
Hadoop HDFS编程 API入门系列之HDFS_HA(五)
不多说,直接上代码。
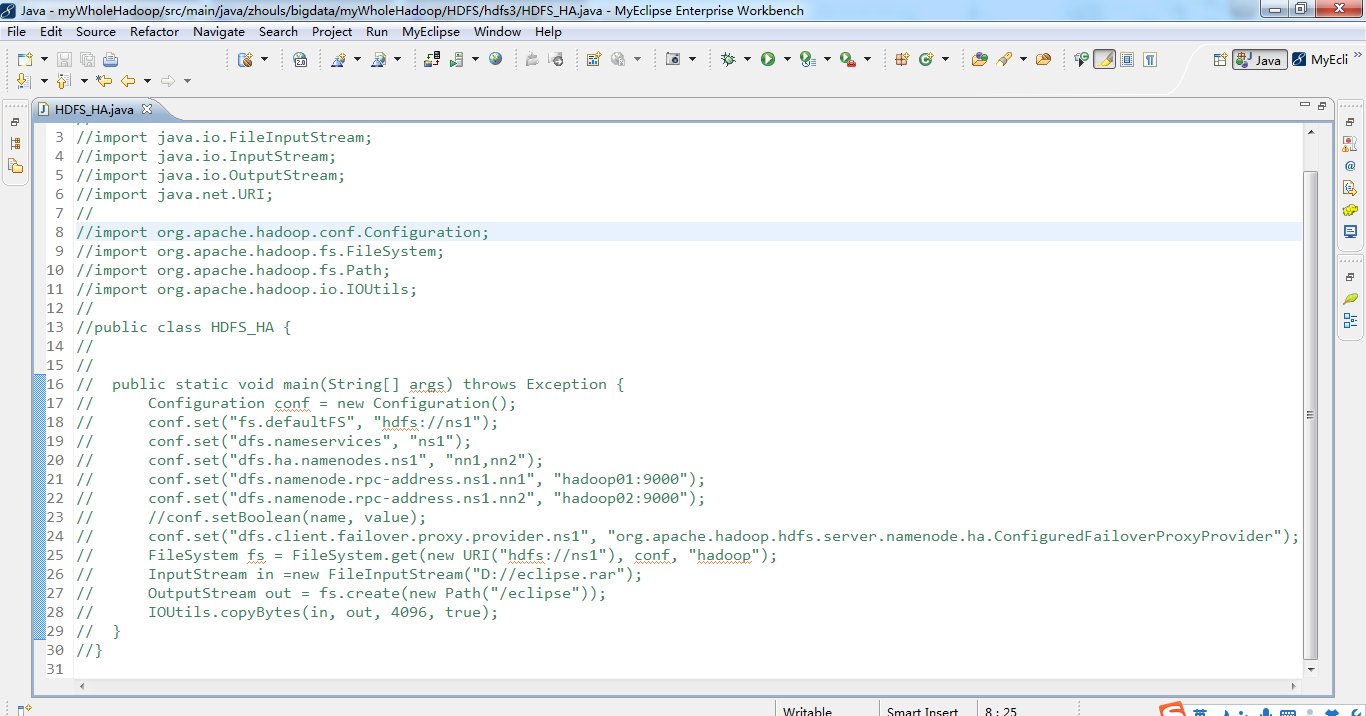
代码
1 package zhouls.bigdata.myWholeHadoop.HDFS.hdfs3; 2 3 import java.io.FileInputStream; 4 import java.io.InputStream; 5 import java.io.OutputStream; 6 import java.net.URI; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.FileSystem; 10 import org.apache.hadoop.fs.Path; 11 import org.apache.hadoop.io.IOUtils; 12 13 public class HDFS_HA { 14 15 16 public static void main(String[] args) throws Exception { 17 Configuration conf = new Configuration(); 18 conf.set("fs.defaultFS", "hdfs://ns1"); 19 conf.set("dfs.nameservices", "ns1"); 20 conf.set("dfs.ha.namenodes.ns1", "nn1,nn2"); 21 conf.set("dfs.namenode.rpc-address.ns1.nn1", "hadoop01:9000"); 22 conf.set("dfs.namenode.rpc-address.ns1.nn2", "hadoop02:9000"); 23 //conf.setBoolean(name, value); 24 conf.set("dfs.client.failover.proxy.provider.ns1", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"); 25 FileSystem fs = FileSystem.get(new URI("hdfs://ns1"), conf, "hadoop"); 26 InputStream in =new FileInputStream("D://eclipse.rar"); 27 OutputStream out = fs.create(new Path("/eclipse")); 28 IOUtils.copyBytes(in, out, 4096, true); 29 } 30 }
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号