MySQL 调优(视野一 explain )
https://docs.oracle.com/cd/E17952_01/mysql-5.6-en/explain-output.html#explain-join-types
简单举例:

The EXPLAIN statement provides information about how MySQL executes statements. EXPLAIN works with SELECT, DELETE, INSERT, REPLACE, and UPDATE statements.
EXPLAIN returns a row of information for each table used in the SELECT statement. It lists the tables in the output in the order that MySQL would read them while processing the statement. MySQL resolves all joins using a nested-loop join method. This means that MySQL reads a row from the first table, and then finds a matching row in the second table, the third table, and so on. When all tables are processed, MySQL outputs the selected columns and backtracks through the table list until a table is found for which there are more matching rows. The next row is read from this table and the process continues with the next table.
When the EXTENDED keyword is used, EXPLAIN produces extra information that can be viewed by issuing a SHOW WARNINGS statement following the EXPLAIN statement. EXPLAIN EXTENDED also displays the filtered column. See Section 8.8.3, “Extended EXPLAIN Output Format”.
You cannot use the EXTENDED and PARTITIONS keywords together in the same EXPLAIN statement. Neither of these keywords can be used together with the FORMAT option. (FORMAT=JSON causes EXPLAIN to display extended and partition information automatically; using FORMAT=TRADITIONAL has no effect on EXPLAIN output.)
MySQL Workbench has a Visual Explain capability that provides a visual representation of EXPLAIN output. See Tutorial: Using Explain to Improve Query Performance.
This section describes the output columns produced by EXPLAIN. Later sections provide additional information about the type and Extra columns.
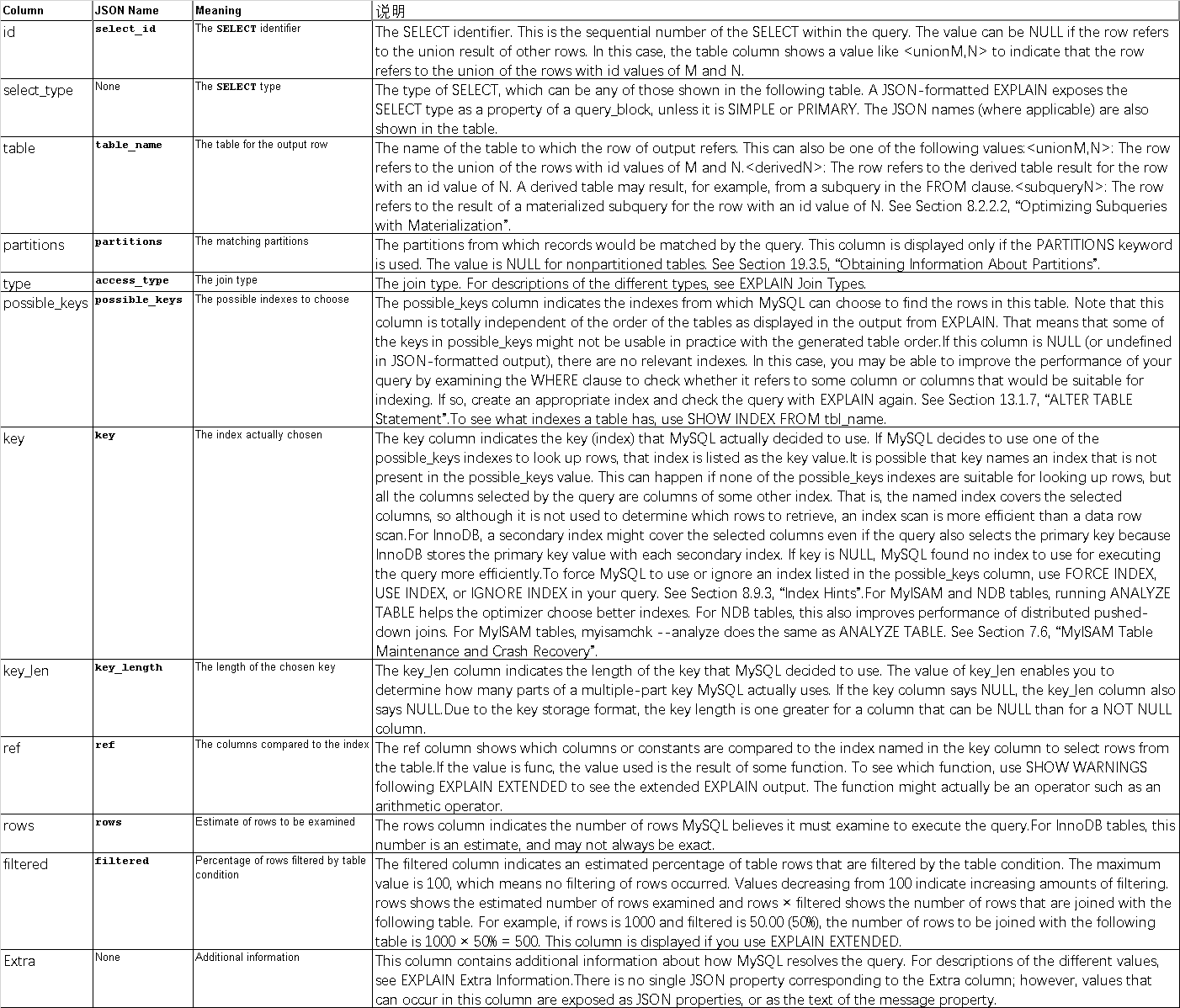
Each output row from EXPLAIN provides information about one table. Each row contains the values summarized in Table 8.1, “EXPLAIN Output Columns”, and described in more detail following the table. Column names are shown in the table's first column; the second column provides the equivalent property name shown in the output when FORMAT=JSON is used.
Table 8.1 EXPLAIN Output Columns
| Column | JSON Name | Meaning |
|---|---|---|
id |
select_id |
The SELECT identifier |
select_type |
None | The SELECT type |
table |
table_name |
The table for the output row |
partitions |
partitions |
The matching partitions |
type |
access_type |
The join type |
