19.Redis故障模转移测试
以下是Redis sentinel的拓扑结构
[root@redis ~]# ps -ef|grep redis root 1259 1 0 3月18 ? 00:08:38 redis-server *:6379 root 1289 1 0 3月18 ? 00:08:18 redis-server *:6380 root 1343 1 0 3月18 ? 00:09:04 redis-server *:6381 root 2064 1 0 03:36 ? 00:09:29 redis-server *:26379 [sentinel] root 2076 1 0 03:38 ? 00:09:29 redis-server *:26380 [sentinel] root 2087 1 0 03:38 ? 00:10:19 redis-server *:26381 [sentinel]
说明:6379/6380/6381是三个Redis数据节点,而26379/26380/26381是三个sentinel
26379 run_id:6521bce7ca0d09d99d2d52976e71b73d96eafe52 26380 run_id:4261696cd87cd788f08dcbf7feffe33a960ae8a7 26381 run_id:cb0049d5314b388e6dbd4ed425029d752d9eaf42
开始模拟
模拟故障方法有很多,比较典型的方法有如下几种:
.方法一,强制杀掉对应节点的进程号,这样可以模拟出宕机的效果
.方法二, 使用Redis的debug sleep命令,让节点进入睡眠状态,这样可以模拟阻塞的效果
.方法三, 使用redis的shutdown命令,模拟正常的停掉redis。
这里使用方法一来进行测试,因为从实际经验来看,数百上千机器偶尔宕机一两台是会不定期出现的,这里记录一下用kill -9 使主节点(这里的主节点是6381)进程宕机的时间:
注意一下,这里发现kill掉主节点进程之后,主节点中没有打印什么日志信息(可能和shutdown效果不一样),但是发现其余的另外的两个节点中有一些日志信息显示
看一下6379日志信息:
2845:S 24 Mar 2022 21:58:25.702 * RDB age 0 seconds 2845:S 24 Mar 2022 21:58:25.702 * RDB memory usage when created 1.97 Mb 2845:S 24 Mar 2022 21:58:25.702 # Done loading RDB, keys loaded: 4, keys expired: 0. 2845:S 24 Mar 2022 21:58:25.703 * MASTER <-> REPLICA sync: Finished with success 2845:S 24 Mar 2022 22:04:25.687 # Connection with master lost. ## 2845:S 24 Mar 2022 22:04:25.687 * Caching the disconnected master state. 2845:S 24 Mar 2022 22:04:25.688 * Reconnecting to MASTER 127.0.0.1:6381 2845:S 24 Mar 2022 22:04:25.688 * MASTER <-> REPLICA sync started 2845:S 24 Mar 2022 22:04:25.688 # Error condition on socket for SYNC: Connection refused 2845:S 24 Mar 2022 22:04:26.141 * Connecting to MASTER 127.0.0.1:6381 2845:S 24 Mar 2022 22:04:26.142 * MASTER <-> REPLICA sync started 2845:S 24 Mar 2022 22:04:26.142 # Error condition on socket for SYNC: Connection refused 2845:S 24 Mar 2022 22:04:27.155 * Connecting to MASTER 127.0.0.1:6381 2845:S 24 Mar 2022 22:04:27.155 * MASTER <-> REPLICA sync started
可以看到一个时间点间隔(从21:58跳到了22:04)这个过程就是执行了kill命令后所出现的反应,从 Connection with master lost这句话开始 说明6379这个从节点去6381(主节点)请求就开始失败了
然后22:04:56时它接到sentinel节点命令,清理原理缓冲的主节点状态信息,sentinel将6379节点晋升为主节点,并重写了配置(config rewrite executed with sucess).
2845:M 24 Mar 2022 22:04:56.005 * Discarding previously cached master state. 2845:M 24 Mar 2022 22:04:56.005 # Setting secondary replication ID to 4e096befcb0b46425e84c0935a44afd848cffe63, valid up to offset: 28505953. New replication ID is 42589dec1d800f42453389730f53bf92ea2fda26 2845:M 24 Mar 2022 22:04:56.005 * MASTER MODE enabled (user request from 'id=10 addr=127.0.0.1:43084 laddr=127.0.0.1:6379 fd=10 name=sentinel-ab0fbd6d-cmd age=391 idle=1 flags=x db=0 sub=0 psub=0 multi=4 qbuf=188 qbuf-free=40766 argv-mem=4 obl=45 oll=0 omem=0 tot-mem=61468 events=r cmd=exec user=default redir=-1') 2845:M 24 Mar 2022 22:04:56.009 # CONFIG REWRITE executed with success. 2845:M 24 Mar 2022 22:04:56.709 * Replica 127.0.0.1:6380 asks for synchronization 2845:M 24 Mar 2022 22:04:56.709 * Partial resynchronization request from 127.0.0.1:6380 accepted. Sending 289 bytes of backlog starting from offset 28505953.
