

keras快速上手学习笔记
目录:
- keras后端配置
- keras深度学习概述
- Keras 架构
- Keras 模块
- Keras 层
- Keras 自定义层
- Keras 模型
- Keras 模型编译
- Keras 模型评估和模型预测
- Keras 卷积神经网络
- Keras MPL 进行回归预测
- Keras 使用 LSTM进行时间序列预测
- Keras 应用模块
keras后端配置
一旦我们执行 Keras,就可以看到配置文件位于你的主目录里面,下面点开.keras/keras.json文件。
{
"image_data_format":"channels_last",
"epsilon":1e-07,
"floatx":"float32",
"backend":"tensorflow"
}
这里面:
- image_data_format: 表示图像数据格式,默认'channels_last'
- epsilon :表示数字常量,用于避免 DivideByZero 错误。
- floatx :表示默认数据类型 float32。此外,还可以用 set_floatx() 方法将其更改为 float16 或者 float64。
- backend :表示后端配置。
假设,如果还没有创建文件,则可以移动到该位置并用以下步骤创建:
>cd home >mkdir .keras >vi keras.json
注意:指定 .keras 作为其文件夹名称,并在 keras.json 文件中添加上述的配置。这样,我们才可以执行一些预定义的操作来了解后端功能。
默认情况下,keras 使用 TensorFlow 后端。如果想要把后端配置从 TensorFlow 改为 Theano,只需要更改 keras.json 文件中的 backend = theano 即可。它的描述具体如下:
keras.json
{
"image_data_format": "channels_last",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "theano"
}
接下来,保存你的文件,重新启动终端并启动 Keras,你的后端就会被更改。
keras深度学习概述
让我们首先了解深度学习的不同阶段,然后了解 Keras 如何在深度学习过程中提供帮助。
- 收集所需数据,深度学习需要大量输入数据才能成功学习和预测结果。因此,首先要收集尽可能多的数据。
- 分析数据 ,分析数据并获得对数据的良好理解。需要更好地理解数据才能选择正确的 ANN 算法。
- 选择算法(模型), 选择最适合学习过程类型(例如图像分类、文本处理等)和可用输入数据的算法。模型在Keras中用Model表示。模型包括一层或多层。ANN中的每一层都可以用Keras中的Keras层表示。
- 准备数据 - 处理、过滤和仅从数据中选择所需的信息。
- 拆分数据 - 将数据拆分为训练和测试数据集。测试数据将用于评估算法/模型的预测(一旦机器进行了学习)并交叉检查学习过程的效率。
- 编译模型 - 编译算法/模型,以便通过训练进一步学习并最终进行预测。这一步需要我们选择损失函数和优化器。在学习阶段使用损失函数和优化器来发现错误(与实际输出的偏差)并进行优化,以使错误最小化。
- 拟合模型 - 实际学习过程将在此阶段使用训练数据集完成。
- 预测未知值的结果 - 预测未知输入数据的输出(现有训练和测试数据除外)
- 评估模型 - 通过预测测试数据的输出并将预测与测试数据的实际结果进行交叉比较来评估模型。
- 冻结、修改或选择新模型 - 检查模型评估是否成功。如果是,请保存模型以备将来预测之用。如果不是,则修改或选择新的算法/模型,最后再次训练、预测和评估模型。重复该过程,直到找到最佳算法(模型)。
Keras 架构
Keras API 可以分为三个主要类别:
- 模型,在 Keras 中,每个网络都由Keras模型表示。
- 层,反过来,每个 Keras 模型都是由Keras层组成,代表人工神经网络的层,如输入、隐藏层、输出层、卷积层、池化层等,
- 核心模块,Keras模型和层访问Keras模块,用于激活函数、损失函数、正则化函数等
使用 Keras 模型、Keras 层和 Keras 模块,可以以简单有效的方式表示任何 ANN 算法(CNN、RNN 等)。
模型:
Keras 模型由两种类型:
- 顺序模型(Sequential Model),顺序模型基本上是 Keras 层的线性组合。序列模型简单、最小,并且能够表示几乎所有可用的神经网络。一个简单的顺序模型如下 :
from keras.models import Sequential from keras.layers import Dense model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,)))
-
- 第 1 行 从 Keras 模型导入Sequential模型
- 第 2 行 导入Dense层
- 第 3 行 使用Sequential API创建一个新的顺序模型
- 第 4 行 添加了具有relu激活(使用 Activation 模块)功能的密集层(Dense API)
顺序模型公开了Model类供我们创建自定义模型。我们可以使用子分类概念来创建我们自己的复杂模型。
- 功能 API,功能 API 基本上用于创建复杂的模型。
层:
Keras 模型中的每个 Keras 层代表实际提出的神经网络模型中的对应层(输入层、隐藏层和输出层)。Keras 提供了很多预构建层,因此可以轻松创建任何复杂的神经网络。下面指定了一些重要的 Keras 层,
- 核心层(Core)
- 卷积层(Convolution)
- 池化层(Pooling)
- 循环层(Recurrent)
from keras.models import Sequential from keras.layers import Dense, Activation, Dropout model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,))) model.add(Dropout(0.2)) model.add(Dense(512, activation = 'relu')) model.add(Dropout(0.2)) model.add(Dense(num_classes, activation = 'softmax'))
Keras 还提供了创建我们自己的自定义层的选项。自定义层可以通过对 Keras.Layer类进行子分类来创建,它类似于对 Keras 模型进行子分类。
核心模块:
Keras 还提供了很多内置的神经网络相关函数来正确创建 Keras 模型和 Keras 层。一些功能如下:
- 激活(Activation)模块, 激活函数是 ANN 中的一个重要概念,激活模块提供了许多激活函数,如:softmax、relu等,
- 损失(Loss)模块,损失模块提供损失函数,如:mean_squared_error、mean_absolute_error、poisson等,
- 优化器(Optimizer)模块,优化器模块提供优化器功能,如:adam、sgd等,
- 正则化器(Regularizers), 正则化器模块提供L1正则化器、L2正则化器等功能,
Keras 模块
正如我们之前了解到的,Keras 模块包含对深度学习算法有用的预定义类、函数和变量。本章让我们学习 Keras 提供的模块。
让我们先看看 Keras 中可用的模块列表:
- 初始化, 提供初始化函数列表,我们可以在 Keras 层 章节中详细了解它,在机器学习的模型创建阶段。
- 正则化器, 提供正则化器功能列表。我们可以在 Keras 层 章节中详细了解它。
- 约束, 提供约束功能列表。我们可以在 Keras 层 章节中详细了解它。
- 激活器, 提供激活器功能列表。我们可以在 Keras 层 章节中详细了解它。
- 损失, 提供损失函数列表。我们可以在模型编译章节中详细了解它。
- 指标, 提供指标功能列表。我们可以在模型编译章节中详细了解它。
- 优化器, 提供优化器功能列表。我们可以在模型编译章节中详细了解它。
- 回调 ,提供回调函数列表。我们可以在训练过程中使用它来打印中间数据以及根据某些条件停止训练本身(EarlyStopping方法)。
- 文本处理, 提供将文本转换为适合机器学习的 NumPy 数组的功能。我们可以在机器学习的数据准备阶段使用它。
- 图像处理, 提供将图像转换为适合机器学习的 NumPy 数组的功能。我们可以在机器学习的数据准备阶段使用它。
- 序列处理, 提供从给定输入数据生成基于时间的数据的功能。我们可以在机器学习的数据准备阶段使用它。
- 后端,提供后端库的功能,如TensorFlow和Theano。