possible_keys |
possible_keys |
The possible indexes to choose |
key |
key |
The index actually chosen |
key_len |
key_length |
The length of the chosen key |
ref |
ref |
The columns compared to the index |
rows |
rows |
Estimate of rows to be examined |
filtered |
filtered |
Percentage of rows filtered by table condition |
Extra |
None | Additional information |
JSON properties which are NULL are not displayed in JSON-formatted EXPLAIN output.
-
The
SELECTidentifier. This is the sequential number of theSELECTwithin the query. The value can beNULLif the row refers to the union result of other rows. In this case, thetablecolumn shows a value like<unionto indicate that the row refers to the union of the rows withM,N>idvalues ofMandN. -
The type of
SELECT, which can be any of those shown in the following table. A JSON-formattedEXPLAINexposes theSELECTtype as a property of aquery_block, unless it isSIMPLEorPRIMARY. The JSON names (where applicable) are also shown in the table.select_typeValueJSON Name Meaning SIMPLENone Simple SELECT(not usingUNIONor subqueries)PRIMARYNone Outermost SELECTUNIONNone Second or later SELECTstatement in aUNIONDEPENDENT UNIONdependent(true)Second or later SELECTstatement in aUNION, dependent on outer queryUNION RESULTunion_resultResult of a UNION.SUBQUERYNone First SELECTin subqueryDEPENDENT SUBQUERYdependent(true)First SELECTin subquery, dependent on outer queryDERIVEDNone Derived table MATERIALIZEDmaterialized_from_subqueryMaterialized subquery UNCACHEABLE SUBQUERYcacheable(false)A subquery for which the result cannot be cached and must be re-evaluated for each row of the outer query UNCACHEABLE UNIONcacheable(false)The second or later select in a UNIONthat belongs to an uncacheable subquery (seeUNCACHEABLE SUBQUERY)DEPENDENTtypically signifies the use of a correlated subquery. See Section 13.2.10.7, “Correlated Subqueries”.DEPENDENT SUBQUERYevaluation differs fromUNCACHEABLE SUBQUERYevaluation. ForDEPENDENT SUBQUERY, the subquery is re-evaluated only once for each set of different values of the variables from its outer context. ForUNCACHEABLE SUBQUERY, the subquery is re-evaluated for each row of the outer context.Cacheability of subqueries differs from caching of query results in the query cache (which is described in Section 8.10.3.1, “How the Query Cache Operates”). Subquery caching occurs during query execution, whereas the query cache is used to store results only after query execution finishes.
