

1.查询结果过滤和排序
distinct
当一个属性值有多条记录时,使用distinct来指定返回一条记录group by
按照某个属性对结果进行分组order by
根据某个属性对结果进行排序,可升序(ASC),可降序(DESC),对于文字,升降序是按照文本的字母顺序limit
指定返回返回多少行offset
指定从哪一行开始返回
2.多表查询
- 数据库范式(normalization)
是数据表设计的规范,在范式的规范下,数据表存储的重复数据降到最低,同时表间不再有很强的数据耦合 - 主键
唯一标识一条数据的属性,借助主键(或其他属性),可以把多个表连接起来 inner join(可简写为join)

这种连接方式只保留每个表都共有的数据
left outer join(简写为left join)
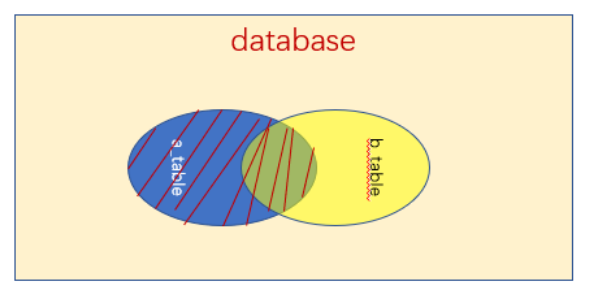
表A连接表B,只保留表A的所有行
right outer join(简写为right join)
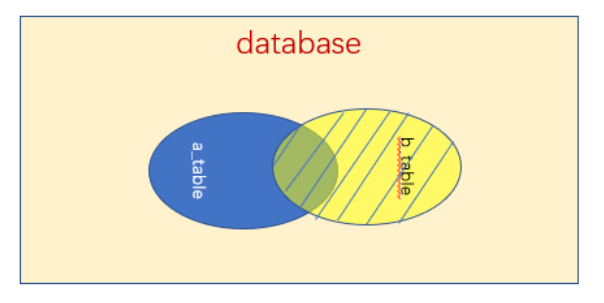
表A连接表B,只保留表B的所有行
full outer join(简写为full join)
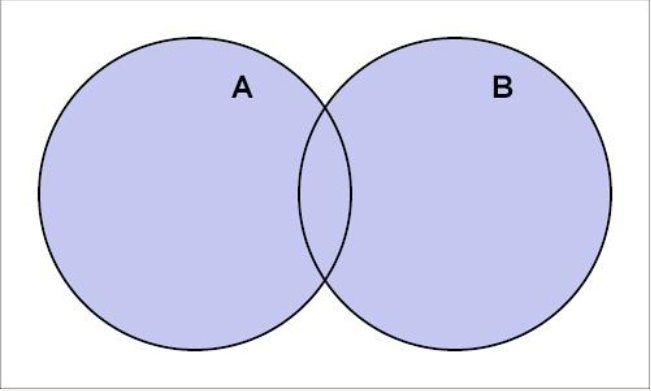
表A连接表B,同时保留表A和表B的所有行
