
Scala IDEA for Eclipse里用maven来创建scala和java项目代码环境(图文详解)
这篇博客
是在Scala IDEA for Eclipse里手动创建scala代码编写环境。
Scala IDE for Eclipse的下载、安装和WordCount的初步使用(本地模式和集群模式)
本博文,教大家,用maven来创建。
第一步:安装scala插件
因为,我win7下的scala环境是2.10.4
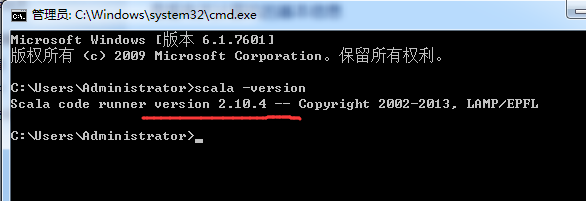
所以,选择下载的是,这个
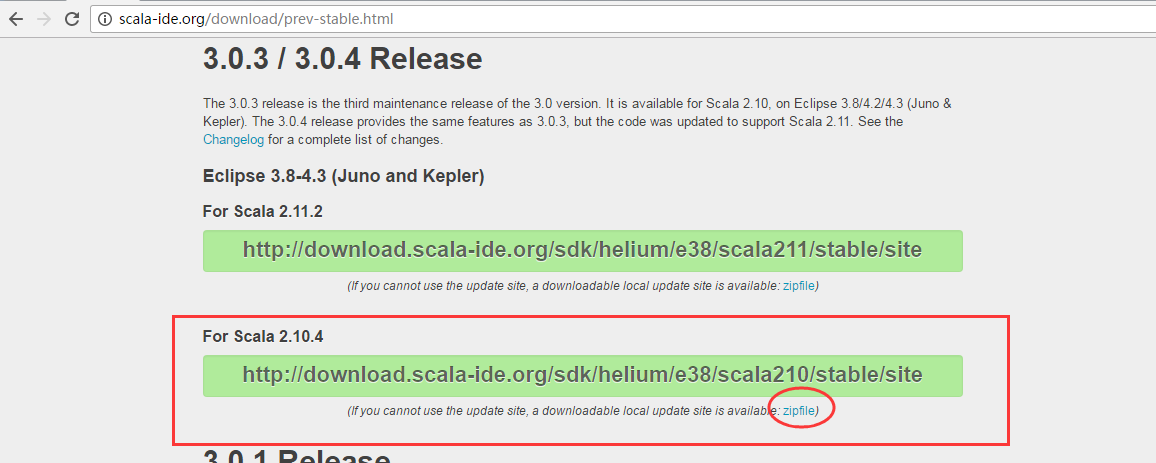


下载好之后,解压缩以后把plugins和features复制到eclipse目录,重启eclipse以后即可。
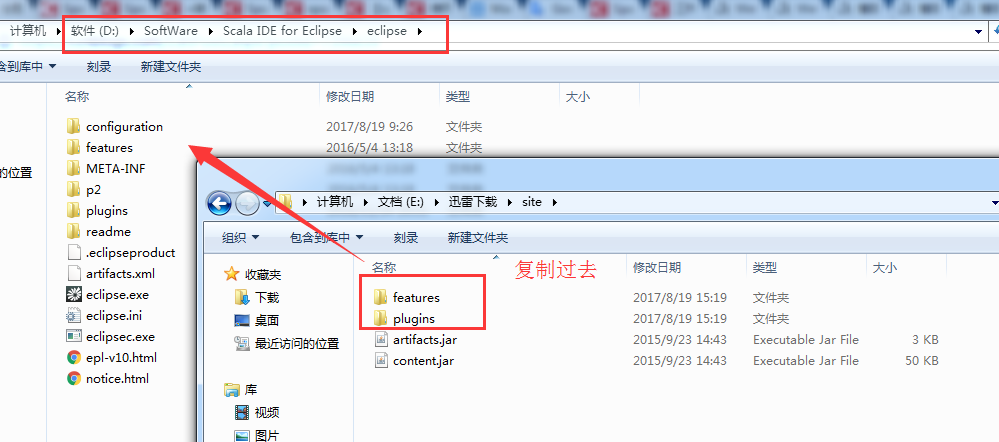
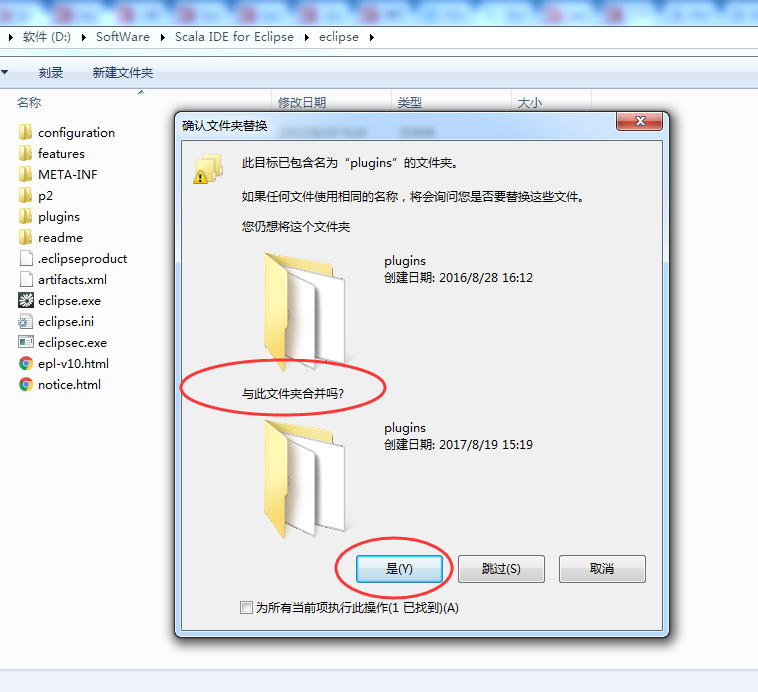
重启eclipse以后即可。
然后,
Window -> Open Perspective -> Other…,打开Scala,说明安装成功。
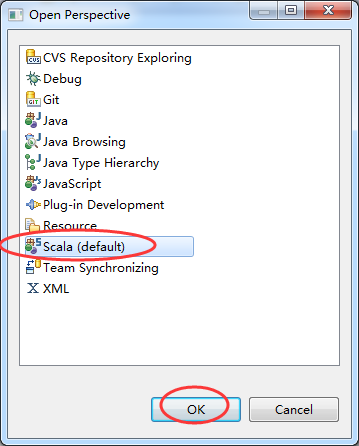
第二步:创建maven工程
