


一、收获
1.这是假期的第四周,主要学习了python爬虫的一些基础知识。
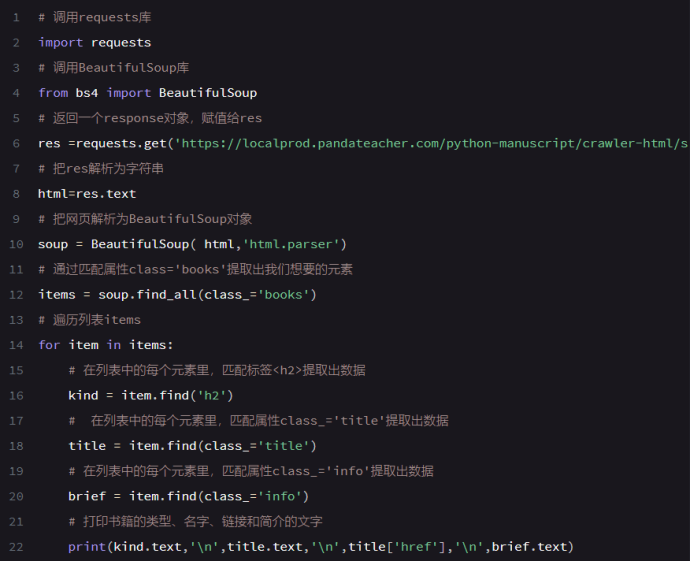
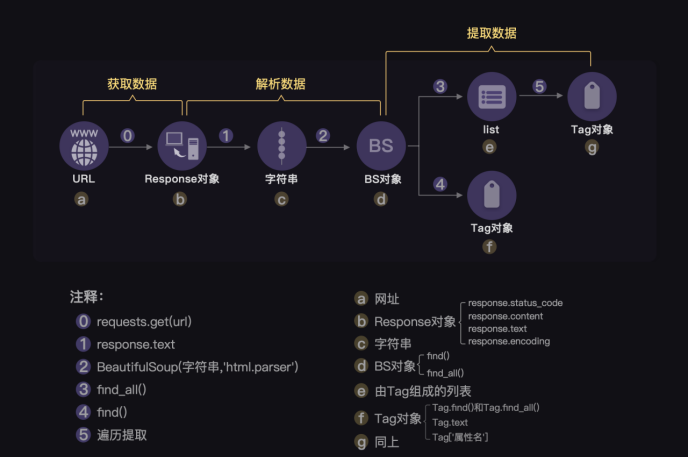
实例:爬取http://www.xiachufang.com/explore/的菜名
# 引用requests库 import requests # 引用BeautifulSoup库 from bs4 import BeautifulSoup # 获取数据 res_foods = requests.get('http://www.xiachufang.com/explore/') # 解析数据 bs_foods = BeautifulSoup(res_foods.text,'html.parser') # 查找包含菜名和URL的<p>标签 tag_name = bs_foods.find_all('p',class_='name') # 查找包含食材的<p>标签 tag_ingredients = bs_foods.find_all('p',class_='ing ellipsis') # 创建一个空列表,用于存储信息 list_all = [] # 启动一个循环,次数等于菜名的数量 for x in range(len(tag_name)): # 提取信息,封装为列表。此处[18:-14]切片的主要功能是切掉空格 list_food = [tag_name[x].text[18:-14],tag_name[x].find('a')['href'],tag_ingredients[x].text[1:-1]] # 将信息添加进list_all list_all.append(list_food) # 打印 print(list_all)
2.每天主要花费1个小时来学习,并且会根据当天学习任务的多少与难度进行调整。
二、下周目标
下周学习大型数据库的相关知识
三、遇到问题
不能爬取特定条件的网页。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号