基于Output Distribution的一种数据污染探测方法
Generalization or Memorization: Data Contamination and Trustworthy Evaluation for Large Language Models
摘要:
在当前LLM训练数据不透明,模型黑盒,合成数据增加,作者提出CDD(Contamination Detect via Output Distribution)识别LLM output peakness进而探测数据污染现象和TED(Trustworthy Evaluation via Output Distribution)的LLM output correction。同时作者提出DETCON和COMIEVAL的数据集用于数据污染探测和污染评估任务
一. Introduction
问题:LLM能力的提升究竟是generalization还是memorization
两种数据污染场景:
- 现有Benchmark Datasets:由于大量的text quotes、代码重用、数据合成,已经学习到LLM中
- upcoming benchmark:由于不了解LLM训练细节,构建的数据可能已经在训练集中
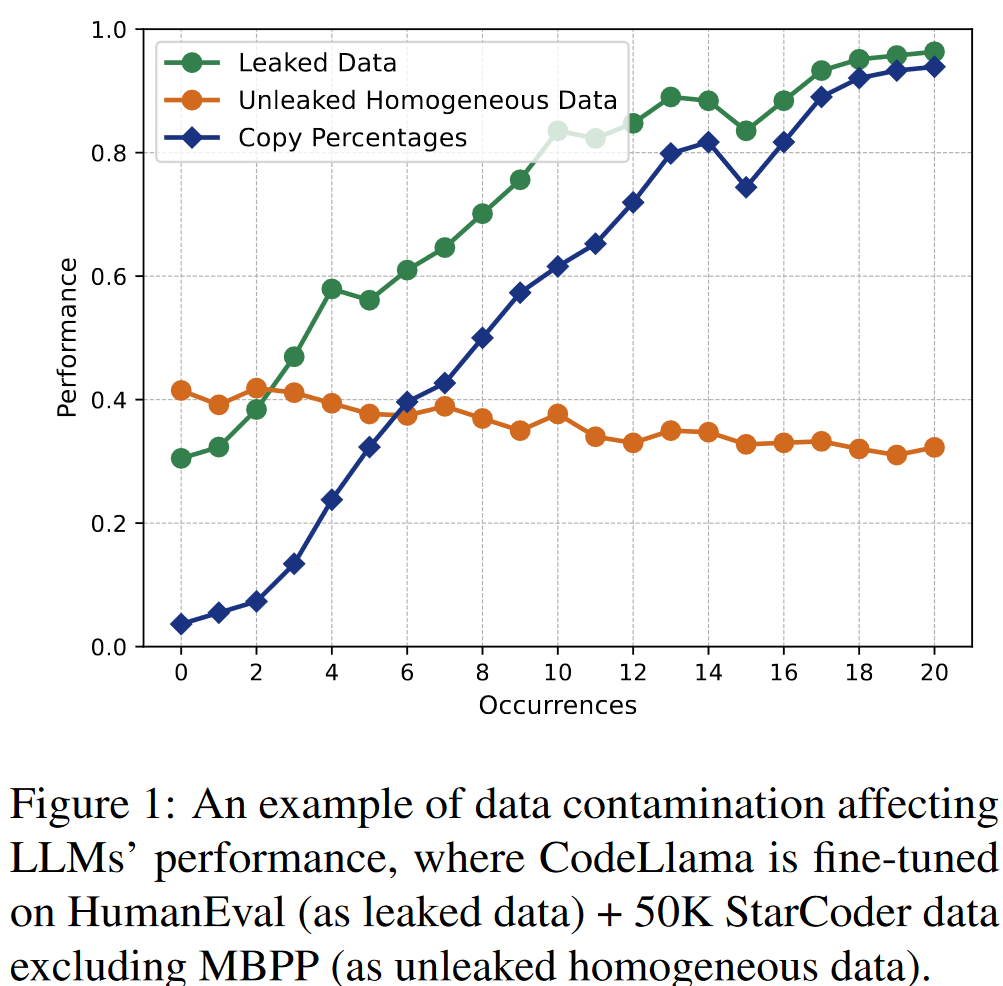
数据污染处理难点:
- Opaque Training Data:数据不公开和全面
- Black Box Models:参数和输出token概率的不可见性
- Proliferation of Syntheic Data:测试数据的变体可能引入到训练数据中
作者提出CDD(识别数据污染)和TED(缓解数据污染)的方法
二. Motivation Example
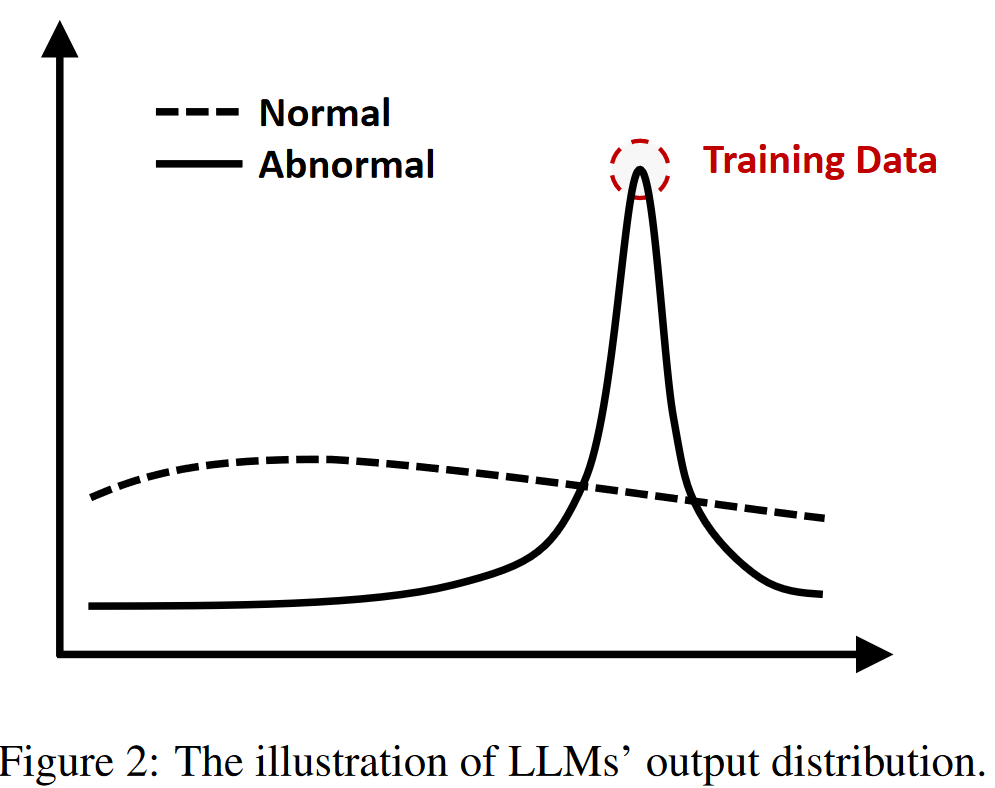
作者基于这样一个发现:当给定pair {x, y}时(x为input prompt,y为answer)时,若该样本未被污染,采样多个output分布会更为平滑。而若该样本被污染,采样多个output会明显存在峰值,且容易集中到y上
三. Methodology
3.1 Edit Distance Distribution

