Python基础7——模块2 字节类型 异常处理
1.模块(类库)基础知识
-
1.1 模块分类
- 内置模块:Python内部提供的功能
- 如sys模块、os模块
- 面试题
- 列举常用的内置模块:json time os sys
- 第三方模块:开发者写好,但需要下载后安装使用
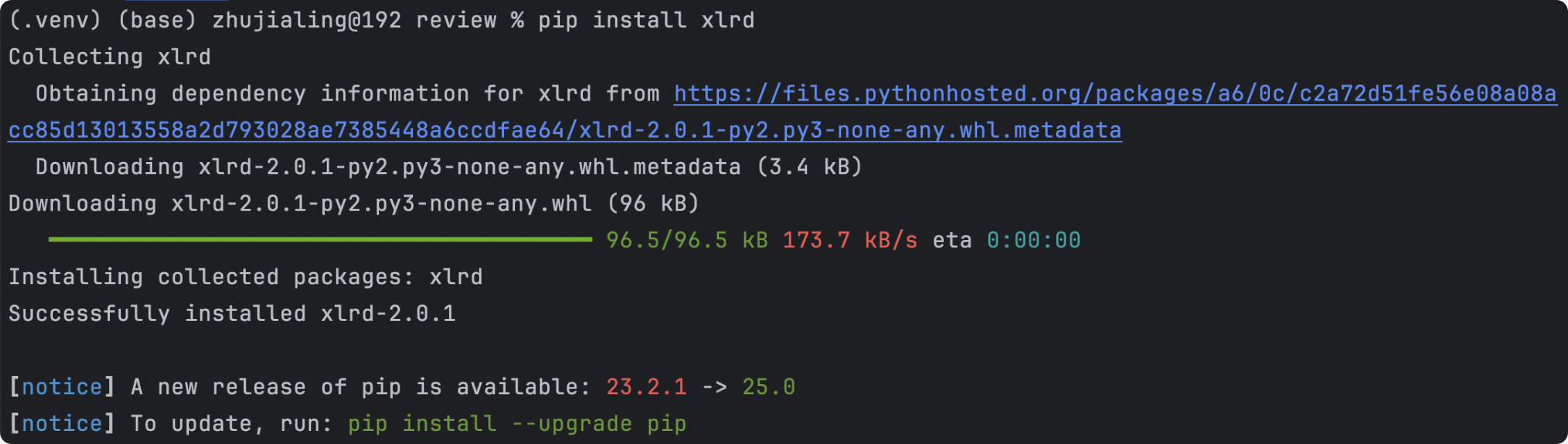
- 安装方法1:pip包管理工具【推荐】
- 安装指令:pip install package_name,如pip install xlrd
![]()
- Windows环境下提前把pip.exe路径添加到环境变量中
- 升级pip工具:python36 -m pip install --upgrade pip
- 安装完成后,如果导入不成功可重启Pycharm;如果还报错,大概是安装错了
- 安装指令:pip install package_name,如pip install xlrd
- 安装方法2:源码安装
- 下载源码压缩包,格式:*.zip *.tar.gz
- 解压后在终端进入源码包所在路径
- 执行:python setup.py build【编译】
- 执行:python setup.py install【安装】
- 安装路径:C:\Python36\Lib\site-package【Windows下第三方模块专用目录】
- 安装方法1:pip包管理工具【推荐】
- 自定义模块:写代码时由于代码量太多,将部分代码提取成模块,实际上就是个py文件
- 定义模块时可以把一个py文件或一个文件夹(包)当做一个模块,以方便以后其他py文件的调用
- 对于包的定义:
- Python2:文件中必须有__init__.py
- Python3:不需要__init__.py,但推荐以后写代码时都要加上__init__.py
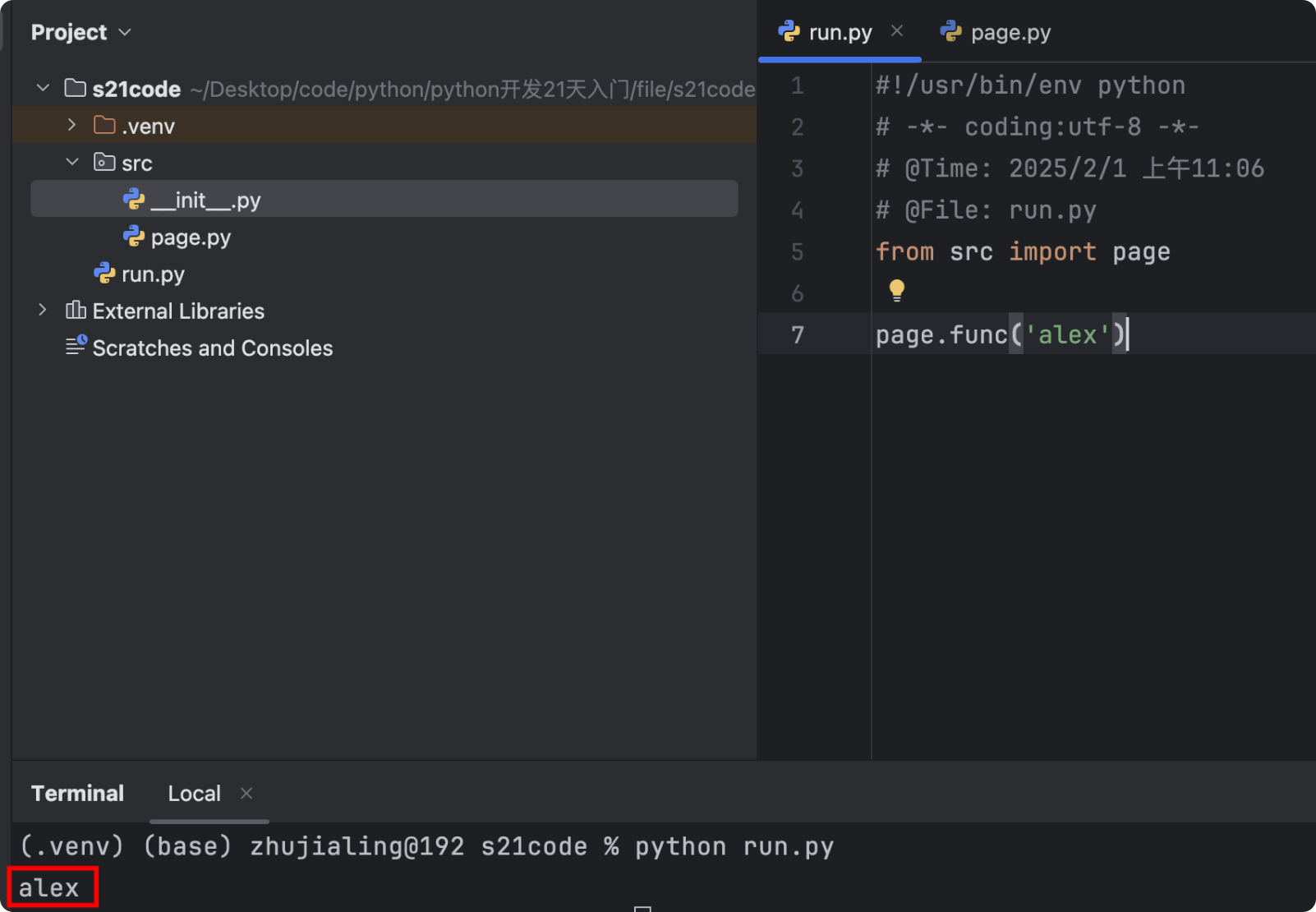
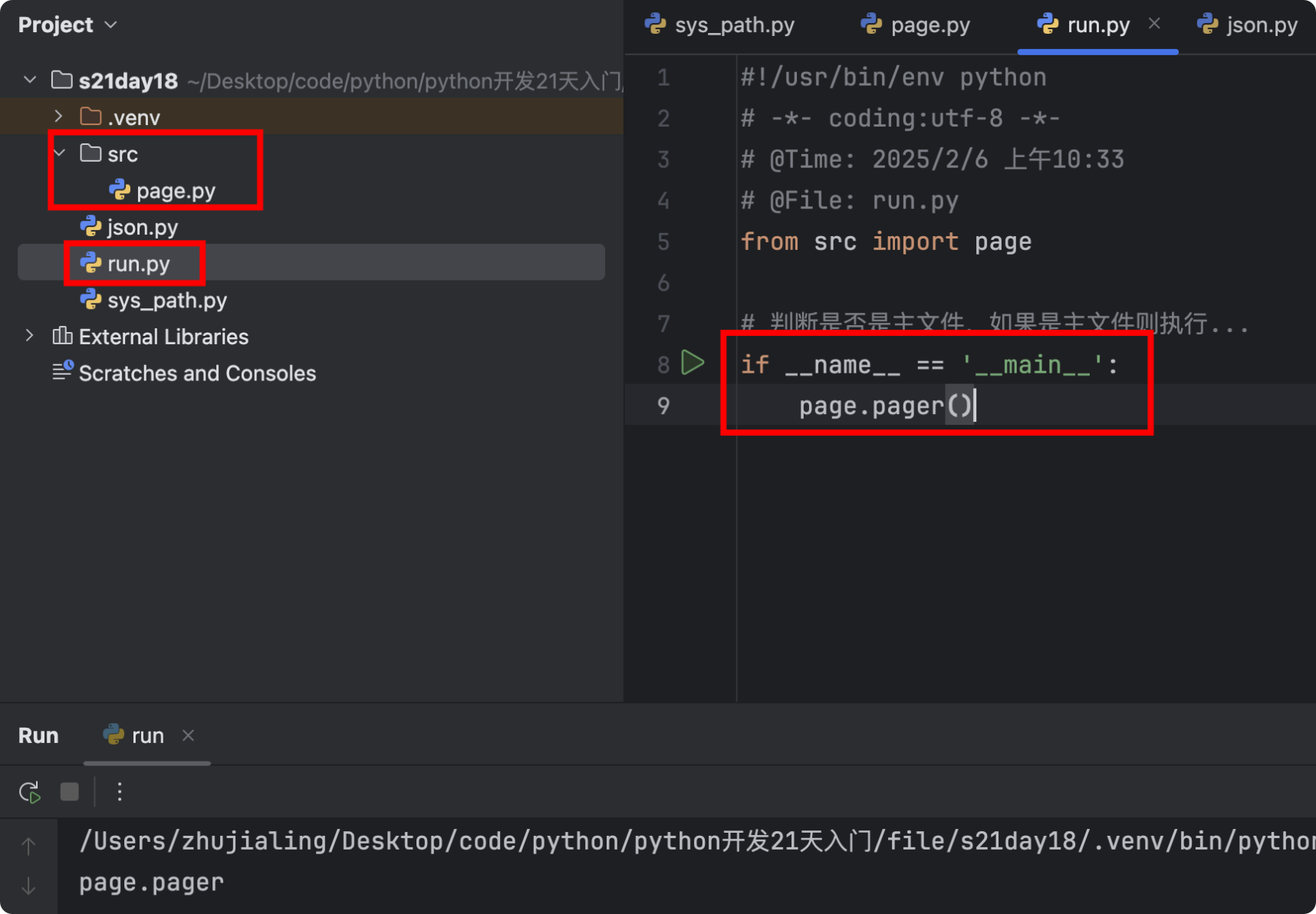
- 示例
# ./src/page.py def func(arg): print(arg) # ./run.py from src import page page.func('alex')![]()
- 内置模块:Python内部提供的功能
-
1.2 模块的调用
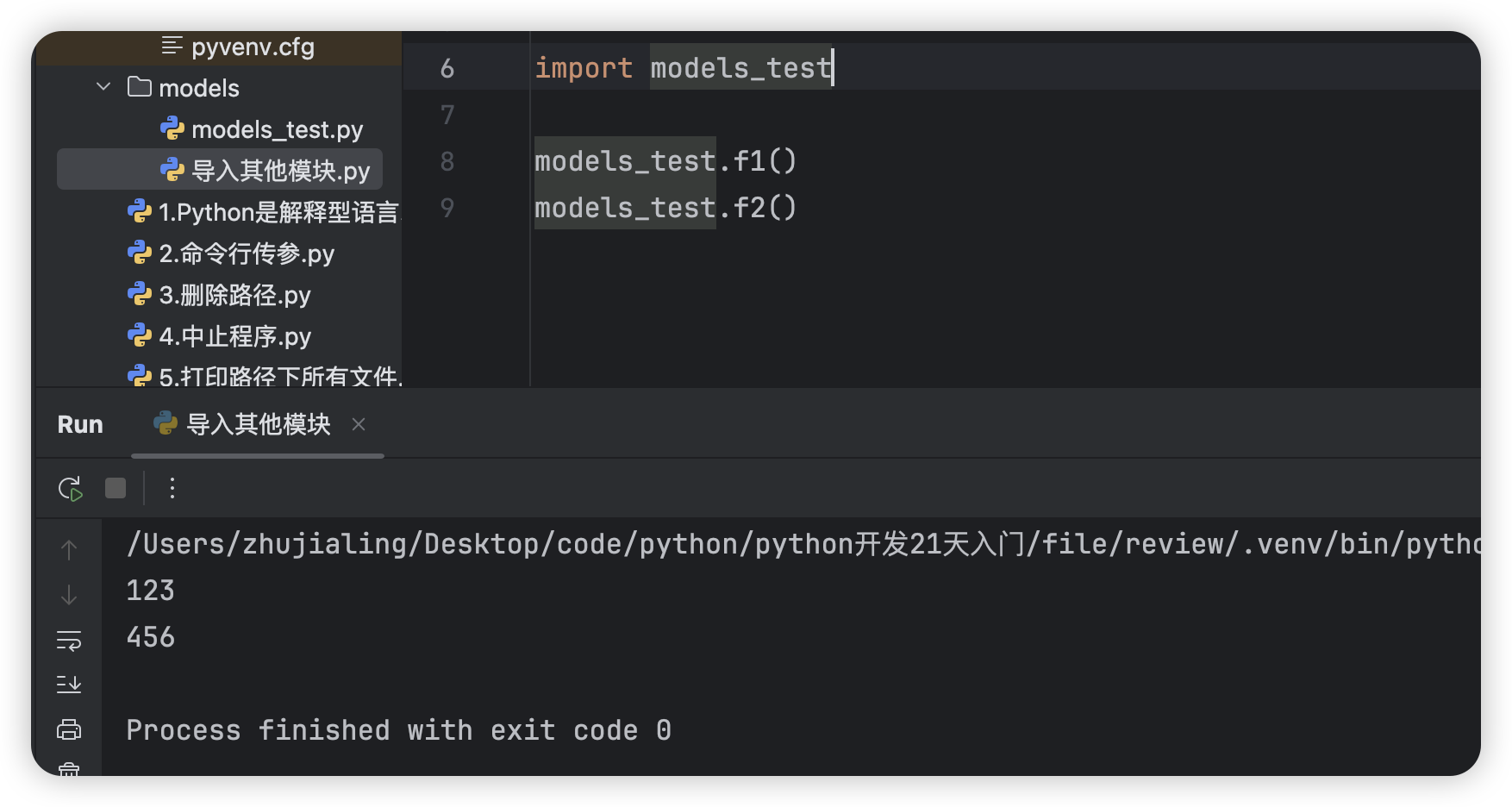
- 示例1
# 创建models_test.py,内有函数f1()和f2()的定义 def f1(): print(123) def f2(): print(456) # 在导入其他模块.py中调用f1()和f2() import models_test models_test.f1() models_test.f2()![]()
- 示例2
