

transformers中,关于PreTrainedTokenizer的使用
在我们使用transformers进行预训练模型学习及微调的时候,我们需要先对数据进行预处理,然后经过处理过的数据才能“喂”进bert模型里面,这这个过程中我们使用的主要的工具就是tokenizer。你可以建立一个tokenizer通过与相关预训练模型相关的tokenizer类,例如,对于Roberta,我们可以使用与之相关的RobertaTokenizer。或者直接通过AutoTokenizer类(这个类能自动的识别所建立的tokenizer是与哪个bert模型对于的)。通过tokenizer,它会将一个给定的文本分词成一个token序列,然后它会映射这些tokens成tokenizer的词汇表中token所对应的下标,在这个过程中,tokenizer还会增加一些预训练模型输入格式所要求的额外的符号,如,'[CLS]','[SEP]'等。经过这个预处理后,就可以直接地“喂”进我们的预训练模型里面。
下面,我们具体看一下怎么使用它。
首先,先获得一个PreTrainedTokenizer类。
from transformers import BertTokenizer
TOKENIZER_PATH = "../input/huggingface-bert/bert-base-chinese"
tokenizer = BertTokenizer.from_pretrained(TOKENIZER_PATH)
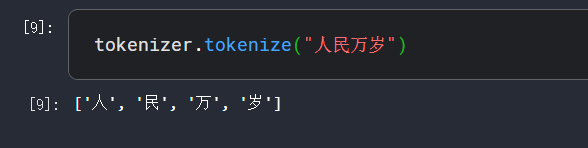
tokenizer有一个方法tokenize,它会将我们的输入句子进行分词操作,
而convert_tokens_to_ids会将一个句子分词得到的tokens映射成它们在词汇表中对应的下标,

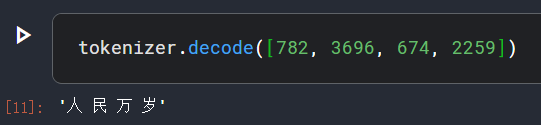
我们要将下标序列解码到tokens,decode方法可以办到,
tokenizer里面的方法encode,batch_encode,encode_plus,batch_encode_plus将上面的两个步骤都包含了,使用起来更加方便,不过这些方法在transformers的将来的版本中,会被遗弃,它们的全部的功能都集成到了__call__方法里面去了,所以我们下面中间的讲解__call__方法,__call__方法里面的参数和这些遗弃的方法里的函数参数基本一致,不再赘述。
查看官方文档,我们可以得到__call__方法的api如下:

我们经常需要设置的参数如下:
- text (str, List[str], List[List[str]]) – The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set is_split_into_words=True (to lift the ambiguity with a batch of sequences).
- text_pair (str, List[str], List[List[str]]) – The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set is_split_into_words=True (to lift the ambiguity with a batch of sequences).
- add_special_tokens (bool, optional, defaults to True) – Whether or not to encode the sequences with the special tokens relative to their model.
- padding (bool, str or PaddingStrategy, optional, defaults to False) –
Activates and controls padding. Accepts the following values:- True or 'longest': Pad to the longest sequence in the batch (or no padding if only a single sequence if provided).
- 'max_length': Pad to a maximum length specified with the argument max_length or to the maximum acceptable input length for the model if that argument is not provided.
- False or 'do_not_pad' (default): No padding (i.e., can output a batch with sequences of different lengths).
- truncation (bool, str or TruncationStrategy, optional, defaults to False) –
Activates and controls truncation. Accepts the following values:- True or 'longest_first': Truncate to a maximum length specified with the argument max_length or to the maximum acceptable input length for the model if that argument is not provided. This will truncate token by token, removing a token from the longest sequence in the pair if a pair of sequences (or a batch of pairs) is provided.
- 'only_first': Truncate to a maximum length specified with the argument max_length or to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.
- 'only_second': Truncate to a maximum length specified with the argument max_length or to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided.
- False or 'do_not_truncate' (default): No truncation (i.e., can output batch with sequence lengths greater than the model maximum admissible input size).
- max_length (int, optional) –
Controls the maximum length to use by one of the truncation/padding parameters.
If left unset or set to None, this will use the predefined model maximum length if a maximum length is required by one of the truncation/padding parameters. If the model has no specific maximum input length (like XLNet) truncation/padding to a maximum length will be deactivated. - is_split_into_words (bool, optional, defaults to False) – Whether or not the input is already pre-tokenized (e.g., split into words). If set to True, the tokenizer assumes the input is already split into words (for instance, by splitting it on whitespace) which it will tokenize. This is useful for NER or token classification.
- return_tensors (str or TensorType, optional) –
If set, will return tensors instead of list of python integers. Acceptable values are:- 'tf': Return TensorFlow tf.constant objects.
- 'pt': Return PyTorch torch.Tensor objects.
- 'np': Return Numpy np.ndarray objects.
- return_token_type_ids (bool, optional) –
Whether to return token type IDs. If left to the default, will return the token type IDs according to the specific tokenizer’s default, defined by the return_outputs attribute. - return_attention_mask (bool, optional) –
Whether to return the attention mask. If left to the default, will return the attention mask according to the specific tokenizer’s default, defined by the return_outputs attribute.
下面,我们主要通过例子,来学习__call__的使用及函数参数的理解。
对于__call__方法,我们先一览它的基本使用:

