操作系统,进程和线程
操作系统介绍
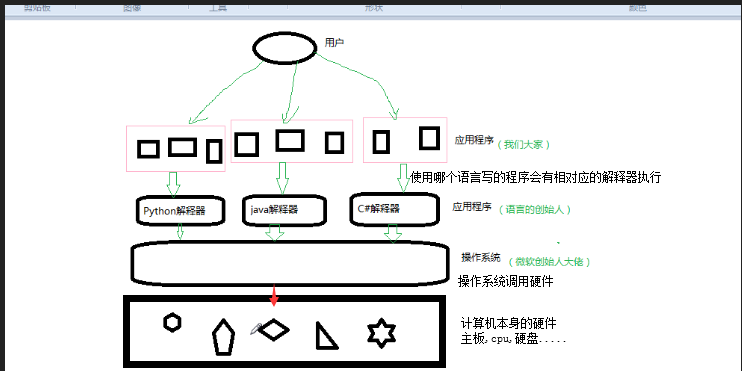
细分的话,操作系统应该分成两部分功能:
#一:隐藏了丑陋的硬件调用接口,为应用程序员提供调用硬件资源的更好,更简单,更清晰的模型(系统调用接口)。应用程序员有了这些接口后,就不用再考虑操作硬件的细节,专心开发自己的应用程序即可。
例如:操作系统提供了文件这个抽象概念,对文件的操作就是对磁盘的操作,有了文件我们无需再去考虑关于磁盘的读写控制(比如控制磁盘转动,移动磁头读写数据等细节),
#二:将应用程序对硬件资源的竞态请求变得有序化
例如:很多应用软件其实是共享一套计算机硬件,比方说有可能有三个应用程序同时需要申请打印机来输出内容,那么a程序竞争到了打印机资源就打印,然后可能是b竞争到打印机资源,也可能是c,这就导致了无序,打印机可能打印一段a的内容然后又去打印c...,操作系统的一个功能就是将这种无序变得有序。
进程
什么是进程
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础.在早期面向进程设计的计算机结构中,进程是程序的基本执行实体:在当代面向线程设计的计算机结构中,进程是线程的容器.程序是指令,数据及其组织形式的描述,进程是程序的实体.
注意 : 同一个程序执行两次,就会在操作系统中出现两个进程,所以我们可以同时运行一个软件,分别做不同的事情也不会混乱.
进程的并行与并发
并行 : 并行指两者同时进行 , 比如跑赛,两个人都在不停的向前跑 : (资源够用)
并发 : 并发指在资源有限的情况下,两者交替轮流使用资源.比如一张大饼(单核CPU),两个人都非常饿,但是吃的时候只能有一个人吃,那么就是A吃一口,让给B,B再吃一口然给A,交替使用,目的是提高效率.
区别 :
并行 : 并行是从微观上,也就是说在一个精确的时间片刻,有不同的程序在执行,这就要求必须有多个处理器
并发 : 并发是从宏观上,在一个时间段里可以看出是同时执行的,比如一个服务器同时处理多个程序.(比如,一遍看视频,一遍聊天.)
