

spark中的算子分为两类: [or 三类 ]
说明:RDD一旦创建不能修改,但是可以使用算子让一个RDD转换成新的RDD,这个过程的所有操作都要基于算子进行操作。
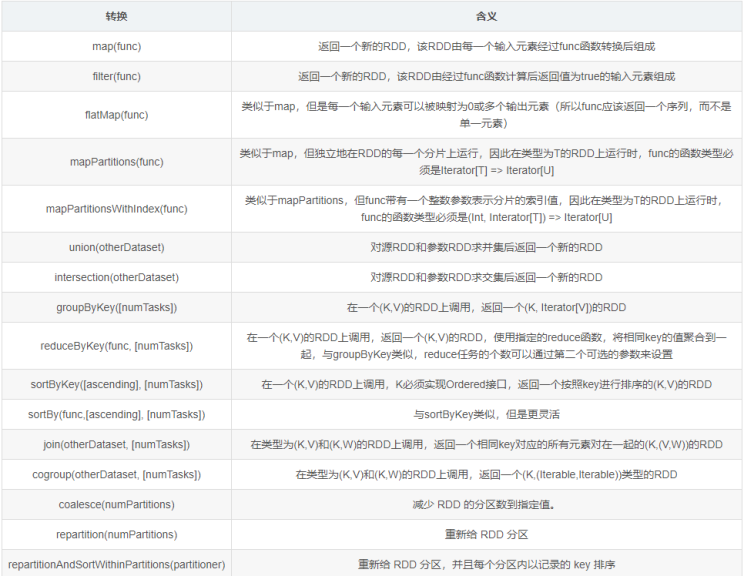
1、transformation 转换类
根据数据集创建一个新的数据集,计算后返回一个新RDD;例如:一个rdd进行map操作后生了一个新的rdd。
RDD中的所有转换都是延迟加载的,也就是说,它们并不会直接计算结果。相反的,它们只是记住每个RDD之间的转换动作。只有当发生一个要求返回结果给Driver的动作时,这些转换才会真正运行。这种设计的优点是让Spark更加有效率地运行。
2、action 行动类
立即执行,不会生成新的RDD.如果没有行动类算子,那么程序只会被加载[读取]不会被执行。
程序遇见action(行动)就会执行,不会转换为新的RDD,代表一个任务的结尾,不是一个应用的结尾。action算子只能将RDD的数据进行打印,收集到Driver端或者存储到其他介质中。
所以程序执行RDD的时候如果触发action算子,那么就会触发 SparkContext 提交 Job 作业,这就是就是action算子。

3、控制类算子
Spark中控制算子也是懒执行的,需要Action算子触发才能执行,主要是为了对数据进行缓存。当有Action算子出现时,他才会真正的执行
其中延迟计算就是懒执行的意思,就像是创建了一个视图,他并不是把查询好的数据放入视图了,而是当你需要这些数据时,查看视图时,他才执行定义视图时候的SQL语句。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号