

MQ 分布式事务 -- 微服务应用
1、背景
友情链接:https://www.cnblogs.com/Agui520/p/11187972.html
https://blog.csdn.net/fd2025/article/details/79863390
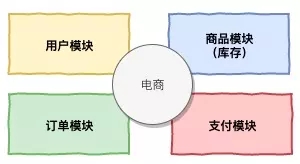
以支付、电商下单为例子。一个电商系统包含了好几大类模块,就比如有用户模块、商品模块、库存模块、订单模块、支付模块、物流模块,活动模块等,以下就先列举几个最基础常见的模块(用户模块、商品模块、库存模块、订单模块、支付模块)。
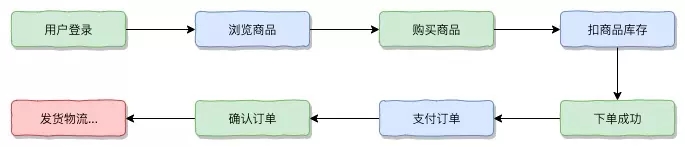
用户流程如下:
2、问题
如果系统规模较小,数据表都在一个数据库实例上,项目服务端也都在同一个项目,那上面的问题基本不是问题,直接用本地事务(一致性,原子性、隔离性、持久性)解决,比如支付转账(A->B)模块肯定会出现A账户减少,B账户增加,程序操作加个事务管理就解决。但是如果系统规模较大,比如支付宝账户表和余额宝账户表显然不会在同一个数据库实例上,他们往往分布在不同的物理节点上,又比如商品模块,订单模块不会在同一个数据库中或是在同一个项目中,这时本地事务就已经失去用武之地了。
3、场景
1.场景1
支付宝转1万元到余额宝,如果支付宝扣除1万后,如果系统挂掉了,余额宝并没有增加1万,数据出现不一致情况。
2.场景2
电商系统中,当有用户下单后,除了在订单表插入一条记录外,对应商品表的这个商品数量必须 减1,怎么保证??在 搜索广告系统中,当用户点击某广告后,除了在点击事件表中 增加一条
记录外 ,还得去商家账户表中找到这个商家扣除广告费吧,怎么保证??
不拆分服务最常见的解决方案:
本地事务:
Begin transaction
update A set amount = amount - 10000 where userId = 1
update B set amount = amount + 10000 where userId = 1