Python中的进程操作


在Windows操作系统中由于没有fork(linux操作系统中创建进程的机制),在创建子进程的时候会自动 import 启动它的这个文件,而在 import 的时候又执行了整个文件。因此如果将process()直接写在文件中就会无限递归创建子进程报错。所以必须把创建子进程的部分使用if __name__ ==‘__main__’ 判断保护起来,import 的时候 ,就不会递归运行了。
进程的创建
1 p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置 2 p.name:进程的名称 3 p.pid:进程的pid / ident---进程的id 4 p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可) 5 p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解即可) 6 p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
基本操作
import multiprocessing def func(arg): print(arg) if __name__ == '__main__': for i in range(10): t = multiprocessing.Process(target=func,args=(i,)) t.start()
● 进程间的数据不共享
import multiprocessing li = [] def func(arg): li.append(arg) print(li) def run(): for i in range(10): t = multiprocessing.Process(target=func,args=(i,)) t.start() if __name__ == '__main__': run() 结果: 每一个数都是一个进程 [0] [1] [2] [3] [4] [5] [6] [7] [8] [9]
● 进程通用功能 -- name
import multiprocessing import time def func(arg): time.sleep(2) print(arg) def run(): print("666") p1 = multiprocessing.Process(target=func,args=(1,)) # p1.name = "pig" #进程名称 # print(p1.name) p1.start() print("888") p2 = multiprocessing.Process(target=func,args=(2,)) # p2.name = "dog" p2.start() print("999") if __name__ == '__main__': run()
●开发者可以控制主进程等待子进程(最多等待时间) join()
import multiprocessing import time def func(arg): time.sleep(5) print(arg) def run(): print("666") p1 = multiprocessing.Process(target=func,args=(1,)) p1.start() # p1.join(1) print("888") p1.join(1) p2 = multiprocessing.Process(target=func,args=(2,)) p2.start() # p1.join(1) print("999") p2.join(1) if __name__ == '__main__': run() 结果: 666 888 #2秒后 999 #5秒后 1 2
注意:join() :
无参数,让主线程在这里等着,等到子线程t1执行完毕,才可以继续往下走。
有参数,让主线程在这里最多等待n秒,无论是否执行完毕,会继续往下走。
● 守护进程 Daemon
会随着主进程的结束而结束
主进程创建守护进程
其一:守护进程会在主进程代码执行结束后就终止
其二:守护进程内无法再开启子进程,否则抛出异常:AssertionError: daemonic processes are not allowed to have children
注意:进程之间是互相独立的,主进程代码运行结束,守护进程随即终止
import os import time from multiprocessing import Process class Myprocess(Process): def __init__(self,person): super().__init__() self.person = person def run(self): print(os.getpid(),self.name) print('%s正在和女主播聊天' %self.person) p=Myprocess('托塔') p.daemon=True #一定要在p.start()前设置,设置p为守护进程,禁止p创建子进程,并且父进程代码执行结束,p即终止运行 p.start() time.sleep(10) # 在sleep时查看进程id对应的进程ps -ef|grep id print('主')
import multiprocessing import time def func(arg): time.sleep(5) print(arg) def run(): print("666") p1 = multiprocessing.Process(target=func,args=(1,)) #daemon 也可以放这里 p1.daemon = True p1.start() print("888") p2 = multiprocessing.Process(target=func,args=(2,)) p2.daemon = True p2.start() print("999") if __name__ == '__main__': run()
● 获取id pid / ident
import multiprocessing import time def func(arg): time.sleep(5) print(arg) def run(): print("666") p1 = multiprocessing.Process(target=func,args=(1,)) p1.start() print(p1.pid) p2 = multiprocessing.Process(target=func,args=(2,)) p2.start() print(p2.pid) if __name__ == '__main__': run() 结果: 666 4808 15240 1 2
类继承的方式
class MyProcess(multiprocessing.Process): def run(self): print('当前进程',multiprocessing.current_process()) def run(): p1 = MyProcess() p1.start() p2 = MyProcess() p2.start() if __name__ == '__main__': run() 结果: 当前进程 <MyProcess(MyProcess-1, started)> 当前进程 <MyProcess(MyProcess-2, started)>
进程间的数据共享
Queue
创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递.
