
班级任务数据采集与融合第一次实验报告
数据采集与融合实验报告
作业①
1)实验内容
本实验的主要目标是使用 Python 的 requests 与 BeautifulSoup
库定向爬取"2020中国大学排名"网页数据。页面中包含完整的大学排名表格数据,包括排名、学校名称、省市、学校类型以及综合得分等字段。
程序通过 requests 库发送带有浏览器头部的 HTTP 请求获取网页源码,并使用
BeautifulSoup 解析 HTML 结构。通过查找第一个 <table>
标签,获取所有表格行,并提取每一行的五个核心字段。使用正则表达式清洗学校名称中多余的空格和英文部分。最终将结果转换为
DataFrame 并在控制台打印。
代码说明
from urllib import request
from bs4 import BeautifulSoup
import pandas as pd
import re
#这是我们要爬取的《2020中国大学排名》web
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
#这里是获取HTML文件的过程
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"} #模拟头部
req = request.Request(url, headers=headers) #构造请求对象
resp = request.urlopen(req) #发送请求
html = resp.read().decode("utf-8") #将读取到的HTML文件解码为字符串
soup = BeautifulSoup(html, "lxml") #用 BeautifulSoup 库把 HTML 源码解析成一个 可方便操作的树形结构对象
table = soup.find("table") # 找到第一个 <table> 表格元素。
rows = table.find_all("tr")[1:] # 跳过表头
#这段代码循环解析表格的每一行,提取出大学的排名、名称、省份、类型和得分,并清理文本后保存到列表 data 中,为后续保存成表格或打印输出做准备。
data = []
for row in rows:
cols = row.find_all("td")
if len(cols) >= 5:
rank = cols[0].text.strip()
name = cols[1].text.strip()
name = re.sub(r"\n.*", "", name) # 去掉英文部分
name = re.sub(r"\s+", "", name) # 去掉所有多余空格与换行
province = cols[2].text.strip()
type_ = cols[3].text.strip()
score = cols[4].text.strip()
data.append([rank, name, province, type_, score])
# 转 DataFrame
df = pd.DataFrame(data, columns=["排名", "学校名称", "省市", "学校类型", "总分"])
print("爬取的大学排名信息:")
print(df.to_string(index=False, justify="left"))
结果展示

2)心得体会
通过本实验,我加深了对静态网页结构化数据爬取原理的理解,其实这个网页挺好爬的,没有反爬系统,HTML文件结构也比较清晰。
同时我体会到正确设置网页编码的重要性,否则中文信息容易出现乱码。
整个过程让我体会到Python 爬虫在数据采集中的灵活性和实用性。
作业②
1)实验内容
本实验旨在设计一个针对电商平台的比价爬虫,用以采集"书包"相关商品的名称与价格信息。一开始我使用request获取HTML文件,发现无论这么匹配都只能输出十个,后来问了问AI,他说这个web使用的是动态加载,只用request只能爬取到预加载的页面。如果想要爬取动态页面,就要使用驱动来模拟加载浏览器,后来的翻页也是用驱动实现的
静态版本使用 requests 获取 HTML 文本,通过正则表达式匹配
<div class="pro-img"> 与 <div class="money-fl">结构,提取商品名称与价格。
动态版本使用 Selenium模拟浏览器行为,滚动页面以加载更多数据,再利用正则匹配完成提取。
代码说明(requests 静态版)
#如果只是通过request读取HTML文件,那么就只能获取到静态内容,无法获取动态加载的内容。
import requests
import re
# 指定目标网页URL,此处为以“书包”为关键词的商品搜索结果页
url = "https://search.bl.com/k-%25E4%25B9%25A6%25E5%258C%2585.html?bl_ad=P668822_-_%u4E66%u5305_-_5"
# 构建HTTP请求头信息,用以模拟浏览器访问,防止请求被服务器拒绝
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36",
"Referer": "https://search.bl.com/",
}
# 输出提示信息,指示程序正在进行网页请求
print("正在请求网页...")
