
pinterest或者任意网页数据的处理方法
0.(抽出MJ)抽出midjourney的数据,放到独立文件夹中
1.(批量重命名)将不需要保留网页数据的内容直接批量重命名
2.(处理网页爬虫数据)针对网上爬下来的标题,运行以下代码,处理每个文件名,删特殊符号和数字,但保留逗号,句号,括号以及括号内数字。
import os import re def clean_filename(filename): # 保留括号内的数字 filename = re.sub(r'(?<!\()\d+(?!\))', '', filename) # 将特殊符号(包括下划线)转换为空格,但保留括号、逗号和句点 filename = re.sub(r'[^\w\s\(\),\.]|_', ' ', filename) # 去除文件名开头和结尾的空格 filename = filename.strip() return filename def is_image_file(filename): return filename.lower().endswith(('.jpg', '.jpeg', '.png', '.gif', '.bmp', '.tiff')) def unique_file_name(directory, filename): base, extension = os.path.splitext(filename) counter = 1 new_filename = filename while os.path.exists(os.path.join(directory, new_filename)): new_filename = f"{base} ({counter}){extension}" counter += 1 return new_filename def rename_files_in_directory(directory): for root, dirs, files in os.walk(directory): for file in files: if is_image_file(file): new_name = clean_filename(file) new_name = unique_file_name(root, new_name) old_file_path = os.path.join(root, file) new_file_path = os.path.join(root, new_name) os.rename(old_file_path, new_file_path) print(f'已重命名: {file} -> {new_name}') def main(): directory = input("请输入要处理的文件夹路径: ") if not os.path.exists(directory): print("路径不存在,请输入有效的文件夹路径。") return rename_files_in_directory(directory) print("处理完成。") if __name__ == "__main__": main()
3.(用txt加前缀)需要保留网页数据的部分,在文件夹内加文本文件,标题为需要加入的前缀,txt文件加入所有图片名前。(结尾无逗号自动补充逗号)