Queue([maxsize])
创建共享的进程队列。
参数 :maxsize是队列中允许的最大项数。如果省略此参数,则无大小限制。
底层队列使用管道和锁定实现。
Queue([maxsize])
创建共享的进程队列。maxsize是队列中允许的最大项数。如果省略此参数,则无大小限制。底层队列使用管道和锁定实现。另外,还需要运行支持线程以便队列中的数据传输到底层管道中。
Queue的实例q具有以下方法:
q.get( [ block [ ,timeout ] ] )
返回q中的一个项目。如果q为空,此方法将阻塞,直到队列中有项目可用为止。block用于控制阻塞行为,默认为True. 如果设置为False,将引发Queue.Empty异常(定义在Queue模块中)。timeout是可选超时时间,用在阻塞模式中。如果在制定的时间间隔内没有项目变为可用,将引发Queue.Empty异常。
q.get_nowait( )
同q.get(False)方法。
q.put(item [, block [,timeout ] ] )
将item放入队列。如果队列已满,此方法将阻塞至有空间可用为止。block控制阻塞行为,默认为True。如果设置为False,将引发Queue.Empty异常(定义在Queue库模块中)。timeout指定在阻塞模式中等待可用空间的时间长短。超时后将引发Queue.Full异常。
q.qsize()
返回队列中目前项目的正确数量。此函数的结果并不可靠,因为在返回结果和在稍后程序中使用结果之间,队列中可能添加或删除了项目。在某些系统上,此方法可能引发NotImplementedError异常。
q.empty()
如果调用此方法时 q为空,返回True。如果其他进程或线程正在往队列中添加项目,结果是不可靠的。也就是说,在返回和使用结果之间,队列中可能已经加入新的项目。
q.full()
如果q已满,返回为True. 由于线程的存在,结果也可能是不可靠的(参考q.empty()方法)。。
方法介绍
示例 :
import multiprocessing q = multiprocessing.Queue() def task(arg, q): q.put(arg) def run(): for i in range(10): p = multiprocessing.Process(target=task, args=(i, q,)) p.start() while True: v = q.get() print(v) run()
import multiprocessing def task(arg, q): q.put(arg) if __name__ == '__main__': q = multiprocessing.Queue() for i in range(10): p = multiprocessing.Process(target=task, args=(i, q,)) p.start() while True: v = q.get() print(v) 结果: 0 1 2 3 4 5 6 7 8 9
Manager ***
进程间数据是独立的,可以借助于队列或管道实现通信,二者都是基于消息传递的 虽然进程间数据独立,但可以通过Manager实现数据共享,事实上Manager的功能远不止于此 A manager object returned by Manager() controls a server process which holds Python objects and allows other processes to manipulate them using proxies. A manager returned by Manager() will support types list, dict, Namespace, Lock, RLock, Semaphore, BoundedSemaphore, Condition, Event, Barrier, Queue, Value and Array.
示例 :
import multiprocessing import time def task(arg, dic): time.sleep(2) dic[arg] = 100 if __name__ == '__main__': m = multiprocessing.Manager() dic = m.dict() process_list = [] for i in range(10): p = multiprocessing.Process(target=task, args=(i, dic,)) p.start() process_list.append(p) while True: count = 0 for p in process_list: if not p.is_alive(): count += 1 if count == len(process_list): break print(dic) 结果: {0: 100, 1: 100, 2: 100, 3: 100, 4: 100, 5: 100, 6: 100, 7: 100, 8: 100, 9: 100}
import multiprocessing m = multiprocessing.Manager() dic = m.dict() def task(arg): dic[arg] = 100 def run(): for i in range(10): p = multiprocessing.Process(target=task, args=(i,)) p.start() input('>>>') print(dic.values()) if __name__ == '__main__': run()
进程锁
进程锁与线程锁的方法是一样的,也是有Lock , RLock , Semaphore , Event , Condition.
RLock
import time import threading import multiprocessing lock = multiprocessing.RLock() def task(arg): print("我真帅") lock.acquire() time.sleep(2) print(arg) lock.release() if __name__ == '__main__': p1 = multiprocessing.Process(target=task,args=(1,)) p1.start() p2 = multiprocessing.Process(target=task, args=(2,)) p2.start() 结果: 我真帅 我真帅 1 2
进程池
为什么要有进程池?进程池的概念。
在程序实际处理问题过程中,忙时会有成千上万的任务需要被执行,闲时可能只有零星任务。那么在成千上万个任务需要被执行的时候,我们就需要去创建成千上万个进程么?首先,创建进程需要消耗时间,销毁进程也需要消耗时间。第二即便开启了成千上万的进程,操作系统也不能让他们同时执行,这样反而会影响程序的效率。因此我们不能无限制的根据任务开启或者结束进程。那么我们要怎么做呢?