这里的ED其实就是将字符级的编辑距离推广到token级别
之后,给定LLM,基于采样\(S ={s_1,s_2,...,s_n}\)的output集合,并定义output的密度函数如下: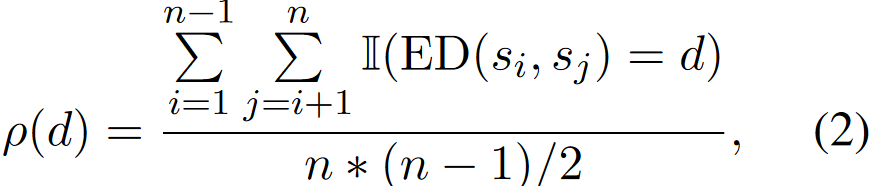
相当于衡量编辑距离为d的样本对有多少个,若p(0)占比较大的话,说明output分布较为集中
3.2 CDD for Data Contamination Detection
给定测试数据 {x, y} 判断是否被污染,基于上述得到变体:
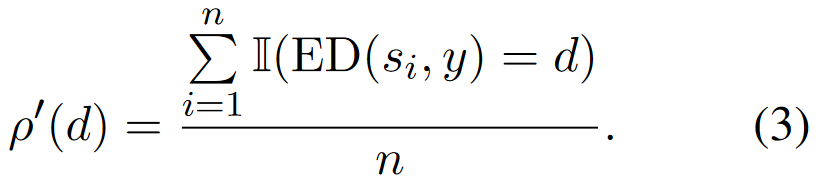
然而考虑到模型可能是基于y的变体而不是y本身进行训练,进一步修改: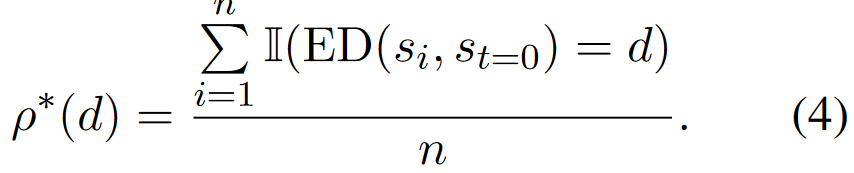
其中\(s_{t=0}\)为设置temperature=0得到的输出,这样得到新的密度函数
同时设置超参数\(\alpha\),有: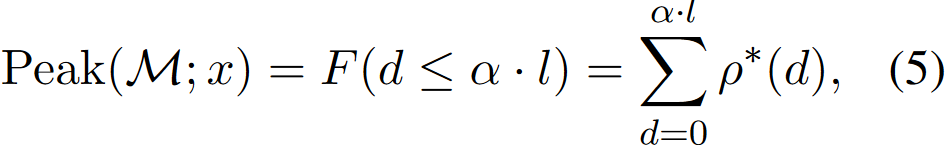