When you specify
FORMAT=JSONwithEXPLAIN, the output has no single property directly equivalent toselect_type; thequery_blockproperty corresponds to a givenSELECT. Properties equivalent to most of theSELECTsubquery types just shown are available (an example beingmaterialized_from_subqueryforMATERIALIZED), and are displayed when appropriate. There are no JSON equivalents forSIMPLEorPRIMARY. -
The name of the table to which the row of output refers. This can also be one of the following values:
-
<union: The row refers to the union of the rows withM,N>idvalues ofMandN. -
<derived: The row refers to the derived table result for the row with anN>idvalue ofN. A derived table may result, for example, from a subquery in theFROMclause. -
<subquery: The row refers to the result of a materialized subquery for the row with anN>idvalue ofN. See Section 8.2.2.2, “Optimizing Subqueries with Materialization”.
-
-
partitions(JSON name:partitions)The partitions from which records would be matched by the query. This column is displayed only if the
PARTITIONSkeyword is used. The value isNULLfor nonpartitioned tables. See Section 19.3.5, “Obtaining Information About Partitions”. -
The join type. For descriptions of the different types, see
EXPLAINJoin Types. -
possible_keys(JSON name:possible_keys)The
possible_keyscolumn indicates the indexes from which MySQL can choose to find the rows in this table. Note that this column is totally independent of the order of the tables as displayed in the output fromEXPLAIN. That means that some of the keys inpossible_keysmight not be usable in practice with the generated table order.If this column is
NULL(or undefined in JSON-formatted output), there are no relevant indexes. In this case, you may be able to improve the performance of your query by examining theWHEREclause to check whether it refers to some column or columns that would be suitable for indexing. If so, create an appropriate index and check the query withEXPLAINagain. See Section 13.1.7, “ALTER TABLE Statement”.To see what indexes a table has, use
SHOW INDEX FROM.tbl_name -
The
keycolumn indicates the key (index) that MySQL actually decided to use. If MySQL decides to use one of thepossible_keysindexes to look up rows, that index is listed as the key value.It is possible that
keynames an index that is not present in thepossible_keysvalue. This can happen if none of thepossible_keysindexes are suitable for looking up rows, but all the columns selected by the query are columns of some other index. That is, the named index covers the selected columns, so although it is not used to determine which rows to retrieve, an index scan is more efficient than a data row scan.For
InnoDB, a secondary index might cover the selected columns even if the query also selects the primary key becauseInnoDBstores the primary key value with each secondary index. IfkeyisNULL, MySQL found no index to use for executing the query more efficiently.To force MySQL to use or ignore an index listed in the
possible_keyscolumn, useFORCE INDEX,USE INDEX, orIGNORE INDEXin your query. See Section 8.9.3, “Index Hints”.For
MyISAMandNDBtables, runningANALYZE TABLEhelps the optimizer choose better indexes. ForNDBtables, this also improves performance of distributed pushed-down joins. ForMyISAMtables, myisamchk --analyze does the same asANALYZE TABLE. See Section 7.6, “MyISAM Table Maintenance and Crash Recovery”. -
key_len(JSON name:key_length)The
key_lencolumn indicates the length of the key that MySQL decided to use. The value ofkey_lenenables you to determine how many parts of a multiple-part key MySQL actually uses. If thekeycolumn saysNULL, thekey_lencolumn also saysNULL.Due to the key storage format, the key length is one greater for a column that can be
NULLthan for aNOT NULLcolumn. -
The
refcolumn shows which columns or constants are compared to the index named in thekeycolumn to select rows from the table.If the value is
func, the value used is the result of some function. To see which function, useSHOW WARNINGSfollowingEXPLAIN EXTENDEDto see the extendedEXPLAINoutput. The function might actually be an operator such as an arithmetic operator. -
The
rowscolumn indicates the number of rows MySQL believes it must examine to execute the query.For
InnoDBtables, this number is an estimate, and may not always be exact. -
filtered(JSON name:filtered)The
filteredcolumn indicates an estimated percentage of table rows that are filtered by the table condition. The maximum value is 100, which means no filtering of rows occurred. Values decreasing from 100 indicate increasing amounts of filtering.rowsshows the estimated number of rows examined androws×filteredshows the number of rows that are joined with the following table. For example, ifrowsis 1000 andfilteredis 50.00 (50%), the number of rows to be joined with the following table is 1000 × 50% = 500. This column is displayed if you useEXPLAIN EXTENDED. -
This column contains additional information about how MySQL resolves the query. For descriptions of the different values, see
EXPLAINExtra Information.There is no single JSON property corresponding to the
Extracolumn; however, values that can occur in this column are exposed as JSON properties, or as the text of themessageproperty.