End transaction
commit;
4、MQ实现分布式事务
当 支付宝账户扣除1万后,我们只要生成一个凭证(消息)即可,这个凭证(消息)上写着“让余额宝账户增加一万”,只要这个凭证(消息)能可靠保证,我们最终是可以拿着这个凭证(消息)让余额宝账户 增加1万的,即我们能依靠这个凭证(消息)完成最终一致性。
4.1 如何可靠保存凭证
业务与消息耦合的方式
支付宝在完成扣款的同时,同时记录消息数据,这个消息数据与业务数据保存在同一数据库实例里(消息记录表名为message).
Begin transtration
update A set amount = amount -10000 where userId = 1;
insert into message(userId,amount,status) values (1,10000,1);
End transaction
commit;
上述事务能保证只要支付宝账户里被扣了钱,消息一定能保存下来。
当上述事务提交成功后,我们通过实时消息服务将此消息通知余额宝,余额宝处理成功后发送回复成功消息后,支付宝收到回复后删除该条消息数据。
业务与消息解耦
为了解耦,可以采取以下方式:
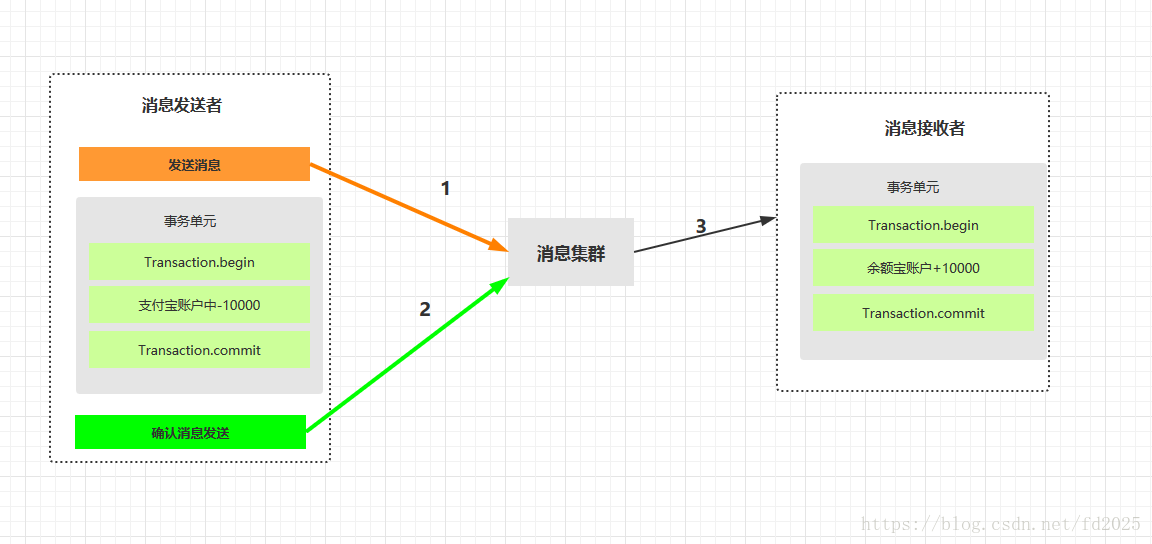
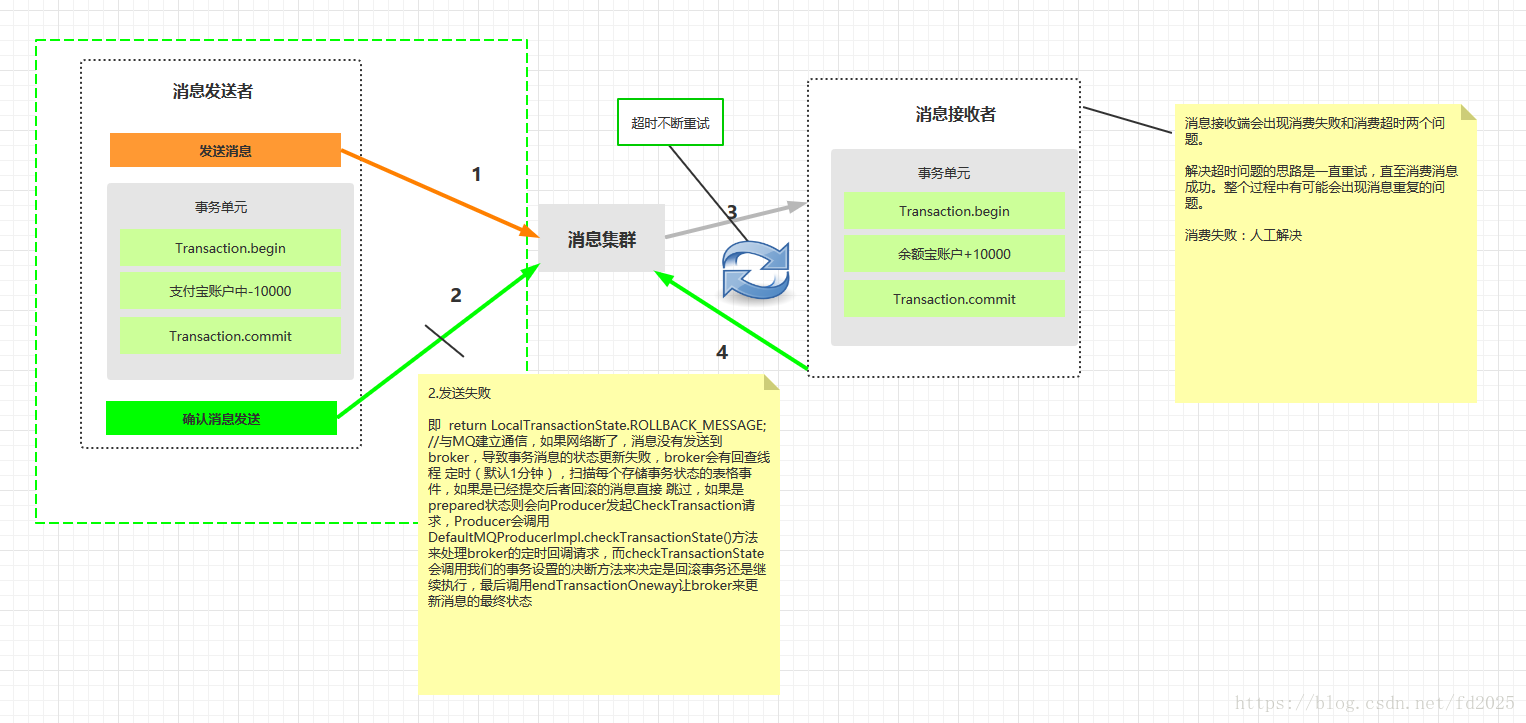
1、支付宝在扣款事务提交之前,向实时消息服务请求发送消息,实时消息服务只记录消息数据,而不真正发送(只是知道有这一条消息),只有消息发送成功后才会提交事务。
//支付宝 - 10000 (业务需求)
//先把(支付宝-10000)封装成一个消息(new Message()))
//然后把这个消息提交到MQ服务器上send(producer.send(new Message(),callback(里面处理本地事务)))
//在callback处理本地事务:在callback方法里:
update A set amount = amount - 10000 where userId = 1;
..............
