

solr索引创建流程
solr索引创建流程:
分词组件Tokenizer
分词组件(Tokenizer)会做以下几件事情(这个过程称为:Tokenize),处理得到的结果是词汇单元(Token)。
1、将文档分成一个一个单独的单词。
2、去除标点符号。
3、去除停词(stop word)。

语言处理组件
语言处理组件(linguistic processor)主要是对得到的词元(Token)做一些语言相关的处理。对于英语,语言处理组件(Linguistic Processor)一般做以下几点:
1、变为小写(Lowercase)
2、将单词缩减为词根形式
3、将单词转换为词根形式

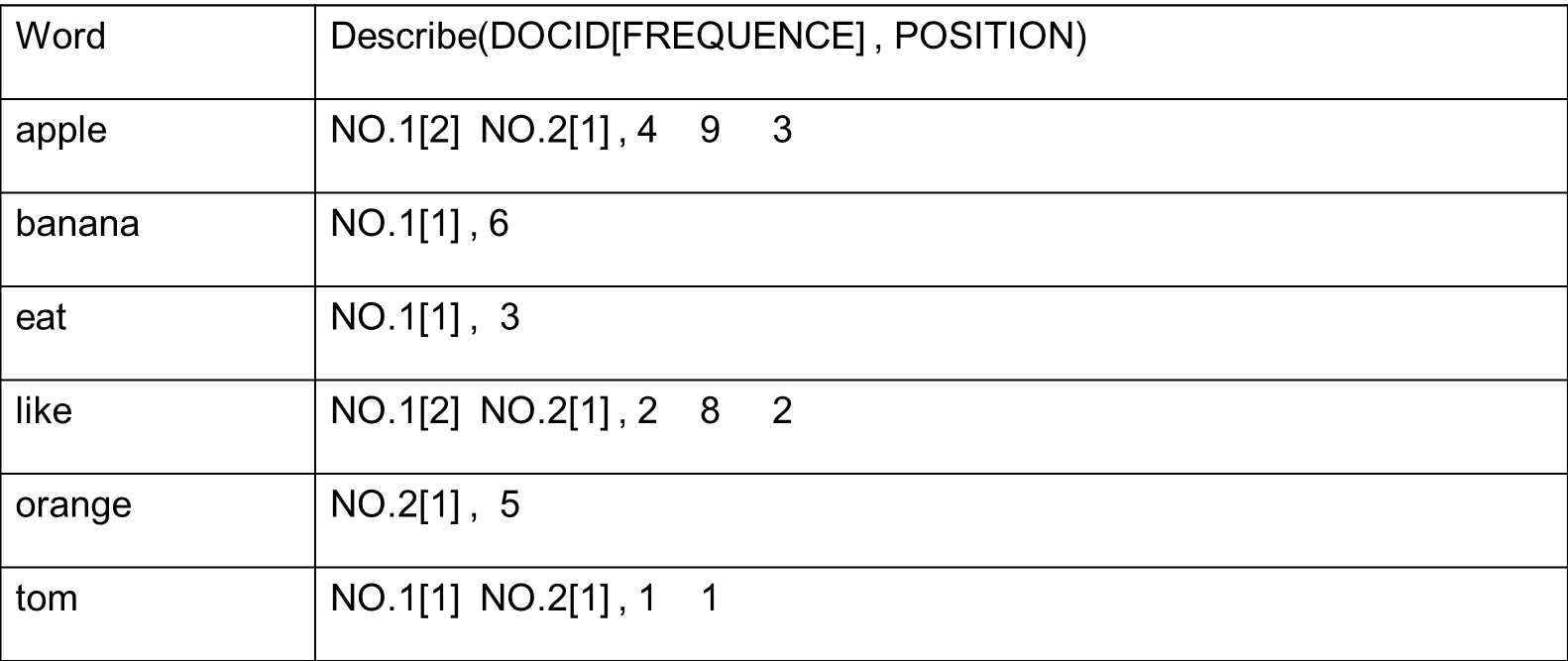
索引组件(Indexer)
1、利用得到的词(Term)创建一个字典
2、对字段进行排序
3、合并相同的词和词出现的文档
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号