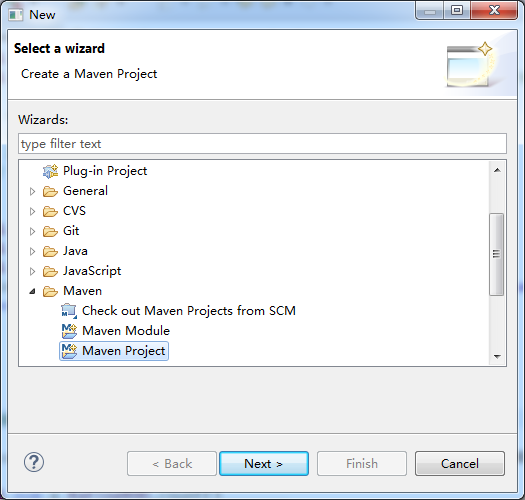
打开File -> New -> Other…,选择Maven Project:

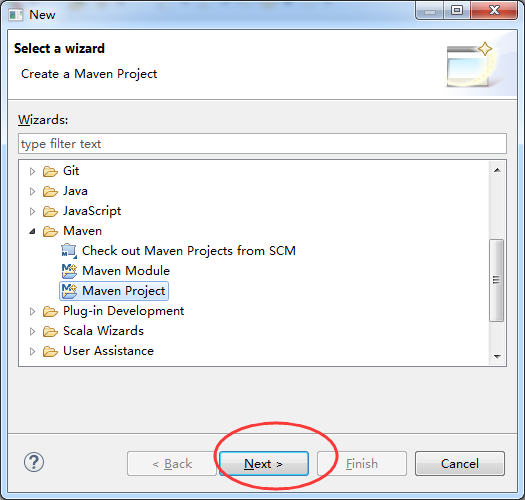
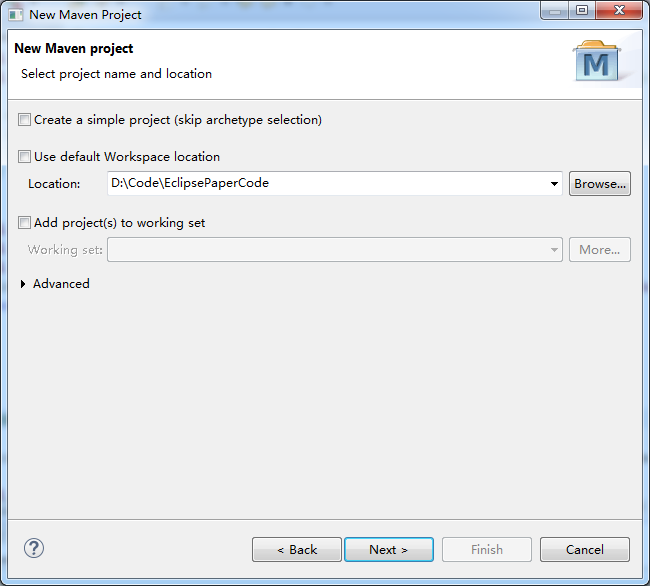
点击Next,输入项目存放路径:

也许,大家会像我这样,没有。org.scala-tools.archetypes找不到。

解决办法:
则需要
安装m2e-scala插件
m2e-scala用来支持scala开发中对maven的一些定制功能。通过eclipse的Install New Software安装。
安装过程
1、Help->Install New Software
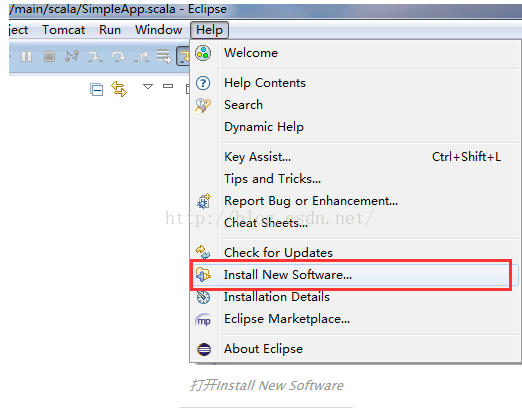
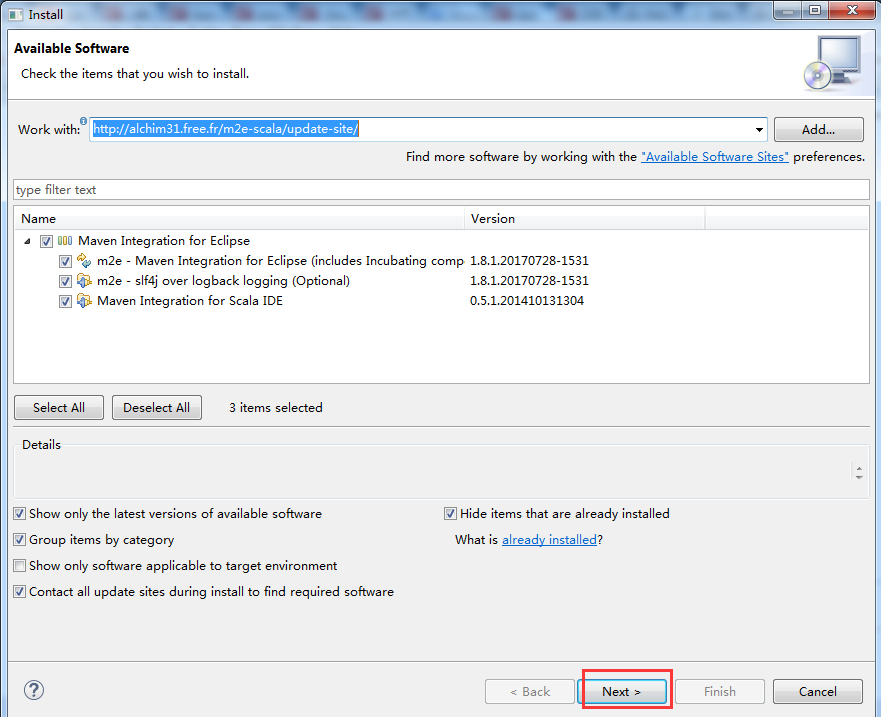
url里输入http://alchim31.free.fr/m2e-scala/update-site/
这里大家可以仅勾选第三项,我这里就全部勾选上。懒得以后还需要再安装。
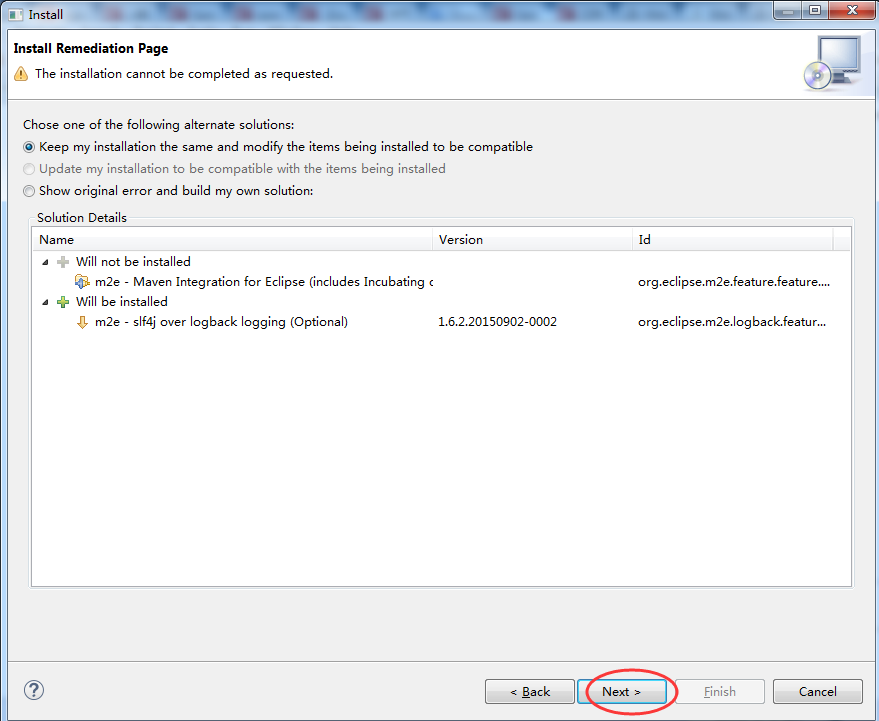