The type column of EXPLAIN output describes how tables are joined. In JSON-formatted output, these are found as values of the access_type property. The following list describes the join types, ordered from the best type to the worst:
-
The table has only one row (= system table). This is a special case of the
constjoin type. -
The table has at most one matching row, which is read at the start of the query. Because there is only one row, values from the column in this row can be regarded as constants by the rest of the optimizer.
consttables are very fast because they are read only once.constis used when you compare all parts of aPRIMARY KEYorUNIQUEindex to constant values. In the following queries,tbl_namecan be used as aconsttable:SELECT * FROM
tbl_nameWHEREprimary_key=1; SELECT * FROMtbl_nameWHEREprimary_key_part1=1 ANDprimary_key_part2=2; -
One row is read from this table for each combination of rows from the previous tables. Other than the
systemandconsttypes, this is the best possible join type. It is used when all parts of an index are used by the join and the index is aPRIMARY KEYorUNIQUE NOT NULLindex.eq_refcan be used for indexed columns that are compared using the=operator. The comparison value can be a constant or an expression that uses columns from tables that are read before this table. In the following examples, MySQL can use aneq_refjoin to processref_table:SELECT * FROM
ref_table,other_tableWHEREref_table.key_column=other_table.column; SELECT * FROMref_table,other_tableWHEREref_table.key_column_part1=other_table.columnANDref_table.key_column_part2=1; -
All rows with matching index values are read from this table for each combination of rows from the previous tables.
refis used if the join uses only a leftmost prefix of the key or if the key is not aPRIMARY KEYorUNIQUEindex (in other words, if the join cannot select a single row based on the key value). If the key that is used matches only a few rows, this is a good join type.refcan be used for indexed columns that are compared using the=or<=>operator. In the following examples, MySQL can use arefjoin to processref_table:SELECT * FROM
ref_tableWHEREkey_column=expr; SELECT * FROMref_table,other_tableWHEREref_table.key_column=other_table.column; SELECT * FROMref_table,other_tableWHEREref_table.key_column_part1=other_table.columnANDref_table.key_column_part2=1; -
The join is performed using a
FULLTEXTindex. -
This join type is like
ref, but with the addition that MySQL does an extra search for rows that containNULLvalues. This join type optimization is used most often in resolving subqueries. In the following examples, MySQL can use aref_or_nulljoin to processref_table:SELECT * FROM
ref_tableWHEREkey_column=exprORkey_columnIS NULL; -
This join type indicates that the Index Merge optimization is used. In this case, the
keycolumn in the output row contains a list of indexes used, andkey_lencontains a list of the longest key parts for the indexes used. For more information, see Section 8.2.1.3, “Index Merge Optimization”. -
This type replaces
eq_reffor someINsubqueries of the following form:valueIN (SELECTprimary_keyFROMsingle_tableWHEREsome_expr)unique_subqueryis just an index lookup function that replaces the subquery completely for better efficiency. -
This join type is similar to
unique_subquery. It replacesINsubqueries, but it works for nonunique indexes in subqueries of the following form:valueIN (SELECTkey_columnFROMsingle_tableWHEREsome_expr) -
Only rows that are in a given range are retrieved, using an index to select the rows. The
keycolumn in the output row indicates which index is used. Thekey_lencontains the longest key part that was used. Therefcolumn isNULLfor this type.rangecan be used when a key column is compared to a constant using any of the=,<>,>,>=,<,<=,IS NULL,<=>,BETWEEN,LIKE, orIN()operators:SELECT * FROM
tbl_nameWHEREkey_column= 10; SELECT * FROMtbl_nameWHEREkey_columnBETWEEN 10 and 20; SELECT * FROMtbl_nameWHEREkey_columnIN (10,20,30); SELECT * FROMtbl_nameWHEREkey_part1= 10 ANDkey_part2IN (10,20,30); -
The
indexjoin type is the same asALL, except that the index tree is scanned. This occurs two ways:-
If the index is a covering index for the queries and can be used to satisfy all data required from the table, only the index tree is scanned. In this case, the
Extracolumn saysUsing index. An index-only scan usually is faster thanALLbecause the size of the index usually is smaller than the table data. -
A full table scan is performed using reads from the index to look up data rows in index order.