定义一个池子,在里面放上固定数量的进程,有需求来了,就拿一个池中的进程来处理任务,等到处理完毕,进程并不关闭,而是将进程再放回进程池中继续等待任务。如果有很多任务需要执行,池中的进程数量不够,任务就要等待之前的进程执行任务完毕归来,拿到空闲进程才能继续执行。也就是说,池中进程的数量是固定的,那么同一时间最多有固定数量的进程在运行。这样不会增加操作系统的调度难度,还节省了开闭进程的时间,也一定程度上能够实现并发效果。
import time from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor def task(arg): time.sleep(2) print(arg) if __name__ == '__main__': pool = ProcessPoolExecutor(5) for i in range(10): pool.submit(task,i) 结果: #2秒后 0 2 1 3 4 #2秒后 5 7 6 8 9
所以,我们可以利用进程池,写一个小爬虫的实例:
import re from urllib.request import urlopen from multiprocessing import Pool def get_page(url,pattern): response=urlopen(url).read().decode('utf-8') return pattern,response def parse_page(info): pattern,page_content=info res=re.findall(pattern,page_content) for item in res: dic={ 'index':item[0].strip(), 'title':item[1].strip(), 'actor':item[2].strip(), 'time':item[3].strip(), } print(dic) if __name__ == '__main__': regex = r'<dd>.*?<.*?class="board-index.*?>(\d+)</i>.*?title="(.*?)".*?class="movie-item-info".*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>' pattern1=re.compile(regex,re.S) url_dic={ 'http://maoyan.com/board/7':pattern1, } p=Pool() res_l=[] for url,pattern in url_dic.items(): res=p.apply_async(get_page,args=(url,pattern),callback=parse_page) res_l.append(res) for i in res_l: i.get()
线程
进程
程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称之为进程。程序和进程的区别就在于:程序是指令的集合,它是进程运行的静态描述文本;进程是程序的一次执行活动,属于动态概念。在多道编程中,我们允许多个程序同时加载到内存中,在操作系统的调度下,可以实现并发地执行。这是这样的设计,大大提高了CPU的利用率。进程的出现让每个用户感觉到自己独享CPU,因此,进程就是为了在CPU上实现多道编程而提出的。
线程的出现原因
进程有很多优点,它提供了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机的利用率。但是进程还是有很多缺陷的,主要体现在两点上:
-
进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
-
进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行
比如:如果把我们在写代码的时候想要写代码的时候可以听歌和聊天.但是如果只是提供进程这个机制的话,那么我们就只能写完代码,在听歌,然后再聊天,不能再同时进行.
所以我们要解决这个问题,我们完全可以让写代码,听歌,聊天三个独立的过程,并行起来,这样很明显可以提高效率。而实际的操作系统中,也同样引入了这种类似的机制——线程。
线程的出现
线程和进程的关系
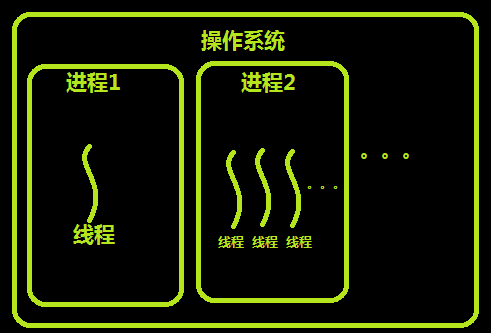
线程与进程的区别 :
● 地址空间和其他资源(比如打开文件) : 进程之间相互独立,同一进程的各线程之间共享资源.某进程内的线程和其他进程内的线程是不可见的.
● 通信 : 进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信(--需要进程同步和互斥手段的辅助,以保证数据的一致性).
● 调度和切换 : 线程上下文切换比进程上下文切换要快的多.
● 在多线程操作系统中,进程不是一个可执行的实体.
进程和线程的区别(面试):
1.进程是CPU分配的最小单元.
线程是CPU计算的最先单元.
2.一个进程可以有多个线程.