- 公用程序utils, 提供许多在深度学习中有用的效用函数。
后端模块:
用于 keras 后端操作。默认情况下,keras 在 TensorFlow 后端之上运行。如果需要,您可以切换到其他后端,如 Theano 或 CNTK。默认后端配置在根目录中的.keras/keras.json文件下定义。 可以使用以下代码导入Keras后端模块:
>>> from keras import backend as k
如果我们使用默认后端TensorFlow,则以下函数将返回基于TensorFlow的信息,如下所示:
>>> k.backend() 'tensorflow' >>> k.epsilon() 1e-07 >>> k.image_data_format() 'channels_last' >>> k.floatx() 'float32'
让我们简要了解一些用于数据分析的重要后端功能:
- get_uid() 它是默认图形的标识符,定义如下:
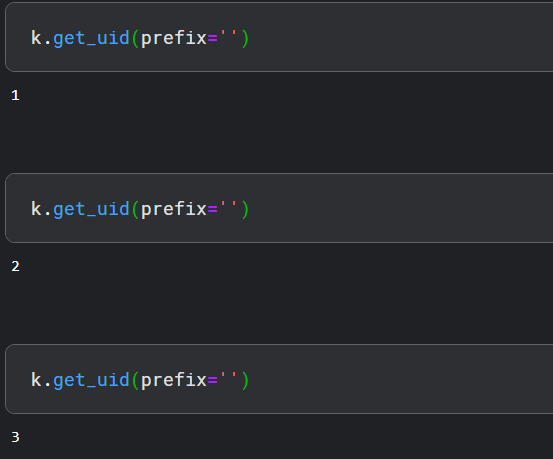
- reset_uids(),它用于重置 uid 值。
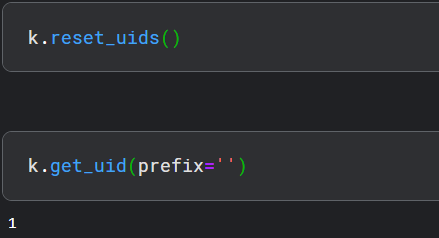
k.reset_uids()
现在,再次执行get_uid(),这将会被重置为1:
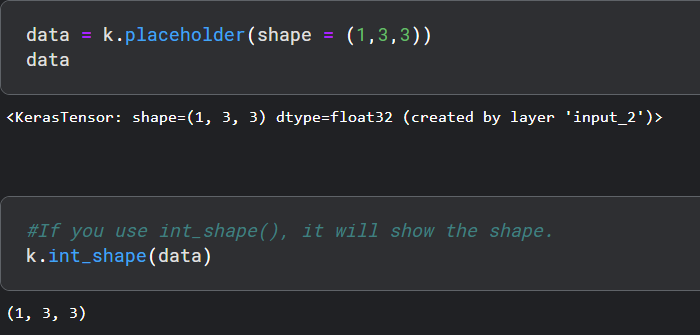
- 占位符 ,它用于实例化占位符张量,保持 3-D 形状的简单占位符如下所示:
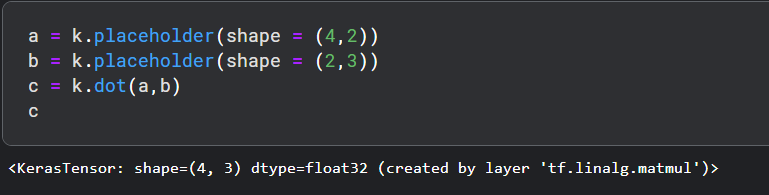
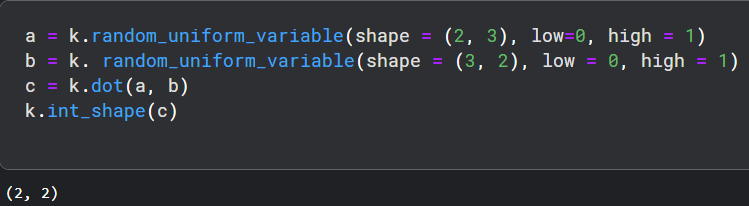
- dot ,它用于将两个张量相乘。考虑a和b是两个张量,c将是ab相乘的结果。假设a形状是(4,2),b形状是(2,3)。它定义如下,
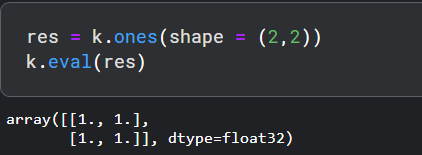
- ones, 它用于将所有初始化为1。
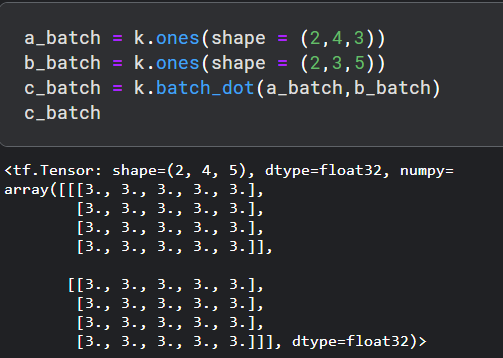
- batch_dot ,用于批量执行两个数据的乘积。输入维度必须为 2 或更高。如下所示:
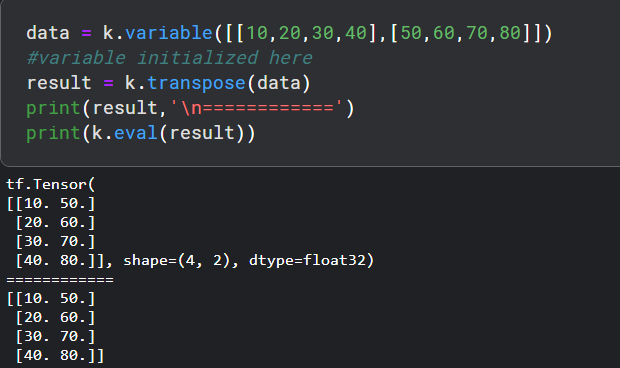
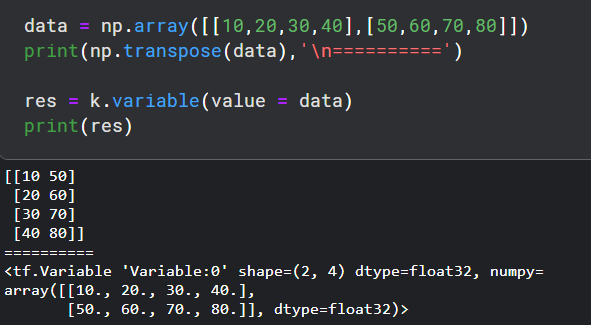
- transpose, 它用于初始化变量。让我们在这个变量中执行简单的转置操作。
- is_sparse(tensor), 它用于检查张量是否稀疏。
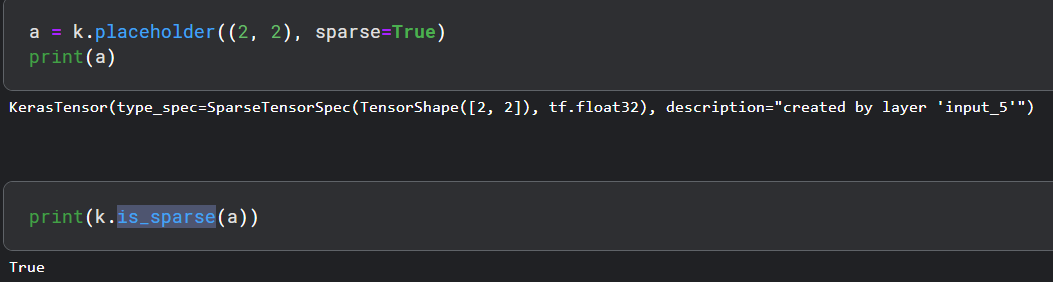
- to_dense() 它用于将稀疏转换为密集。

- random_uniform_variable, 它用于使用 均匀分布 概念进行初始化。
utils模块:
utils为深度学习提供了有用的实用程序功能。utils模块提供的一些方法如下:
- HDF5矩阵 ,它用于表示 HDF5 格式的输入数据。
from keras.utils import HDF5Matrix
data = HDF5Matrix('data.hdf5', 'data')
- to_categorical, 它用于将类向量转换为二进制类矩阵。
>>> from keras.utils import to_categorical >>> labels = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> to_categorical(labels) array([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 1., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]], dtype = float32) >>> from keras.utils import normalize >>> normalize([1, 2, 3, 4, 5]) array([[0.13483997, 0.26967994, 0.40451992, 0.53935989, 0.67419986]])
- print_summary(打印摘要), 它用于打印模型的摘要。
from keras.utils import print_summary print_summary(model)
- plot_model(绘图模型) ,它用于以点格式创建模型表示并将其保存到文件。
from keras.utils import plot_model plot_model(model,to_file = 'image.png')
此plot_model将生成图像以了解模型的性能。
Keras 层
如前所述,Keras 层是 Keras 模型的主要构建块。每一层接收输入信息,做一些计算,最后输出转换后的信息。一层的输出将作为输入流入下一层。我们将在本章中了解有关图层的完整详细信息。
Keras 层需要输入的形状 (input_shape)来理解输入数据的结构,初始化器为每个输入设置权重,最后激活器来转换输出以使其非线性。在这两者之间,约束限制并指定要生成的输入数据的权重范围,正则化器将通过在优化过程中动态应用权重的惩罚来尝试优化层(和模型)。
总而言之,Keras 层需要不低于最低限度的细节来创建一个完整的层。
- 输入数据的形状
- 层中神经元/单元的数量
- 初始化程序
- 正则化器
- 约束
- 激活
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers from keras import regularizers from keras import constraints model = Sequential() model.add(Dense(32, input_shape=(16,), kernel_initializer = 'he_uniform', kernel_regularizer = None, kernel_constraint = 'MaxNorm', activation = 'relu')) model.add(Dense(16, activation = 'relu')) model.add(Dense(8))
第 10 行 创建一个新的 Dense 层并将其添加到模型中。Dense 是 Keras 提供的入门级层,它接受神经元或单元(32)的数量作为其所需参数。如果图层是第一层,那么我们还需要提供Input Shape, (16,)。否则,上一层的输出将用作下一层的输入。所有其他参数都是可选的。要创建模型的第一层(或模型的输入层),应指定输入数据的形状。
初始化:
在机器学习中,权重将分配给所有输入数据。Initializers 模块提供了不同的函数来设置这些初始权重。一些 Keras Initializer 函数如下:
- Zeros() ,所有输入数据生成0。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.Zeros() model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init))
其中,kernel_initializer表示模型内核的初始化程序。
- Ones() ,所有输入数据生成1。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.Ones() model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init))
- Constant ,所有输入数据生成用户指定的常量值(例如5)。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.Constant(value = 0) model.add( Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init) )
其中,value表示常数值
- RandomNormal, 使用输入数据的正态分布生成值。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.RandomNormal(mean=0.0, stddev = 0.05, seed = None) model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init))
- RandomUniform ,使用输入数据的均匀分布生成值。