我们看到,在得到的index列表中,开头多了101,末尾多了102,这是增加的额外的token "[CLS]"和"[SEP]",我们可以验证这一点:
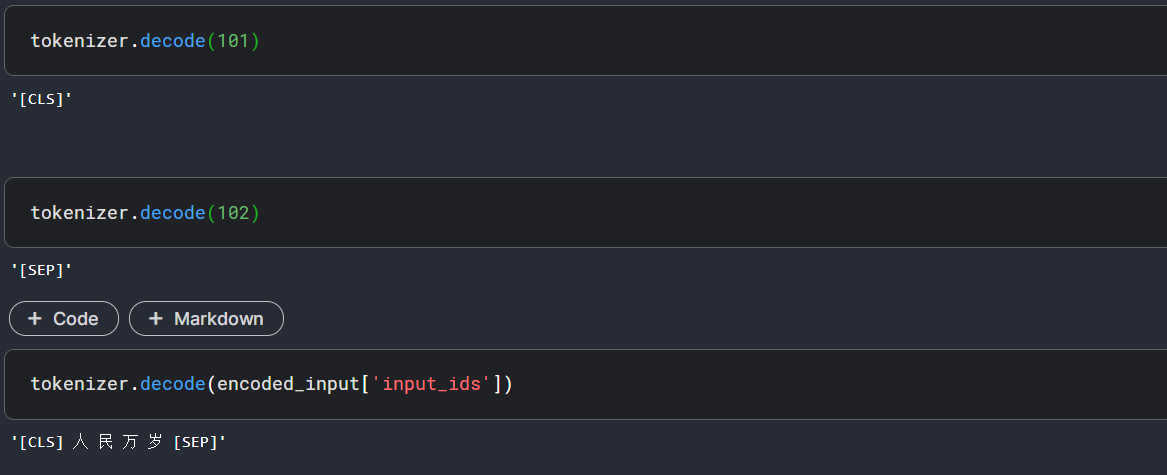
并不是所有的模型需要增加特殊的tokens,例如我们使用gpt2-meduim而不是bert-base-cased的时候。如果想禁止这个行为(当你自己已经手动添加上特殊的tokens的时候,强烈建议你这样做),可以设置参数add_special_tokens=False。
假如你有好几个句子需要处理,你可以以列表的形式传进去,

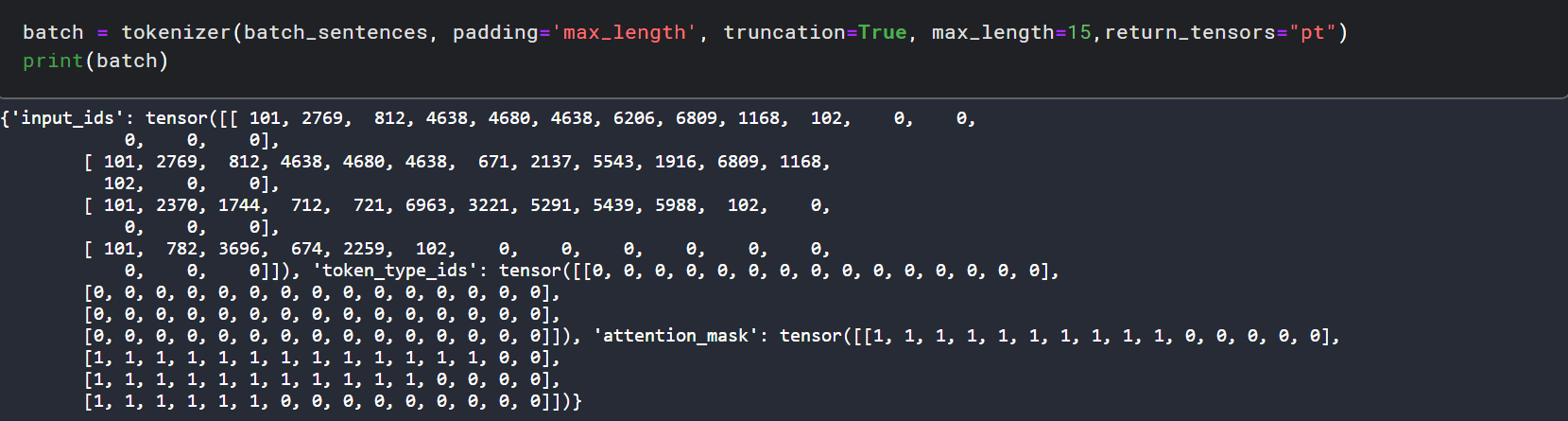
如果我们同时传进去了好几个句子,作为一批样本,最后处理的结果要喂进去model里面,那么我们可以设置填充参数padding,截断参数truncation,以及返回pytorch 张量参数return_tensors="pt",
有时候,你需要喂进去句子对到你的模型中去,例如,你想分类两个句子做为一对,是否是相似的,或者对于问答系统模型,一个句子做为context,一个句子做为question。此时,对于BERT模型来说,输入需要表示成这样的格式:
[CLS] Sequence A [SEP] Sequence B [SEP]
第一个句子做为text的实参,第二个句子做为text_pair的实参,

假如你有多个句子对需要处理,你需要把它们做为两个列表传进tokenizer:一个第一个句子的列表和一个第二个句子的列表,


同样的,针对句子对输入,你可以设置最大长度参数,填充参数,截断参数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号