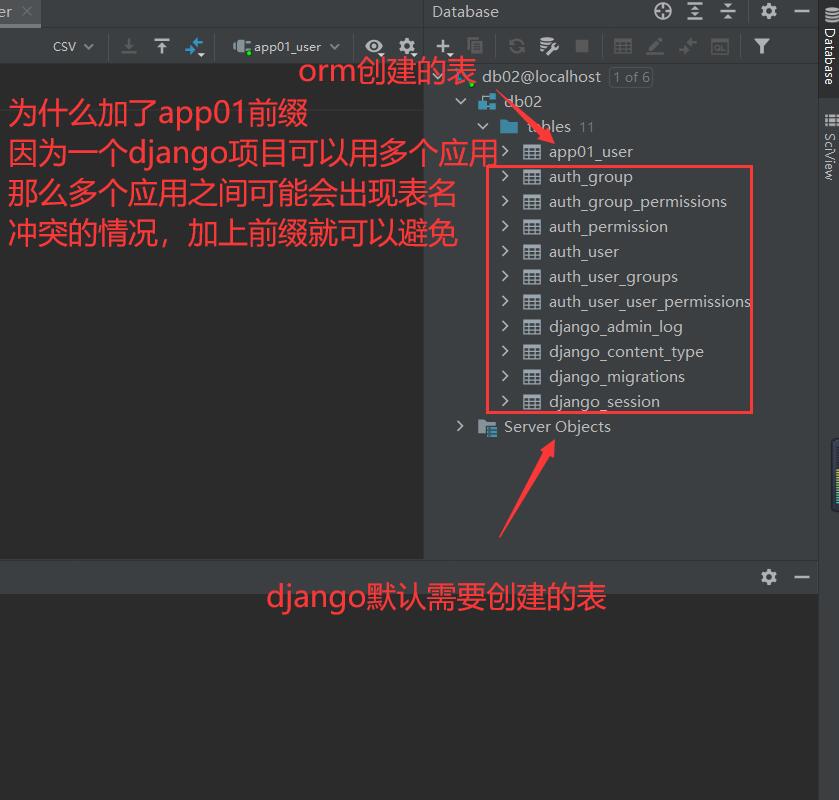
创建成功
ORM特性
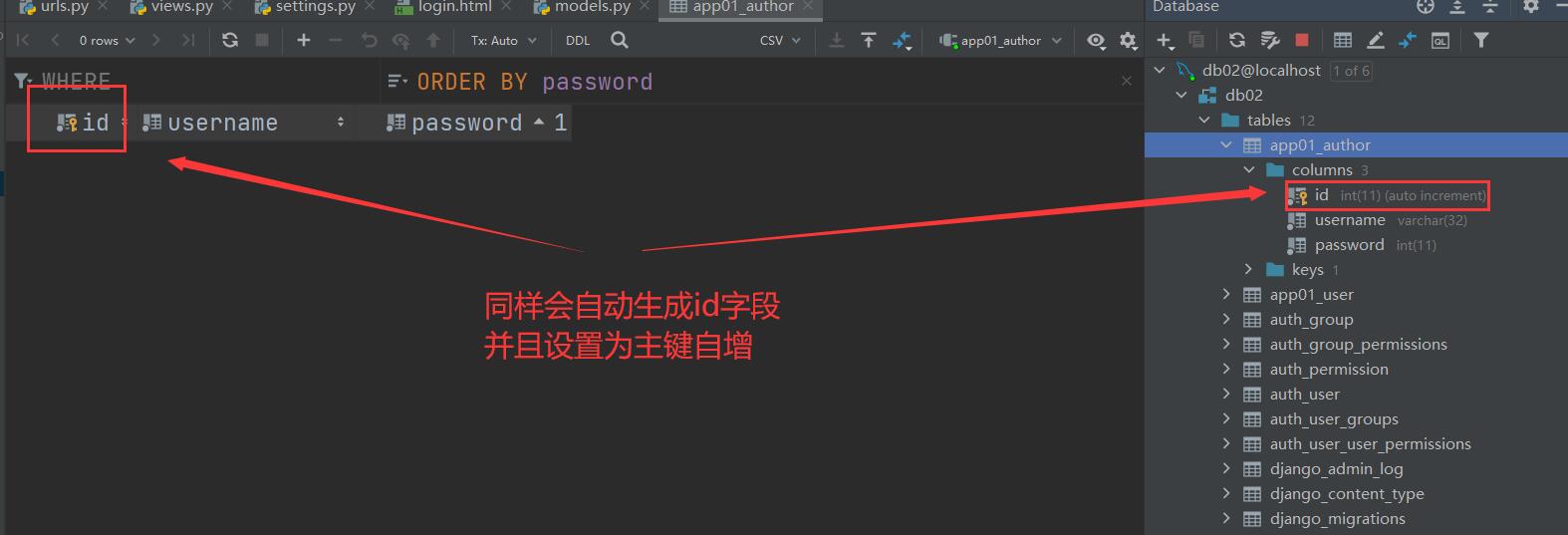
由于一张表中必须要有一个主键字段 并且一般情况下都叫id字段
所以orm当你不定义主键字段的时候 orm会自动帮你创建一个名为id主键字段
也就意味着 后续我们在创建模型表的时候如果主键字段名没有额外的叫法 那么主键字段可以省略不写
# 在models.py文件中
class Author(models.Model):
# 相当于 username varchar(32)
username = models.CharField(max_length=32, verbose_name='用户名')
# 相当于 password int
password = models.IntegersField(verbose_name='密码')