from keras import initializers my_init = initializers.RandomUniform(minval = -0.05, maxval = 0.05, seed = None) model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init))
- TruncatedNormal, 使用输入数据的截断正态分布生成值。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.TruncatedNormal(mean = 0.0, stddev = 0.05, seed = None model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init))
- VarianceScaling ,根据图层的输入形状和输出形状以及指定的比例生成值。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import initializers my_init = initializers.VarianceScaling( scale = 1.0, mode = 'fan_in', distribution = 'normal', seed = None) model.add(Dense(512, activation = 'relu', input_shape = (784,), skernel_initializer = my_init))
scale 表示缩放因子, mode 表示fan_in、fan_out和fan_avg值中的任何一个, distribution 代表正态或均匀
它使用以下公式找到正态分布的stddev值,然后使用正态分布找到权重,stddev = sqrt(scale / n),其中n代表, mode = fan_in 的输入单元数, mode = fan_out 的输出单元数 ,mode = fan_avg 的平均输入和输出单元数。
类似地,它使用以下公式找到均匀分布的极限,然后使用均匀分布找到权重,limit = sqrt(3 * scale / n)
- 。。。
约束
在机器学习中,将在优化阶段对参数(权重)设置约束。Constraints 模块提供了不同的功能来设置层上的约束。一些约束函数如下。
- non_neg, 将权重限制为非负。
from keras.constraints import non_neg
其中,kernel_constraint表示要在层中使用的约束。
- UnitNorm, 将权重约束为单位范数。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import constraints my_constrain = constraints.UnitNorm(axis = 0) model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_constraint = my_constrain))
- MaxNorm ,将权重限制为小于或等于给定值的范数。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import constraints my_constrain = constraints.MaxNorm(max_value = 2, axis = 0) model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_constraint = my_constrain))
max_value表示上限 轴表示要应用约束的维度。例如,在 Shape (2,3,4) 轴中,0 表示第一维,1 表示第二维,2 表示第三维
- MinMaxNorm ,将权重约束为指定的最小值和最大值之间的范数。
from keras.models import Sequential from keras.layers import Activation, Dense from keras import constraints my_constrain = constraints.MinMaxNorm(min_value = 0.0, max_value = 1.0, rate = 1.0, axis = 0) model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_constraint = my_constrain))
其中,rate表示应用权重约束的速率。
正则化器
在机器学习中,正则化器用于优化阶段。它在优化过程中对层参数应用一些惩罚。Keras 正则化模块提供以下函数来设置层的惩罚。正则化仅适用于每层基础。
- L1 正则化器, 它提供基于 L1 的正则化
from keras.models import Sequential from keras.layers import Activation, Dense from keras import regularizers my_regularizer = regularizers.l1(0.) model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_regularizer = my_regularizer))
- L2 正则化器, 它提供基于 L2 的正则化
from keras.models import Sequential from keras.layers import Activation, Dense from keras import regularizers my_regularizer = regularizers.l2(0.) model = Sequential() model.add(Dense(512, activation = 'relu', input_shape = (784,), kernel_regularizer = my_regularizer))
激活
from keras.models import Sequential from keras.layers import Activation, Dense model = Sequential() model.add(Dense(512, activation = 'linear', input_shape = (784,)))
其中,激活是指层的激活函数。可以简单地通过函数名称指定,层将使用相应的激活器。
from keras.models import Sequential from keras.layers import Activation, Dense model = Sequential() model.add(Dense(512, activation = 'softmax', input_shape = (784,)))
from keras.models import Sequential from keras.layers import Activation, Dense model = Sequential() model.add(Dense(512, activation = 'sigmoid', input_shape = (784,)))
Keras 自定义层
Keras 允许创建我们自己的自定义层。一旦创建了一个新层,它就可以在任何模型中使用而不受任何限制。让我们在本章中学习如何创建新层。 Keras 提供了一个基础层类Layer, 可以对其进行子类化以创建我们自己的自定义层。让我们创建一个简单的层,它会根据正态分布找到权重,然后在训练期间进行基本计算,找到输入与权重的乘积之和。
需要实现三个方法:
- build(input_shape):定义你自己权重的地方,需要设置self.built=True.你可以通过调用super([Layer],self).build()来实现
- call(x):定义层逻辑的地方。除非你需要支持mask,否则你只需要关系传递给call的第一个参数
- compute_output_shape(input_shape):如果你的层更改了输入张量的形状,你应该在这里定义形状变化的逻辑,这让Keras能够自动推断各层的形状。
from keras import backend as K
from keras.layers import Layer
class MyLayer(Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(MyLayer, self).__init__(**kwargs)
def build(self, input_shape):
