
Sqoop Import原理和详细流程讲解
Sqoop Import原理
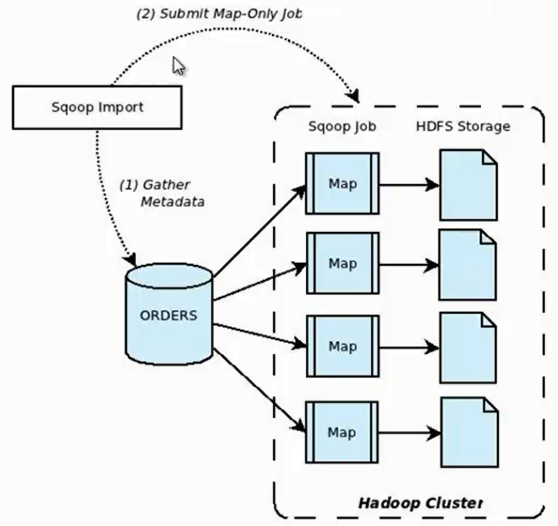
Sqoop Import详细流程讲解
Sqoop在import时,需要指定split-by参数。Sqoop根据不同的split-by参数值来进行切分,然后将切分出来的区域分配到不同map中。
每个map中再处理数据库中获取的一行一行的值,写入到HDFS中(由此也可知,导入导出的事务是以Mapper任务为单位)。
同时split-by根据不同的参数类型有不同的切分方法,如比较简单的int型,Sqoop会取最大和最小split-by字段值,然后根据传入的num-mappers来确定划分几个区域。
比如select max(split_by),min(split-by) from得到的max(split-by)和min(split-by)分别为1000和1,而num-mappers为2的话,则会分成两个区域(1,500)和(501-1000),同时也会分成2个sql给2个map去进行导入操作,分别为select XXX from table where split-by>=1 and split-by<500和select XXX from table where split-by>=501 and split-by<=1000。最后每个map各自获取各自SQL中的数据进行导入工作。
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号