# 数据库迁移
执行python3 manage.py makemigrations和python3 manage.py migrate
补充
CharField必须要指定max_length参数 不指定会直接报错
verbose_name该参数是所有字段都有的 就是用来对字段的解释
字段的增删改查
增
方式1:可以在终端内直接给出默认值
# 在models.py文件中
class Author(models.Model):
# 相当于 username varchar(32)
username = models.CharField(max_length=32, verbose_name='用户名')
# 相当于 password int
password = models.IntegersField(verbose_name='密码')
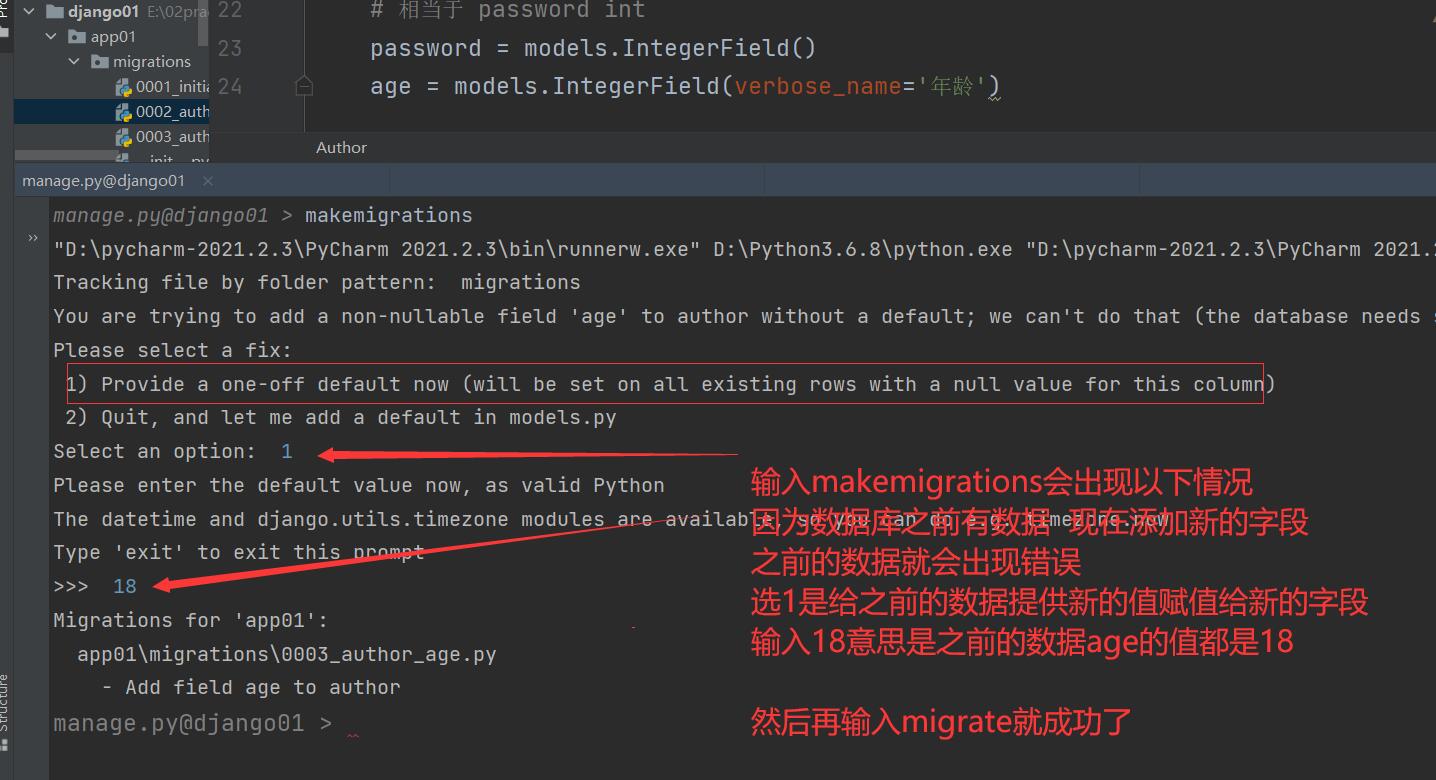