# 发送HTTP GET请求以获取网页响应对象
response = requests.get(url, headers=headers, timeout=10)
# 自动检测并设置网页编码格式,防止出现中文乱码
response.encoding = response.apparent_encoding
# 提取网页的HTML源代码文本
html = response.text
# 商品名称位于<img>标签的title或alt属性中
name_pattern = re.compile(r'<div class="pro-img">.*?<img[^>]+(?:title|alt)="(.*?)".*?>', re.S)
# 价格信息包含在<div class="money-fl">¥价格</div>标签中
price_pattern = re.compile(r'<div class="pro-money">.*?<div class="money-fl">¥(.*?)</div>', re.S)
# 分别提取所有符合条件的商品名称与价格,返回列表形式
names = name_pattern.findall(html)
prices = price_pattern.findall(html)
# 输出已成功提取的商品数量
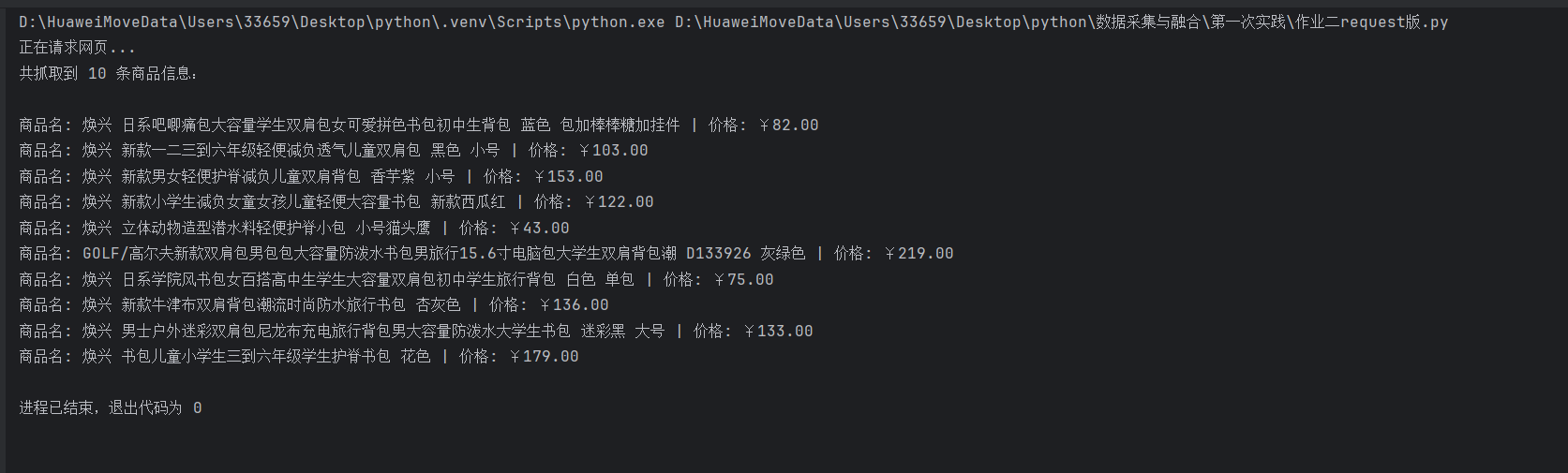
print("共抓取到", len(names), "条商品信息:\n")
# 初始化数据列表,用于存储最终的商品名称与价格数据
data = []
# 遍历提取结果,将商品名称与价格进行配对并输出
for n, p in zip(names, prices):
n = n.strip() # 去除名称字段中的多余空格或换行符
p = p.strip() # 去除价格字段中的多余空格或换行符
print(f"商品名: {n} | 价格: ¥{p}")
data.append([n, p]) # 将结果以列表形式追加到数据集中
结果展示
代码说明(Selenium 动态版)
#在爬取网页时,某些内容是通过JavaScript动态加载的,传统的requests库无法获取这些动态内容。
#为了解决这个问题,我们可以使用Selenium库,它能够模拟真实用户的浏览器操作,从而获取完整的网页内容。
import time
import re
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 指定本地 ChromeDriver 的绝对路径