# lizhongwei.py def show(): print('我是张三') def func(): pass print(456) # 1.模块.py # 导入模块 加载模块中所有内容到内存 import lizhongwei print(123) # 调用模块中的函数 lizhongwei.func() # 导入模块 from lizhongwei import func, show from lizhongwei import func from lizhongwei import show from lizhongwei import * func() show() # 导入模块 起别名 防止导入的函数名与当前py文件中的函数名相同 from lizhongwei import func as f def func(): print(111) func() f()-
总结1:import导入
- import 模块1 模块1.函数()
- import 模块1.模块2.模块3 模块1.模块2.模块3.函数()
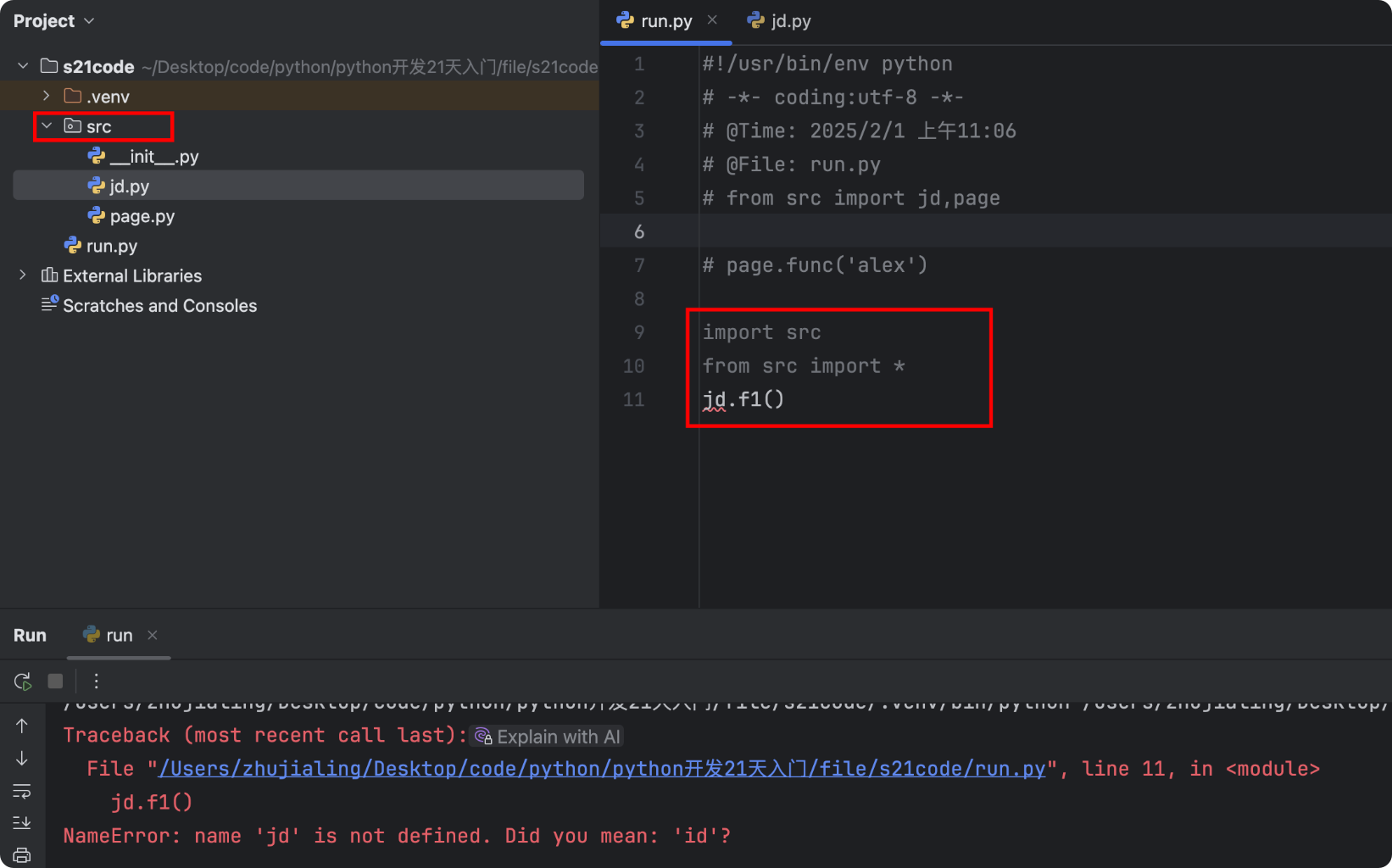
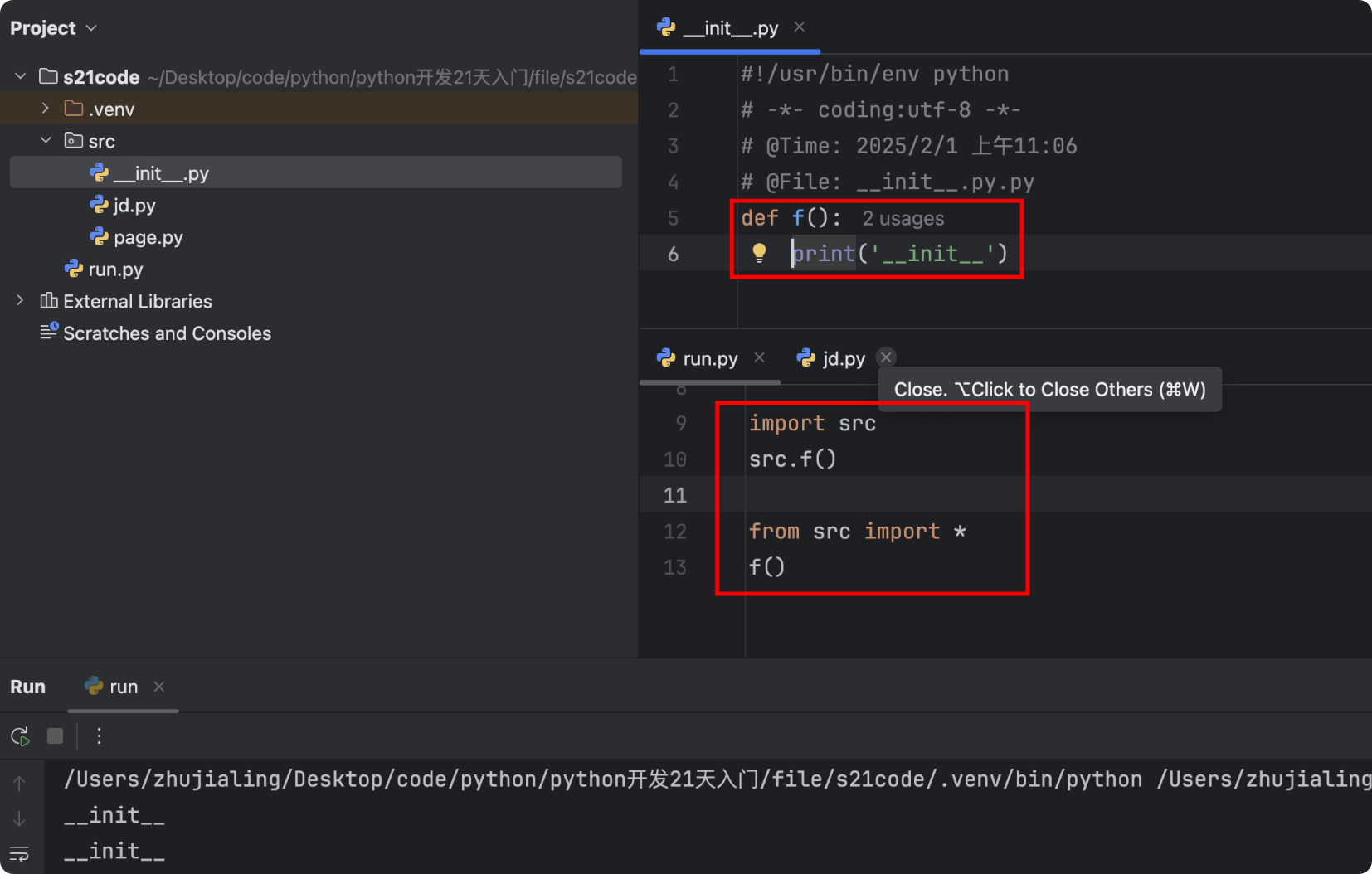
- 特殊:import 文件夹 本质上是加载了文件夹中的
__init__.py文件
# ./run.py import src # 内部加载__init__.py from src import * # 内部引入__init__.py中的内容 jd.f1() # 报错,只能使用__init__.py中的内容![]()
![]()
-
总结2:from xx import xx导入
- form 模块.模块 import 函数 函数()
- from 模块.模块 import 函数 as 别名 别名()
- from 模块.模块 import * *表示所有 函数1() 函数2()
- from 模块 import 模块 as m m.函数()
-
总结3:相对导入【不推荐】
- from . import utils
- from .. import utils
-
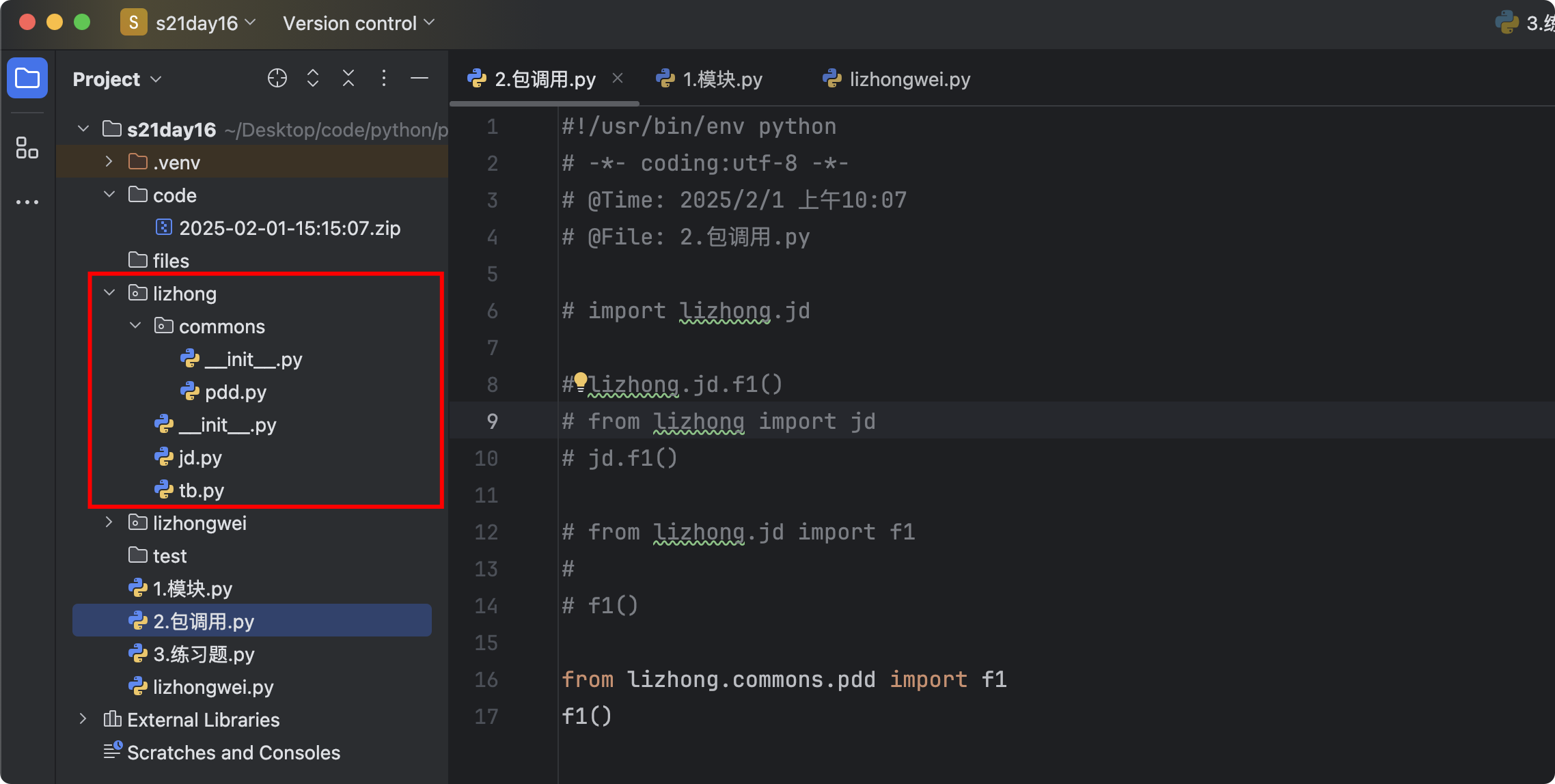
示例3
# 假设目录结构为 - lizhong - commons - pdd.py - jd.py - tb.py - 包.py from lizhong import jd jd.f1() from lizhong.jd import f1 f1() from lizhong.commons.pdd import f1 f1()![]()
- 总结