Uses indexdoes not appear in theExtracolumn.
MySQL can use this join type when the query uses only columns that are part of a single index.
-
-
A full table scan is done for each combination of rows from the previous tables. This is normally not good if the table is the first table not marked
const, and usually very bad in all other cases. Normally, you can avoidALLby adding indexes that enable row retrieval from the table based on constant values or column values from earlier tables.
The Extra column of EXPLAIN output contains additional information about how MySQL resolves the query. The following list explains the values that can appear in this column. Each item also indicates for JSON-formatted output which property displays the Extra value. For some of these, there is a specific property. The others display as the text of the message property.
If you want to make your queries as fast as possible, look out for Extra column values of Using filesort and Using temporary, or, in JSON-formatted EXPLAIN output, for using_filesort and using_temporary_table properties equal to true.
-
Child of '(JSON:table' pushed join@1messagetext)This table is referenced as the child of
tablein a join that can be pushed down to the NDB kernel. Applies only in NDB Cluster, when pushed-down joins are enabled. See the description of thendb_join_pushdownserver system variable for more information and examples. -
const row not found(JSON property:const_row_not_found)For a query such as
SELECT ... FROM, the table was empty.tbl_name -
Deleting all rows(JSON property:message)For
DELETE, some storage engines (such asMyISAM) support a handler method that removes all table rows in a simple and fast way. ThisExtravalue is displayed if the engine uses this optimization. -
Distinct(JSON property:distinct)MySQL is looking for distinct values, so it stops searching for more rows for the current row combination after it has found the first matching row.
-
FirstMatch((JSON property:tbl_name)first_match)The semijoin FirstMatch join shortcutting strategy is used for
tbl_name. -
Full scan on NULL key(JSON property:message)This occurs for subquery optimization as a fallback strategy when the optimizer cannot use an index-lookup access method.
-
Impossible HAVING(JSON property:message)The
HAVINGclause is always false and cannot select any rows. -
Impossible WHERE(JSON property:message)The
WHEREclause is always false and cannot select any rows. -
Impossible WHERE noticed after reading const tables(JSON property:message)MySQL has read all
const(andsystem) tables and notice that theWHEREclause is always false. -
LooseScan((JSON property:m..n)message)The semijoin LooseScan strategy is used.
mandnare key part numbers. -
No matching min/max row(JSON property:message)No row satisfies the condition for a query such as
SELECT MIN(...) FROM ... WHERE.condition -
no matching row in const table(JSON property:message)For a query with a join, there was an empty table or a table with no rows satisfying a unique index condition.
-
No matching rows after partition pruning(JSON property:message)For
DELETEorUPDATE, the optimizer found nothing to delete or update after partition pruning. It is similar in meaning toImpossible WHEREforSELECTstatements. -
No tables used(JSON property:message)The query has no
FROMclause, or has aFROM DUALclause.For
INSERTorREPLACEstatements,EXPLAINdisplays this value when there is noSELECTpart. For example, it appears forEXPLAIN INSERT INTO t VALUES(10)because that is equivalent toEXPLAIN INSERT INTO t SELECT 10 FROM DUAL. -
Not exists(JSON property:message)MySQL was able to do a
LEFT JOINoptimization on the query and does not examine more rows in this table for the previous row combination after it finds one row that matches theLEFT JOINcriteria. Here is an example of the type of query that can be optimized this way:SELECT * FROM t1 LEFT JOIN t2 ON t1.id=t2.id WHERE t2.id IS NULL;
Assume that
t2.idis defined asNOT NULL. In this case, MySQL scanst1and looks up the rows int2using the values oft1.id. If MySQL finds a matching row int2, it knows thatt2.idcan never beNULL, and does not scan through the rest of the rows int2that have the sameidvalue. In other words, for each row int1, MySQL needs to do only a single lookup int2, regardless of how many rows actually match int2. -
Range checked for each record (index map:(JSON property:N)message)MySQL found no good index to use, but found that some of indexes might be used after column values from preceding tables are known. For each row combination in the preceding tables, MySQL checks whether it is possible to use a
rangeorindex_mergeaccess method to retrieve rows. This is not very fast, but is faster than performing a join with no index at all. The applicability criteria are as described in Section 8.2.1.2, “Range Optimization”, and Section 8.2.1.3, “Index Merge Optimization”, with the exception that all column values for the preceding table are known and considered to be constants.Indexes are numbered beginning with 1, in the same order as shown by
SHOW INDEXfor the table. The index map valueNis a bitmask value that indicates which indexes are candidates. For example, a value of0x19(binary 11001) means that indexes 1, 4, and 5 are considered. -
Scanned(JSON property:Ndatabasesmessage)This indicates how many directory scans the server performs when processing a query for
INFORMATION_SCHEMAtables, as described in Section 8.2.3, “Optimizing INFORMATION_SCHEMA Queries”. The value ofNcan be 0, 1, orall. -
Select tables optimized away(JSON property:message)The optimizer determined 1) that at most one row should be returned, and 2) that to produce this row, a deterministic set of rows must be read. When the rows to be read can be read during the optimization phase (for example, by reading index rows), there is no need to read any tables during query execution.