# 相当于 age int
age = models.IntegerField(verbose_name='年龄') ########### 新添加的字段
# 数据库迁移
执行python3 manage.py makemigrations和python3 manage.py migrate
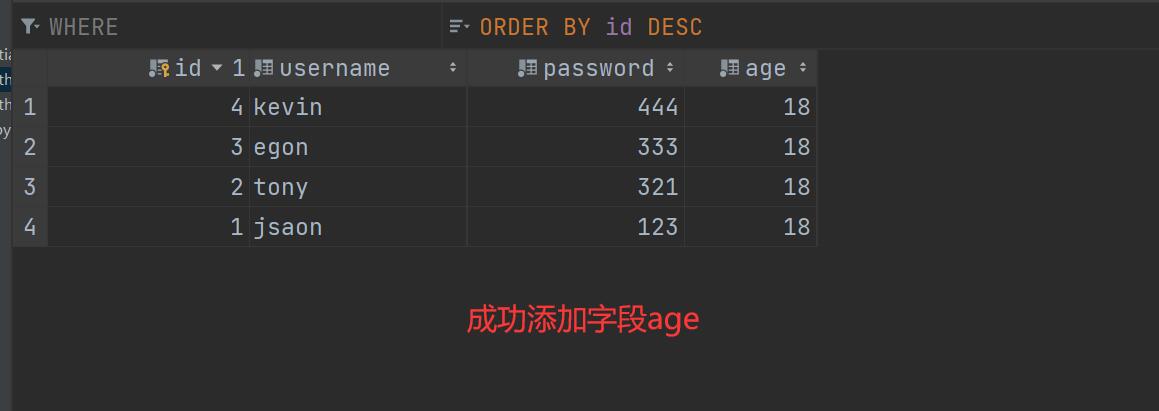
方式二:该字段可以为空
# 添加新字段 info
info = models.CharField(max_length=32,verbose_name='个人简介',null=True)
# 数据库迁移
执行python3 manage.py makemigrations和python3 manage.py migrate
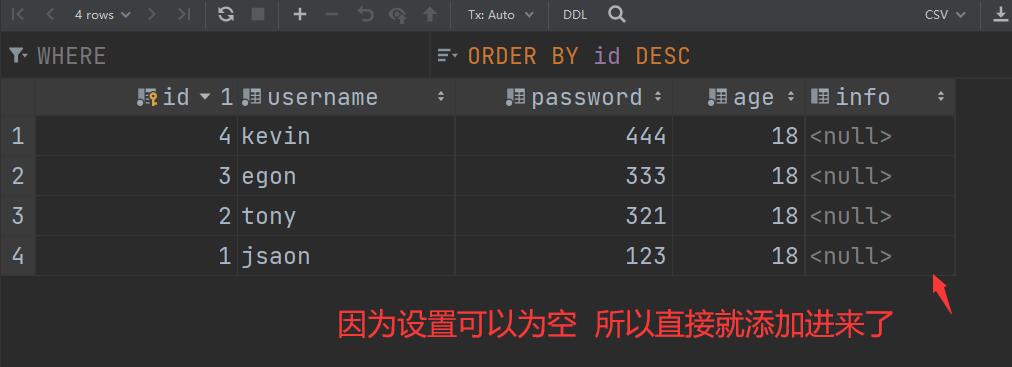
方式三:给字段设置默认值
# 添加新字段 hobby
hobby = models.CharField(max_length=32, default='study', verbose_name='爱好')