- 模块和要执行的py文件(如run.py)在同一目录且需要模块中的很多功能时,推荐用:import 模块
- 其他推荐:from 模块1 import 模块2 模块2.函数()
- 其他推荐:from 模块1.模块2 import 函数 函数()
- 注意:sys.path的作用
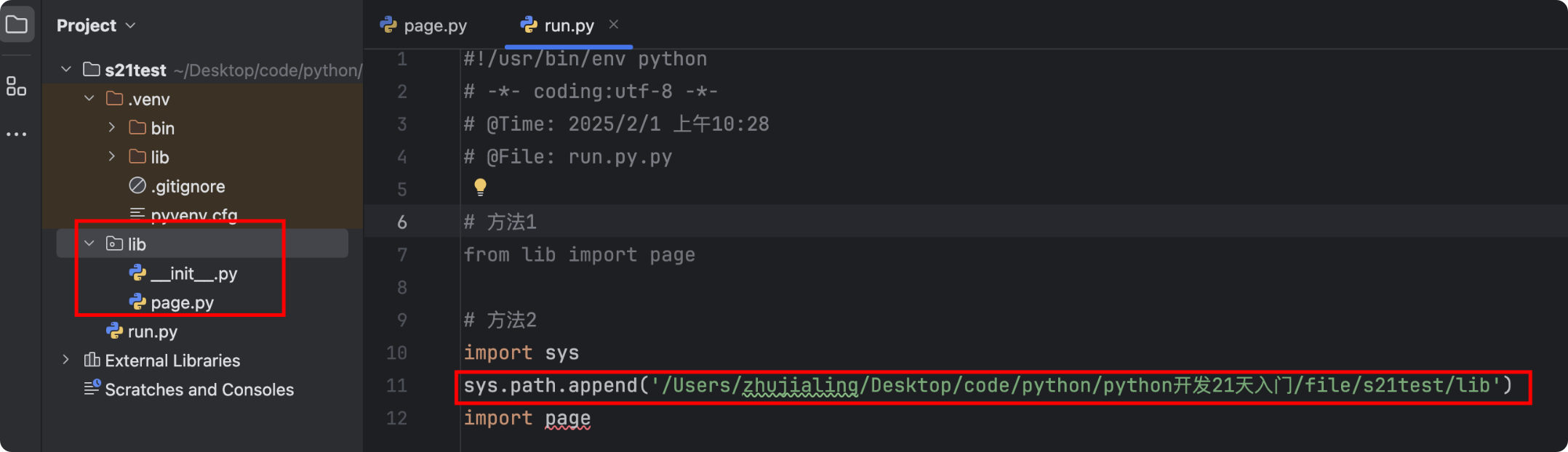
- 示例4:从当前项目的lib包中导入page.py
# 方法1:由于lib包在s21test项目根路径下,可直接导入 from lib import page # 方法2:将lib包加入到sys.path中 import sys sys.path.append('/Users/zhujialing/Desktop/code/python/python开发21天入门/file/s21test/lib') import page # 此时pycharm中会标注红色下滑曲线,但运行不会报错![]()
-
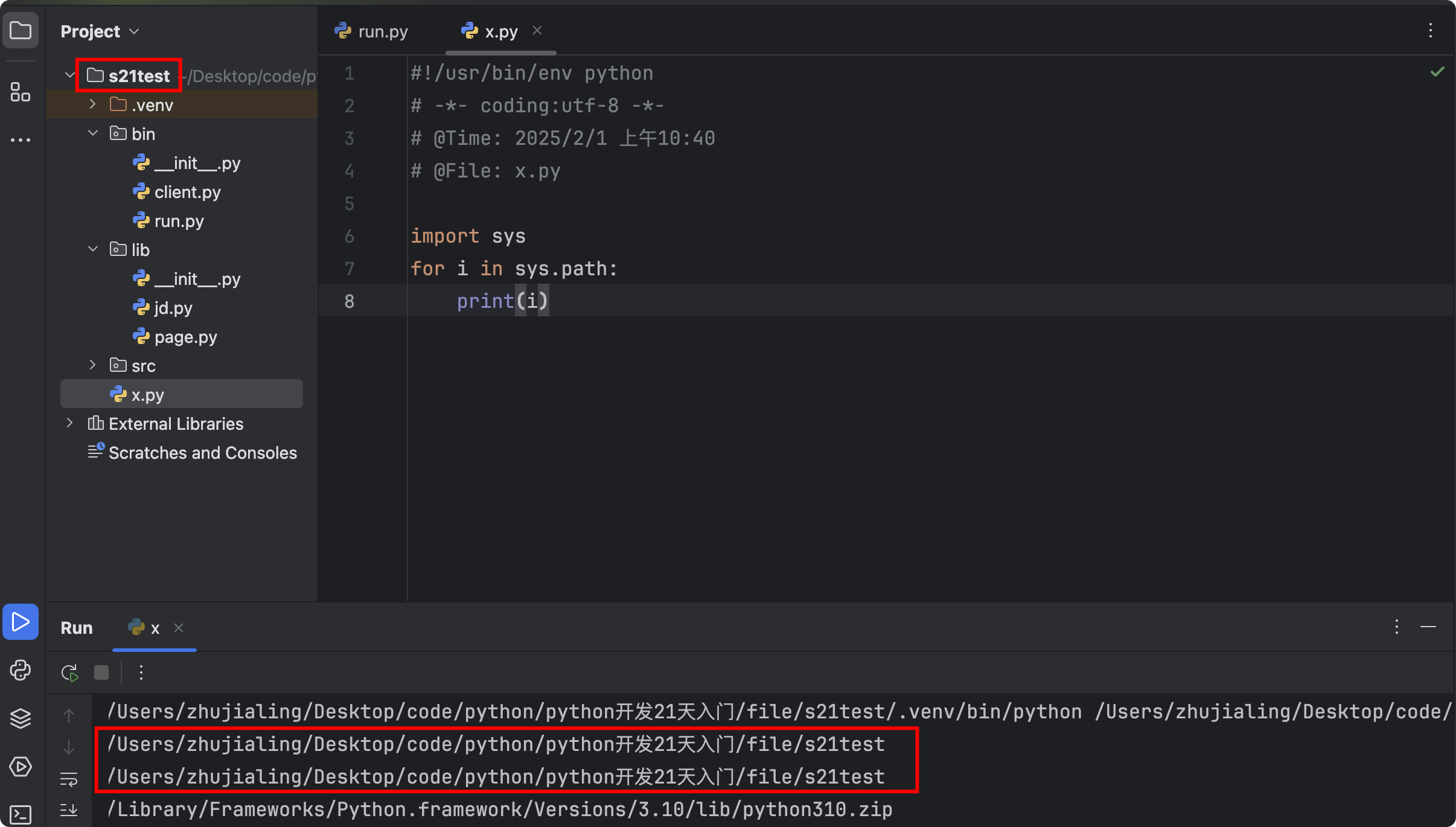
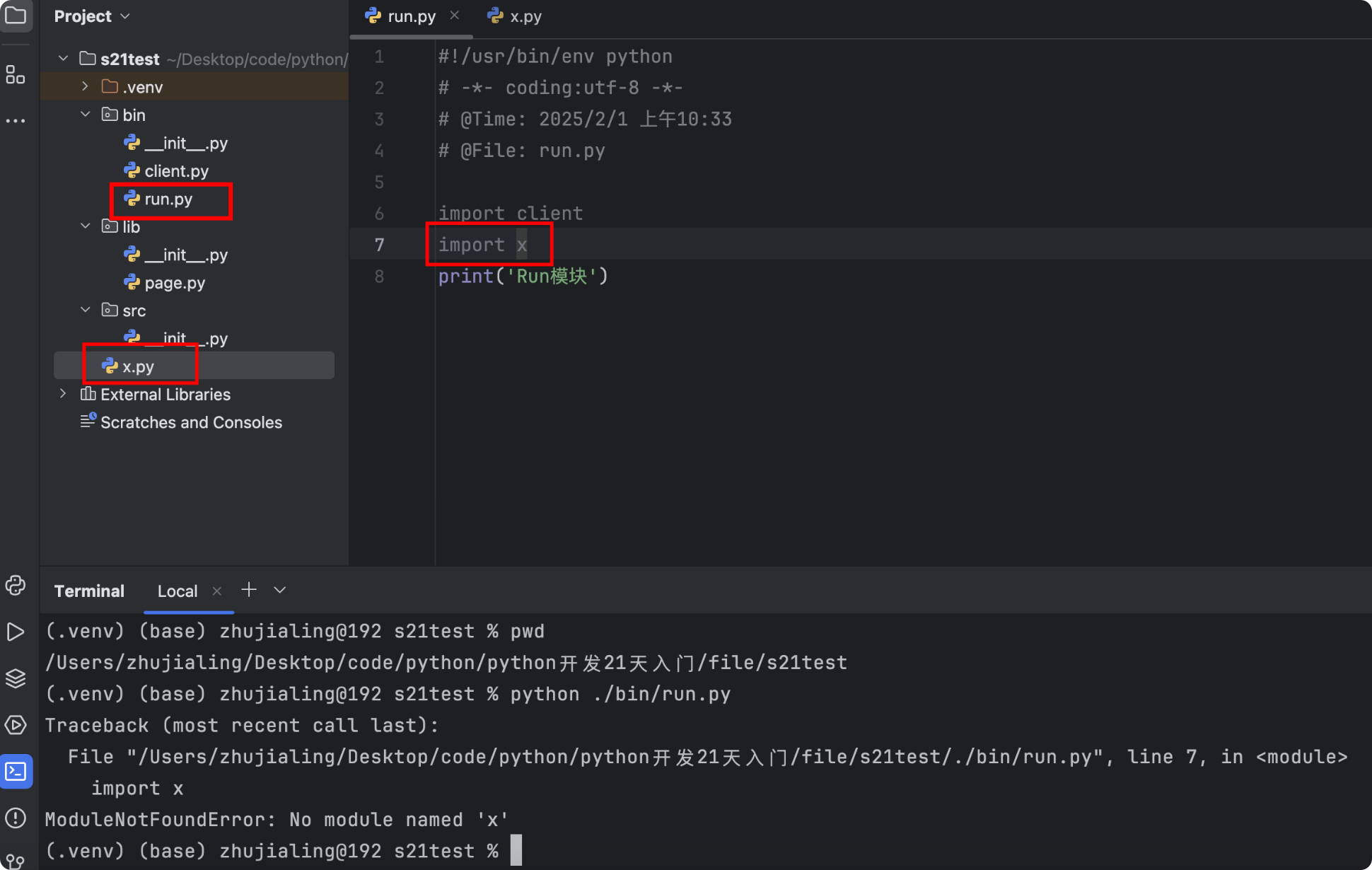
示例5:同一段代码在命令行下运行会报错,但在pycharm中运行不会报错,因为pycharm会将当前项目路径(/Users/zhujialing/Desktop/code/python/python开发21天入门/file/s21test)加到sys.path中
- 如何避免命令行报错?将项目路径加入到sys.path中即可
![]()
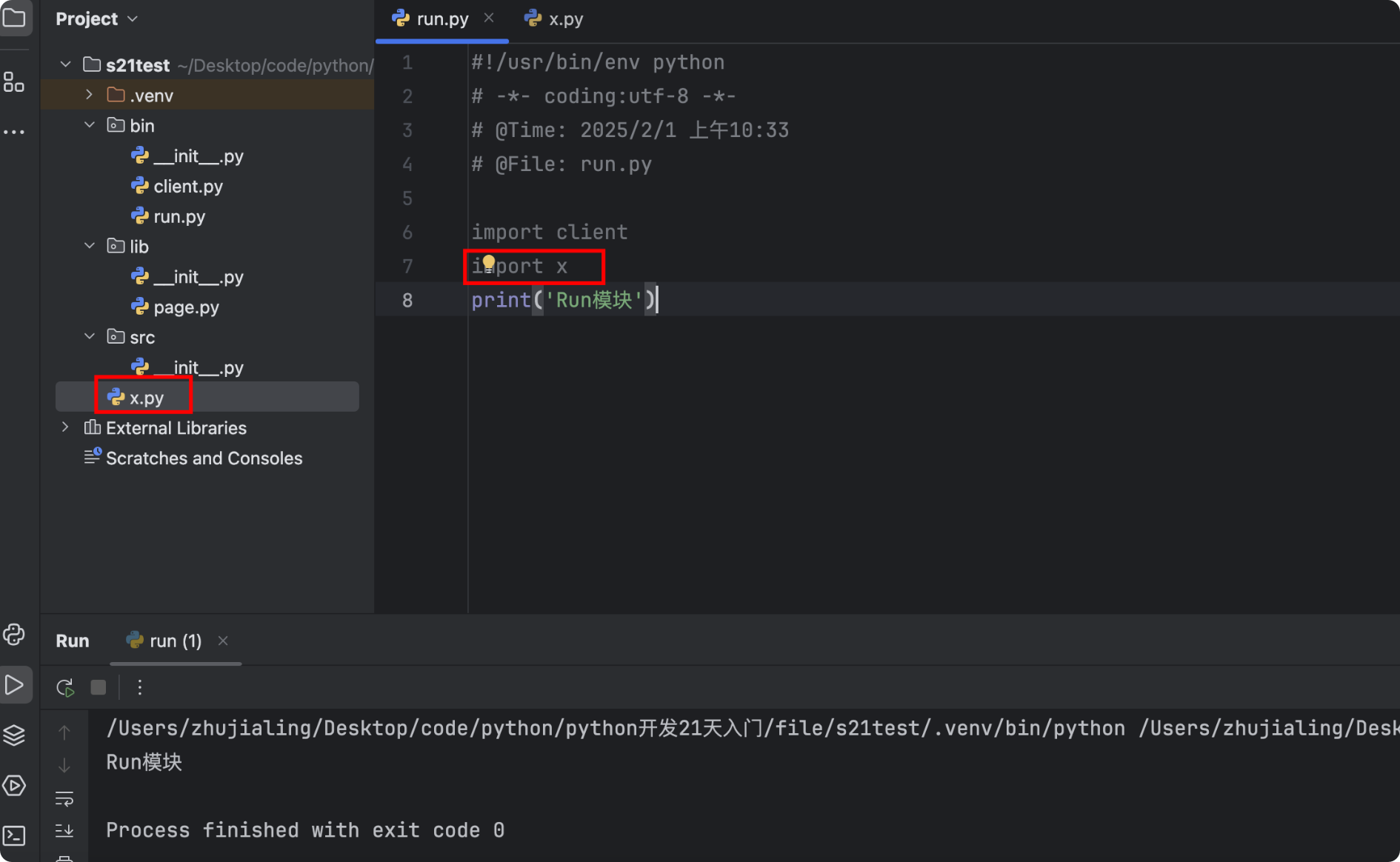
import client import x print('Run模块')![]()
![]()
- 注意:将当前脚本的默认运行目录加到sys.path中
![]()
- 如何避免命令行报错?将项目路径加入到sys.path中即可
-
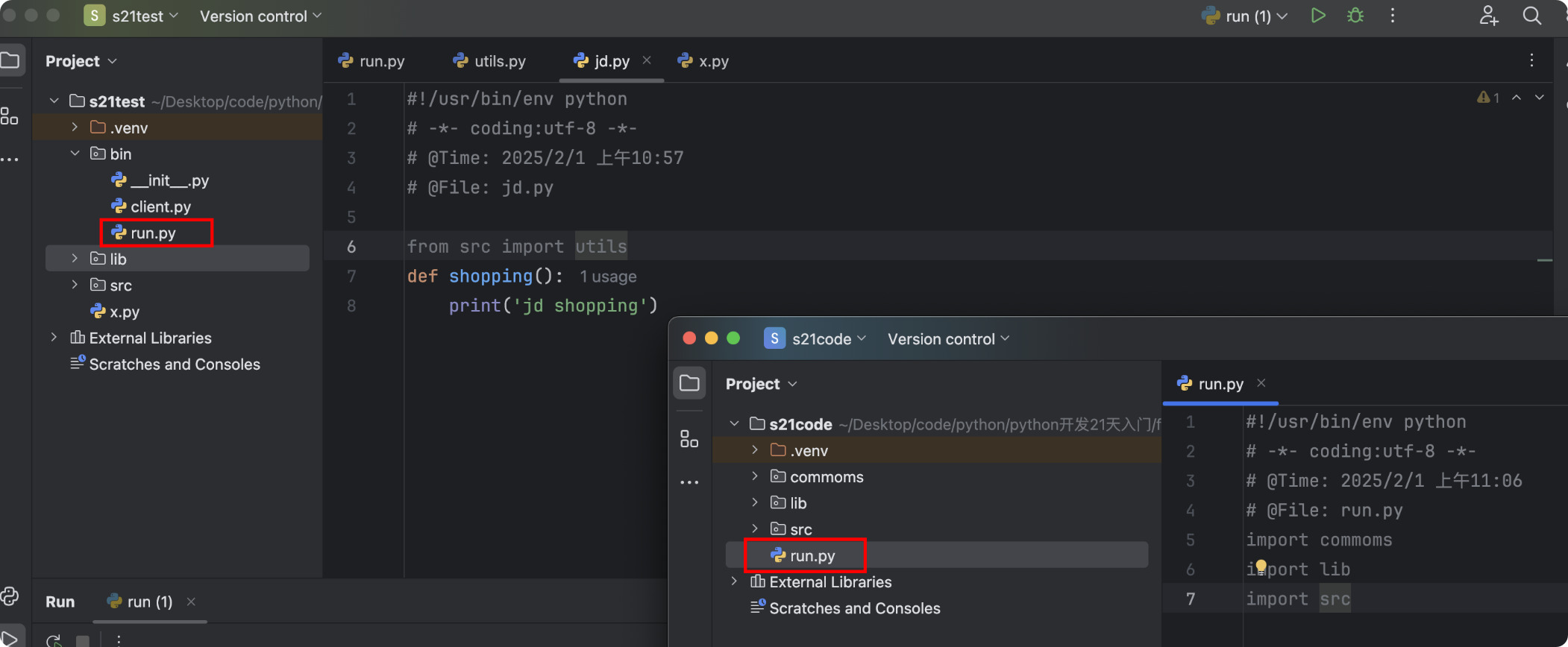
示例6
- Python文件和文件夹的命名不能与导入的模块名称相同,否则就会直接在当前目录中查找,因为Pycharm会将项目目录放入sys.path中
![]()
![]()
-
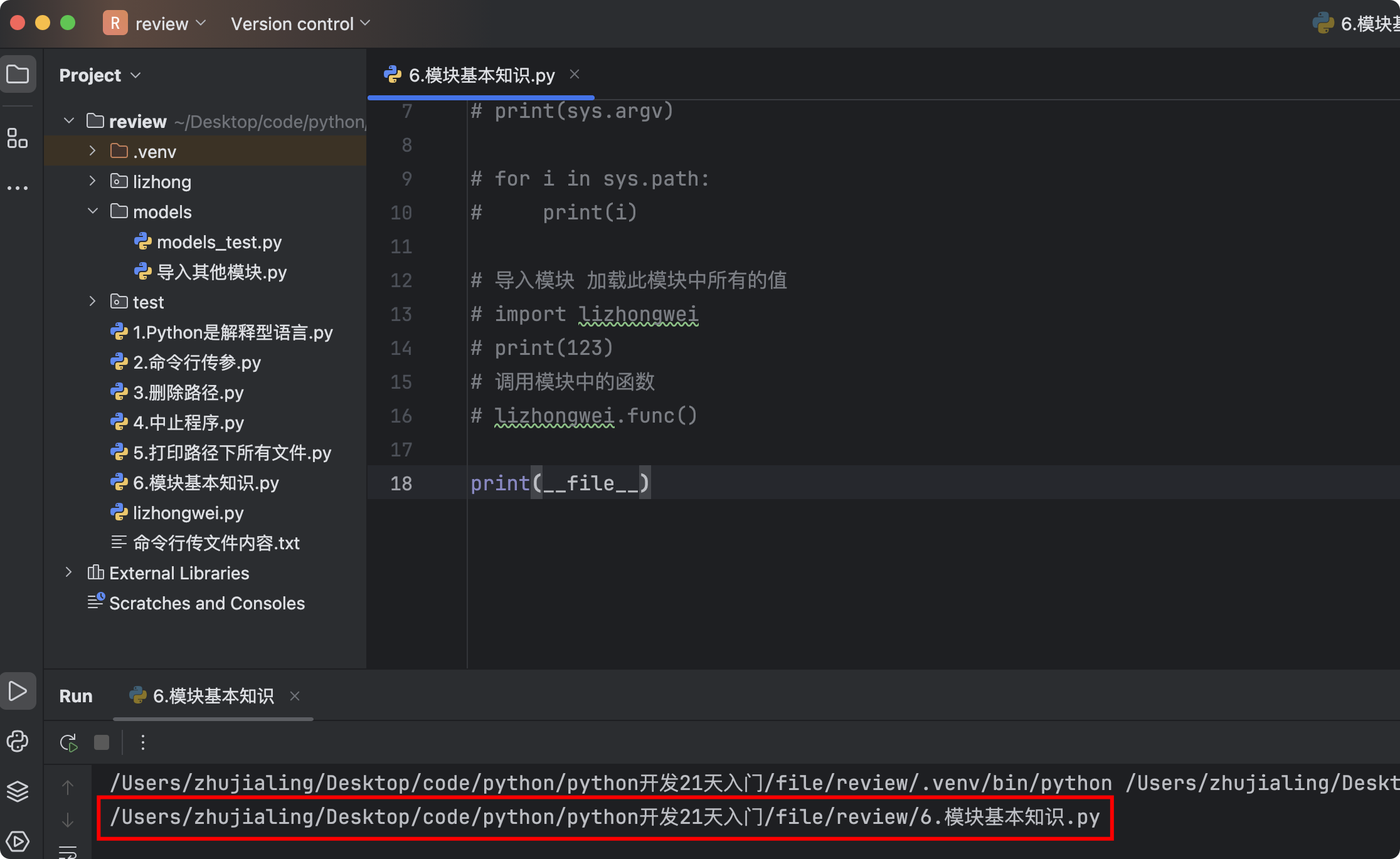
1.3 __file__导入与应用
- 1.值分析
print(__file__)- Pycharm中打印的是当前脚本的绝对路径
![]()
- MacOS命令行下打印的是当前脚本的绝对路径
![]()
- Windows10命令行下打印的结果要参考执行脚本时后方的参数(即python后接的参数),可以是绝对路径,也可以是相对路径