然后从 Replica 127.0.0.1:6380 asks for synchronization 这句话可以看到6380这个节点发起了连接主节点的请求,
这时去看sentinel日志:
这里我们可以26379的日志:
2064:X 24 Mar 2022 22:04:55.814 # +try-failover master mymaster 127.0.0.1 6381 2064:X 24 Mar 2022 22:04:55.817 # +vote-for-leader ab0fbd6da2b0a72051dbe3bee8ef3f02b3cc9a2a 4 2064:X 24 Mar 2022 22:04:55.824 # 18e34da0c4ee7c3c285d1d2735d8ab12a44cd72b voted for ab0fbd6da2b0a72051dbe3bee8ef3f02b3cc9a2a 4 2064:X 24 Mar 2022 22:04:55.825 # eadd4c9ebfa6c1fbcbfdc5d7e1eec13c80774ec5 voted for ab0fbd6da2b0a72051dbe3bee8ef3f02b3cc9a2a 4
这里可以看到sentinel集群在进行选举: 'ab0fbd6da2b0a72051dbe3bee8ef3f02b3cc9a2a' 这个是run_id
再来看看26380的日志:
2076:X 24 Mar 2022 22:04:55.706 # +sdown master mymaster 127.0.0.1 6381 2076:X 24 Mar 2022 22:04:55.821 # +new-epoch 4 2076:X 24 Mar 2022 22:04:55.823 # +vote-for-leader ab0fbd6da2b0a72051dbe3bee8ef3f02b3cc9a2a 4 2076:X 24 Mar 2022 22:04:56.700 # +config-update-from sentinel ab0fbd6da2b0a72051dbe3bee8ef3f02b3cc9a2a 127.0.0.1 26379 @ mymaster 127.0.0.1 6381 2076:X 24 Mar 2022 22:04:56.700 # +switch-master mymaster 127.0.0.1 6381 127.0.0.1 6379 2076:X 24 Mar 2022 22:04:56.701 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 2076:X 24 Mar 2022 22:04:56.701 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 2076:X 24 Mar 2022 22:05:26.723 # +sdown slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
从26380日志可以看出,原master(127.0.0.1 6381)被主观下线了,然后sentinel进行选举了,选择了run_id是‘ab0fbd6da2b0a72051dbe3bee8ef3f02b3cc9a2a’这个sentinel做了sentinel集群的主节点,从上面可以看到这个sentinel主节点也就是(23679)
而26381的日志也和26380内容差不多
2087:X 24 Mar 2022 22:04:55.795 # +sdown master mymaster 127.0.0.1 6381 2087:X 24 Mar 2022 22:04:55.822 # +new-epoch 4 2087:X 24 Mar 2022 22:04:55.825 # +vote-for-leader ab0fbd6da2b0a72051dbe3bee8ef3f02b3cc9a2a 4 2087:X 24 Mar 2022 22:04:55.853 # +odown master mymaster 127.0.0.1 6381 #quorum 3/2 2087:X 24 Mar 2022 22:04:55.854 # Next failover delay: I will not start a failover before Thu Mar 24 22:10:55 2022 2087:X 24 Mar 2022 22:04:56.702 # +config-update-from sentinel ab0fbd6da2b0a72051dbe3bee8ef3f02b3cc9a2a 127.0.0.1 26379 @ mymaster 127.0.0.1 6381 2087:X 24 Mar 2022 22:04:56.702 # +switch-master mymaster 127.0.0.1 6381 127.0.0.1 6379 2087:X 24 Mar 2022 22:04:56.702 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 2087:X 24 Mar 2022 22:04:56.703 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 2087:X 24 Mar 2022 22:05:26.765 # +sdown slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