# 数据库迁移
执行python3 manage.py makemigrations和python3 manage.py migrate
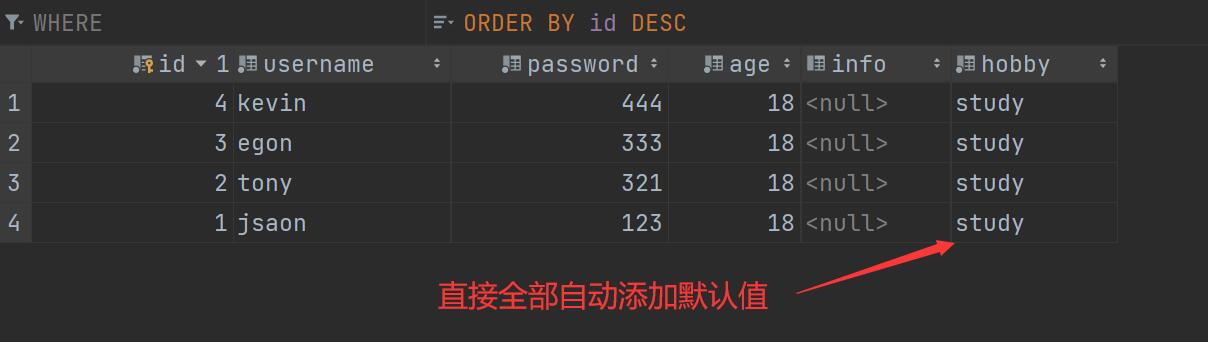
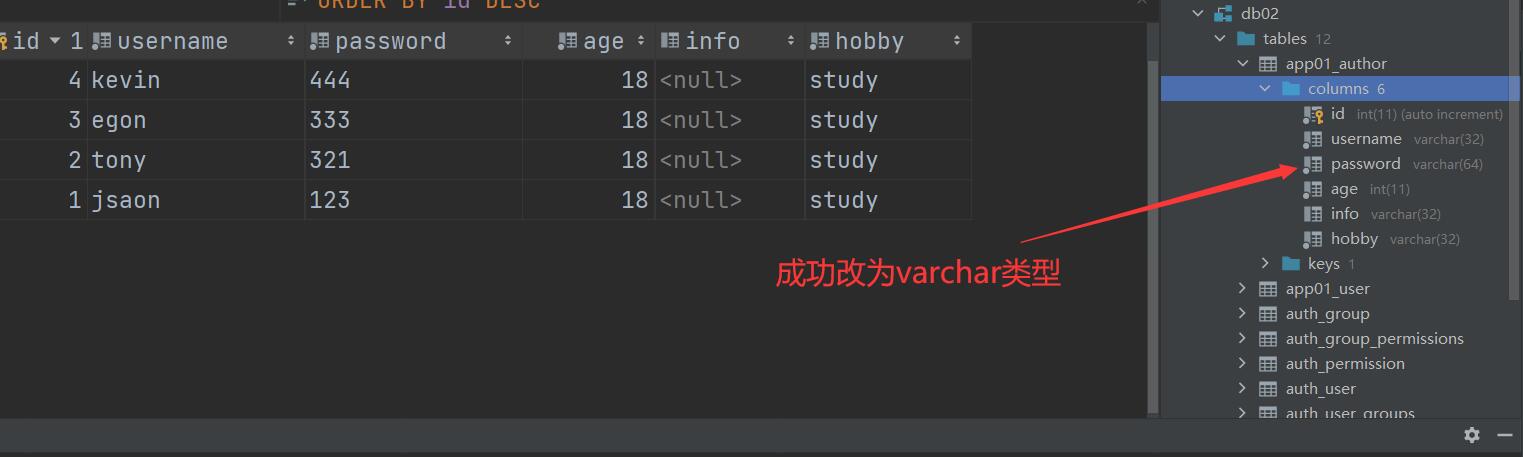
改
# 把password字段的int类型改为varchar类型
# password = models.IntegerField(verbose_name='密码')
password = models.CharField(verbose_name='密码', max_length=64)
# 数据库迁移
执行python3 manage.py makemigrations和python3 manage.py migrate
删(慎重)
直接注释对应的字段然后执行数据库迁移的两条命令即可!