- 小结
- __file__变量保存了当前脚本的路径,它可以在脚本或模块中使用,以访问当前文件的完整路径
- 该功能在需要动态获取脚本路径的场景中非常有用,比如在读取配置文件、日志文件或需要基于脚本位置执行其他操作时
- Pycharm中打印的是当前脚本的绝对路径
- 2.应用:本机模块代码拷贝其他机器仍能正常运行
import sys import os BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR) - 1.值分析
-
1.4 主文件
![]()

2.os模块
- os.mkdir() 创建目录,用的不多,无法递归创建子目录
import os
os.mkdir('./file/db')
file_path = r'./file/db/user.txt'
with open(file_path, mode='w', encoding='utf-8') as f:
f.write('hello')
- os.makedirs() 创建目录,递归生成多级目录,使用的多
import os
file_path = r'./file/db/dbb/xx/user.txt'
file_folder = os.path.dirname(file_path) # 获取文件的上级目录
if not os.path.exists(file_folder): # 检查上级目录是否存在
os.makedirs('./file/db/dbb/xx')
with open(file_path, mode='w', encoding='utf-8') as f:
f.write('hello')
- os.path.join()
- os.path.dirname()
- os.path.abspath()
- os.path.exists()
- os.stat('文件路径')
- os.listdir()
- os.walk()
- os.rename(path)
import os
os.rename('./file/db', './file/bb') # 目录重命名
3.sys模块
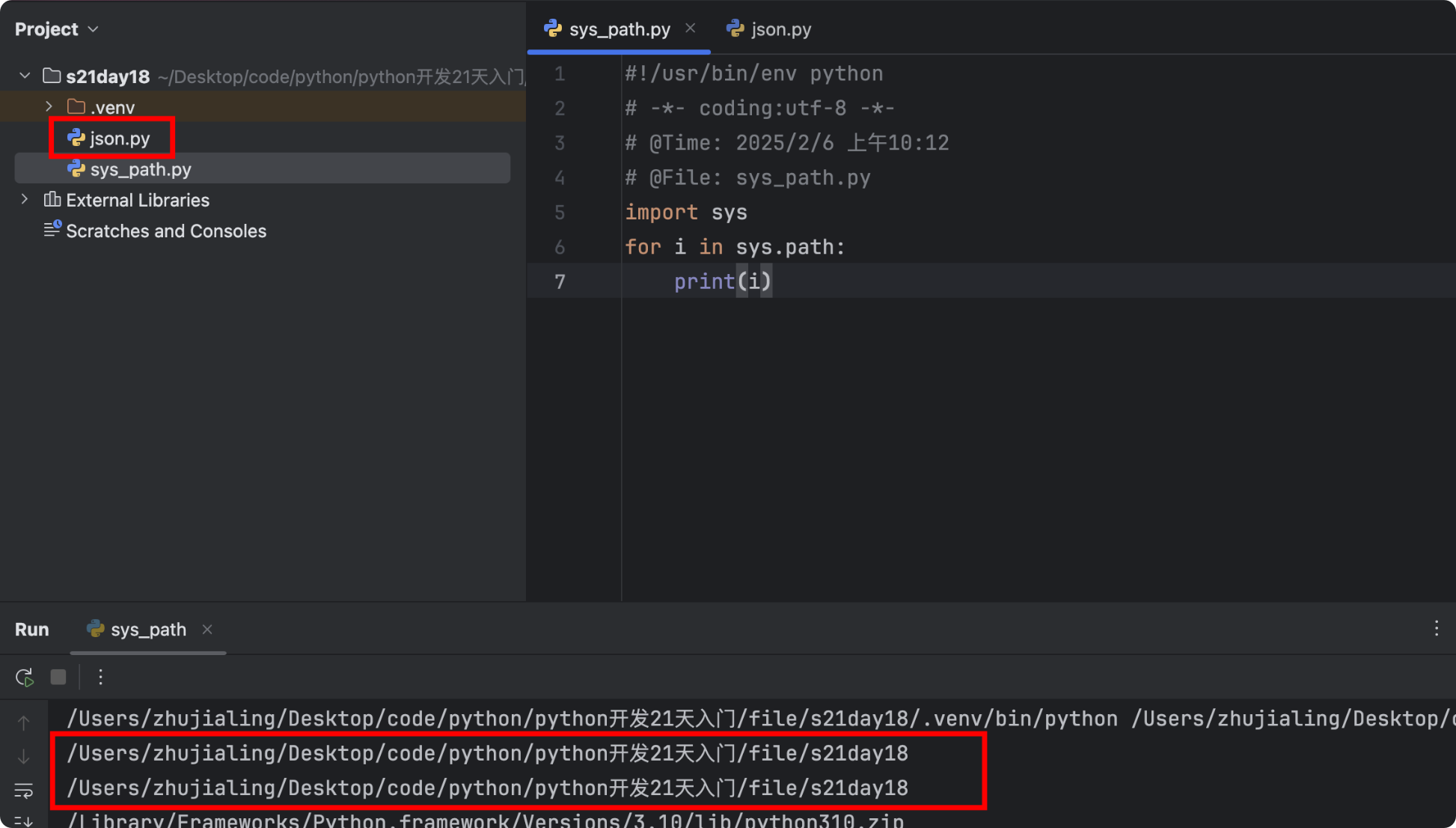
- sys.path
- Python程序在导入模块时,会在安装路径下去寻找模块的位置,查找的具体路径会按照列表sys.path中的路径逐个查找
- 导入的模块默认会到Python安装目录的Lib目录中找
- 第三方模块到Lib/site-packages目录中找
import sys for i in sys.path: print(i)![]()
- sys.path.append(r'D:\code')
