
python-unnitest无法按照顺序执行excel文件中测试用例问题解决
根据排序规则,unittest执行测试用例,默认是根据ASCII码的顺序加载测试用例,数字与字母的顺序为:0-9,A-Z,a-z。
file = excel_data.get_xls('filetest.xlsx', 'test')
@paramunittest.parametrized(*file)
执行得到的结果排序是0,1,10,11,12,13,14,15,16,17,18,19,2,20,21.。。。。
由此顺序,用例执行的时候排序就是按照0,1,10,11,12,13,14,15,16,17,18,19,2,20,21。。。。的顺序来执行的,所以1-10的用例排序有问题
那么,怎么来解决这个问题呢?首先我们想到的最简单、不改变代码框架的方法是能否用例返回的名称如果小于10的情况下,不是1,2,3,5,6。。。而是01,02,03,04,05.。。。,这样问题也就解决了
因为用到的是parametrized这个方法,我们来分析一下:
我们找到排序编号这里的方法:
def _build_name(name, index):
return '%s_%d' % (name, index)
对这个方法进行修改,修改后的代码如下:
![]()
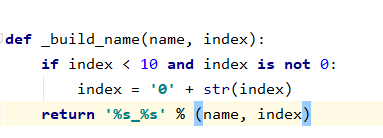
def _build_name(name, index):
if index < 10 and index is not 0:
index = '0' + str(index)
return '%s_%s' % (name, index)
这样执行下来就解决了执行顺序不对的问题。
同理,如果遇到了三位数的用例排序问题,也可以自己改造这个方法来实现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号