Null
表示“无”、“没有东西”,0会参与计算,而Null则不会,在一些难以避免出现Null的情景,使用is Null、is not null来进行筛选- 可以在查询中使用表达式,如根据日期计算年龄,对某个属性进行计算等,每种数据库都有自己的一套函数,具体可参考相关文档
- 为表达式或者属性名甚至表名赋予一个别名使用关键字
as
3.在查询中进行统计
- 常见统计函数
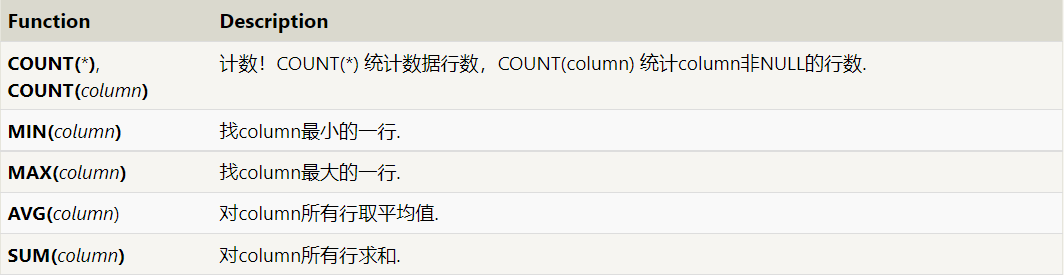
(更多统计函数请参见各数据库文档)
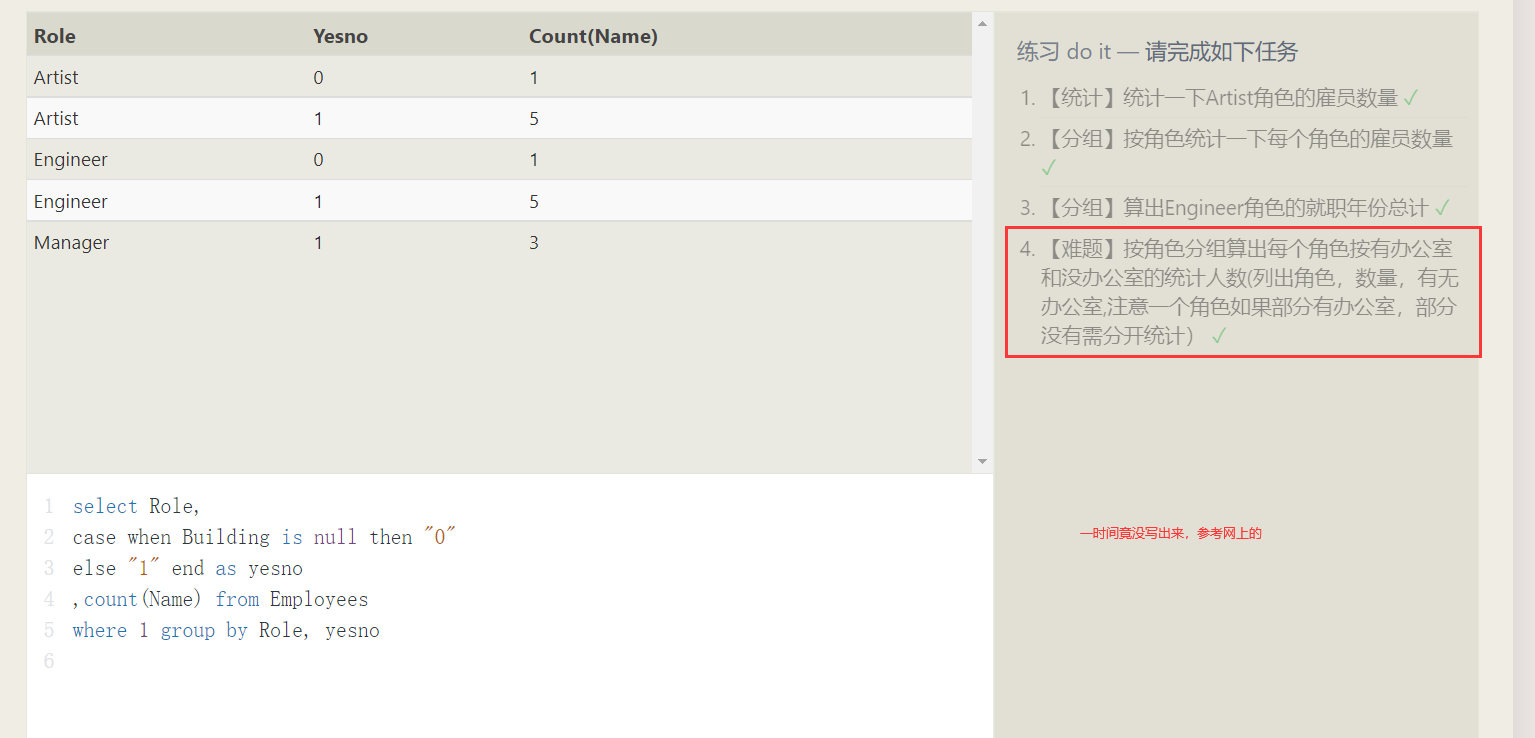