- 假设路径'D:\code'下有自定义模块,该指令会将会将对应目录加入到Python默认的模块查找路径中
- 这样'D:\code'下的模块就可以直接import了

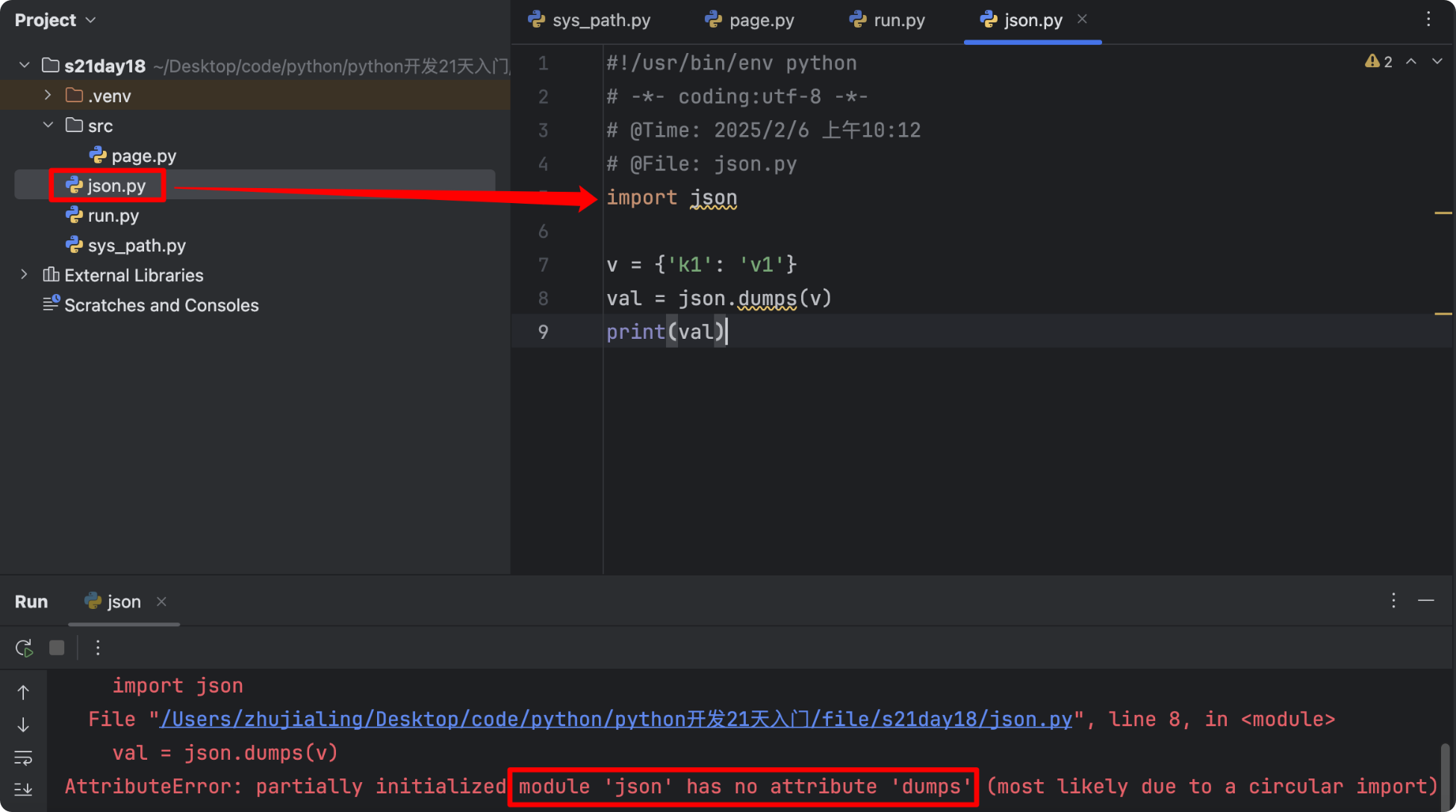
4.json模块
- 序列化
- 其他数据类型转为json类型
- 反序列化
- json类型转为其他数据类型
- json数据类型的特征
- 是一个特殊的字符串【长得像列表/字典/字符串/数字/真假】
- 最外层必须是一个列表或字典
- 如果包含字符串,必须是双引号""
- 只有Python中字符串可以用单引号,其他语言都是双引号
- 爬虫用的比较多
- 优点:所有语言通用
- 缺点:只能序列化基本数据类型 list/dict/int
- 常用函数
- 1.dumps()
- 序列化:将Python的值转换为json格式的字符串
v = [12, 3, 4, {'k1': 'v1'}, True, 'hello'] import json v1 = json.dumps(v) print(v1) # 单引号全变成双引号 # [12, 3, 4, {"k1": "v1"}, true, "hello"] v = [{1, 2, 3}, True] print(json.dumps(v)) # 报错 集合不是可序列化对象- 注意中文
v = {'k1': 'alex', 'k2': '张三'} import json val = json.dumps(v) print(val) # Unicode对照表 {"k1": "alex", "k2": "\u5f20\u4e09"} v = {'k1': 'alex', 'k2': '张三'} import json val = json.dumps(v, ensure_ascii=False) print(val) # {"k1": "alex", "k2": "张三"} - 2.loads()
- 反序列化:将json格式的字符串转换成Python的数据类型
v2 = '["alex", 123]' print(type(v2)) v3 = json.loads(v2) print(v3, type(v3)) # <class 'str'> # ['alex', 123] <class 'list'> - 3.dump()
- 将Python对象转换为字符串或字节流,以便存储到文件、数据库或通过网络发送
v = {'k1': 'alex', 'k2': '张三'} f = open('./file/x.txt', mode='w', encoding='utf-8') val = json.dump(v, f) # 序列化v并写入到文件x.txt中 print(val) f.close() - 4.load()