The first condition is fulfilled when the query is implicitly grouped (contains an aggregate function but no
GROUP BYclause). The second condition is fulfilled when one row lookup is performed per index used. The number of indexes read determines the number of rows to read.Consider the following implicitly grouped query:
SELECT MIN(c1), MIN(c2) FROM t1;
Suppose that
MIN(c1)can be retrieved by reading one index row andMIN(c2)can be retrieved by reading one row from a different index. That is, for each columnc1andc2, there exists an index where the column is the first column of the index. In this case, one row is returned, produced by reading two deterministic rows.This
Extravalue does not occur if the rows to read are not deterministic. Consider this query:SELECT MIN(c2) FROM t1 WHERE c1 <= 10;
Suppose that
(c1, c2)is a covering index. Using this index, all rows withc1 <= 10must be scanned to find the minimumc2value. By contrast, consider this query:SELECT MIN(c2) FROM t1 WHERE c1 = 10;
In this case, the first index row with
c1 = 10contains the minimumc2value. Only one row must be read to produce the returned row.For storage engines that maintain an exact row count per table (such as
MyISAM, but notInnoDB), thisExtravalue can occur forCOUNT(*)queries for which theWHEREclause is missing or always true and there is noGROUP BYclause. (This is an instance of an implicitly grouped query where the storage engine influences whether a deterministic number of rows can be read.) -
Skip_open_table,Open_frm_only,Open_full_table(JSON property:message)These values indicate file-opening optimizations that apply to queries for
INFORMATION_SCHEMAtables, as described in Section 8.2.3, “Optimizing INFORMATION_SCHEMA Queries”.-
Skip_open_table: Table files do not need to be opened. The information has already become available within the query by scanning the database directory. -
Open_frm_only: Only the table's.frmfile need be opened. -
Open_full_table: The unoptimized information lookup. The.frm,.MYD, and.MYIfiles must be opened.
-
-
Start temporary,End temporary(JSON property:message)This indicates temporary table use for the semijoin Duplicate Weedout strategy.
-
unique row not found(JSON property:message)For a query such as
SELECT ... FROM, no rows satisfy the condition for atbl_nameUNIQUEindex orPRIMARY KEYon the table. -
Using filesort(JSON property:using_filesort)MySQL must do an extra pass to find out how to retrieve the rows in sorted order. The sort is done by going through all rows according to the join type and storing the sort key and pointer to the row for all rows that match the
WHEREclause. The keys then are sorted and the rows are retrieved in sorted order. See Section 8.2.1.13, “ORDER BY Optimization”. -
Using index(JSON property:using_index)The column information is retrieved from the table using only information in the index tree without having to do an additional seek to read the actual row. This strategy can be used when the query uses only columns that are part of a single index.
For
InnoDBtables that have a user-defined clustered index, that index can be used even whenUsing indexis absent from theExtracolumn. This is the case iftypeisindexandkeyisPRIMARY. -
Using index condition(JSON property:using_index_condition)Tables are read by accessing index tuples and testing them first to determine whether to read full table rows. In this way, index information is used to defer (“push down”) reading full table rows unless it is necessary. See Section 8.2.1.5, “Index Condition Pushdown Optimization”.