# Create a trainable weight variable for this layer.
self.kernel = self.add_weight(name='kernel',
shape=(input_shape[1], self.output_dim),
initializer='uniform',
trainable=True)
super(MyLayer, self).build(input_shape) # Be sure to call this at the end
def call(self, x):
return K.dot(x, self.kernel)
def compute_output_shape(self, input_shape):
return (input_shape[0], self.output_dim)
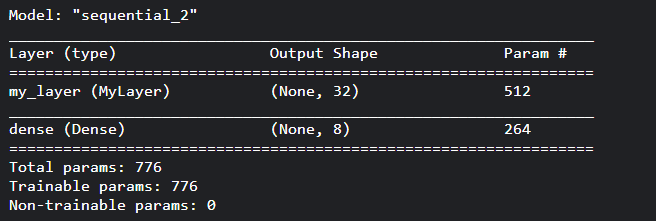
让我们使用我们的自定义层创建一个简单的模型,
from keras.models import Sequential from keras.layers import Dense model = Sequential() model.add(MyLayer(32, input_shape = (16,))) model.add(Dense(8, activation = 'softmax')) model.summary()
Keras 模型
如前所述,Keras 模型代表了实际的神经网络模型。Keras 提供了两种模式来创建模型,
- 简单易用的 Sequential API,
- 以及更灵活和高级的 Functional API。
现在让我们学习如何在本章中使用 Sequential 和 Functional API 创建模型。
线性(Sequential)
Sequential API的核心思想是简单地按顺序排列 Keras 层,因此称为Sequential API。大多数ANN具有按顺序排列的层,数据以给定的顺序从一层流向另一层,直到数据最终到达输出层。
- 创建Sequential模型,可以通过简单地调用Sequential() API来创建 ANN 模型,如下所示:
from keras.models import Sequential model = Sequential()
- 添加图层,要添加一个层,只需使用 Keras 层 API 创建一个层,然后通过 add() 函数传递该层,如下所示:
from keras.models import Sequential model = Sequential() input_layer = Dense(32, input_shape=(8,)) model.add(input_layer) hidden_layer = Dense(64, activation='relu'); model.add(hidden_layer) output_layer = Dense(8) model.add(output_layer)
- 访问模型 ,Keras 提供了一些方法来获取模型信息,如层、输入数据和输出数据。它们如下:
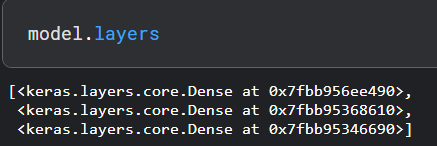
model.layers, 将模型的所有层作为列表返回。
model.inputs, 将模型的所有输入张量作为列表返回。

model.outputs ,将模型的所有输出张量作为列表返回。

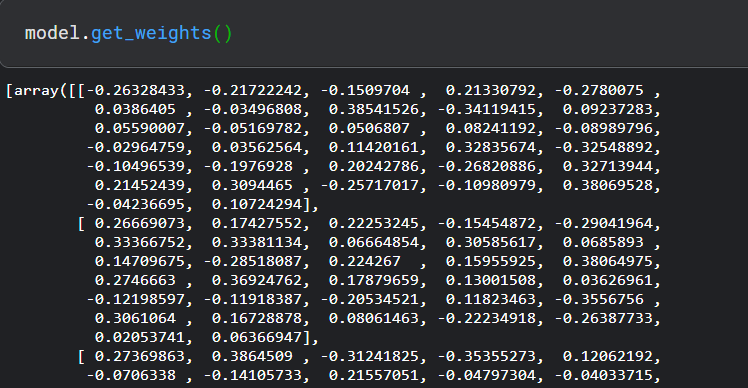
model.get_weights(), 将所有权重作为 NumPy 数组返回。
model.set_weights(weight_numpy_array) ,设置模型的权重。
- 序列化模型, Keras 提供了将模型序列化为对象以及 json 并稍后再次加载的方法。它们如下:
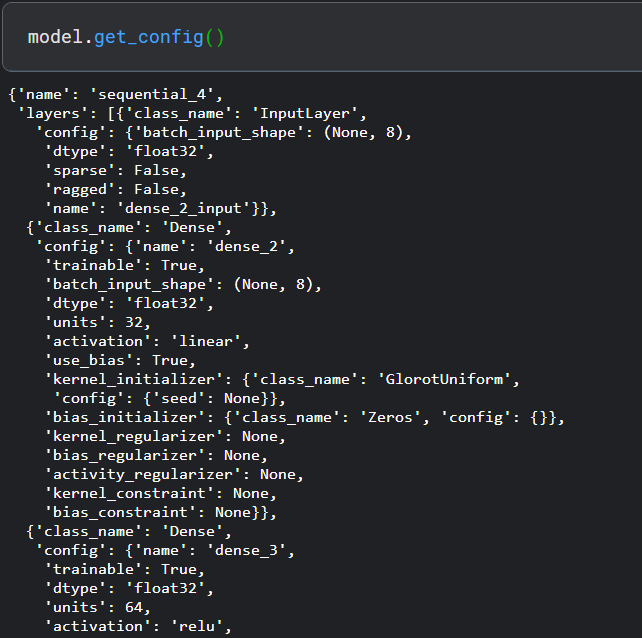
get_config():
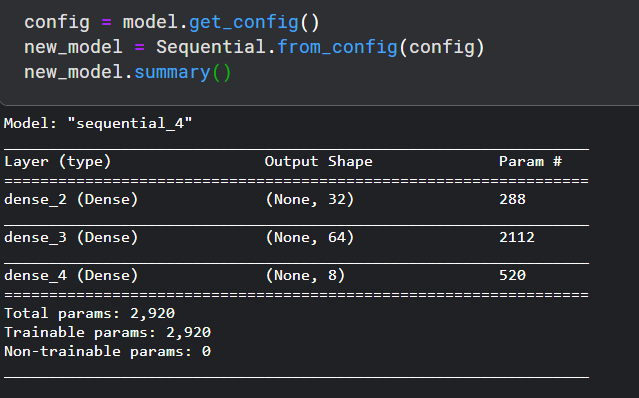
from_config():
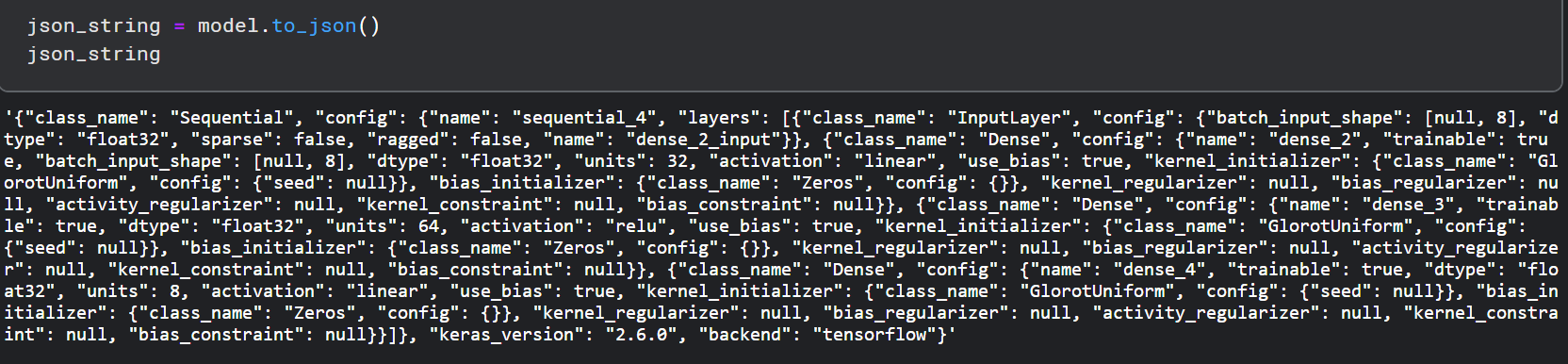
to_json() 将模型作为 json 对象返回。
model_from_json() ,接受模型的 json 表示并创建一个新模型。
from keras.models import model_from_json new_model = model_from_json(json_string)
- 总结模型, 理解模型是正确使用模型进行训练和预测的非常重要的阶段。Keras 提供了一种简单的方法,摘要来获取有关模型及其层的完整信息。
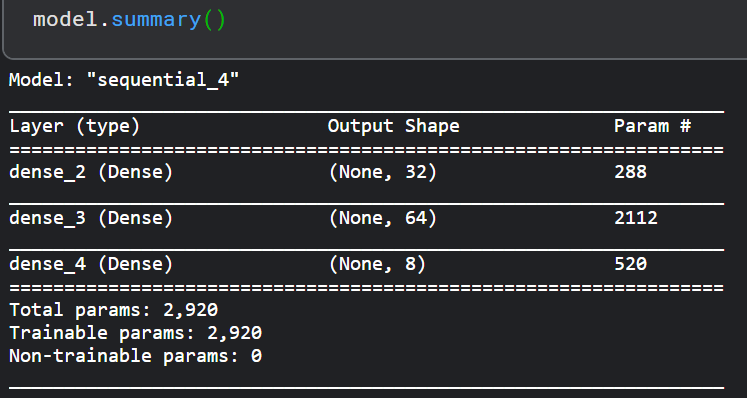
训练和预测模型:
模型为训练、评估和预测过程提供功能。它们如下:
- compile ,配置模型的学习过程
- fit ,使用训练数据训练模型
- evaluate, 使用测试数据评估模型
- predict ,预测新输入的结果。
功能API:
Keras的函数式模型为Model,即广义的拥有输入和输出的模型,tf.keras.Sequential 模型是层的简单堆叠,无法表示任意模型。使用 Keras 函数式 API 可以构建复杂的模型拓扑。例如:
- 多输入模型,
- 多输出模型,
- 具有共享层的模型(同一层被调用多次),
- 具有非序列数据流的模型(例如,残差连接)。
下面我们进行一一介绍。
全连接神经网络,
对于全连接神经网络Sequential 模型可能更合适,这里只是用来做示例(可以用来做对比),因为简单的网络更容易理解。
import tensorflow as tf from keras.layers import Input, Dense from keras.models import Model # 返回一个张量 inputs = Input(shape=(784,)) # 层的实例是可调用的,它以张量为参数,并且返回一个张量 x = Dense(64, activation='relu')(inputs) # 第一层 x = Dense(43, activation='relu')(x) # 第二层 outputs = Dense(10, activation='softmax')(x) # 输出层 # 这部分创建了一个包含输入层和三个全连接层的模型 model = Model(inputs=inputs, outputs=outputs) model.summary() keras.utils.plot_model(model,'alex_model.png',show_shapes=True, show_dtype=True)

