Impala储存与分区
不多说,直接上干货!



hive的元数据存储在/user/hadoop/warehouse
Impala的内部表也在/user/hadoop/warehouse。
那两者怎么区分,看前面的第一列。
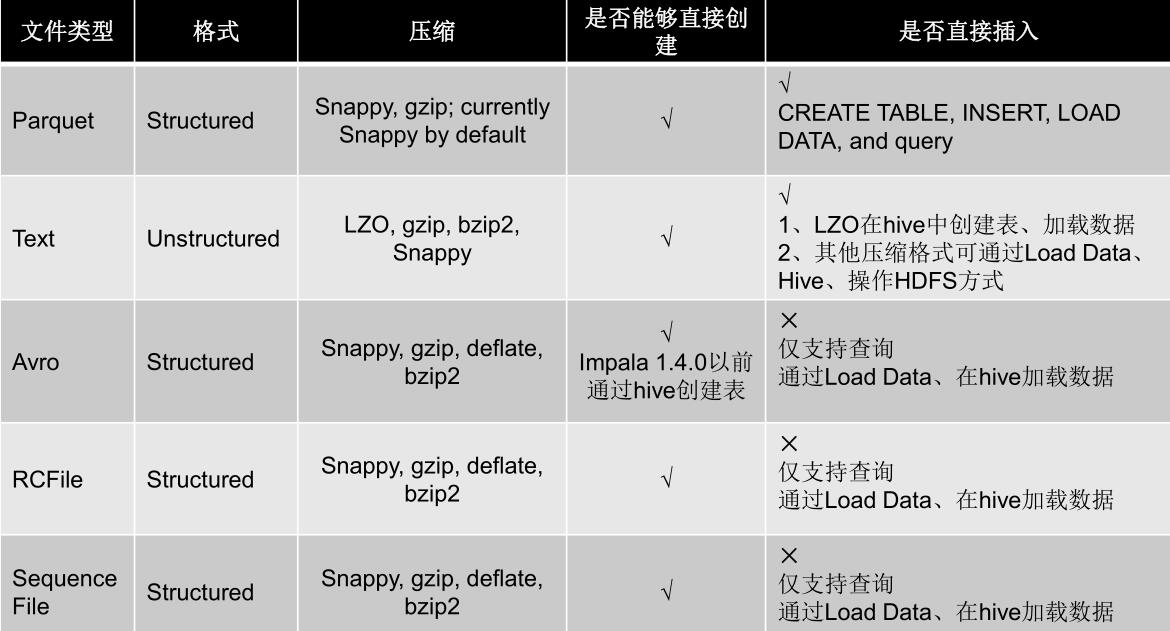
下面是Impala对文件的格式及压缩类型的支持

• 添加分区方式
– 1、partitioned by 创建表时,添加该字段指定分区列表
– 2、使用alter table 进行分区的添加和删除操作
create table t_person(id int, name string, age int) partitioned by (type string); alter table t_person add partition (sex=‘man'); alter table t_person drop partition (sex=‘man'); alter table t_person drop partition (sex=‘man‘,type=‘boss’);
• 分区内添加数据
insert into t_person partition (type='boss') values (1,’zhangsan’,18),(2,’lisi’,23) insert into t_person partition (type='coder') values(3,wangwu’,22),(4,’zhaoliu’,28),(5,’tianqi’,24)
• 查询指定分区数据
select id,name from t_person where type=‘coder
进行数据分区将会极大的提高数据查询的效率,尤其是对于当下大数据的运用,是一门不可或缺的知识。那数据怎么创建分区呢?数据怎样加载到分区
一、 Impala/Hive按State分区Accounts
(1)示例:accounts是非分区表
通过以上方式创建的话,数据就存放在accounts目录里面。那么,如果Loudacre大部分对customer表的分析是按state来完成的?比如:
这种情况下如果数据量很大,为了避免全表扫描的发生,我们可以去创建分区。如果不创建分区的话,它会默认所有查询不得不扫描目录的所有文件。创建分区按state将数据存储到不同的子目录,当按照“NY”的条件进行查询的时候,它只会扫描到子目录,下面我具体来看一下分区创建。
二、分区创建
(1)使用PARTITIONED BY来创建分区表
在这里注意state是被删除掉的,因为它作为分区字段,我们知道分区数据是不会出现在实际的文件当中的,所以state作为分区字段是不会出现在列当中的。换句话说,分区键就是一个虚列,它是不会存在列当中的。那么,如何去查看我们分区的列呢?它会出现在我们的结构当中吗?会的。
三、查看分区列
使用DESCRIBE显示分区列,它会出现在结构最后一列,它是一个虚列,并不是真实在数据中存在的列。
我们创建单个分区,但有时候会有嵌套分区,如何来处理呢?
四、创建嵌套分区:
创建好了分区,我们怎么加载数据到分区呢?有两种方式动态分区和静态分区。动态分区是指Impala/Hive在加载的时候自动添加新的分区,数据基于列值存储到正确的分区(子目录)。而静态分区需要我们通过ADD PARTITION提前去定义分区的名称,当加载数据的时候,指定存储数据到哪个分区。那么动态分区和静态分区各有什么特征呢?后续为大家接着分享。
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号