-
Using index for group-by(JSON property:using_index_for_group_by)Similar to the
Using indextable access method,Using index for group-byindicates that MySQL found an index that can be used to retrieve all columns of aGROUP BYorDISTINCTquery without any extra disk access to the actual table. Additionally, the index is used in the most efficient way so that for each group, only a few index entries are read. For details, see Section 8.2.1.14, “GROUP BY Optimization”. -
Using join buffer (Block Nested Loop),Using join buffer (Batched Key Access)(JSON property:using_join_buffer)Tables from earlier joins are read in portions into the join buffer, and then their rows are used from the buffer to perform the join with the current table.
(Block Nested Loop)indicates use of the Block Nested-Loop algorithm and(Batched Key Access)indicates use of the Batched Key Access algorithm. That is, the keys from the table on the preceding line of theEXPLAINoutput are buffered, and the matching rows are fetched in batches from the table represented by the line in whichUsing join bufferappears.In JSON-formatted output, the value of
using_join_bufferis always either one ofBlock Nested LooporBatched Key Access.For more information about these algorithms, see Block Nested-Loop Join Algorithm, and Batched Key Access Joins.
-
Using MRR(JSON property:message)Tables are read using the Multi-Range Read optimization strategy. See Section 8.2.1.10, “Multi-Range Read Optimization”.
-
Using sort_union(...),Using union(...),Using intersect(...)(JSON property:message)These indicate the particular algorithm showing how index scans are merged for the
index_mergejoin type. See Section 8.2.1.3, “Index Merge Optimization”. -
Using temporary(JSON property:using_temporary_table)To resolve the query, MySQL needs to create a temporary table to hold the result. This typically happens if the query contains
GROUP BYandORDER BYclauses that list columns differently. -
Using where(JSON property:attached_condition)A
WHEREclause is used to restrict which rows to match against the next table or send to the client. Unless you specifically intend to fetch or examine all rows from the table, you may have something wrong in your query if theExtravalue is notUsing whereand the table join type isALLorindex.Using wherehas no direct counterpart in JSON-formatted output; theattached_conditionproperty contains anyWHEREcondition used. -
Using where with pushed condition(JSON property:message)This item applies to
NDBtables only. It means that NDB Cluster is using the Condition Pushdown optimization to improve the efficiency of a direct comparison between a nonindexed column and a constant. In such cases, the condition is “pushed down” to the cluster's data nodes and is evaluated on all data nodes simultaneously. This eliminates the need to send nonmatching rows over the network, and can speed up such queries by a factor of 5 to 10 times over cases where Condition Pushdown could be but is not used. For more information, see Section 8.2.1.4, “Engine Condition Pushdown Optimization”.
You can get a good indication of how good a join is by taking the product of the values in the rows column of the EXPLAIN output. This should tell you roughly how many rows MySQL must examine to execute the query. If you restrict queries with the max_join_size system variable, this row product also is used to determine which multiple-table SELECT statements to execute and which to abort. See Section 5.1.1, “Configuring the Server”.
The following example shows how a multiple-table join can be optimized progressively based on the information provided by EXPLAIN.
Suppose that you have the SELECT statement shown here and that you plan to examine it using EXPLAIN:
EXPLAIN SELECT tt.TicketNumber, tt.TimeIn,
tt.ProjectReference, tt.EstimatedShipDate,
tt.ActualShipDate, tt.ClientID,
tt.ServiceCodes, tt.RepetitiveID,
tt.CurrentProcess, tt.CurrentDPPerson,
tt.RecordVolume, tt.DPPrinted, et.COUNTRY,
et_1.COUNTRY, do.CUSTNAME
FROM tt, et, et AS et_1, do
WHERE tt.SubmitTime IS NULL
AND tt.ActualPC = et.EMPLOYID
AND tt.AssignedPC = et_1.EMPLOYID
AND tt.ClientID = do.CUSTNMBR;
For this example, make the following assumptions:
-
The columns being compared have been declared as follows.
Table Column Data Type ttActualPCCHAR(10)ttAssignedPCCHAR(10)ttClientIDCHAR(10)etEMPLOYIDCHAR(15)doCUSTNMBRCHAR(15) -
The tables have the following indexes.