执行完毕之后字段对应的数据也都没有了
"""
在操作models.py的时候一定要细心
千万不要注释一些字段
执行迁移命令之前最好先检查一下自己写的代码
"""
# 个人建议:当你离开你的计算机之后一定要锁屏
数据的增删改查
查
格式:
models.User.objects.filter(字段名=要查找的数据) # 结果是个列表 也支持索引及切片操作(不支持负数)
models.User.objects.filter(pk=主键对应的数据) # 这里的pk就是代表主键 是primary key的简写
models.User.objects.all() # 查出数据库中所有的数据(推荐)
models.User.objects.filter() # 查出数据库中所有的数据
filter括号内可以携带多个参数 参数与参数之间默认是and关系
你可以把filter联想成where记忆
from app01 impot models # 要把这个models模块导过来
# 接收用户输入的username信息
name = request.POST.get('username')
# 去app01_user表中的字段username中寻找有没有和name相等的数据 结果返回一个列表res_list 可以有很多个对象
res_list = models.User.objects.filter(username=name)
# 从列表中找第一个对象
user_obj = res_list.first() # 也可以res_list[0] 但是官方不推荐
# 对象可以点方法获取数据 是该行数据对应的所有信息 点字段名就取到该字段的值
print(user_obj.username) # jason
print(user_obj.password) # 123
增
格式:
models.User.objects.create(字段名=数据,...) # 返回值是该数据对象
from app01 import models
name = request.POST.get('username')
pwd = request.POST.get('password')
# 返回值就是当前被创建的对象本身
res = models.User.objects.create(username=name,password=pwd)
print(res.username) # tom
print(res.username) # 123
# 第二种增加
user_obj = models.User(username=username,password=password)
user_obj.save() # 保存数据
改
方式一(推荐):
将filter查询出来的列表中所有的对象全部更新 批量更新操作
格式:
# 先获取符合条件的数据对象列表
obj_list = models.User.objects.filter(id=edit_id)
# 修改该列表所有对象的数值
obj_list.update(username=name,password=pwd...) # 返回值是影响的行数
优点:只修改被修改的字段 节省资源
方式二:
单个对象修改
格式:
obj = models.User.objects.filter(id=edit_id).first()
obj.字段名 = 新值
obj.save()
缺点:当字段特别多的时候效率会非常的低
从头到尾将数据的所有字段全部更新一边 无论该字段是否被修改
删
格式:
# 数据库中找到对应的数据删除(批量删除)
models.User.objects.filter(字段=被删除数据对应的值).delete()
# 单一删除
obj = models.User.objects.filter(字段=被删除数据对应的值).first()
obj.delete() # 单个删除
增或改
在models.py中
class UserToken(models.Model):
user = models.OneToOneField(to='User', on_delete=models.CASCADE)
token = models.CharField(max_length=64)
在views.py中
# 这句话的意思是:去这个表中去查有没有user对应的数据,有则更新,没有则新增
UserToken.objects.update_or_create(defaults={'token': token}, user=user_obj)
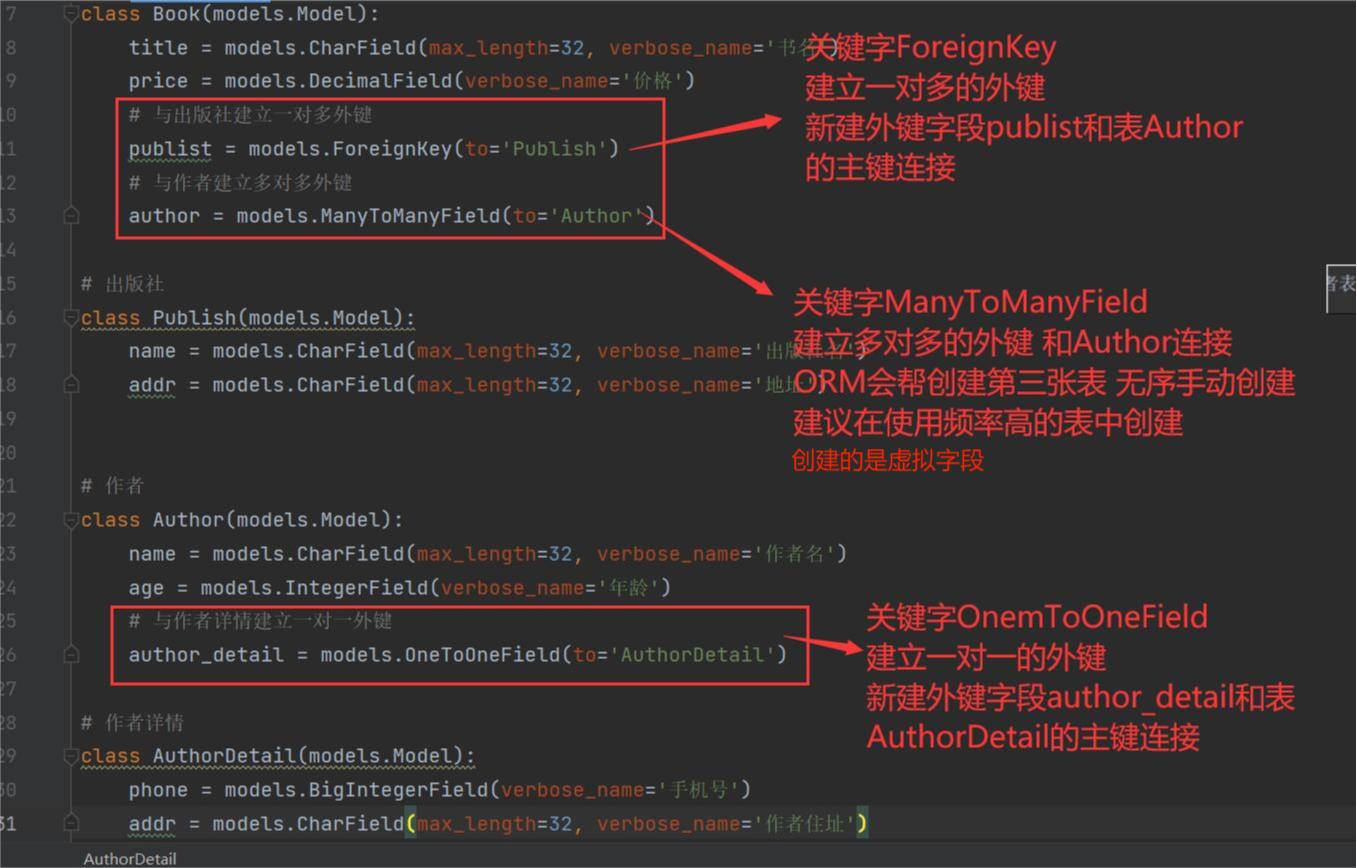
ORM中创建表关系
一对多
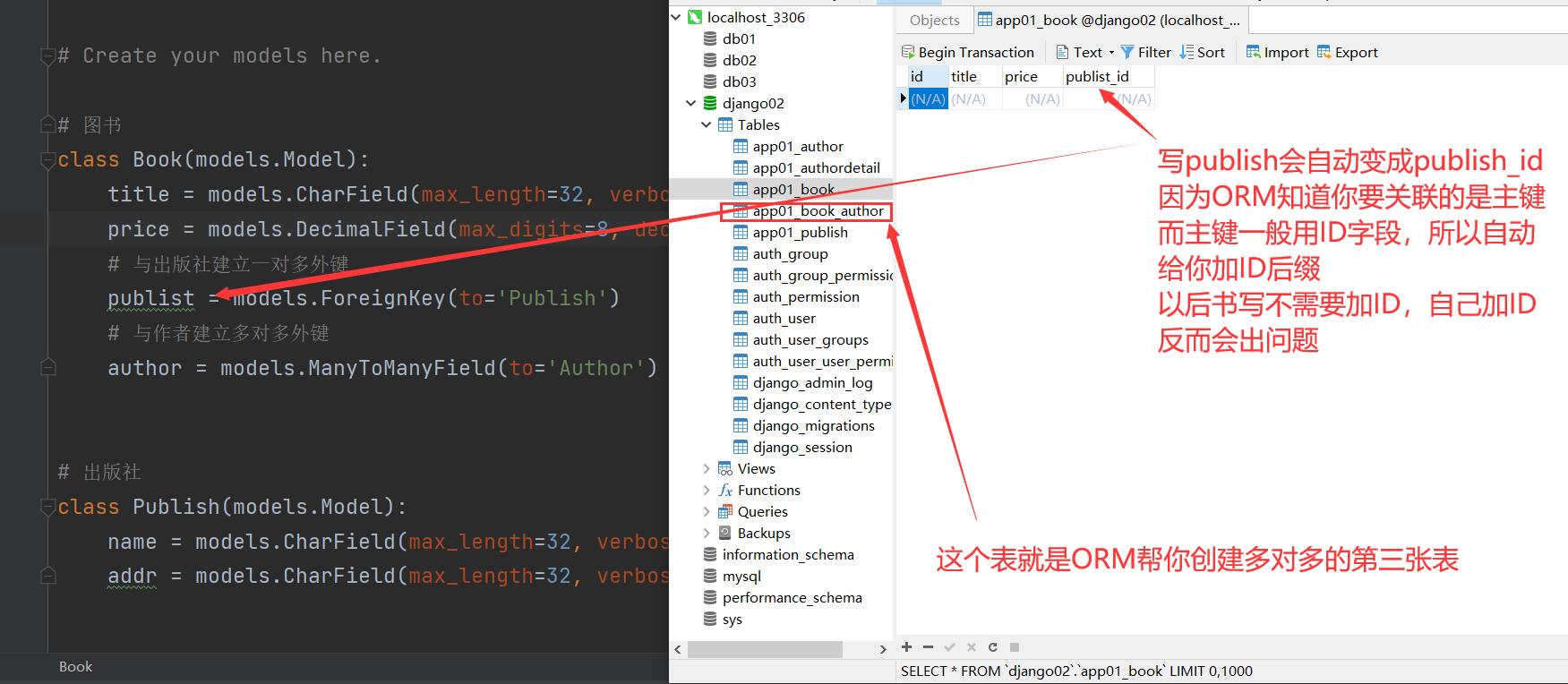
格式:
外键字段 = models.ForeignKey(to='关联的表名') # 默认就与关联表的主键字段做外键关联
'''
如果字段对应的是ForeignKey 那么会orm会自动在字段的后面加_id
如果你自作聪明的加了_id那么orm还是会在后面继续加_id
后面在定义ForeignKey的时候就不要自己加_id
'''
eg:
publish = models.ForeignKey(to='Publish')
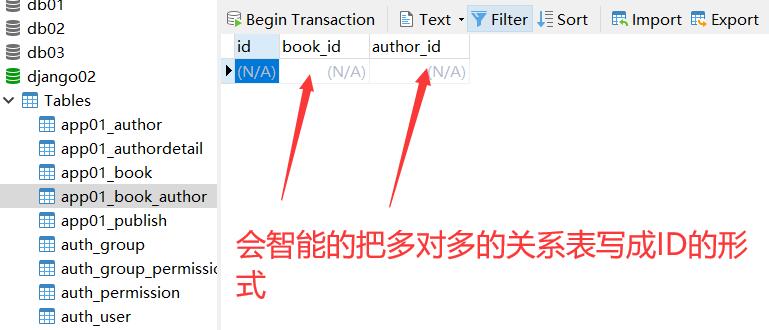