- 读取json文件中内容到内存,加载为Python对象
v = {'k1': 'alex', 'k2': '张三'} f = open('./file/x.txt', mode='r', encoding='utf-8') data = json.load(f) f.close() print(data, type(data))
+-------------------+---------------+ | Python | JSON | +===================+===============+ | dict | object | +-------------------+---------------+ | list, tuple | array | +-------------------+---------------+ | str | string | +-------------------+---------------+ | int, float | number | +-------------------+---------------+ | True | true | +-------------------+---------------+ | False | false | +-------------------+---------------+ | None | null | +-------------------+---------------+ - 1.dumps()
5.pickle模块
- 序列化
- 其他数据类型转为pickle类型
- 反序列化
- pickle类型转为其他数据类型
- pickle数据类型的特征
- 是一个字节码
- 优点:python中除socket外所有的东西都能被序列化
- 缺点:序列化的内容只有python可以识别
- 常用函数
- 1.dumps()
import pickle v = {1, 2, 3, 4} val = pickle.dumps(v) print(val) # b'\x80\x04\x95\r\x00\x00\x00\x00\x00\x00\x00\x8f\x94(K\x01K\x02K\x03K\x04\x90.' def f1(): print('f1') v1 = pickle.dumps(f1) print(v1) # b'\x80\x04\x95\x13\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x94\x8c\x02f1\x94\x93\x94.'- 2.loads()