如果output样本明显向\(s_{t=0}\)集中时(即与\(s_{t=0}\)编辑距离较小的样本更多),则认为是污染,否则是未被污染: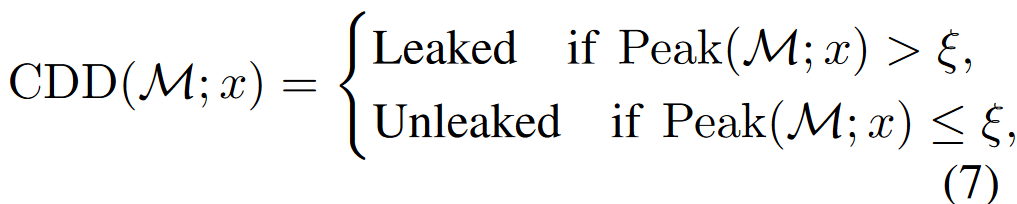
整体的workflow:
3.3 TED for Contamination Mitigation Evaluation
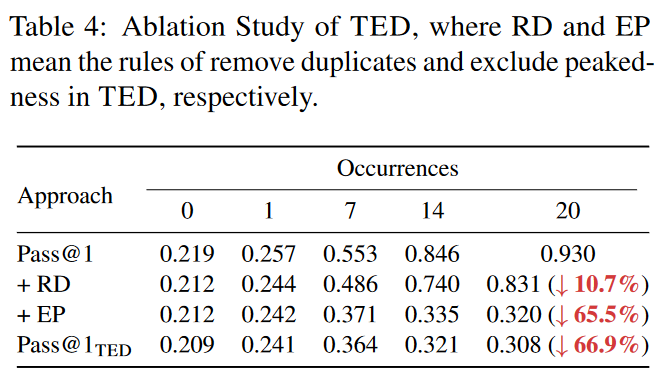
通过在output剔除与\(s_{t=0}\)相似样本(峰值样本)和去重来减少污染程度
- Exclude Peakedness
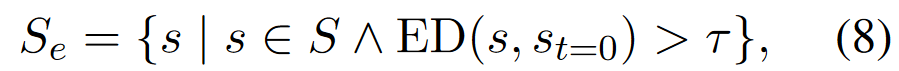
- Remove Duplicates
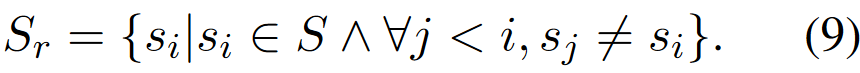
最终通过挑选两个样本集合的交集用于LLM的Evaluation,从而减少数据污染对LLM Evaluation带来的影响
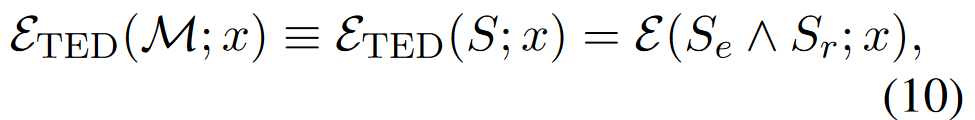

四. Experiment
4.1 Dataset