- 网络层的实例是可调用的,它以张量为参数,并且返回一个张量,
- 输入和输出均为张量,它们都可以用来定义一个模型(Model),
- 模型同 Keras 的 Sequential 模型一样,都可以被训练,
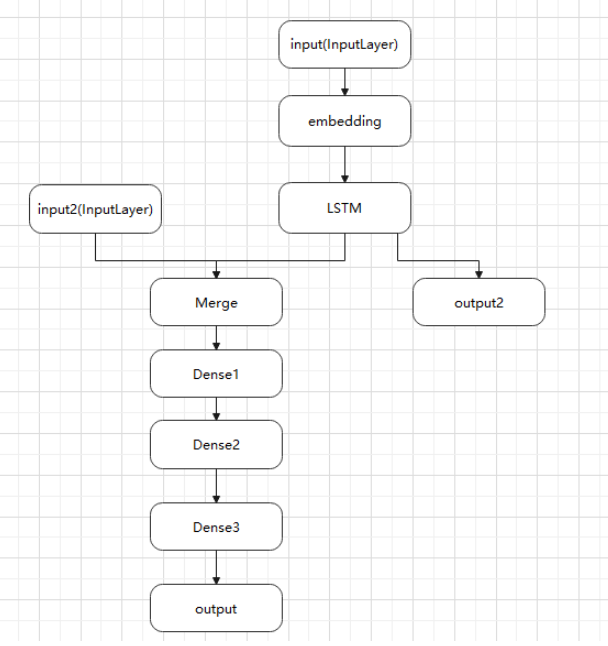
多输入多输出模型,
例如:试图预测一条新闻标题的转发和点赞数。模型的主要输入是新闻标题本身(一系列词语),还添加了其他辅助输入,例如新闻标题的发布的时间等。 该模型也将通过两个损失函数进行监督学习。较早地在模型中使用主损失函数,是深度学习模型的一个良好正则方法。 模型结构如下图所示:
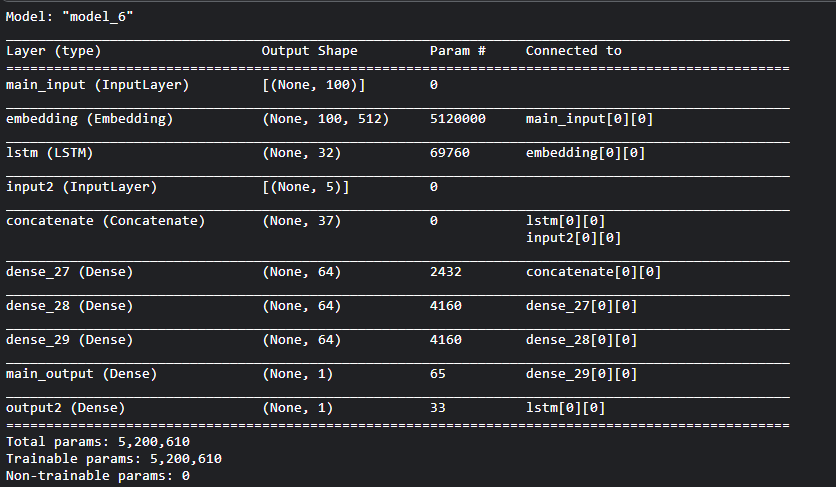
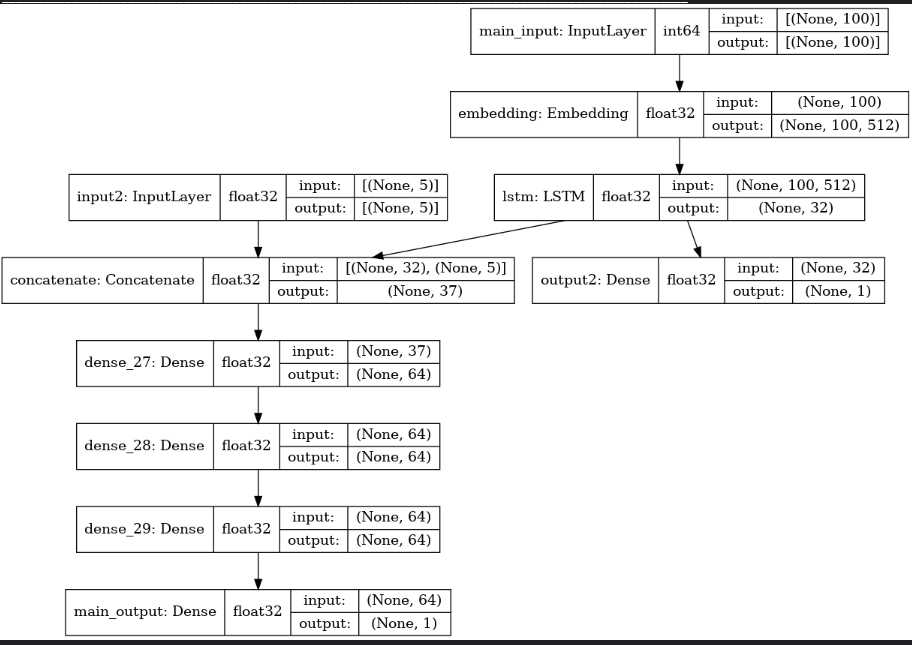
from keras.layers import Input, Embedding, LSTM, Dense
from keras.models import Model
# 标题输入:接收一个含有 100 个整数的序列,每个整数在 1 到 10000 之间。
# 通过传递一个 "name" 参数来命名任何层
main_input = Input(shape=(100,), dtype='int64', name='main_input')
# Embedding 层将输入序列编码为一个稠密向量的序列
# 每个向量维度为 512
x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)
# LSTM 层把向量序列转换成单个向量
# 它包含整个序列的上下文信息
lstm_out = LSTM(32)(x)
# 插入辅助损失,使得即使在模型主损失很高的情况下,LSTM 层和 Embedding 层都能被平稳地训练。
output2 = Dense(1, activation='sigmoid', name='output2')(lstm_out) # output2
input2 = Input(shape=(5,), name='input2') # input2
# 将辅助输入数据与 LSTM 层的输出连接起来
x = keras.layers.concatenate([lstm_out, input2])
# 堆叠多个全连接网络层
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
# 添加主要的逻辑回归层
main_output = Dense(1, activation='sigmoid', name='main_output')(x)
# 定义整个网络的2个输入和输出的模型
model = Model(inputs=[main_input, input2], outputs=[main_output, output2])
# 编译模型,并给辅助损失分配 0.2 的权重。如果要为不同的输出指定不同的 loss_weights 或 loss,可以使用列表或字典。 在这里,给loss参数传递单个损失函数,这个损失将用于所有的输出。
model.compile(optimizer='rmsprop', loss='binary_crossentropy',
loss_weights=[1., 0.2])
model.fit([headline_data, additional_data], [labels, labels],
epochs=50, batch_size=32)
# 或者可以通过以下方式编译和训练
model.compile(optimizer='rmsprop',
loss={'main_output': 'binary_crossentropy', 'output2': 'binary_crossentropy'},
loss_weights={'main_output': 1., 'output2': 0.2})
# 然后使用以下方式训练:
model.fit({'main_input': headline_data, 'input2': additional_data},
{'main_output': labels, 'output2': labels},
epochs=50, batch_size=32)
共享网络层,
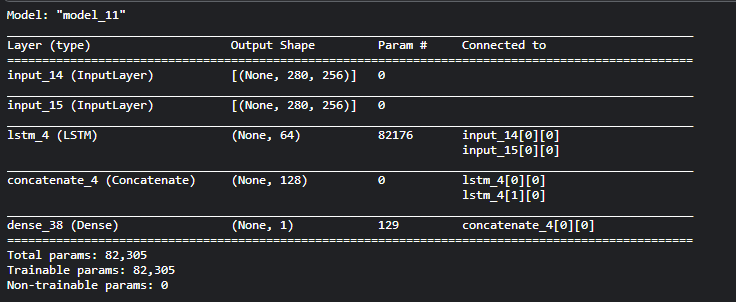
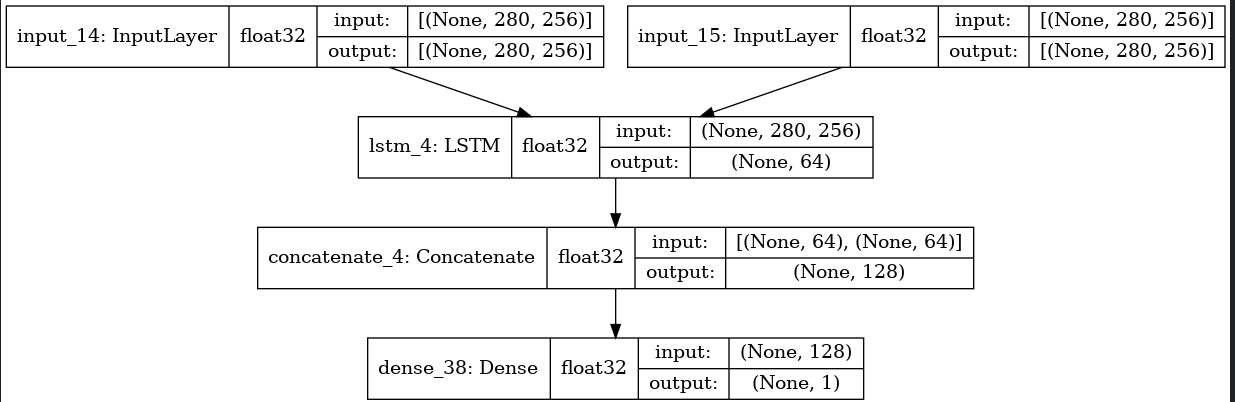
函数式 API 的另一个用途是使用共享网络层的模型,来考虑推特推文数据集。我们想要建立一个模型来分辨两条推文是否来自同一个人(例如,通过推文的相似性来对用户进行比较)。 实现这个目标的一种方法是建立一个模型,将两条推文编码成两个向量,连接向量,然后添加逻辑回归层,这将输出两条推文来自同一作者的概率。模型将接收一对对正负表示的推特数据。 由于这个问题是对称的,编码第一条推文的机制应该被完全重用来编码第二条推文(权重及其他全部)。这里我们使用一个共享的 LSTM 层来编码推文。 首先我们将一条推特转换为一个尺寸为 (280, 256) 的矩阵,即每条推特 280 字符,每个字符为 256 维的 one-hot 编码向量 (取 256 个常用字符)。
import keras
from keras.layers import Input, LSTM, Dense
from keras.models import Model
tweet_a = Input(shape=(280, 256))
tweet_b = Input(shape=(280, 256))
# 要在不同的输入上共享同一个层,只需实例化该层一次
# 这一层可以输入一个矩阵,并返回一个 64 维的向量
shared_lstm = LSTM(64)
# 当我们重用相同的图层实例多次,图层的权重也会被重用 (它其实就是同一层)
encoded_a = shared_lstm(tweet_a)
encoded_b = shared_lstm(tweet_b)
# 然后再连接两个向量:
merged_vector = keras.layers.concatenate([encoded_a, encoded_b], axis=-1)
# 再在上面添加一个逻辑回归层
predictions = Dense(1, activation='sigmoid')(merged_vector)
