
第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC

2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业。
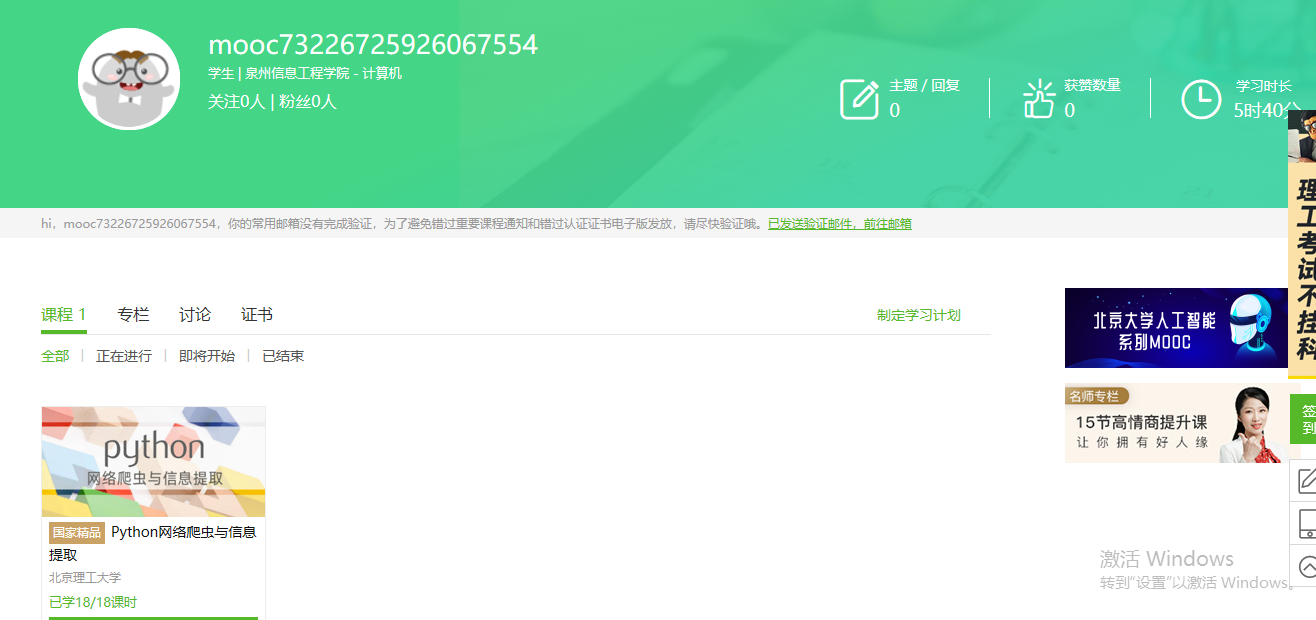
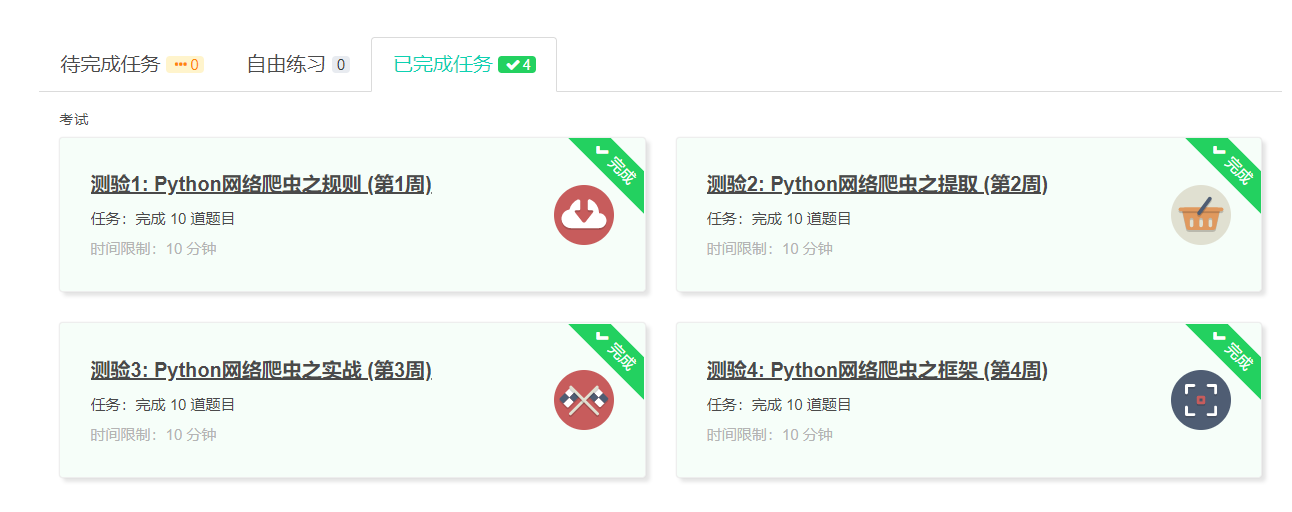
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
《Python网络爬虫与信息提取》的学习笔记
首先,这是第一次使用MOOC,并参与学习了北京理工大学崇天老师的课程。这是一个非常便捷的网站,可以从中学习很多知识。
通过这一门课程的学习,我更加了解了《Python网络爬虫与信息提取》,主要学习了requests库,Beautiful Soup库等知识。其实本身的Python没有很好,有一些知识点还是没有很清楚,需要自己独立的去写完整的代码还是有所难度。老师课上有一些具体的代码,自己再去敲一遍理解个代码意思,这样自己相对的也会记住一些,没有那么的困难。因为爬虫本身就是需要在实际操作中去学习python中相关的知识,这样反复的记忆才能让我们识记并运用。爬虫分为五个基本构架:调度器,URL管理器,网页下载器,网页解析器,数据存储器。对爬虫有了比较清晰的认识,不再是对他只有一个模糊的概念。也学习到了爬取网页的过程:发送请求和获取相应,对获取的response进行想要的信息的提取,对信息进行存储。scrapy框架,它是一个快速功能强大的网络爬虫框架。HTML解析网页内容,网络爬虫,是实现浏览器的功能。通过指定url,直接返回给用户所需要的数据,而不需要一步步人工去操纵浏览器获取。分析就是抓取之后就是对抓取的内容进行分析,你需要什么内容,就从中提炼出相关的内容来。