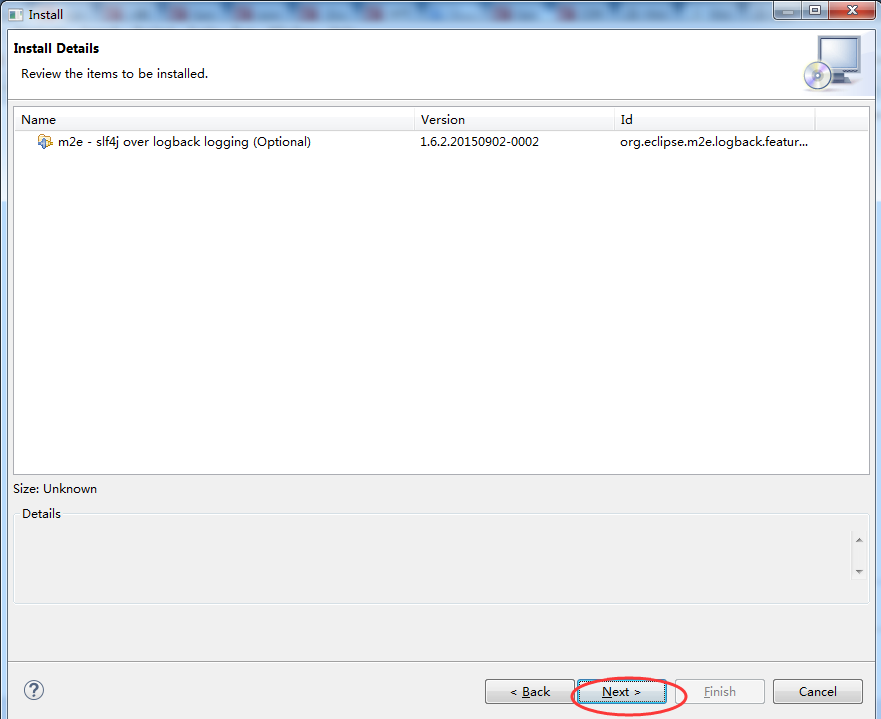
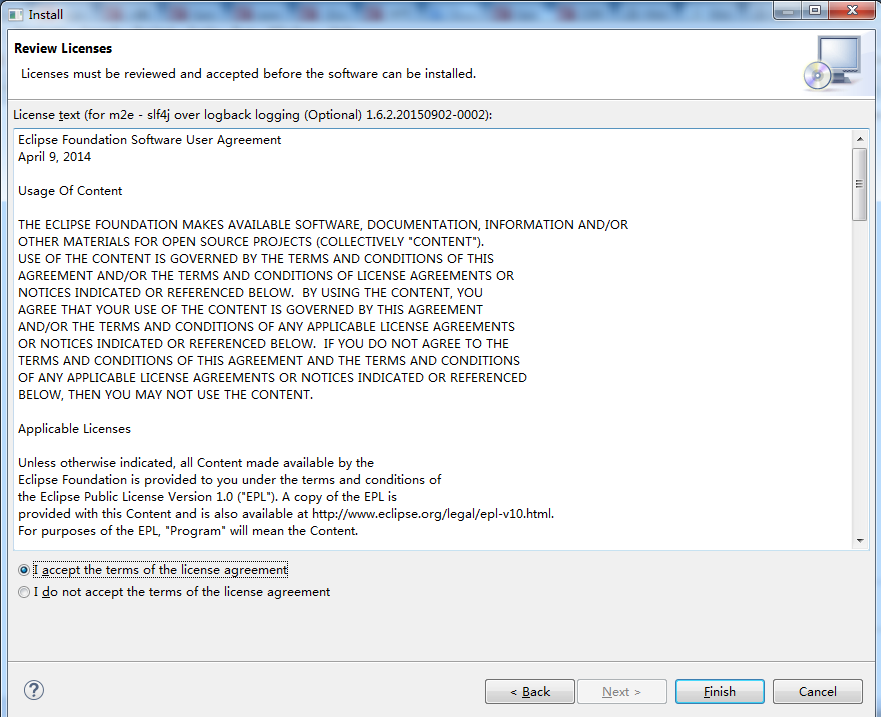
安装完成后,可在Help->Installation Details中查看
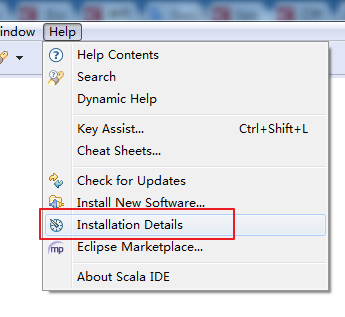
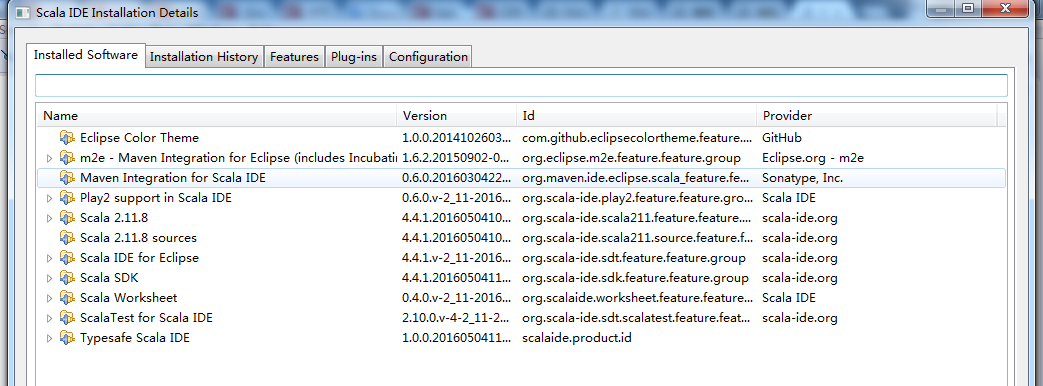
然后,再
设置远程Archetype
为了方便地创建Scala Maven项目,我们在Eclipse配置远程的Maven Archetype,ArcheType相当于项目模板。在Preference页面中选择Maven->Archetypes:
点击 Add Remote Catelog,在弹出框的catlog file输入:
OK,完成。
当然,若大家,这里也可以以后若不需要了,也可以卸载。
如何在Eclipse/Myeclipse/Scala IDEA for Eclipse 中正确删除已经下载过的插件(图文详解)
如果大家还是,没有成功的话,则
1、下载一个maven-Scala-plugin插件,本次下载为maven-scala-plugin-2.15.2.jar包,放入scala-SDK-4.4.1-vfinal-2.11-win32.win32.x86_64\eclipse\plugins路径下,然后重启eclipse。