数据集构建:
两种污染方法:explict/implicit ,三种不同的学习率
四种Mixing Ratio和21中不同程度的污染Occurrences,并基于LoRA实现LLM fine-tune
DETCON
包括2224条任务,随机从leaked dataset选择样本,occurrence 0表示未污染,occurrence 1表示污染
COMIEVAL
包括560条任务和对应的(污染,非污染)模型,要求评估污染模型的性能,并尝试减少数据污染对模型的影响
4.2 Data Contamination Detection
Baseline:1) N-Gram:13 gram (char-level和token-level)
2)Embedding Similarity:基于base model的embedding计算相似度
3)Perplexity:计算original answer的困惑度
4)Min-k% Prob:计算minimum k% token概率
5)LLM Decontaminator:用其他的LLM衡量相似度
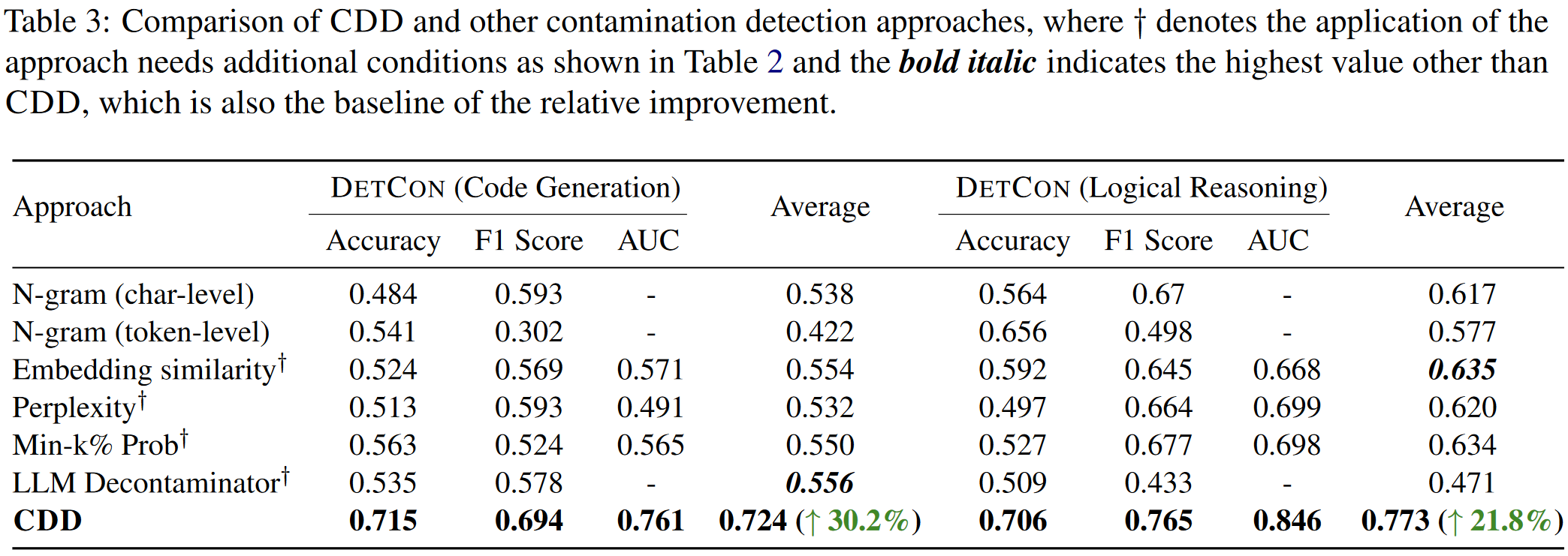
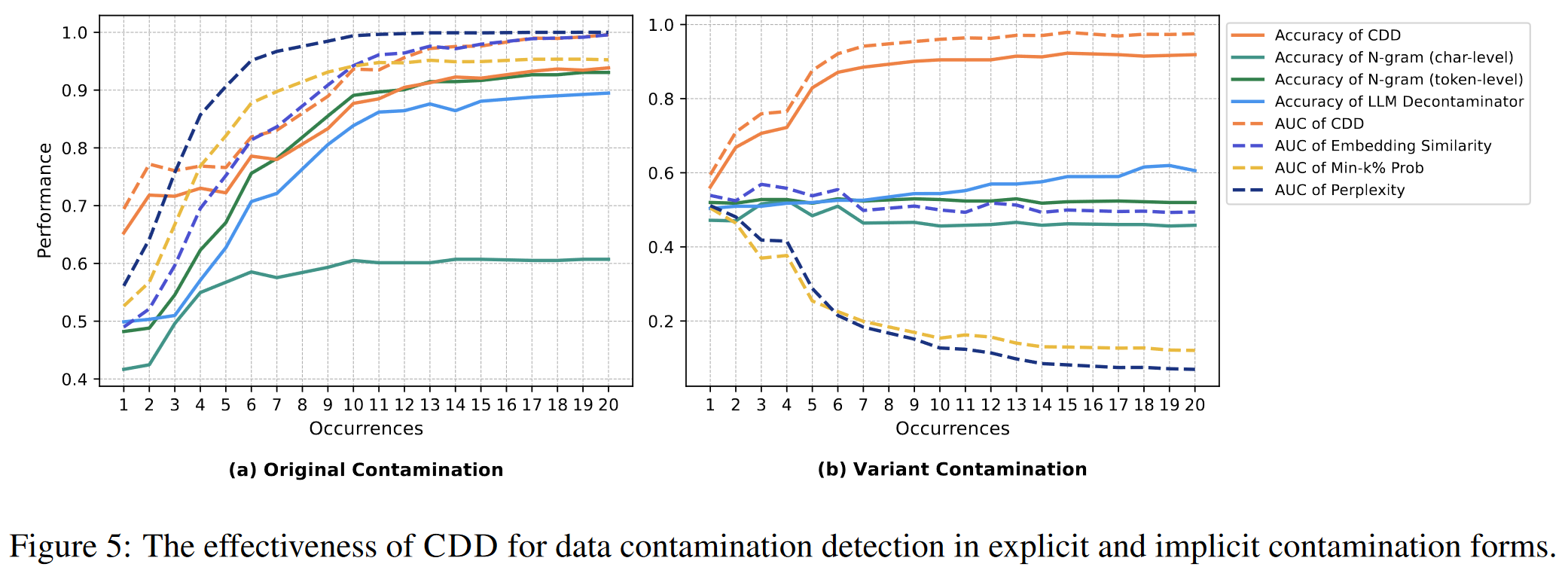
The Effect of CDD:
CDD在显性污染和隐形污染探测中都取得了比较好的效果
超参数设置:
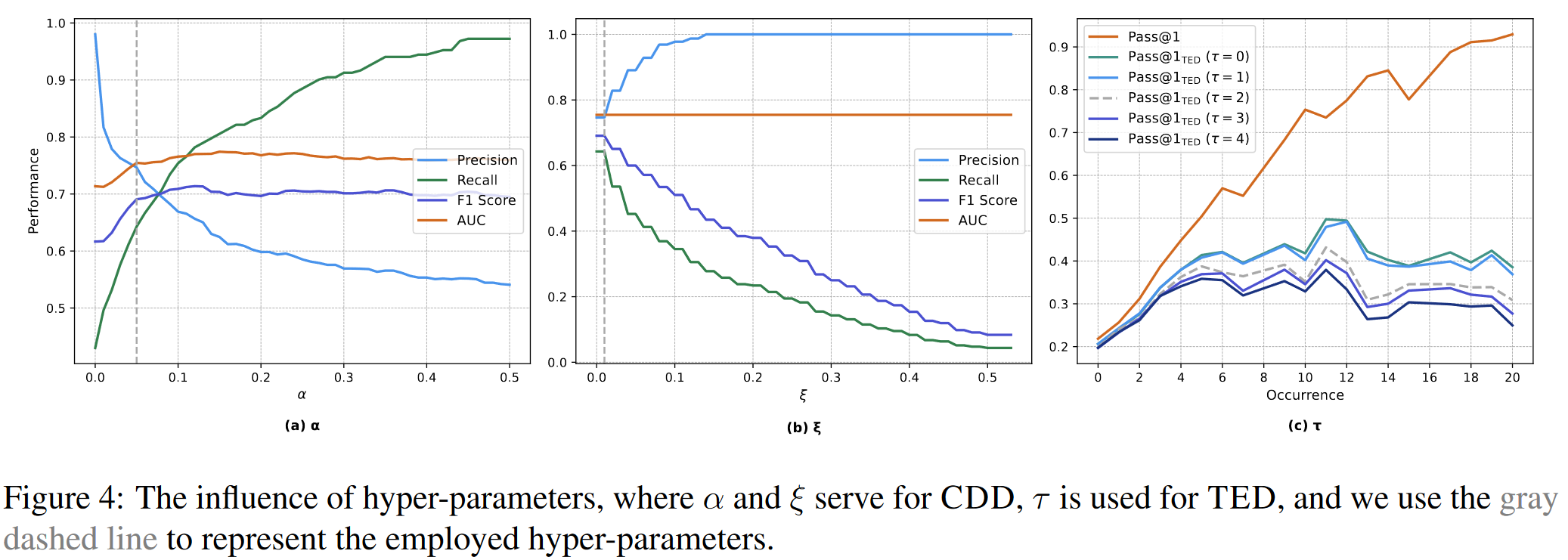
在更好的选择超参数\(\alpha\)和\(\xi\)上,存在进一步提升的空间
4.3 Contamination Mitigation Evaluation
Experimental Setup: 在不同的学习率,LLMs,mixing ratios和contamination forms
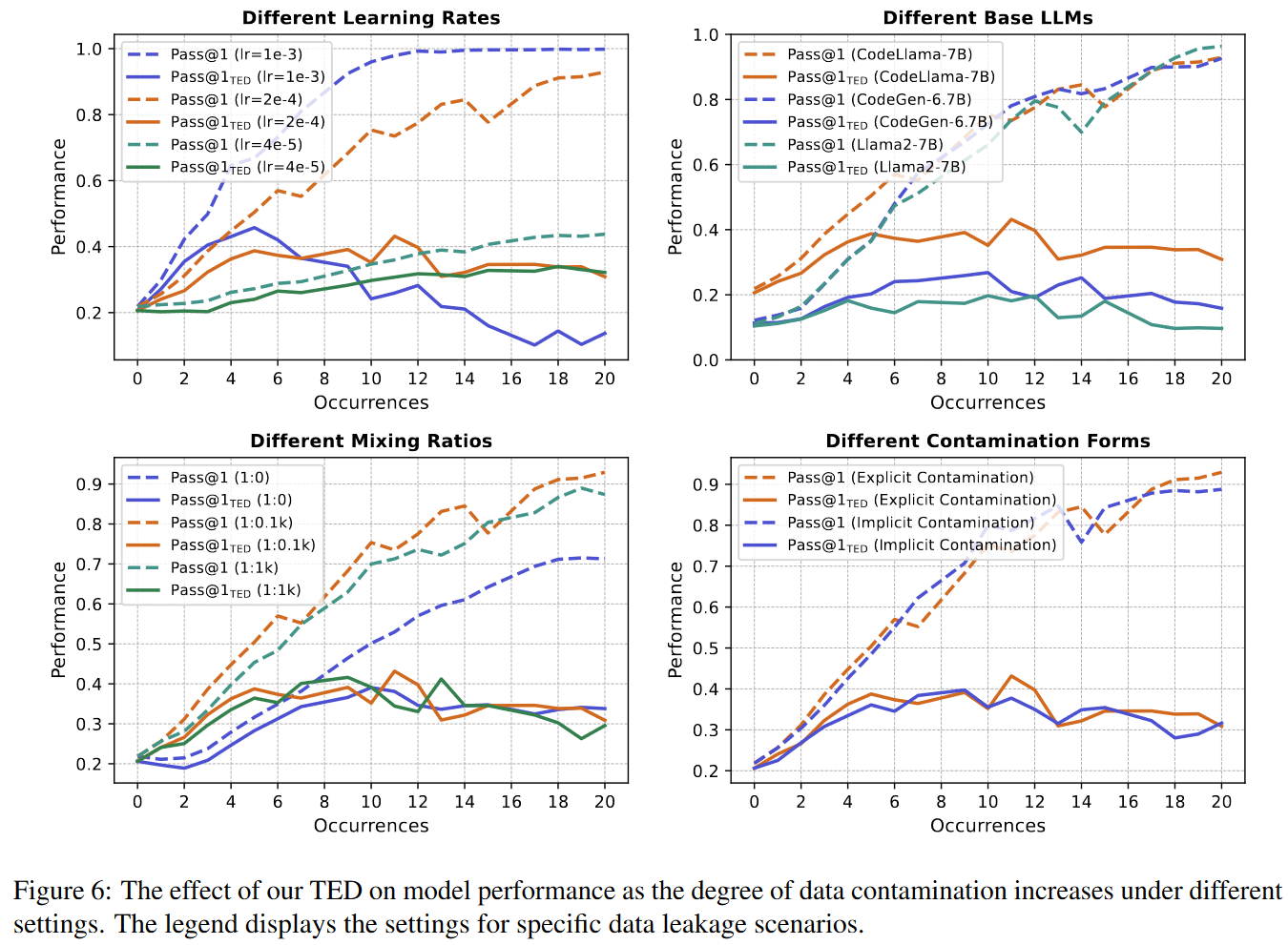
TED策略可以稳步减轻由于不同设置导致的数据污染带来的LLM效果提升
同时TED方法不会减轻未污染模型的性能
4.4 Real-World Application
Experimental Setup:
- CodeForces2305: 90个最简单的编程问题,May 2023在ChatGPT训练deadline之后