chrome_driver_path = r"D:\HuaweiMoveData\Users\33659\Desktop\python\chromedriver-win64\chromedriver.exe"
# 通过 Service 类指定 ChromeDriver 服务对象
service = Service(chrome_driver_path)
# 初始化并启动 Chrome 浏览器实例
driver = webdriver.Chrome(service=service)
# 打开测试网页(可选步骤,用于验证浏览器是否正常启动)
driver.get("https://example.com")
# 定义目标网页的URL,此处为以“书包”为关键词的商品搜索结果页
url = "https://search.bl.com/k-%25E4%25B9%25A6%25E5%258C%2585.html?bl_ad=P668822_-_%u4E66%u5305_-_5"
driver.get(url)
# 等待网页加载完成,确保页面内容完全渲染
time.sleep(5)
# 模拟用户滚动操作,以触发动态加载更多商品信息
for _ in range(5):
driver.execute_script("window.scrollBy(0, 1000);") # 向下滚动1000像素
time.sleep(2)
# 获取网页的完整HTML源代码
html = driver.page_source
# 名称位于<img>标签的title或alt属性中
name_pattern = re.compile(r'<div class="pro-img">.*?<img.*?(?:title|alt)="(.*?)".*?>', re.S)
# 价格信息在<div class="money-fl">¥价格</div>标签中
price_pattern = re.compile(r'<div class="pro-money">.*?<div class="money-fl">¥(.*?)</div>', re.S)
# 分别匹配网页中所有的商品名称与价格,返回列表形式
names = name_pattern.findall(html)
prices = price_pattern.findall(html)
# 遍历并输出提取到的商品信息
for n, p in zip(names, prices):
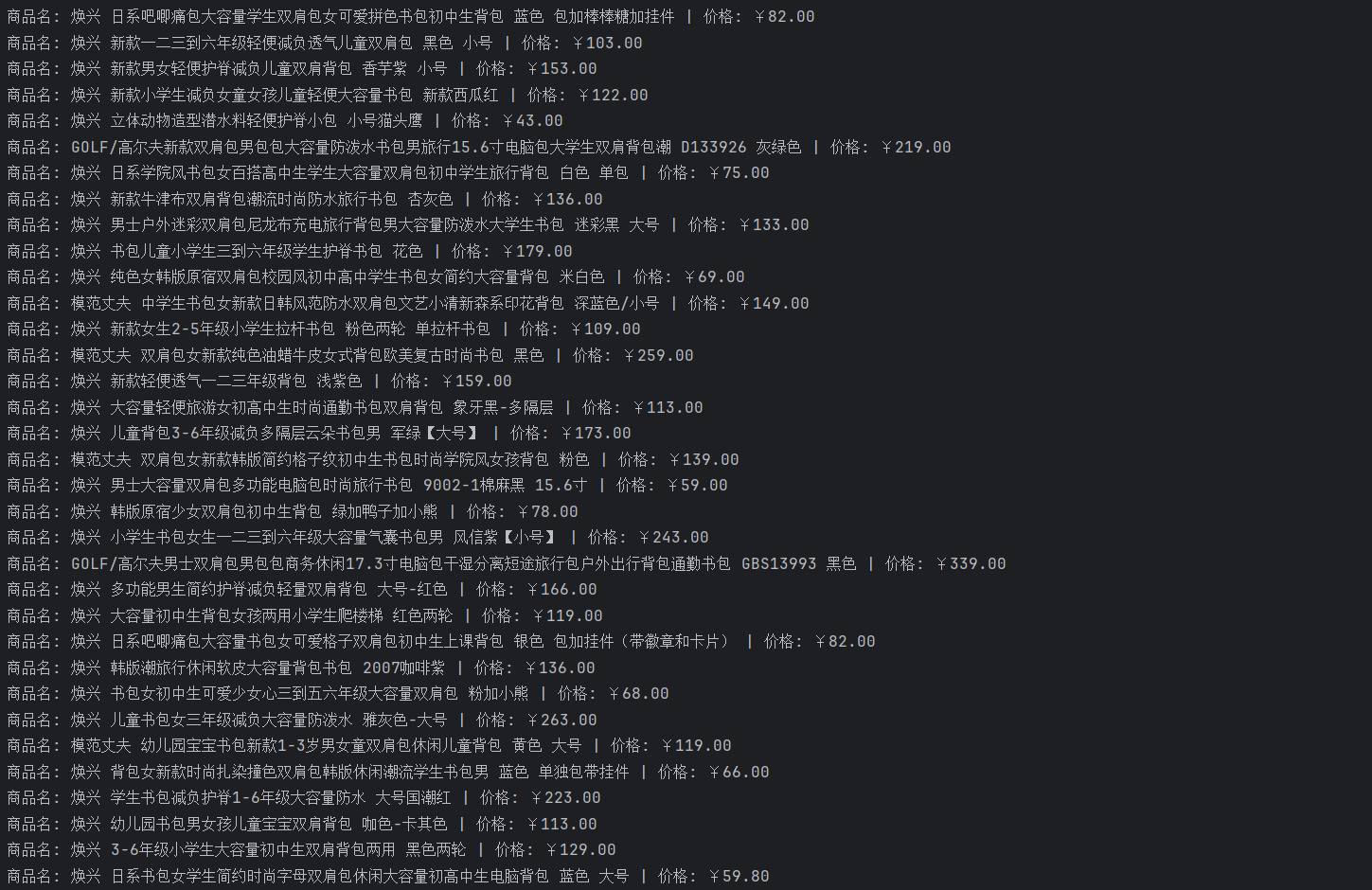