下载地址
http://mvnrepository.com/artifact/org.scala-tools/maven-scala-plugin/2.15.2

注意:这个版本,我只是举个例子,大家可以变动哈!


2、在项目的pom.xml中增加以下代码:

<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<id>scala-test-compile</id>
<phase>test-compile</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
为什么,要上述这么做呢,是因为
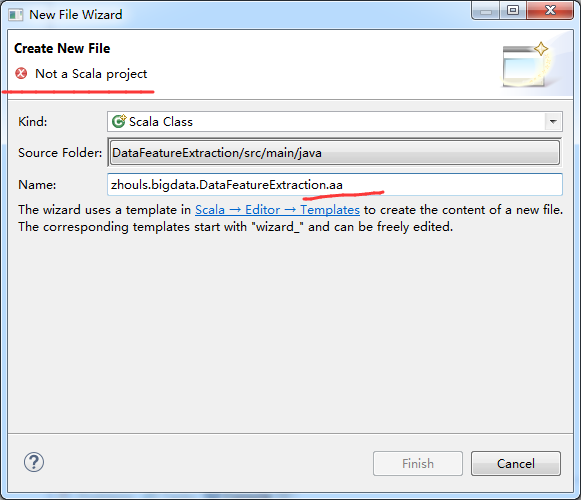

若是你的,没有生成的话,多保存下pom.xml或者在Scala IDEA for Eclipse下方的problem里选中错误的信息一条,逐个去quick fix就可以了
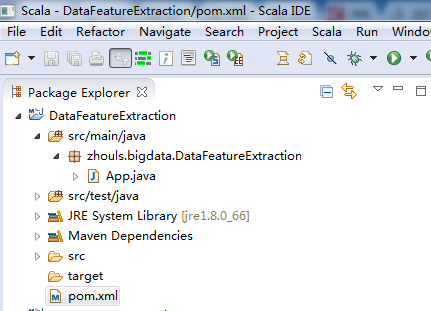
以下是我在Scala IDEA for Eclipse里先用maven来构建scala,再来构建java项目(博主推荐!!!)