- HumanEval_R:HumanEval变体,将function signature变换为German, French和Chinese
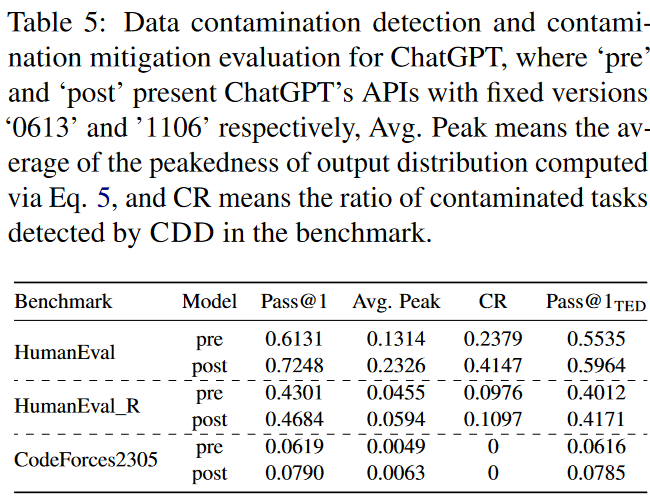
可以发现ChatGPT在不断训练的过程中,Avg. Peak和CR在不断增加
五. Related Work
Data Contamination Detection:
最早期GPT-3提出的13-gram方法
Min-k% Prob:计算前k%最小的token probability
Perplexity:计算生成文本的困惑度
依赖于概率分布
LLM Decontaminator:基于先进LLM检测测试数据和训练数据的相似性
总结:简单但是比较有趣的方法
本文来自博客园,作者:zjz2333,转载请注明原文链接:https://www.cnblogs.com/zjz2333/p/18985667

 浙公网安备 33010602011771号
浙公网安备 33010602011771号