//当本地事务操作完成了以后
1.要么成功:(给MQ一个标识:COMMIT)
2.要么失败:(给MQ一个标识:ROLLBACK)
2. 当支付宝扣款事务被提交成功后,向实时 消息服务确认发送,只有在得到确认发送指令后,实时消息服务才真正发送该消息。
3. 当支付宝扣款事务提交失败回滚后,向实时 消息服务取消发送。在得到取消发送指令后, 该消息将不会被发送。
4. 对于那些未确认的消息或者取消的消息,需要有一个消息状态确认系统定时去支付宝系统查询这个消息的 状态进行更新。为什么需要这一个步骤:假设在支付宝扣款事务被成功提交后,系统挂了,此时消息状态并未被更新为“确认发送”,从而导致消息不能被发送。
优点:消息数据独立存储 ,降低业务系统与消息系统之间的耦合。
缺点:一次消息发送需要两次请求;业务处理服务需要实现消息状态回查接口
综合上述的描述,RabbitMQ 做了这么三件事:
2,处理本地事物。
3,根据本地事物的执行结果,结合transactionId,找到该消息的位置,在mq中标志该消息的最终处理结果。
5、Rabbit MQ 介绍
相关链接:https://www.cnblogs.com/duanxz/p/3542320.html
RabbitMQ的结构图如下:
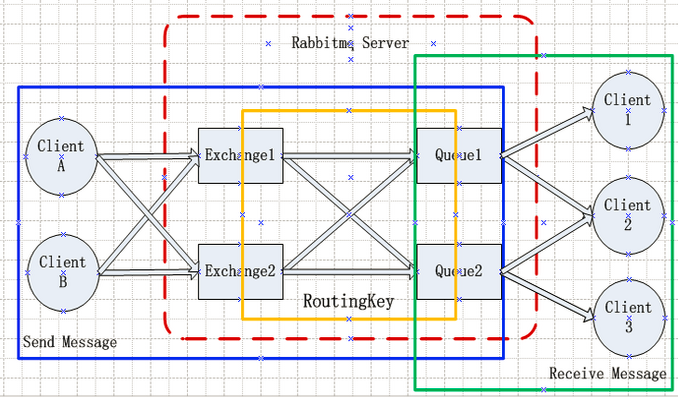
1、几个概念说明:
Broker:简单来说就是消息队列服务器实体。
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
(
Exchange类型
A. direct exchange:将与routing key 比配的消息,直接推入相对应的队列,创建队列时,默认就创建同名的routing key。
B. fanout exchange:是一种广播模式,忽略routingkey的规则。
C. topic exchange:应用主题,根据key进行模式匹配路由,例如:若为abc*则推入到所有abc*相对应的queue;若为abc.#则推入到abc.xx.one ,abc.yy.two对应的queue。
)
Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
producer:消息生产者,就是投递消息的程序。
consumer:消息消费者,就是接受消息的程序。
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。是基于Connection之上建立通信通道,因为每次Connection建立TCP协议通信开销及性能消耗较大,所以一次建立Connection后,使用多个Channel通道通信减少开销和提高性能。
2、消息队列的使用过程大概如下:
(1)客户端连接到消息队列服务器,打开一个channel。
(2)客户端声明一个exchange,并设置相关属性。
(3)客户端声明一个queue,并设置相关属性。
(4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
(5)客户端投递消息到exchange。
exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里。
exchange也有几个类型,完全根据key进行投递的叫做Direct交换机,例如,绑定时设置了routing key为”abc”,那么客户端提交的消息,只有设置了key为”abc”的才会投递到队列。对key进行模式匹配后进行投递的叫做Topic交换机,符 号”#”匹配一个或多个词,符号”*”匹配正好一个词。例如”abc.#”匹配”abc.def.ghi”,”abc.*”只匹配”abc.def”。还 有一种不需要key的,叫做Fanout交换机,它采取广播模式,一个消息进来时,投递到与该交换机绑定的所有队列。
6、代码实现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号