这个原理,跟下面我写的在IDEA里,maven来先构建scala,再来构建java项目,是一样的。
是在Intellij IDEA(Ultimate版本)里用maven常见scala和java代码编写环境
Spark编程环境搭建(基于Intellij IDEA的Ultimate版本)(包含Java和Scala版的WordCount)(博主强烈推荐)
具体如下:
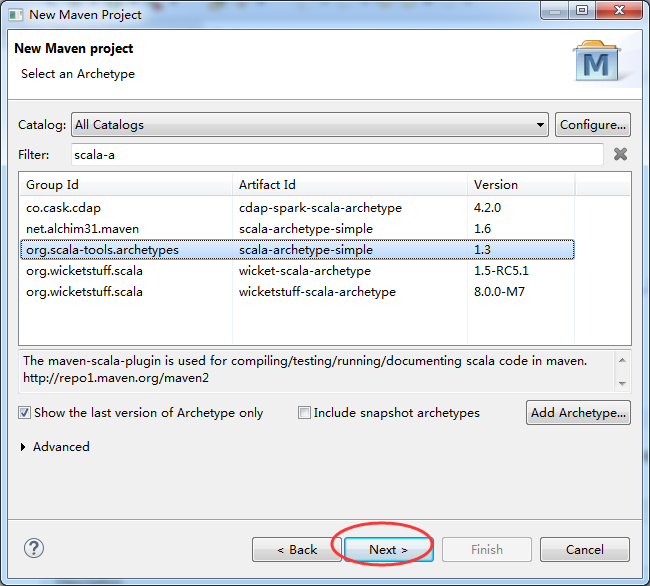
Eclipse中选择New->Maven Project,在ArcheType的选择页面中,选择如下:
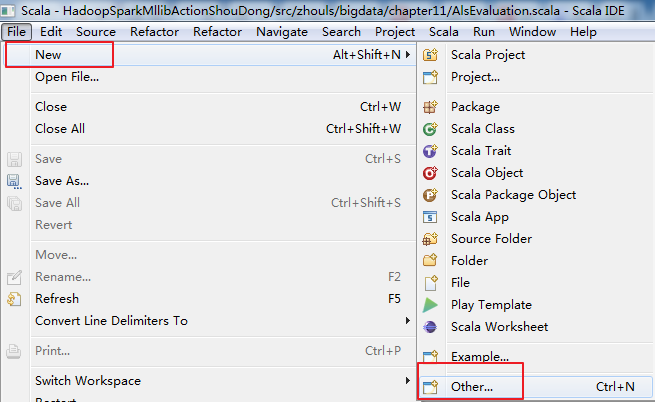
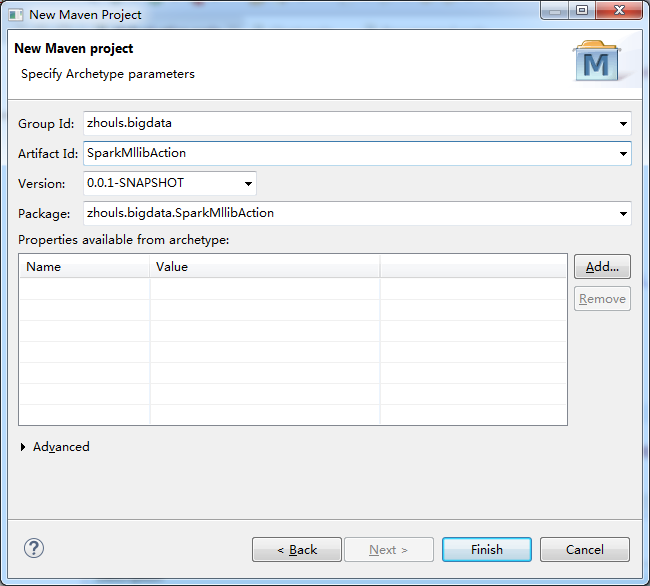
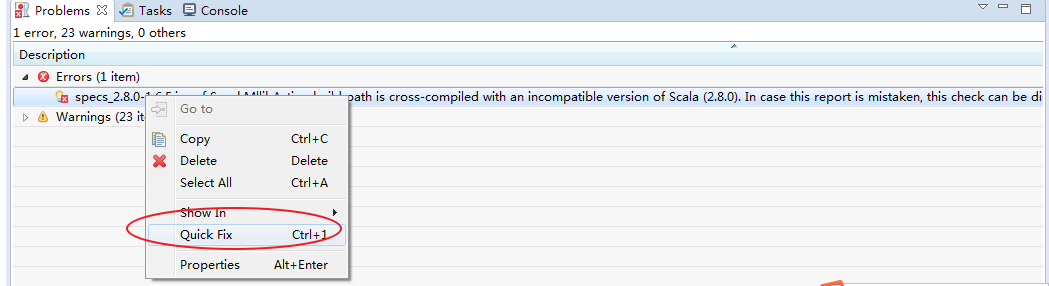
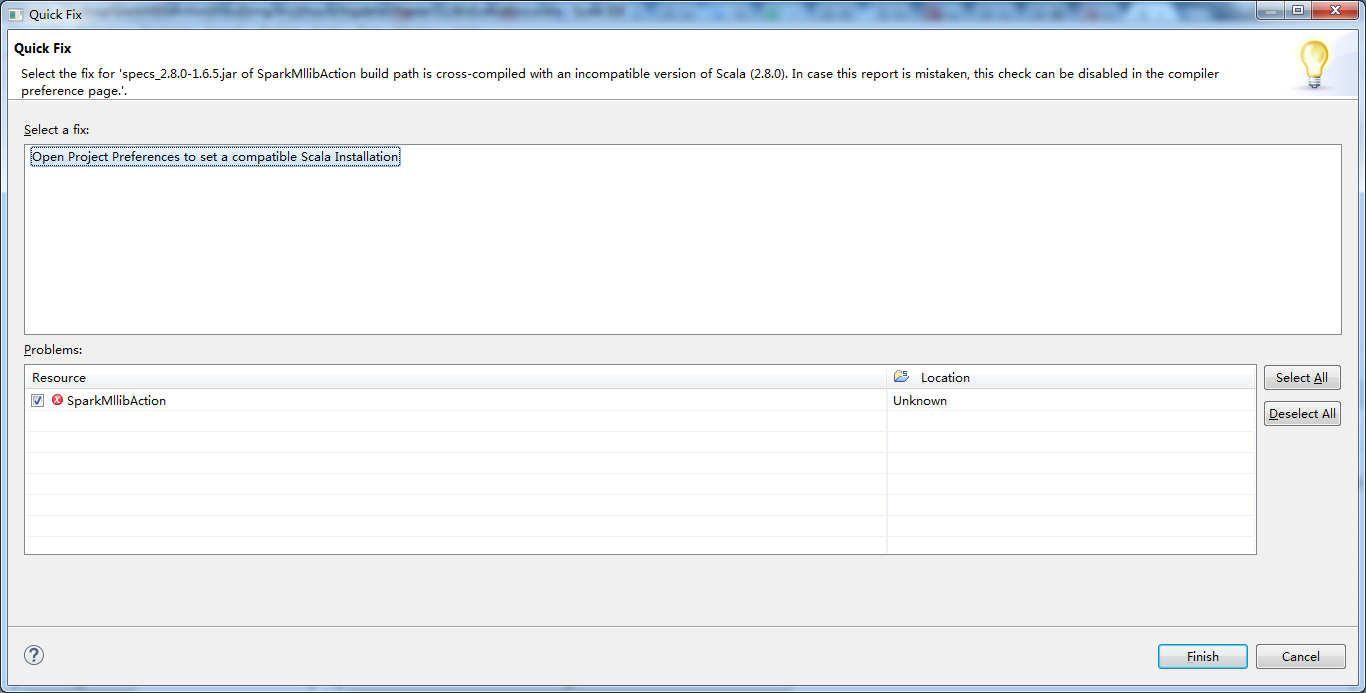
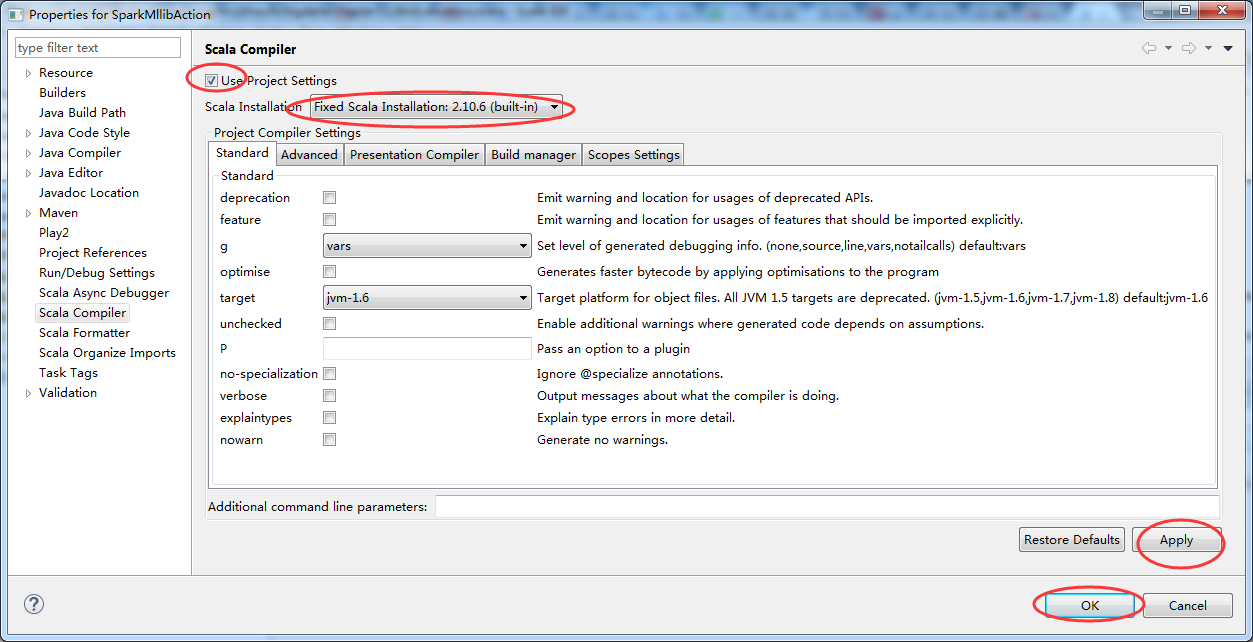
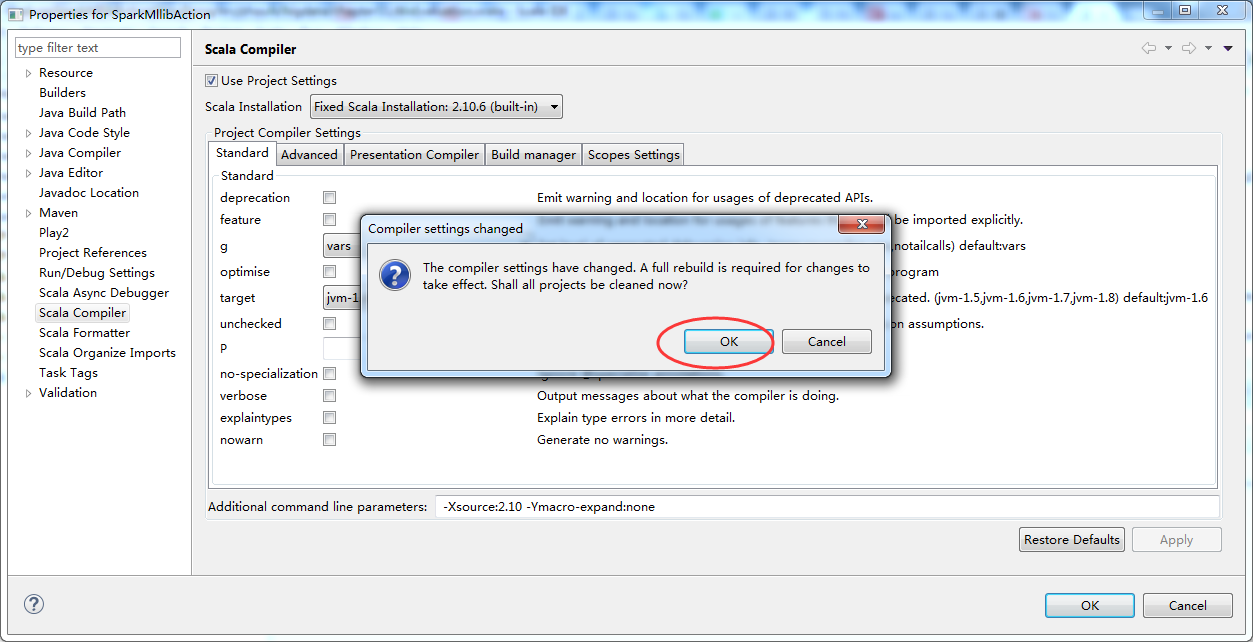
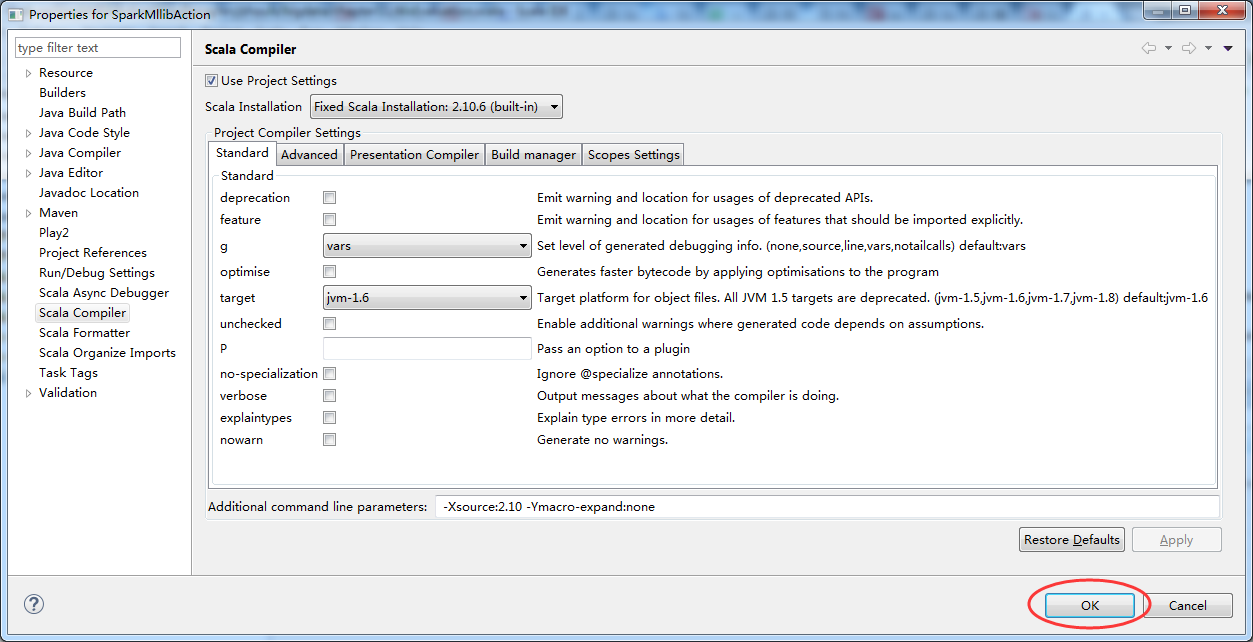
然后,来解决这个自带错误
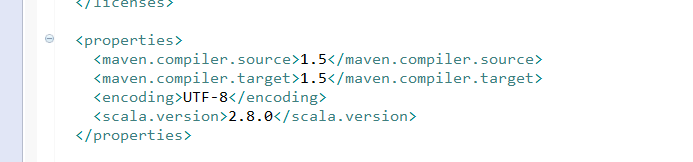
因为,自带是scala的2.8.0版本
以下是我在Scala IDEA for Eclipse里先用maven来构建java,再来构建scala项目
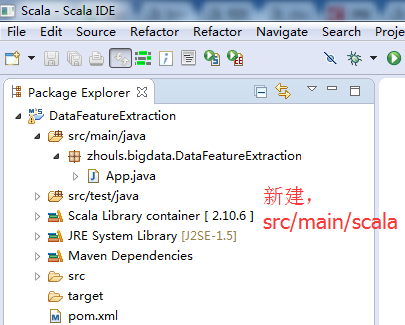

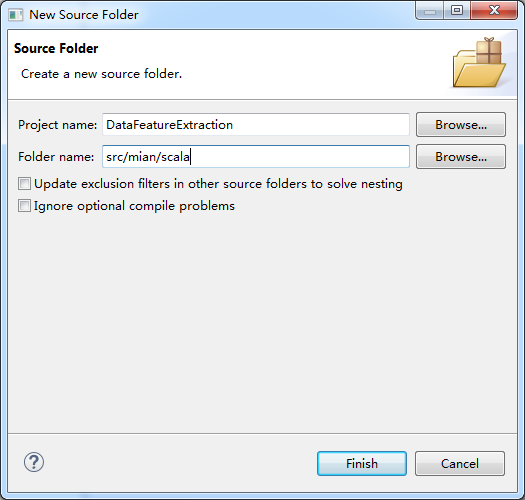
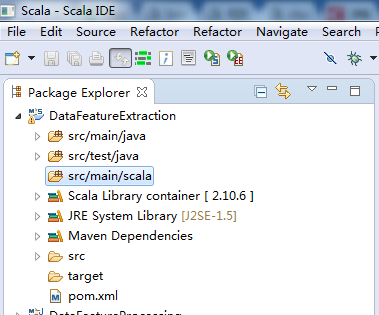
即,新建好了,src/main/java。同理去新建好src/test/scala。
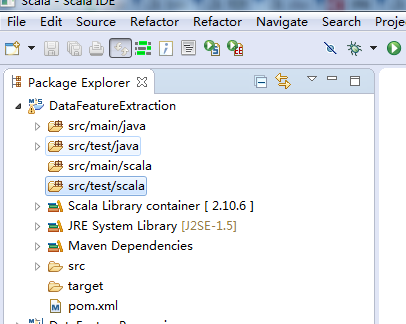
我这里,在src/main/scala里,新建包zhouls.bigdata.DataFeatureExtraction,是为了与src/main/java里统一。
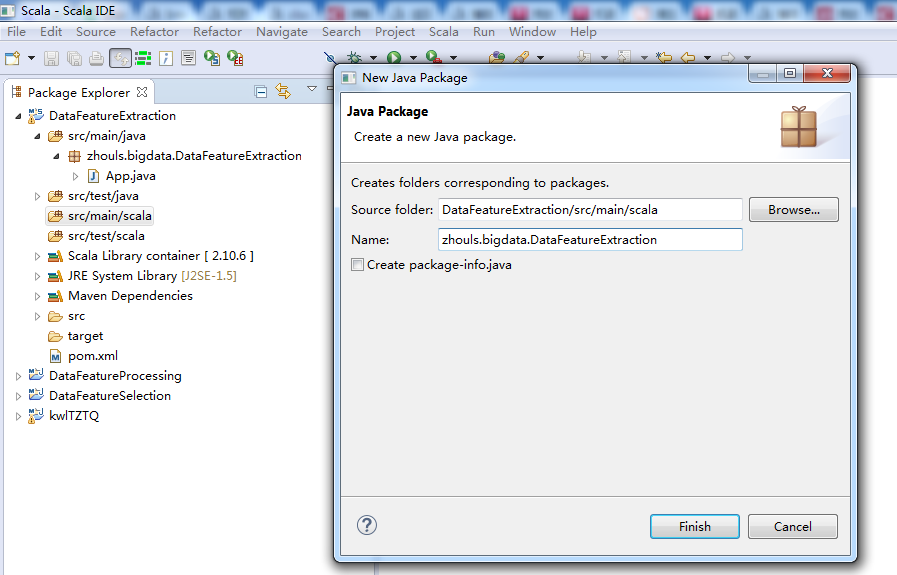
然后,我这里,以一个wordcount.scala为例。
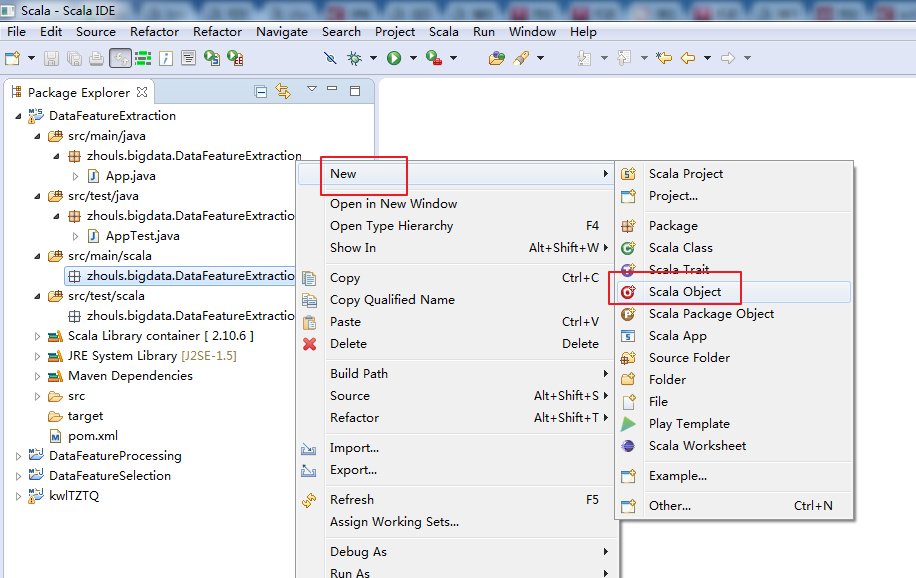