print(f"商品名: {n} | 价格: ¥{p}")
# 关闭浏览器,释放资源
driver.quit()
结果展示

2)心得体会
通过对比静态与动态爬虫,我理解了不同网页加载方式下的爬取策略差异。
requests 适合直接获取固定 HTML,而 Selenium 能模拟浏览器行为、加载
JavaScript 内容。
作业③
1)实验内容
本实验任务是从福州大学新闻网"扬帆掠影"栏目爬取所有 JPG、JPEG、PNG
图片并保存到本地。
程序遍历多个分页链接,使用 requests 获取网页内容,通过正则表达式匹配
<ul class="clearfix"> 块中的 <img> 标签,提取图片链接。再使用
urljoin 拼接完整路径,逐一下载并保存到指定文件夹。
代码说明
import re
import os
import requests
from urllib.parse import urljoin
# 配置目标网页信息
base_urls = [
"https://news.fzu.edu.cn/yxfd.htm", # 第1页
"https://news.fzu.edu.cn/yxfd/5.htm", # 第2页
"https://news.fzu.edu.cn/yxfd/4.htm", # 第3页
"https://news.fzu.edu.cn/yxfd/3.htm", # 第4页
"https://news.fzu.edu.cn/yxfd/2.htm", # 第5页
"https://news.fzu.edu.cn/yxfd/1.htm" # 第6页
]
# 定义网页的基础域名,用于拼接相对路径
base_domain = "https://news.fzu.edu.cn/"
# 指定图片的本地保存路径,如不存在则自动创建
save_dir = "fzu_yxfd_images"
os.makedirs(save_dir, exist_ok=True)
# ② 定义获取网页HTML内容的函数
def get_html(url):
"""
功能:向指定URL发送HTTP请求,返回网页HTML文本
参数:
url (str):网页地址
返回:
str:网页源代码(若请求失败则返回空字符串)
"""
try:
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
resp = requests.get(url, headers=headers, timeout=10)