import os import re def is_image_file(filename): for ext in ['.jpg', '.jpeg', '.png', '.gif', '.bmp', '.tiff']: if filename.lower().endswith(ext): return True return False def get_txt_prefix(directory): for file in os.listdir(directory): if file.lower().endswith('.txt'): prefix = os.path.splitext(file)[0] if not prefix.endswith(','): prefix += ',' return prefix return None def rename_images_with_prefix(directory, prefix): for root, dirs, files in os.walk(directory): for file in files: if is_image_file(file): new_name = prefix + file old_file_path = os.path.join(root, file) new_file_path = os.path.join(root, new_name) os.rename(old_file_path, new_file_path) print(f'已重命名: {file} -> {new_name}') def main(): directory = input("请输入要处理的文件夹路径: ") for root, dirs, files in os.walk(directory): for dir in dirs: dir_path = os.path.join(root, dir) prefix = get_txt_prefix(dir_path) if prefix: rename_images_with_prefix(dir_path, prefix) print("处理完成。") if __name__ == "__main__": main()
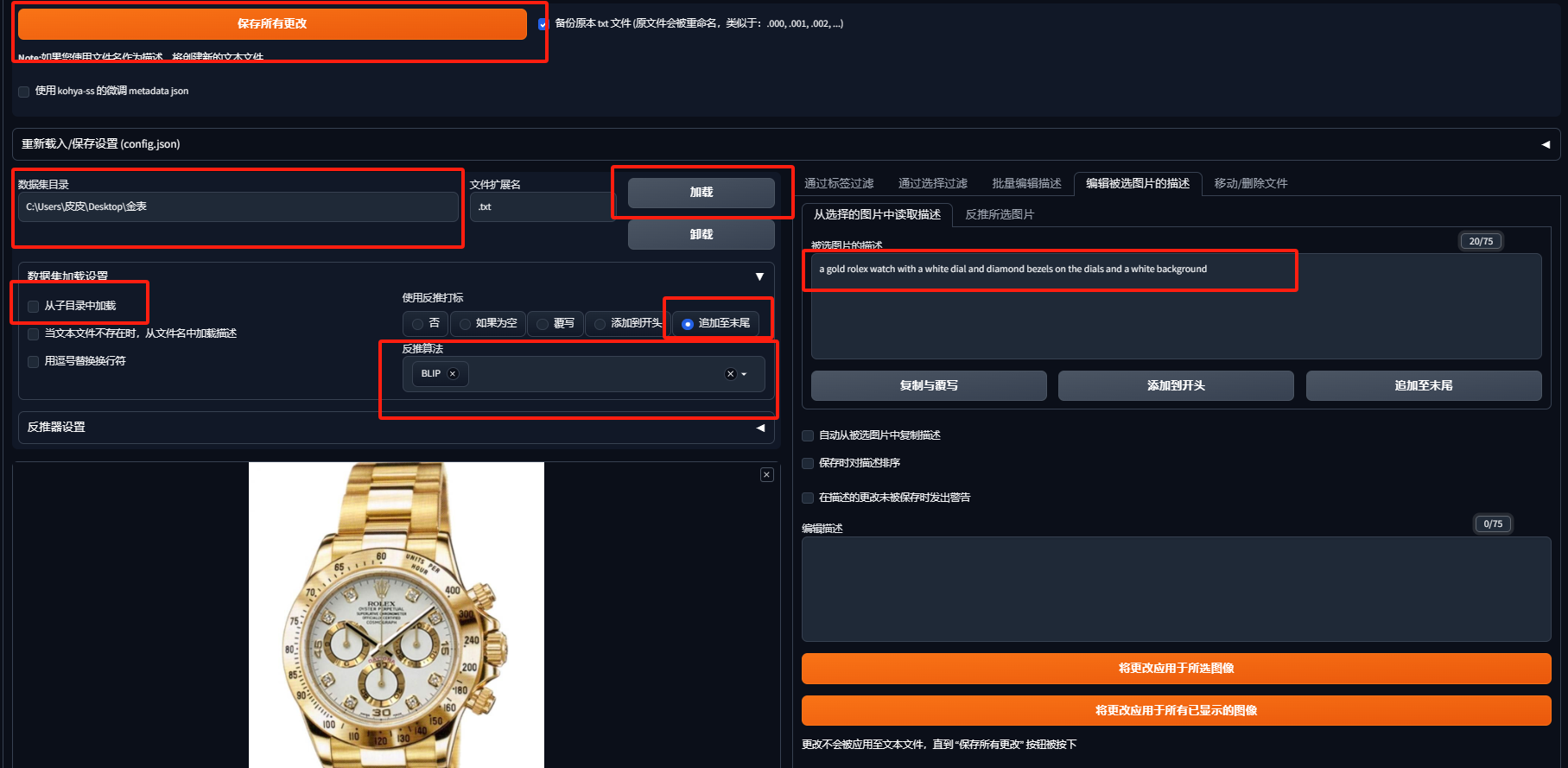
4.(SD自然语言反推)利用stable diffusion的BLIP自然语言反推,递归子文件夹得到文本文件。文本文件标题与图片名相同。
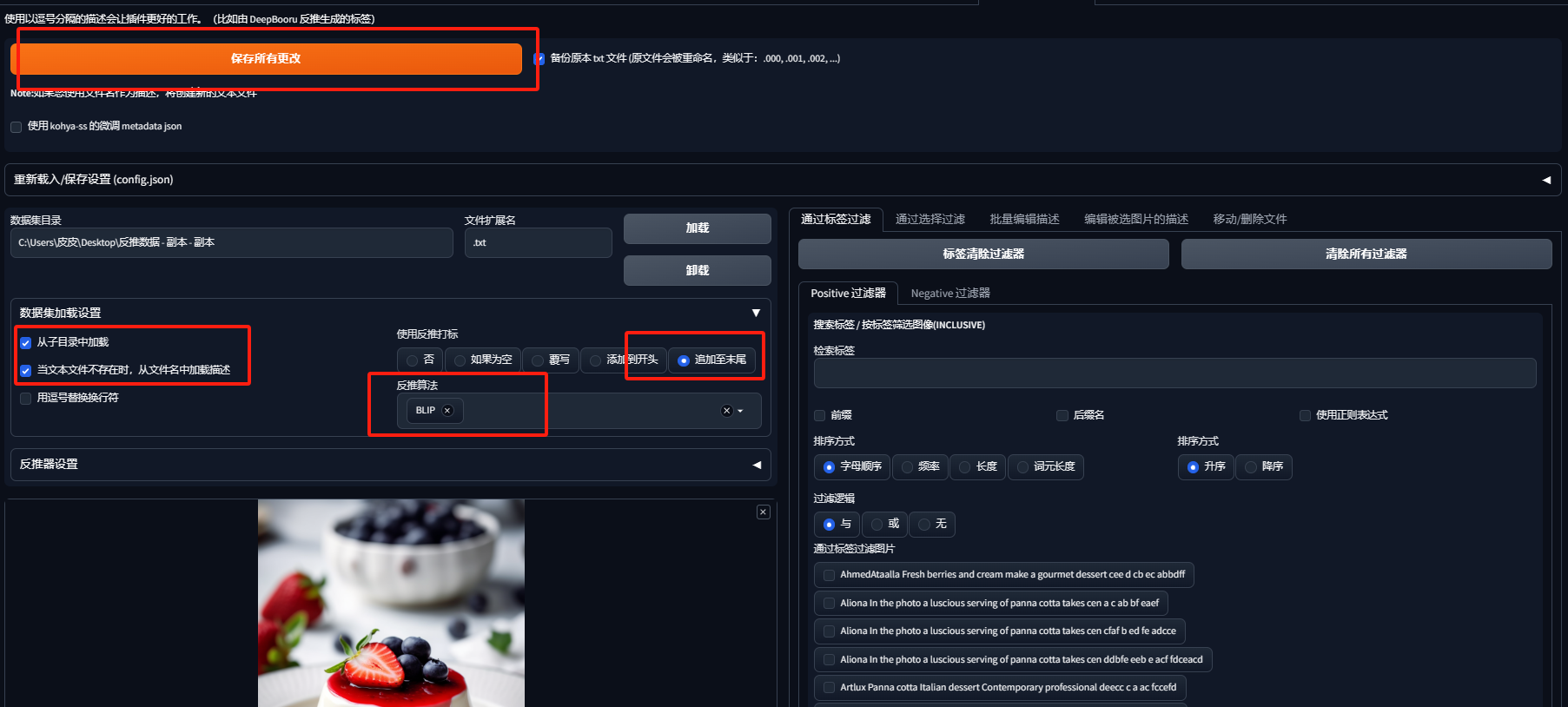
5.(删括号及数字)遍历目录及其子目录下所有txt类文件,删除其中的括号与数字
import os import re def remove_numbers_and_brackets(text): # 使用正则表达式删除数字和括号 return re.sub(r'[\d\(\)]', '', text) def process_directory(directory): for root, dirs, files in os.walk(directory): for file in files: if file.endswith('.txt'): file_path = os.path.join(root, file) with open(file_path, 'r', encoding='utf-8') as f: content = f.read() # 删除数字和括号 content = remove_numbers_and_brackets(content) with open(file_path, 'w', encoding='utf-8') as f: f.write(content) # 主程序入口 if __name__ == "__main__": dir_path = input("请输入要处理的目录路径: ") process_directory(dir_path) print("处理完成。")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号