# 定义一个连接推特输入和预测的可训练的模型
model = Model(inputs=[tweet_a, tweet_b], outputs=predictions)
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit([data_a, data_b], labels, epochs=100)
残差网络,
from tensorflow import keras from keras.layers import Conv2D, Input # 输入张量为 3 通道 256x256 图像 x = Input(shape=(256, 256, 3)) # 3 输出通道(与输入通道相同)的 3x3 卷积核 y = Conv2D(3, (3, 3), padding='same')(x) # 返回 x + y z = keras.layers.add([x, y]) model = Model(inputs=x, outputs=z) model.summary() keras.utils.plot_model(model,'alex_model.png',show_shapes=True, show_dtype=True)

Keras 模型编译
编译是创建模型的最后一步。编译完成后,我们就可以进入训练阶段。
Loss 损失:
Keras 在模型编译过程中需要损失函数。
Keras 在损失模块中提供了不少的损失函数,下面为大家罗列出来:
- mean_squared_error
- mean_absolute_error
- mean_absolute_percentage_error
- squared_hinge
- categorical_hinge
- categorical_hine
- huber_loss
- categorical_crossentropy
- sparse_categorical_crossentropy
- binary_crossentropy
- kullback_leibler_divergence
- poisson cosine_proximity
- is_categorical_crossentropy
以上所有损失函数都接受两个参数:
- y_true 作为 tensor 的真实标签
- y_pred 与 y_true 形状相同的预测
在使用下面指定的损失函数之前,首先要导入损失模块:
from keras import losses
Optimizer 优化器:
Keras 提供了很多优化器,具体如下:
keras.optimizers.SGD(learning_rate = 0.01, momentum = 0.0, nesterov = False)
keras.optimizers.RMSprop(learning_rate = 0.001, rho = 0.9)
keras.optimizers.Adagrad(learning_rate = 0.01)
keras.optimizers.Adadelta(learning_rate = 1.0, rho = 0.95)
keras.optimizers.Adam( learning_rate = 0.001, beta_1 = 0.9, beta_2 = 0.999, amsgrad = False )
导入优化器模型,
from keras import optimizers
Metrics 指标:
在机器学习中,指标用于评估模型的功能。它类似于损失函数,但不用于训练过程。Keras也提供了许多的指标,详细如下:
accuracybinary_accuracycategorical_accuracysparse_categorical_accuracytop_k_categorical_accuracysparse_top_k_categorical_accuracycosine_proximityclone_metric
和损失函数一样,指标一样接受一下的两种参数:
y_true作为 tensor 的真实标签y_pred与y_true形状相同的预测
使用指标需要导入指定的指标模块:
from keras import metrics
编译模型:
Keras 模型提供了一个方法compile()来编译模型。compile()方法的参数和默认值如下:
compile( optimizer, loss = None, metrics = None, loss_weights = None, sample_weight_mode = None, weighted_metrics = None, target_tensors = None )
重要的参数如下:
- 损失函数
- 优化器
- 指标
from keras import losses from keras import optimizers from keras import metrics model.compile(loss = 'mean_squared_error', optimizer = 'sgd', metrics = [metrics.categorical_accuracy])
模型训练:
model.fit(X, y, epochs = , batch_size = )
from tensorflow import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from tensorflow.keras.optimizers import Adam,Nadam, SGD
import numpy as np
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
model = Sequential()
model.add(Dense(512, activation='relu', input_shape = (784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation = 'relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy',
optimizer = SGD(),
metrics = ['accuracy'])
history = model.fit(x_train, y_train,
batch_size = 128, epochs = 2, verbose = 1, validation_data = (x_test, y_test))

Keras 模型评估和模型预测