3.对于Python来说,它的进程和线程和其他语言有差异,是有GIL锁的
GIL锁保证一个进程中同一时刻只有一个线程被CPU调度.
线程的特点
在多线程的操作系统中,通常是在一个进程中包括多个线程,每一个线程都是作为利用CPU的基本单元,是花费最小开销的实体.
线程的属性 :
● 轻型实体
线程上的实体基本上不拥有系统资源,只是有一点必不可少的,能保证独立运行的资源.
线程的实体包括程序,数据和TCB.线程是动态概念,他的动态特性由线程控制块TCB描述.
TCB包括以下信息: (1)线程状态。 (2)当线程不运行时,被保存的现场资源。 (3)一组执行堆栈。 (4)存放每个线程的局部变量主存区。 (5)访问同一个进程中的主存和其它资源。 用于指示被执行指令序列的程序计数器、保留局部变量、少数状态参数和返回地址等的一组寄存器和堆栈。
● 独立调度和分派的基本单位.
在多线程OS中,线程是能独立运行的最小单位,因而也是独立调度和分派的基本单位,由于现场很"轻",故线程的切换非常迅速且开销小(在同一进程中的线程.)
● 共享进程资源
线程在同一进程中的各个线程,都可以共享该进程所拥有的资源,这首先表现在 : 所有线程都具有相同的进程id,意味着,线程可以访问该进程的每一个内存资源:此外,还可以访问进程所拥有的已经打开文件,定时器,信号量机构等.由于同一个进程内的线程共享内存和文件,所有线程直接互相通信不必调用内核.
● 可并发执行
在同一个进程的多个线程之间,可以并发执行,甚至允许在一个进程中所有线程都能并发执行:同样,不同进程中的线程也能并发执行,充分利用和发挥了处理机制与外围设备并行工作的能力.
使用线程的实际场景
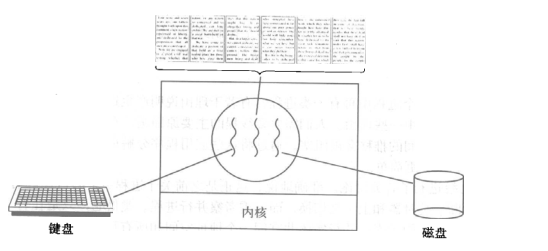
开启一个字处理软件进程,该进程肯定需要办不止一件事情,比如监听键盘输入,处理文字,定时自动将文字保存到硬盘,这三个任务操作的都是同一块数据,因而不能用多进程。只能在一个进程里并发地开启三个线程,如果是单线程,那就只能是,键盘输入时,不能处理文字和自动保存,自动保存时又不能输入和处理文字。
Python中的线程
Python中自己是没有线程和进程的,Python是调用操作系统中的线程和进程.
全局解释器---GIL锁
Python代码的执行由Python虚拟机(也叫解释器主循环)来控制。Python在设计之初就考虑到要在主循环中,同时只有一个线程在执行。虽然 Python 解释器中可以“运行”多个线程,但在任意时刻只有一个线程在解释器中运行。
对Python虚拟机的访问由全局解释器锁(GIL)来控制,所以,GIL锁的作用就是保证一个进程中在同一时刻只要一个线程可以运行(被CPU调度).
注意 : 默认GIL锁在执行100个CPU指令后换另外一个线程执行.
