
第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC

2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
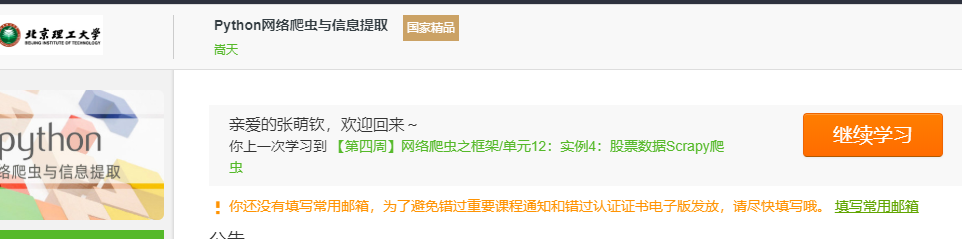
3.学习完成第0周至第4周的课程内容,并完成各周作业



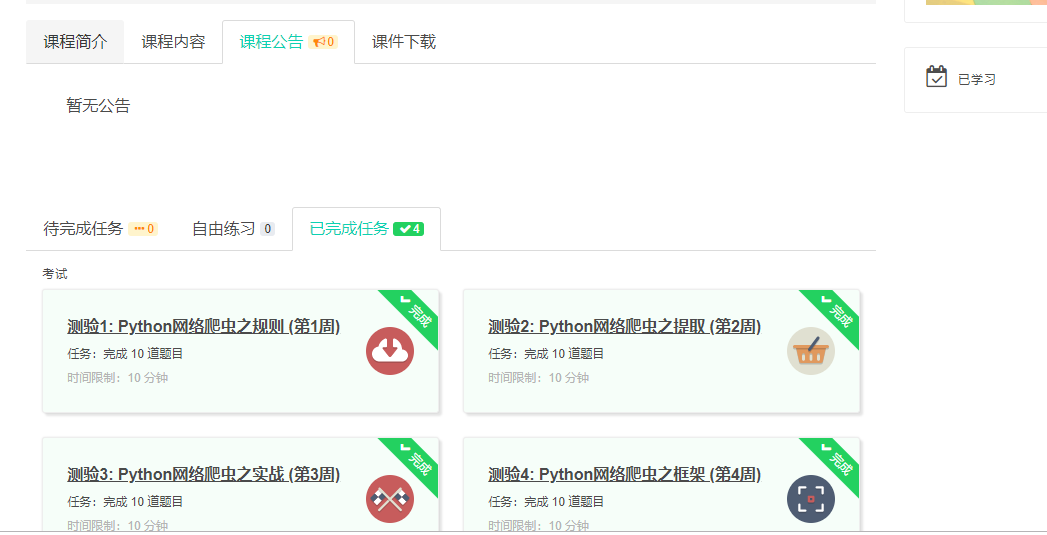
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
通过老师的介绍,接触了“中国大学生MOOC”这个网站,在上面学习了“python网络爬虫与信息提取”,因为以前学过HTML的内容,所以对爬虫这一块的知识不是特别的陌生,所以在观看视频和做习题学习时,比较容易理解。通过学习了前四周的知识,也有了一点感想分享。
这四周的课程是关于爬虫知识的,所以我也是第一次知道了什么是爬虫, 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。通俗一点说就是爬取某个网站上的你想要的某些数据,然后保存起来。爬虫分为五个基本构架:调度器,URL管理器,网页下载器,网页解析器,数据存储器。对爬虫有了比较清晰的认识,不再是对他只有一个模糊的概念。也学习到了爬取网页的过程:发送请求和获取相应,对获取的response进行想要的信息的提取,对信息进行存储。激发了对学习python的乐趣。也基本掌握了定向数据爬取和网页解析的基本能力。也了解了对其他数据进行爬虫的步骤,和爬虫时需要注意的事项。也懂得了为什么要了解和学习爬虫,它给我们的工作带来了多大的便捷。只要掌握的爬取方法,无论工作量有多么大都可以按你的心思去收集想要的数据了,这会极大的减轻我们的工作量。
如果我们需要大量的从网上请求数据,在以前没有接触爬虫的时候,我们只能依靠人工一个个得机械操作,但是这样特别浪费时间,显然是不现实的,当我们接触了爬虫后,我们就可以发挥爬虫的作用了,它会让这一切变得十分简单。在学习爬虫的过程中,我们也会遇到各种各样的情况:直接加载资源无处理,使用ajax异步加载,带参数验证的加载,cookie验证,登录验证,js加密。这些情况都会促进我们的思考,牵引着我们越来越进步,对爬虫的理解更加的深入。也更懂得了Python有很多优点,利用python写爬虫程序比较简洁,高效。python含有第三方urllib库,一个最基本的网络请求库,是用来写爬虫的好工具。学习用Python语言爬虫必须要对python的基本语法规则要有一定的了解。对爬虫的知识越来越熟悉后也知道了,用爬虫爬取网站,需要听取网站的爬虫协议,有的可以爬,有的不能爬。在网站的域名后面加上robots.txt。如果出现404,可以随心所欲爬取。
生活在现在网络越来越发达的时代,网上的数据对我们来说至关重要,所以对爬虫的学习必不可少,这次也是第一次系统全面的了解了爬虫,我想我会一直的坚持下去,毕竟python爬虫工程师这个工作资源也是很多的。对于自己现在所学的专业,多学了这门课程只有好处没有坏处,相信这也会对我找工作和今后的工作中有非常大的帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号