模型评估:
Keras 模型提供了一个函数,evaluate 对模型进行评估。它有三个主要参数:
- 测试数据
- 测试数据标签
verbose:true或false
score = model.evaluate(x_test, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])

模型预测:
Keras 提供了一种方法predict来得到训练模型的预测。预测方法的签名如下:
predict( x, batch_size = None, verbose = 0, steps = None, callbacks = None, max_queue_size = 10, workers = 1, use_multiprocessing = False )
在这里,除了第一个参数外,所有参数都是可选的,它指的是未知的输入数据。应保持形状以获得正确的预测。
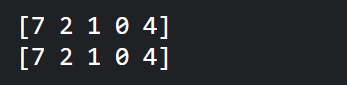
pred = model.predict(x_test) pred = np.argmax(pred, axis = 1)[:5] label = np.argmax(y_test,axis = 1)[:5] print(pred) print(label)
Keras 卷积神经网络
from tensorflow import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.optimizers import SGD
from keras import backend as K
import numpy as np
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print("x_train shape:",x_train.shape)
img_rows, img_cols = 28, 28
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
print("the actual input_shape:",input_shape)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
model = Sequential()
model.add(Conv2D(32, kernel_size = (3, 3),
activation = 'relu', input_shape = input_shape))
model.add(Conv2D(64, (3, 3), activation = 'relu'))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation = 'softmax'))
model.compile(loss = keras.losses.categorical_crossentropy,
optimizer = SGD(), metrics = ['accuracy'])
model.fit(
x_train, y_train,
batch_size = 128,
epochs = 2,
verbose = 1,
validation_data = (x_test, y_test)
)

该模型的核心特征如下:
- 输入层由 (28, 28, 1) 个值组成。
- 第一层,
Conv2D由32个内核大小为(3,3)过滤器和 的“relu”激活函数组成。 - 第二层,
Conv2D由64个内核大小为(3,3)过滤器和“relu”激活函数组成。 - 第三层,
MaxPooling2D的池大小为(2, 2)。 - 第五层,
Flatten用于将其所有输入展平为单一维度。 - 第六层,
Dense由128个神经元和“relu”激活函数组成。 - 第七层,
Dropout的值为0.5。 - 第八层也是最后一层由
10个神经元和“softmax”激活函数组成。 - 使用
categorical_crossentropy作为损失函数。 - 使用
SGD()作为优化器。 - 使用
accuracy作为指标。 - 使用
128作为批量大小。 - 使用
2epochs。
Keras MPL 进行回归预测
import keras from keras.datasets import boston_housing from keras.models import Sequential from keras.layers import Dense from tensorflow.keras.optimizers import RMSprop from keras.callbacks import EarlyStopping from sklearn import preprocessing from sklearn.preprocessing import scale (x_train, y_train), (x_test, y_test) = boston_housing.load_data() x_train_scaled = preprocessing.scale(x_train) scaler = preprocessing.StandardScaler().fit(x_train) x_test_scaled = scaler.transform(x_test) model = Sequential() model.add(Dense(64, kernel_initializer = 'normal', activation = 'relu', input_shape = (13,))) model.add(Dense(64, activation = 'relu')) model.add(Dense(1)) model.compile( loss = 'mse', optimizer = RMSprop(), metrics = ['mean_absolute_error'] ) history = model.fit( x_train_scaled, y_train, batch_size=128, epochs = 2, verbose = 1, validation_split = 0.2, callbacks = [EarlyStopping(monitor = 'val_loss', patience = 20)] )

Keras 使用 LSTM进行时间序列预测
让我们创建一个 LSTM 模型来分析 IMDB 电影评论并预测其正面/负面情绪。