resp.encoding = resp.apparent_encoding # 自动识别编码,避免中文乱码
return resp.text
except Exception as e:
print(f"获取 {url} 失败: {e}")
return ""
# ③ 定义提取图片链接的函数(使用正则表达式)
def extract_img_links(html):
"""
功能:从HTML文本中提取图片文件链接
处理流程:
1. 定位<ul class="clearfix"> ... </ul>块
2. 在块内查找所有<img src="...">标签
3. 拼接完整图片URL并去重
参数:
html (str):网页源代码
返回:
list:完整图片URL列表
"""
# 匹配所有<ul class="clearfix">...</ul>区域
ul_blocks = re.findall(
r'<ul\s+class=["\']clearfix["\'][^>]*>(.*?)</ul>',
html,
re.IGNORECASE | re.DOTALL
)
img_links = []
# 匹配图片链接(支持jpg/jpeg/png/gif/webp格式)
img_pattern = re.compile(
r'src=["\']([^"\']+\.(?:jpg|jpeg|png|gif|webp))(?:\?[^"\']*)?["\']',
re.IGNORECASE
)
# 在每个<ul>块中提取图片地址并补全为绝对路径
for block in ul_blocks:
matches = img_pattern.findall(block)
for link in matches:
full_url = urljoin(base_domain, link)
img_links.append(full_url)
# 返回去重后的图片链接列表
return list(set(img_links))
# ④ 定义图片下载函数
def download_image(url):
"""
功能:根据图片URL下载并保存到本地目录
参数:
url (str):图片的完整网络地址
"""
try:
# 提取文件名并确定本地保存路径
filename = url.split("/")[-1].split("?")[0]
filepath = os.path.join(save_dir, filename)
# 若文件已存在则跳过
if os.path.exists(filepath):
print(f"已存在:{filename}")