data = pickle.loads(val) print(data, type(data)) # {1, 2, 3, 4} <class 'set'> v2 = pickle.loads(v1) print(v2) v2() # <function f1 at 0x144c56480> # f1- 3.dump()
v = {1, 2, 3, 4} f = open('./file/x.txt', mode='w', encoding='utf=8') val = pickle.dump(v, f) f.close() print(val) # TypeError: write() argument must be str, not bytes # 报错:写入时应当写入字节码 v = {1, 2, 3, 4} f = open('./file/x.txt', mode='wb') val = pickle.dump(v, f) f.close() print(val) # None- 4.load()
f = open('./file/x.txt', mode='rb') data = pickle.load(f) f.close() print(data) # {1, 2, 3, 4} - 字节类型
- v1 = '张三'称为字符串类型,内部是Unicode编码,共4B
- v2 = v1.encode('utf-8') 称为字节(bytes)类型
- 上述pickle模块在执行时得到的形如b'......',就是将Unicode经过某种编码方式压缩之后的0101...
f = open('./file/x.txt', mode='wb') data = 'hello'.encode('utf-8') print(data, type(data)) # b'hello' <class 'bytes'> f.write(data) f.close() v = {1, 2, 3, 4} val = pickle.dumps(v) print(val, type(val)) # 字节类型 # b'\x80\x04\x95\r\x00\x00\x00\x00\x00\x00\x00\x8f\x94(K\x01K\x02K\x03K\x04\x90.' <class 'bytes'> v = [11, 22, 33] import json va = json.dumps(v) print(va, type(va)) # 字符串类型 # [11, 22, 33] <class 'str'> - 6.异常处理
- 基本结构