这里来看一下各个节点客观下线的时间
26379 2064:X 24 Mar 2022 22:04:55.814 # +odown master mymaster 127.0.0.1 6381 #quorum 2/2 26380 这个在日志中竟然没有找到 26381 2087:X 24 Mar 2022 22:04:55.853 # +odown master mymaster 127.0.0.1 6381 #quorum 3/2
从这两个日志的+odown客观下线时间来看,26379是最先客观下线的,
3)故障转移日志:这里可以通过sentinel的主节点(26379)日志看出整个日志转移时的整个流程。
2064:X 24 Mar 2022 22:04:55.736 # +sdown master mymaster 127.0.0.1 6381 2064:X 24 Mar 2022 22:04:55.814 # +odown master mymaster 127.0.0.1 6381 #quorum 2/2 ##对主节点进行客观下线 2064:X 24 Mar 2022 22:04:55.814 # +new-epoch 4 2064:X 24 Mar 2022 22:04:55.814 # +try-failover master mymaster 127.0.0.1 6381 ##这里是尝试故障转移6381这个节点 2064:X 24 Mar 2022 22:04:55.817 # +vote-for-leader ab0fbd6da2b0a72051dbe3bee8ef3f02b3cc9a2a 4 ##这里进行选举sentinel主节点 2064:X 24 Mar 2022 22:04:55.824 # 18e34da0c4ee7c3c285d1d2735d8ab12a44cd72b voted for ab0fbd6da2b0a72051dbe3bee8ef3f02b3cc9a2a 4 ##run_id 2064:X 24 Mar 2022 22:04:55.825 # eadd4c9ebfa6c1fbcbfdc5d7e1eec13c80774ec5 voted for ab0fbd6da2b0a72051dbe3bee8ef3f02b3cc9a2a 4 2064:X 24 Mar 2022 22:04:55.878 # +elected-leader master mymaster 127.0.0.1 6381 ##这里没有没有搞懂意思。。。 2064:X 24 Mar 2022 22:04:55.879 # +failover-state-select-slave master mymaster 127.0.0.1 6381 ##这里故障转移原主节点(6381) 2064:X 24 Mar 2022 22:04:55.939 # +selected-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 ##选举6379作为redis数据的主节点 2064:X 24 Mar 2022 22:04:55.939 * +failover-state-send-slaveof-noone slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 ##这里通过命令salveof no one使得6379成为主节点 2064:X 24 Mar 2022 22:04:56.003 * +failover-state-wait-promotion slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 ##这里是等待6379成为redis数据主节点 2064:X 24 Mar 2022 22:04:56.645 # +promoted-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 ##这里是提升6379作为redis数据主节点 2064:X 24 Mar 2022 22:04:56.645 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6381 ##这里重配置了原主节点6381的配置文件 2064:X 24 Mar 2022 22:04:56.695 * +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381 ##这里是重配置了6380的配置文件 2064:X 24 Mar 2022 22:04:56.901 # -odown master mymaster 127.0.0.1 6381 ##撤销对原主节点进行客观下线 2064:X 24 Mar 2022 22:04:57.687 * +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381 2064:X 24 Mar 2022 22:04:57.687 * +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381 2064:X 24 Mar 2022 22:04:57.746 # +failover-end master mymaster 127.0.0.1 6381 ##原主节点故障转移结束 2064:X 24 Mar 2022 22:04:57.747 # +switch-master mymaster 127.0.0.1 6381 127.0.0.1 6379 ##这里最好说明了有原主127.0.0.1 6381 ---> 新主 127.0.0.1 6379 这样的一个过程 2064:X 24 Mar 2022 22:04:57.747 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 ##原从节点6380开始连接新主节点 2064:X 24 Mar 2022 22:04:57.747 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 ##原从节点6381也开始连接新主节点 2064:X 24 Mar 2022 22:05:27.798 # +sdown slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 ##这里又判断了6381为主观下线, 2064:X 25 Mar 2022 09:47:35.167 # +tilt #tilt mode entered
这里对日志中的一些订阅做解释:
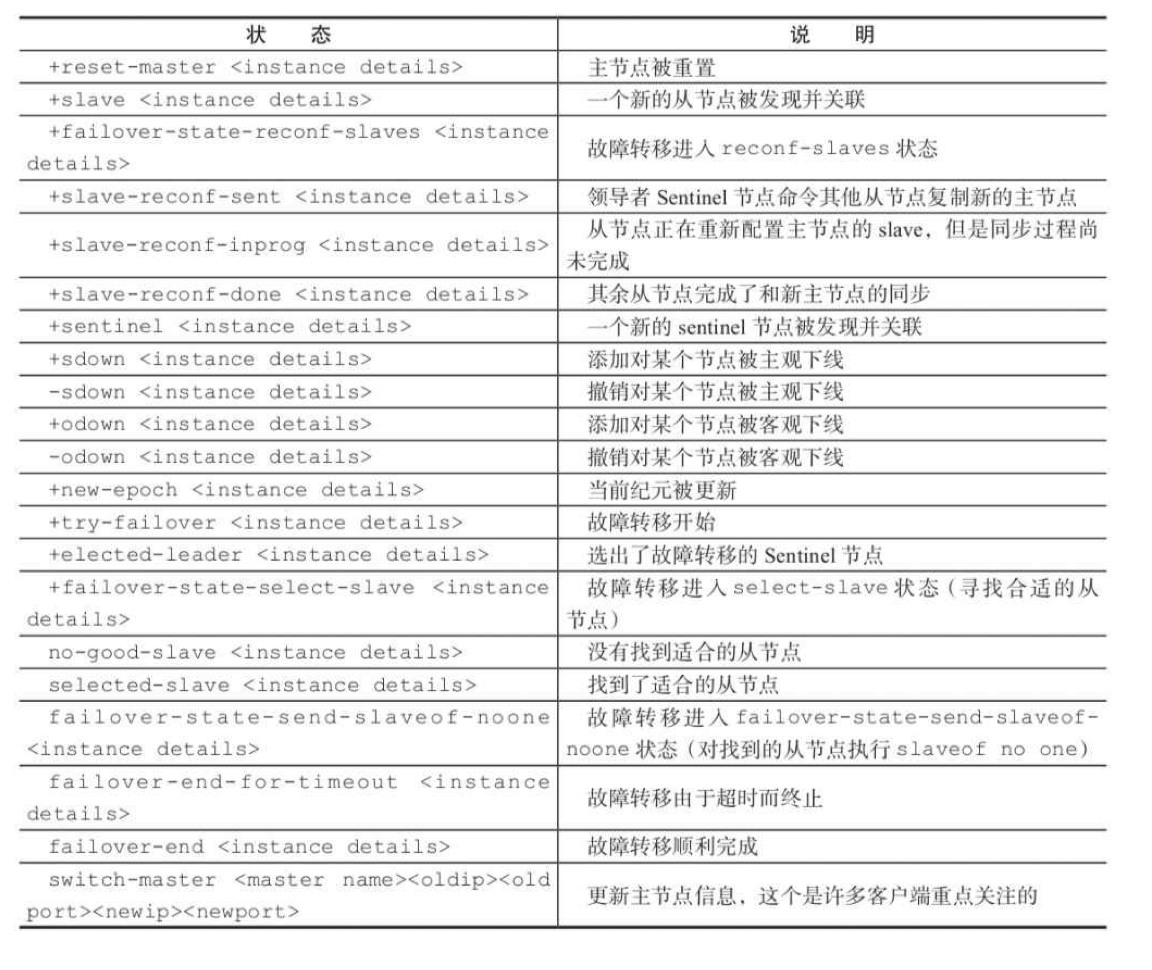
原主节点如果重启后:
6381(原主节点)日志:
5294:S 25 Mar 2022 22:54:11.963 * Connecting to MASTER 127.0.0.1:6379 5294:S 25 Mar 2022 22:54:11.964 * MASTER <-> REPLICA sync started 5294:S 25 Mar 2022 22:54:11.964 * REPLICAOF 127.0.0.1:6379 enabled (user request from 'id=3 addr=127.0.0.1:49004 laddr=127.0.0.1:6381 fd=8 name=sentinel-18e34da0-cmd age=10 idle=0 flags=x db=0 sub=0 psub=0 multi=4 qbuf=196 qbuf-free=40758 argv-mem=4 obl=45 oll=0 omem=0 tot-mem=61468 events=r cmd=exec user=default redir=-1') 5294:S 25 Mar 2022 22:54:11.967 # CONFIG REWRITE executed with success
这里启动后接到sentinel节点的命令,让它去复制6379节点
再来看一下6379(现主节点)日志
2845:M 25 Mar 2022 22:54:11.972 * Replica 127.0.0.1:6381 asks for synchronization 2845:M 25 Mar 2022 22:54:11.972 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for 'f4503c1ab5bec8923b2fb0559e95a58f0cd9f039', my replication IDs are '42589dec1d800f42453389730f53bf92ea2fda26' and '4e096befcb0b46425e84c0935a44afd848cffe63') 2845:M 25 Mar 2022 22:54:11.972 * Starting BGSAVE for SYNC with target: disk 2845:M 25 Mar 2022 22:54:11.973 * Background saving started by pid 5309 5309:C 25 Mar 2022 22:54:11.977 * DB saved on disk 5309:C 25 Mar 2022 22:54:11.978 * RDB: 2 MB of memory used by copy-on-write 2845:M 25 Mar 2022 22:54:12.021 * Background saving terminated with success 2845:M 25 Mar 2022 22:54:12.022 * Synchronization with replica 127.0.0.1:6381 succeeded
这时可以新的主机点中看到,有来自失联多年的兄弟6381的请求复制,
然后再来看看sentinel日志:
26379日志: 撤销了对6381节点主观下线的决定
2064:X 26 Mar 2022 11:04:56.643 # -sdown slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
26380日志:也撤销了对6381节点主观下线的决定
2076:X 26 Mar 2022 11:04:56.921 # -sdown slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
26381日志:也是撤销了对6381的主观下线的决定
注意点:
部署各个节点的机器时间尽量要同步,否则日志的时序性会很混乱,例如可以给机器添加NTP服务来同步时间
这里补充一下如果其中一个节点宕掉了,会出现如下日志情况:
会在redis数据的主节点出现连接丢失的报错
2845:M 26 Mar 2022 11:02:43.602 # Connection with replica 127.0.0.1:6381 lost.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号