多对多
格式:
虚拟外键字段 = models.ManyToManyField(to='关联的表名')
'''
创建的是一个虚拟字段 主要是用来告诉orm 该表和关联的表是多对多关系
让orm自动帮你创建第三张关系表
外键字段建在任意一方均可 但是推荐你建在查询频率较高的一方
'''
eg:
authors = models.ManyToManyField(to='Author')
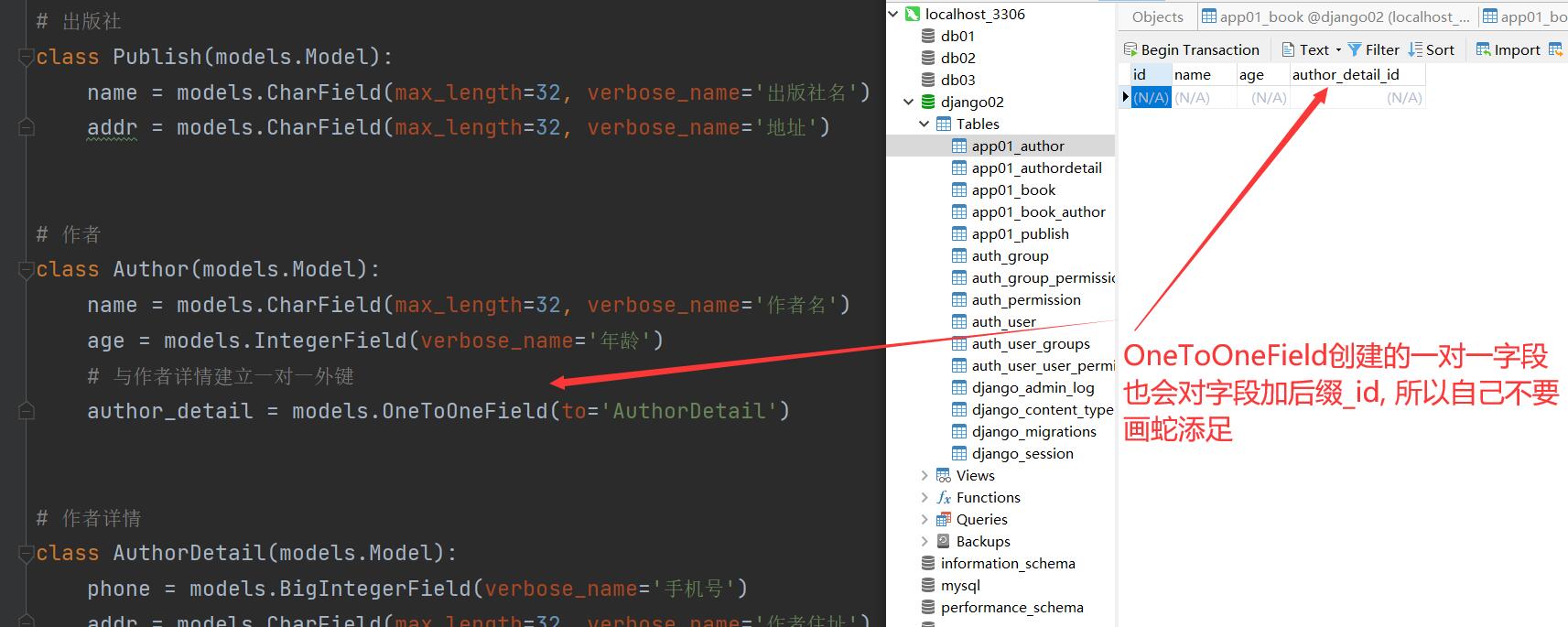
一对一
格式:
外键字段 = models.OneToOneField(to='关联的表名')
'''
OneToOneField也会自动给字段加_id后缀
所以你也不要自作聪明的自己加_id
'''
eg:
author_detail = models.OneToOneField(to='AuthorDetail')
总结
# ForeignKey、OneToOneField会自动在字段后面加_id后缀
# 在django1.X版本中外键默认都是级联更新级联删除的
# 多对多的表关系可以有好几种创建方式 这里暂且先介绍一种
# 针对外键字段里面的其他参数 暂时不要考虑 如果感兴趣自己可以百度试试看
# 不常用的数据我们称之为冷数据,
# 常用的数据我们称之为热数据
# 先创建这张表的基础字段,再回头创建外键字段
# decimal(5, 2) eg:123.58 !!!!!!!!!!!!!!
price = models.DecimalField(max_digits=5, decimal_places=2)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号