所以 , 由于在Python中存在一个GIL锁:
---导致 : 多线程无法利用多核的优势
---解决 : 开多进程处理(浪费资源)
线程的创建
#基本使用 import threading def func(arg): print(arg) t = threading.Thread(target=func,args=(112,)) #子线程 t.start() print(123) #主线程 结果: 112 123
● 主线程默认等子线程执行完毕
import threading import time def func(arg): time.sleep(arg) print(arg) t1 = threading.Thread(target=func,args=(1,)) t1.start() t2 = threading.Thread(target=func,args=(3,)) t2.start() print("我真帅") 结果: 我真帅 #1秒后 1 #3秒后 3
● 主线程不再等,主线程终止则所以线程终止 setDaemon()
import threading import time def func(arg): time.sleep(2) print(arg) t1 = threading.Thread(target=func,args=(3,)) t1.setDaemon(True) #使主线程不等子线程 t1.start() t2 = threading.Thread(target=func,args=(5,)) t2.setDaemon(True) t2.start() print("我真帅")
●开发者可以控制主线程等待子线程(最多等待时间) join()
import threading import time def func(arg): time.sleep(arg) print(arg) print("我是有多帅") t1 = threading.Thread(target=func,args=(3,)) t1.start() t1.join() print("非常帅") t2 = threading.Thread(target=func,args=(5,)) t2.start() t2.join() print("大实话") 结果: 我是有多帅 #3秒后 3 非常帅 #5秒后 5 大实话
import threading import time def func(arg): time.sleep(arg) print(arg) print("我是有多帅") t1 = threading.Thread(target=func,args=(5,)) t1.start() t1.join(2) print("非常帅") t2 = threading.Thread(target=func,args=(9,)) t2.start() t2.join(2) print("大实话") 结果: 我是有多帅 #2秒后 非常帅 #2秒后 大实话 #5秒后(和大实话差1秒) 5 #9秒后 9
注意:join() :
无参数,让主线程在这里等着,等到子线程t1执行完毕,才可以继续往下走。
有参数,让主线程在这里最多等待n秒,无论是否执行完毕,会继续往下走。
● 线程名称 srtName()
import threading def func(arg): # 获取当前执行该函数的线程的对象 t = threading.current_thread() # 根据当前线程对象获取当前线程名称 name = t.getName() print(name,arg) t1 = threading.Thread(target=func,args=(11,)) t1.setName("张三") #使线程有名称 t1.start() t2 = threading.Thread(target=func,args=(22,)) t2.setName('李四') t2.start() print(123)
● 线程本质
import threading def func(arg): print(arg) t1 = threading.Thread(target=func,args=(66,)) t1.start() # start 是开始运行线程吗?不是 # start 告诉cpu,我已经准备就绪,你可以调度我了。 print("我好看") 结果: 66 我好看
● 面向对象的多线程
import threading 线程方式:1 (常见) def func(arg): print(arg) t1 = threading.Thread(target=func,args=(11,)) t1.start() # 多线程方式:2 class MyThread(threading.Thread): def run(self): print(11111,self._args,self._kwargs) t1 = MyThread(args=(11,)) t1.start() t2 = MyThread(args=(22,)) t2.start() print('end')
● IO操作
import threading import requests import uuid url_list = [ 'https://www3.autoimg.cn/newsdfs/g28/M05/F9/98/120x90_0_autohomecar__ChsEnluQmUmARAhAAAFES6mpmTM281.jpg', 'https://www2.autoimg.cn/newsdfs/g28/M09/FC/06/120x90_0_autohomecar__ChcCR1uQlD6AT4P3AAGRMJX7834274.jpg', 'https://www2.autoimg.cn/newsdfs/g3/M00/C6/A9/120x90_0_autohomecar__ChsEkVuPsdqAQz3zAAEYvWuAspI061.jpg', ] def task(url): ret = requests.get(url) file_name = str(uuid.uuid4()) + '.jpg' with open(file_name, mode='wb') as f: f.write(ret.content) for url in url_list: t = threading.Thread(target=task,args=(url,)) t.start()
总结 :
1.Python中存在一个GIL锁。
---造成:多线程无法利用多核优势
---解决:开多进程处理(浪费资源)
2.IO密集型(文件的输入/输出/socket网络通信) : 多线程 (不占用CPU)
计算密集型 : 多进程
3.为什么Python有GIL锁?
答 : Python语言创始人在开发这门语言时,目的是快速把语言开发出来,如果加上GIL锁(C语言加锁),切换时按照100条字节指令来进行线程间的切换.
4.线程创建的越多越好吗?
答:不好,线程之间进行切换时,要做上下文处理.