常见的分析工具有正则表达式,BeautifulSoup,lxml等等。分析出我们需要的内容之后,接下来就是存储了。我们可以选择存入文本文件,也可以选择存入。从这一周的学习,让我了解到Python的学习是一个漫长的过程,它包含太多的知识点,对于我来说有些复杂,需要掌握的东西也很多。在这个课程中也了解网络爬虫在现今生活中的广泛运用。今天是互联网的时代,网络爬虫也成为自动获取互联网数据的一种主要方式。Python对于我们学习和工作都起到了很重要的作用,大大的降低了我们的时间,更快更好的对信息进行提取。通过这次课程的学习,使我受益匪浅。接下来我会继续对Python网络爬虫与信息提取这门课程的学习,在未来有更好的发展。
requests库的七种方法
request.request() 构造一个请求,支撑以下各方法的基础
request.get() 获取HTML网页的主要方法,对应于HTTP的GET
request.head() 获取HTML网页头信息的方法,对应于HTTP的HEAD
request.post() 向HTML网页提交POST请求的方法,对应于HTTP的POST
request.put() 向HTML网页提交PUT请求的方法,对应于HTTP的PUT
request.patch() 向HTML网页提交局部修改请求的方法,对应于HTTP的PATCH
request.delete() 向HTML网页提交删除请求的方法,对应于HTTP的DELETE
Beautiful Soup库解析器:
bs4的HTML解析器
lxml的HTML解析器
lxml的XML解析器
html5liblxml的解析器
BeautifulSoup类的基本元素:
Tag:标签
Name:标签名
Attributes:标签属性
NavigableString: 标签内非属性字符串

 浙公网安备 33010602011771号
浙公网安备 33010602011771号