return
# 发送请求并保存图片数据
img_data = requests.get(url, timeout=10).content
with open(filepath, "wb") as f:
f.write(img_data)
print(f"下载成功:{filename}")
except Exception as e:
print(f"下载失败 {url}: {e}")
# ⑤ 主程序执行流程
all_img_links = set() # 用于存放所有图片的去重集合
# 遍历配置的每个网页地址并提取图片链接
for i, page_url in enumerate(base_urls, start=1):
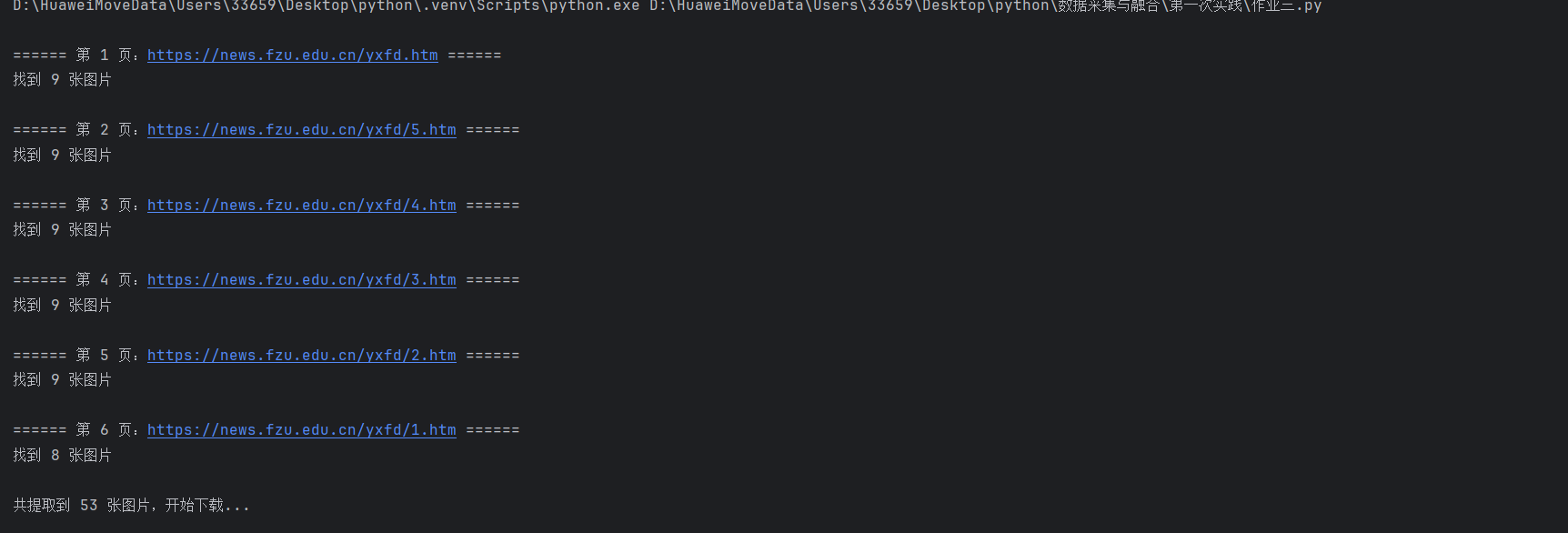
print(f"\n====== 第 {i} 页:{page_url} ======")
html = get_html(page_url)
if not html:
continue # 若网页获取失败则跳过
img_links = extract_img_links(html)
print(f"找到 {len(img_links)} 张图片")
# 将本页图片链接加入总集合
all_img_links.update(img_links)
# 输出总共提取的图片数量并开始下载
print(f"\n共提取到 {len(all_img_links)} 张图片,开始下载...\n")
# 按顺序下载所有图片
for idx, link in enumerate(all_img_links, start=1):
print(f"[{idx}/{len(all_img_links)}] 正在下载:{link}")
download_image(link)
# 下载完成后的提示信息
print(f"\n所有图片已保存到文件夹: {os.path.abspath(save_dir)}")
结果展示
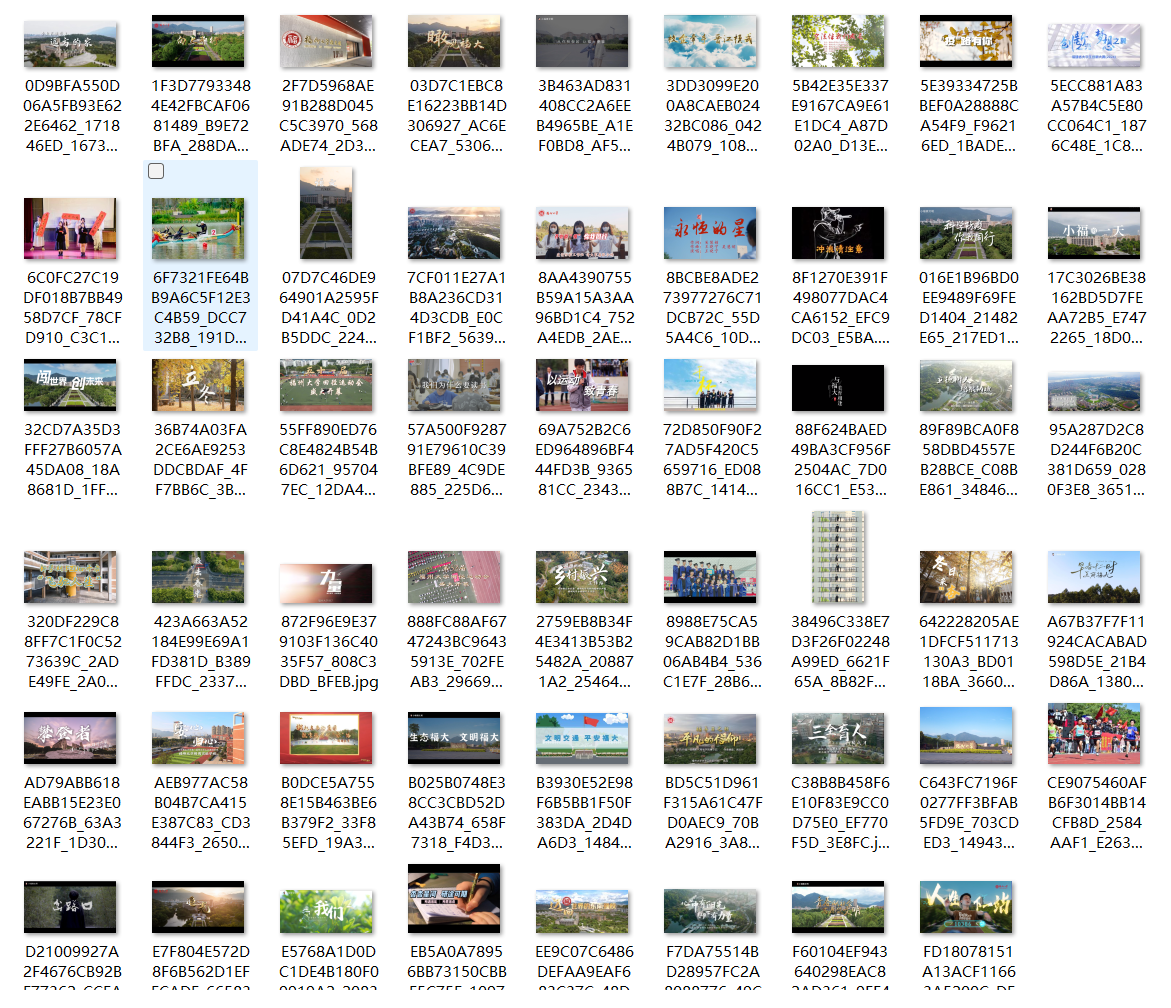
2)心得体会
图片下载实验让我掌握了网页中多媒体资源的采集方法。
相比文字数据,图片爬取更需要处理网络超时、文件重名及路径拼接等问题。
通过正则匹配<img src>,结合异常处理机制,我实现了稳健的图片下载流程。
本实验让我进一步理解了爬虫在多媒体信息获取中的应用价值,也增强了我对正则表达式的灵活使用能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号