锁
同步锁 Lock(一次放一个)
线程安全:多线程操作时,内部会让所有线程排队处理.如:list / dict / Queue
线程不安全 + 人 => 排队处理
创建100个线程 v = [] 加锁 -把自己的添加到列表中.安全的 -读取列表的最后一个.最后一个就不一定是自己的了,所以不安全 解锁
import threading import time v = [] lock = threading.Lock() def func(arg): lock.acquire() 上锁 v.append(arg) time.sleep(0.01) m = v[-1] print(arg,m) lock.release() 解锁 for i in range(10): t = threading.Thread(target=func,args=(i,)) t.start() 以后锁一个代码块
递归锁 RLock(一次放一个) 与死锁
所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程,如下就是死锁.
import threading import time v = [] lock = threading.Lock() def func(arg): lock.acquire() lock.acquire() v.append(arg) time.sleep(0.01) m = v[-1] print(arg,m) lock.release() lock.release() for i in range(10): t =threading.Thread(target=func,args=(i,)) t.start()
解决方法,递归锁,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁:
import threading import time v = [] lock = threading.RLock() def func(arg): lock.acquire() lock.acquire() v.append(arg) time.sleep(0.01) m = v[-1] print(arg,m) lock.release() lock.release() for i in range(10): t =threading.Thread(target=func,args=(i,)) t.start()
信号量 BoundedSemaphore (一次放n个)
同进程的一样
BoundedSemaphore管理一个内置的计数器,
每当调用acquire()时内置计数器-1;
调用release() 时内置计数器+1;
计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
实例:(同时只有3个线程可以获得BoundedSemaphore,即可以限制最大连接数为3):
import time import threading lock = threading.BoundedSemaphore(3) def func(arg): lock.acquire() print(arg) time.sleep(2) lock.release() for i in range(20): t =threading.Thread(target=func,args=(i,)) t.start() 结果: #2秒后 0 1 2 #2秒后 3 4 5 #2秒后 6 7 8 9 10 11 12 13 14 15 16 17 18 19
条件 Condition (一次放x个,根据条件)
使得线程等待,只有满足某条件时,才释放n个线程
Python提供的Condition对象提供了对复杂线程同步问题的支持。Condition被称为条件变量,除了提供与Lock类似的acquire和release方法外,还提供了wait和notify方法。线程首先acquire一个条件变量,然后判断一些条件。如果条件不满足则wait;如果条件满足,进行一些处理改变条件后,通过notify方法通知其他线程,其他处于wait状态的线程接到通知后会重新判断条件。不断的重复这一过程,从而解决复杂的同步问题。
代码说明:
import time import threading lock = threading.Condition() def func(arg): print('线程进来了') lock.acquire() lock.wait() # 加锁 print(arg) time.sleep(1) lock.release() for i in range(10): t =threading.Thread(target=func,args=(i,)) t.start() while True: inp = int(input('>>>')) lock.acquire() lock.notify(inp) lock.release() 结果: 线程进来了 线程进来了 线程进来了 线程进来了 线程进来了 线程进来了 线程进来了 线程进来了 线程进来了 线程进来了 >>>8 #输入8. 因为谁也不知道CPU是先调用那个线程,所以没有顺序 >>>0 2 3 5 4 6 7 1 3 #输入2 但是只剩下2个 >>>8 9
import time import threading lock = threading.Condition() def xxxx(): print('来执行函数了') input(">>>") # ct = threading.current_thread() # 获取当前线程 # ct.getName() return True def func(arg): print('线程进来了') lock.wait_for(xxxx) print(arg) time.sleep(1) for i in range(10): t =threading.Thread(target=func,args=(i,)) t.start() #说明:先循环,调用func函数,打印"线程来了",等待调用函数xxxx,打印"来执行函数了",用户输入数字,返回arg = i ,所以无论输入什么都是一个线程执行.