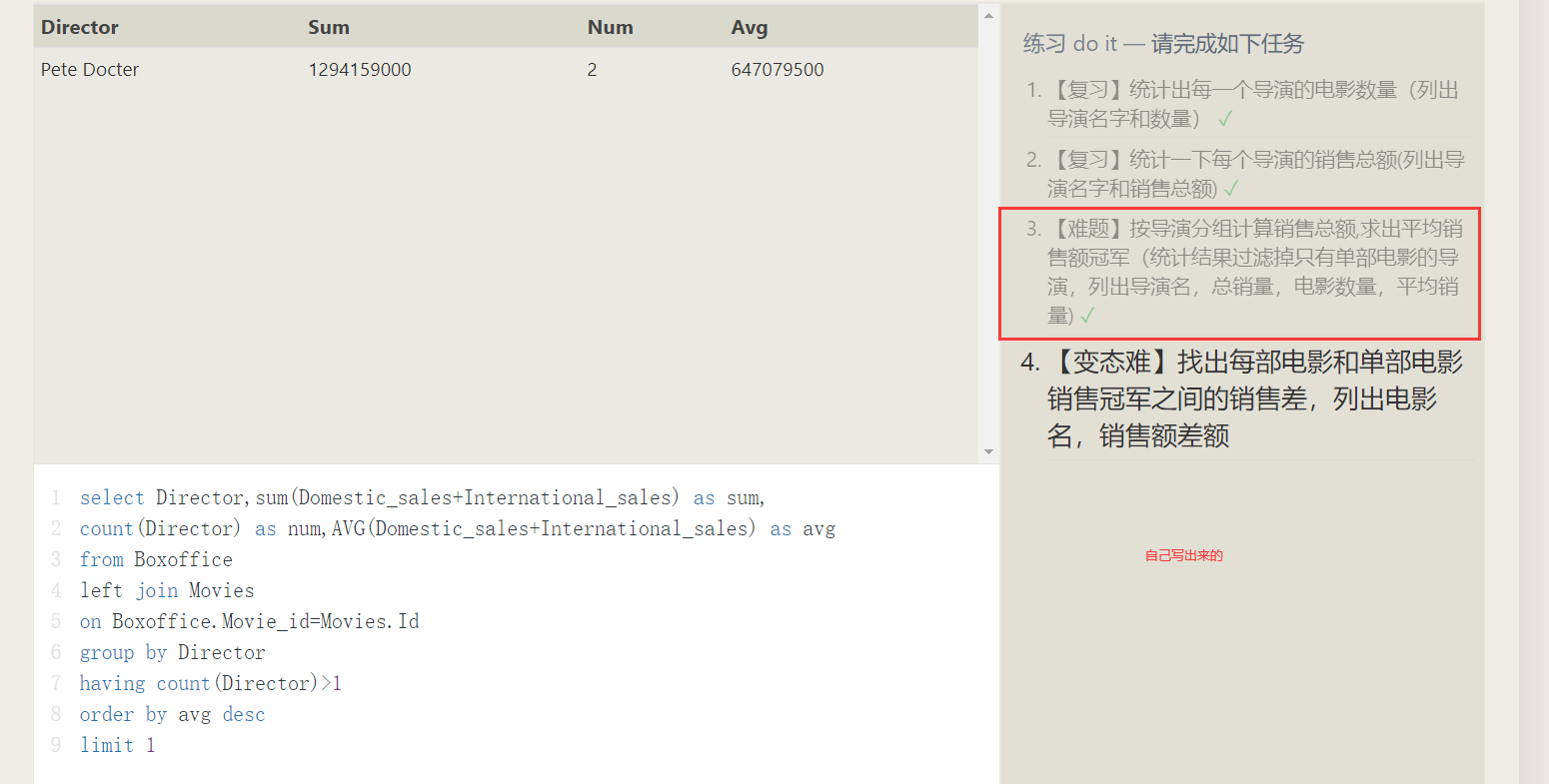
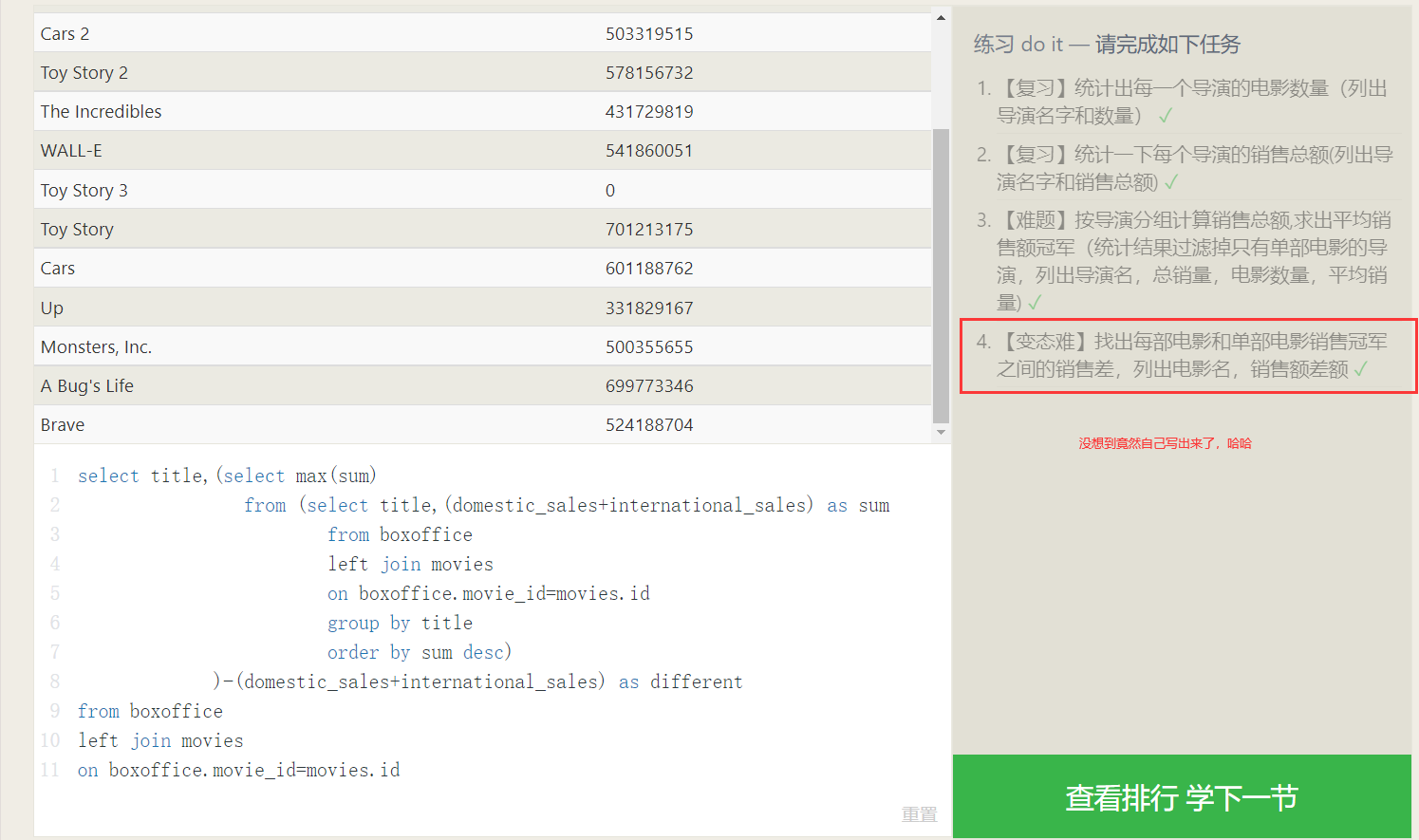
- 分组统计
把统计函数和group by结合,就是对分组内的数据进行统计 - 通常,我们先对数据做
where,然后分组,对分组完的数据进行筛选请使用having
4.查询的执行顺序
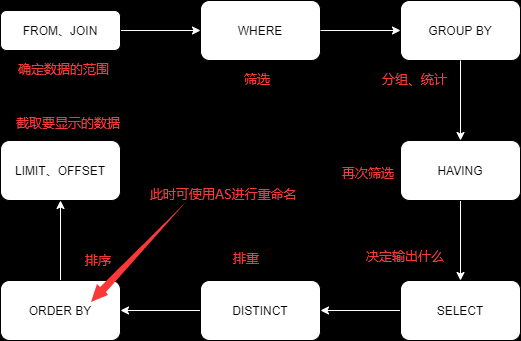
深刻理解SQL的执行顺序能更好地解决数据问题
🧐🧐看似寻常最奇崛,成如容易却艰辛🧐🧐

 浙公网安备 33010602011771号
浙公网安备 33010602011771号