Table Index ttActualPCttAssignedPCttClientIDetEMPLOYID(primary key)doCUSTNMBR(primary key) -
The
tt.ActualPCvalues are not evenly distributed.
Initially, before any optimizations have been performed, the EXPLAIN statement produces the following information:
table type possible_keys key key_len ref rows Extra
et ALL PRIMARY NULL NULL NULL 74
do ALL PRIMARY NULL NULL NULL 2135
et_1 ALL PRIMARY NULL NULL NULL 74
tt ALL AssignedPC, NULL NULL NULL 3872
ClientID,
ActualPC
Range checked for each record (index map: 0x23)
Because type is ALL for each table, this output indicates that MySQL is generating a Cartesian product of all the tables; that is, every combination of rows. This takes quite a long time, because the product of the number of rows in each table must be examined. For the case at hand, this product is 74 × 2135 × 74 × 3872 = 45,268,558,720 rows. If the tables were bigger, you can only imagine how long it would take.
One problem here is that MySQL can use indexes on columns more efficiently if they are declared as the same type and size. In this context, VARCHAR and CHAR are considered the same if they are declared as the same size. tt.ActualPC is declared as CHAR(10) and et.EMPLOYID is CHAR(15), so there is a length mismatch.
To fix this disparity between column lengths, use ALTER TABLE to lengthen ActualPC from 10 characters to 15 characters:
mysql> ALTER TABLE tt MODIFY ActualPC VARCHAR(15);
Now tt.ActualPC and et.EMPLOYID are both VARCHAR(15). Executing the EXPLAIN statement again produces this result:
table type possible_keys key key_len ref rows Extra
tt ALL AssignedPC, NULL NULL NULL 3872 Using
ClientID, where
ActualPC
do ALL PRIMARY NULL NULL NULL 2135
Range checked for each record (index map: 0x1)
et_1 ALL PRIMARY NULL NULL NULL 74
Range checked for each record (index map: 0x1)
et eq_ref PRIMARY PRIMARY 15 tt.ActualPC 1
This is not perfect, but is much better: The product of the rows values is less by a factor of 74. This version executes in a couple of seconds.
A second alteration can be made to eliminate the column length mismatches for the tt.AssignedPC = et_1.EMPLOYID and tt.ClientID = do.CUSTNMBR comparisons:
mysql>ALTER TABLE tt MODIFY AssignedPC VARCHAR(15),MODIFY ClientID VARCHAR(15);
After that modification, EXPLAIN produces the output shown here:
table type possible_keys key key_len ref rows Extra
et ALL PRIMARY NULL NULL NULL 74
tt ref AssignedPC, ActualPC 15 et.EMPLOYID 52 Using
ClientID, where
ActualPC
et_1 eq_ref PRIMARY PRIMARY 15 tt.AssignedPC 1
do eq_ref PRIMARY PRIMARY 15 tt.ClientID 1
At this point, the query is optimized almost as well as possible. The remaining problem is that, by default, MySQL assumes that values in the tt.ActualPC column are evenly distributed, and that is not the case for the tt table. Fortunately, it is easy to tell MySQL to analyze the key distribution:
mysql> ANALYZE TABLE tt;
With the additional index information, the join is perfect and EXPLAIN produces this result:
table type possible_keys key key_len ref rows Extra
tt ALL AssignedPC NULL NULL NULL 3872 Using
ClientID, where
ActualPC
et eq_ref PRIMARY PRIMARY 15 tt.ActualPC 1
et_1 eq_ref PRIMARY PRIMARY 15 tt.AssignedPC 1
do eq_ref PRIMARY PRIMARY 15 tt.ClientID 1
The rows column in the output from EXPLAIN is an educated guess from the MySQL join optimizer. Check whether the numbers are even close to the truth by comparing the rows product with the actual number of rows that the query returns. If the numbers are quite different, you might get better performance by using STRAIGHT_JOIN in your SELECT statement and trying to list the tables in a different order in the FROM clause. (However, STRAIGHT_JOIN may prevent indexes from being used because it disables semijoin transformations. See Section 8.2.2.1, “Optimizing Subqueries with Semijoin Transformations”.)
It is possible in some cases to execute statements that modify data when EXPLAIN SELECT is used with a subquery; for more information, see Section 13.2.10.8, “Derived Tables”.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号