事件 Event (一次放行)
同进程的一样
线程的一个关键特性是每个线程都是独立运行且状态不可预测。如果程序中的其 他线程需要通过判断某个线程的状态来确定自己下一步的操作,这时线程同步问题就会变得非常棘手。为了解决这些问题,我们需要使用threading库中的Event对象。 对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在 初始情况下,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行
event.isSet():返回event的状态值; event.wait():如果 event.isSet()==False将阻塞线程; event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度; event.clear():恢复event的状态值为False。
import time import threading lock = threading.Event() def func(arg): print('线程来了') lock.wait() # 加锁:红灯 print(arg) for i in range(10): t =threading.Thread(target=func,args=(i,)) t.start() input(">>>>") lock.set() # 绿灯 lock.clear() # 再次变红灯 for i in range(10): t =threading.Thread(target=func,args=(i,)) t.start() input(">>>>") lock.set() #放行
总结 : 为什么要加锁?
---非线程安全
---控制一段代码块
线程池
作用: 调用线程,规定并发的最大个数
from concurrent.futures import ThreadPoolExecutor import time def task(a1,a2): time.sleep(2) print(a1,a2) # 创建了一个线程池(最多5个线程) pool = ThreadPoolExecutor(5) for i in range(40): # 去线程池中申请一个线程,让线程执行task函数。 pool.submit(task,i,8)
threading.local
当我们在考试的时候,会有收手机这个行为,考场的老师会将我们的手机放到一个收纳盒中,等考试结束之后,才可以拿自己的手机,但是这里有一个弊端,会不会有人看到 iPhone X 就拿走了.但是当我们为每个人都创建一个收纳盒,放自己的手机在写上名字,这样是不是就不会拿错了呢?
所以 , threading.local 的作用 : 内部自动为每一个线程维护一个空间(以字典形式),用于当前存取属于自己的值,保证数据隔离.
{
线程ID: {...},
线程ID: {...},
线程ID: {...},
线程ID: {...}
}
示例 :
import time import threading v = threading.local() def func(arg): # 内部会为当前线程创建一个空间用于存储:phone=自己的值 v.phone = arg time.sleep(2) print(v.phone,arg) # 去当前线程自己空间取值 for i in range(10): t =threading.Thread(target=func,args=(i,)) t.start() 结果: 0 0 1 1 4 4 2 2 5 5 3 3 6 6 7 7 9 9 8 8
""" 以后:Flask框架内部看到源码 上下文管理 """ import time import threading INFO = {} class Local(object): def __getattr__(self, item): ident = threading.get_ident() return INFO[ident][item] def __setattr__(self, key, value): ident = threading.get_ident() if ident in INFO: INFO[ident][key] = value else: INFO[ident] = {key:value} obj = Local() def func(arg): obj.phone = arg # 调用对象的 __setattr__方法(“phone”,1) time.sleep(2) print(obj.phone,arg) for i in range(10): t =threading.Thread(target=func,args=(i,)) t.start()
生产者消费者模型
当我们在节假日或者春运的时候买车票,我们买票的和卖票的之间存在着一定的关系,因为卖票的不知道是要多少人才能满足人买票的需求,这就需要排队.这样就会造成一定的事件.但是,当我们在买票和卖票的之间放一根管道:

这样,我们可以把需求放入管道里,就可以去做别的事情,当票打印之后再通知你,这样就可以两不当误.我们称管道叫做:队列.
线程队列
queue队列: 使用 import queue
queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
(队列在线程编程中特别有用,当信息必须在多个线程之间安全交换时。)
queue.Queue() #先进先出
import queue q=queue.Queue() q.put('first') q.put('second') q.put('third') print(q.get()) print(q.get()) print(q.get()) 结果(先进先出): first second third
示例 :
import time import queue import threading q = queue.Queue() # 线程安全 def producer(id): """ 生产者 :return: """ while True: time.sleep(2) q.put('包子') print('厨师%s 生产了一个包子' %id ) for i in range(1,4): t = threading.Thread(target=producer,args=(i,)) t.start() def consumer(id): """ 消费者 :return: """ while True: time.sleep(1) v1 = q.get() print('顾客 %s 吃了一个包子' % id) for i in range(1,3): t = threading.Thread(target=consumer,args=(i,)) t.start()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号