try: python_code except Exception as e: print("操作异常!") import requests try: ret = requests.get("http://www.google.com") print(ret.text) except Exception as e: print("请求异常!")- 案例分析
def func(a): try: a.strip() except Exception as e: print('处理失败') return 123 v = func('alex') print(v) v = func([11, 22, 33]) print(v) def func(a): try: return a.strip() except Exception as e: pass return False v = func('alex ') if not v: print('函数执行失败') else: print('结果是', v)- 练习题
# 1.写函数,函数接收一个列表,请将列表中的元素每个都加100 def func(data): result = [] for item in data: if item.isdecimal(): result.append(int(item) + 100) return result # 2.写函数接收一个列表,列表中都是url,请访问每个地址并获取结果。 import requests def func1(url_list): result = [] try: for url in url_list: response = requests.get(url) result.append(response.text) except Exception as e: # 抛出异常后for循环强行结束,result中只有baidu的结果 pass return result def func2(url_list): result = [] for url in url_list: try: response = requests.get(url) result.append(response.text) except Exception as e: # 抛出异常后for循环继续,result中有baidu/google/bing的结果 pass return result func1(['http://www.baidu.com','http://www.google.com','http://www.bing.com']) func2(['http://www.baidu.com','http://www.google.com','http://www.bing.com'])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号