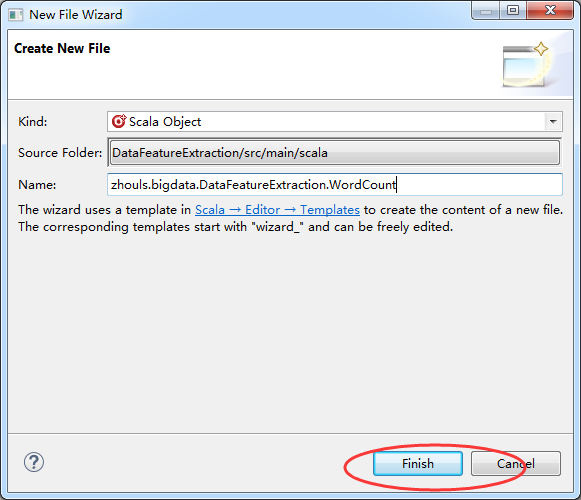
再改下jdk
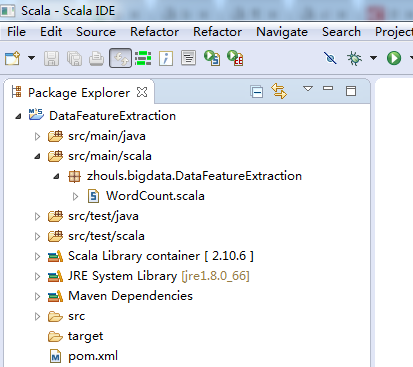
然后,我这里编个简单的程序。

package zhouls.bigdata.DataFeatureExtraction //import org.apache.spark.SparkConf //import org.apache.spark.SparkContext import org.apache.spark.{SparkConf, SparkContext} object WordCount { def main(args: Array[String]): Unit = { println("Hello World") } }

成功!
总结
其实思路很简单。
1、 对于Scala IDEA for Eclipse而言:
好比我本博客,是先用maven来创建普通的java项目,这个太简单了,若不懂的博友,请移步
Eclipse下Maven新建项目、自动打依赖jar包(包含普通项目和Web项目)
然后,在建立好maven创建的普通java项目之后,需要下载插件maven-scala-plugin-2.15.2.jar包,放入scala-SDK-4.4.1-vfinal-2.11-win32.win32.x86_64\eclipse\plugins路径下,然后重启eclipse。
然后,再在pom.xml里加入插件所需的配置文件。
然后,再手动新建src/main/scala和src/test/scala。
然后,再手动新建好包和类。
不多赘述后面的了。
说包了,就是在Scala IDEA for Eclipse里,若直接这么去maven创建项目的话,则默认的是java项目,所以需要scala项目,则需手动。
2、对于在IDEA而言:
好比如下的博客
IntelliJ IDEA(Ultimate版本)的下载、安装和WordCount的初步使用(本地模式和集群模式)
Spark编程环境搭建(基于Intellij IDEA的Ultimate版本)(包含Java和Scala版的WordCount)(博主强烈推荐)
先,手动新建src/main/java和src/test/java。
然后,再手动新建好包和类。
不多赘述后面的了。
说包了,就是在Scala IDEA for Eclipse里,若直接这么去maven创建项目的话,则默认的是java项目,所以需要scala项目,则需手动。