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Embedding
from keras.layers import LSTM
from keras.datasets import imdb
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = 2000)
print("x_train :",x_train[0])
print("y_train :",y_train[0])
x_train = sequence.pad_sequences(x_train, maxlen=80)
x_test = sequence.pad_sequences(x_test, maxlen=80)
model = Sequential()
model.add(Embedding(2000, 128))
model.add(LSTM(64, dropout = 0.2, recurrent_dropout = 0.2))
model.add(Dense(1, activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy',
optimizer = 'adam', metrics = ['accuracy'])
model.fit(
x_train, y_train,
batch_size = 128,
epochs = 2,
validation_data = (x_test, y_test)
)
imdb 是 Keras 提供的数据集。它代表了一系列电影及其评论,num_words 表示评论中的最大单词数。

Keras 应用模块
Keras应用模块用于为深度神经网络提供预训练模型,预训练模型用于预测、特征提取和微调。
训练好的模型由模型架构和模型权重两部分组成。模型权重是大文件,下面列出了一些流行的预训练模型:
ResNetVGG16MobileNetInceptionResNetV2InceptionResNetV3
Keras 预训练模型可以轻松加载,如下所示:
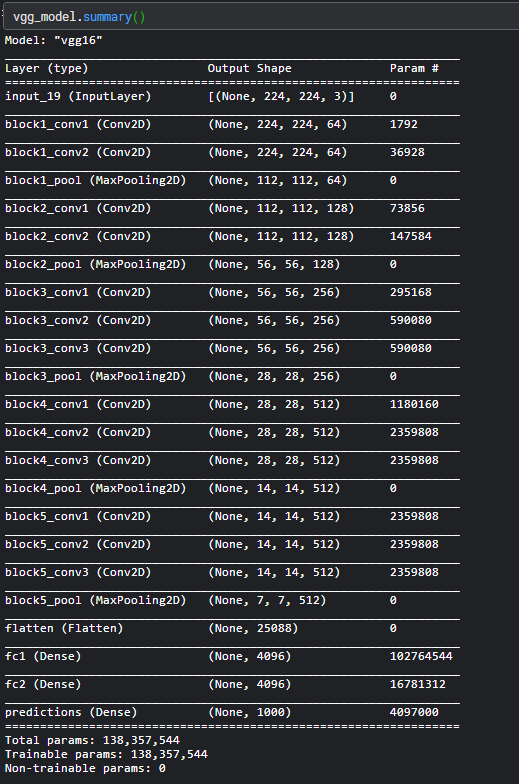
import keras import numpy as np from tensorflow.keras.applications import vgg16, inception_v3, resnet50, mobilenet #Load the VGG model vgg_model = vgg16.VGG16(weights = 'imagenet') #Load the Inception_V3 model inception_model = inception_v3.InceptionV3(weights = 'imagenet')

加载模型后,我们可以立即将其用于预测目的。ResNet是一个预训练模型,它使用 ImageNet 进行训练。在 ImageNet 上预训练的 ResNet 模型权重,它具有以下语法:
keras.applications.resnet.ResNet50 ( include_top = True, weights = 'imagenet', input_tensor = None, input_shape = None, pooling = None, classes = 1000 )
include_top指的是网络顶部的全连接层。weights指的是ImageNet上的预训练。input_tensor指用作模型的图像输入的可选的Keras张量。input_shape指可选的形状元组。此模型的默认输入大小为224x224。clasees指用于对图像进行分类的可选数量的类。
下面我们来一步步来介绍。
- 先导入必要的模块,
import PIL from keras.preprocessing.image import load_img, image from keras.preprocessing.image import img_to_array from keras.applications.imagenet_utils import decode_predictions import matplotlib.pyplot as plt import numpy as np from tensorflow.keras.applications import vgg16, inception_v3, resnet50, mobilenet import matplotlib.pyplot as plt %matplotlib inline
- 选择一个输入图像,网上找了一张图片,如下所示:
filename = '../input/tupian/8b0cc25943c94be3b44bf250c288f10d.png'
original = load_img(filename, target_size = (224, 224))
print('PIL image size',original.size)
plt.imshow(original)
- 将图像转换为 NumPy 数组,以便将其传递到模型中以进行预测,
# 将图 转 numpy 数组
numpy_image = img_to_array(original)
plt.imshow(np.uint8(numpy_image))
print('numpy array size',numpy_image.shape)
# 将图转 图的批量格式
image_batch = np.expand_dims(numpy_image, axis = 0)
print('image batch size', image_batch.shape)
- 将输入输入模型以获得预测,
# 为 resnet50 模型 格式 processed_image = resnet50.preprocess_input(image_batch.copy()) # 创建 resnet 模型 resnet_model = resnet50.ResNet50(weights = 'imagenet') # 获得 预测可能分类 predictions = resnet_model.predict(processed_image)

- 输出,
# 转化为可能分类标签 label = decode_predictions(predictions,top=1) print(label)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号