我的配置文件pom.xml(暂时为)
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>zhouls.bigdata</groupId> <artifactId>DataFeatureExtraction</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>DataFeatureExtraction</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <build> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <version>2.15.2</version> <executions> <execution> <id>scala-test-compile</id> <phase>test-compile</phase> <goals> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> <!-- https://mvnrepository.com/artifact/org.datanucleus/datanucleus-api-jdo --> <dependency> <groupId>org.datanucleus</groupId> <artifactId>datanucleus-api-jdo</artifactId> <version>5.0.6</version> </dependency> <!-- https://mvnrepository.com/artifact/org.datanucleus/datanucleus-core --> <dependency> <groupId>org.datanucleus</groupId> <artifactId>datanucleus-core</artifactId> <version>5.0.6</version> </dependency> <!-- https://mvnrepository.com/artifact/org.datanucleus/datanucleus-rdbms --> <dependency> <groupId>org.datanucleus</groupId> <artifactId>datanucleus-rdbms</artifactId> <version>5.0.6</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core_2.10 --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.6.2</version> </dependency> <!-- https://mvnrepository.com/artifact/com.ecfront/ez-fs <dependency> <groupId>com.ecfront</groupId> <artifactId>ez-fs</artifactId> <version>1.0</version> </dependency> --> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql_2.10 --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.10</artifactId> <version>1.6.2</version> </dependency> <!-- https://mvnrepository.com/artifact/com.databricks/spark-csv_2.10 --> <dependency> <groupId>com.databricks</groupId> <artifactId>spark-csv_2.10</artifactId> <version>1.5.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-mllib_2.10 --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_2.10</artifactId> <version>1.6.2</version> <scope>provided</scope> </dependency> </dependencies> </project>
扩展博客(一定要去看)
用maven来创建scala和java项目代码环境(图文详解)(Intellij IDEA(Ultimate版本)、Intellij IDEA(Community版本)和Scala IDEA for Eclipse皆适用)(博主推荐)
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号