Python基础6——装饰器(续) 递归 模块1
1.函数
- 1.1 参数
- 当默认参数的值为可变类型时慎用
# 不推荐使用以下代码 def func(data, value=[]): pass- 可以将默认参数的值改为None
# 推荐使用以下代码 def func(data, value=None): if not value: value = []- 案例
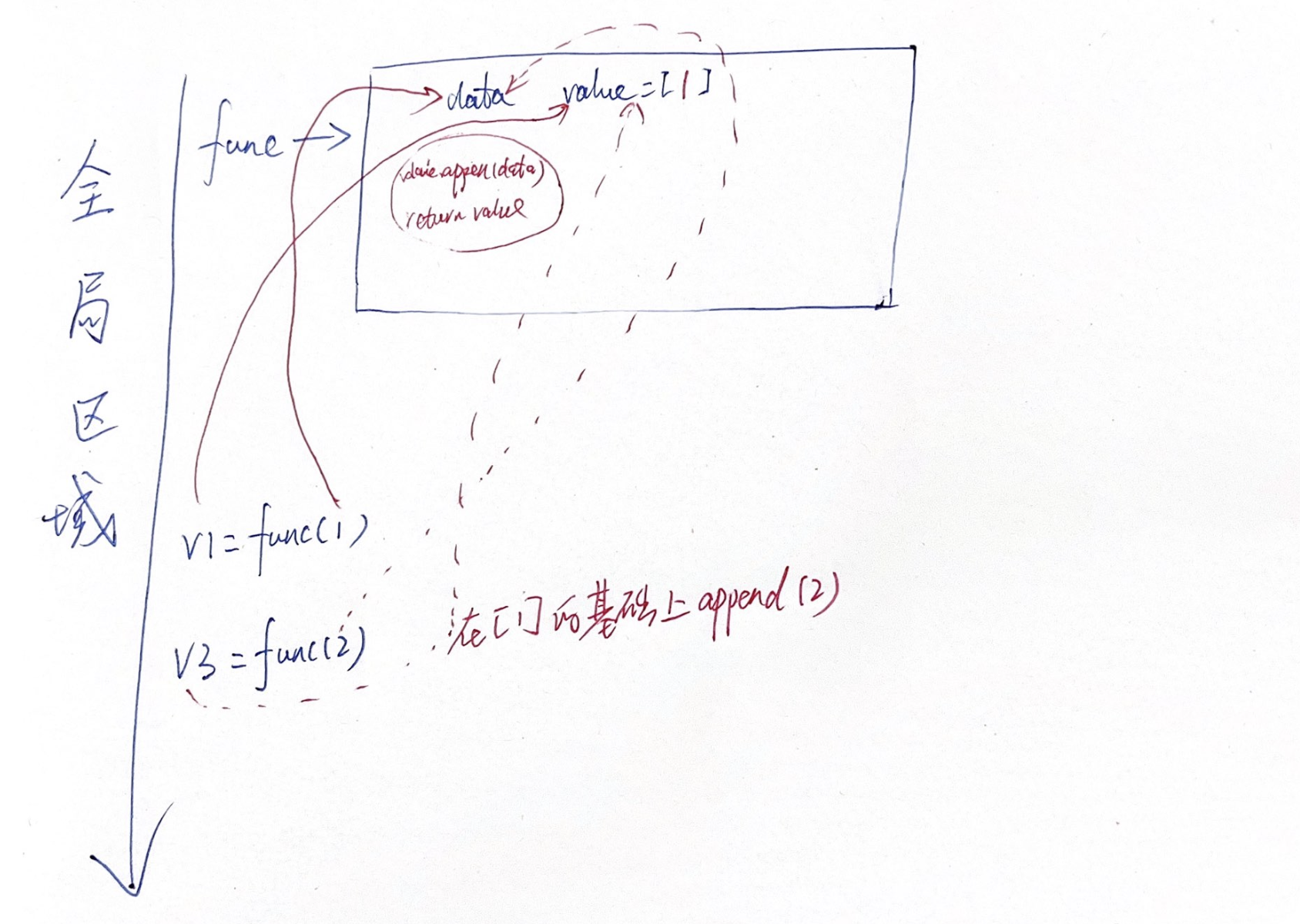
def func(data, value=[]): value.append(data) return value v1 = func(1) # [1,] v2 = func(1, [11, 22, 33]) # [11, 22, 33, 1] 没有使用默认的列表,而是传了一个新的列表 print(v1, v2) v3 = func(2) print(v3) # 结果不是[2] 而是[1, 2] ,因为以默认列表的形式传递2时,value已经是[1]了。参考函数的执行空间![]()
def func(data, value=[]): value.append(data) return value v1 = func(1) print(v1) # [1] v2 = func(2) print(v2, v1) # [1, 2] [1, 2]- 面试题:下述代码在使用期间有什么陷阱?
def func(a, b=[]) : pass # 当调用func期间不传递列表参数时,默认用的都是同一个地址,后续调用的结果会受前面调用的影响 def func(a, b=[]): b.append(a) return b r1 = func(1) r2 = func(2, [11, 22]) r3 = func(3) print(r1, r2, r3) # [1, 3] [11, 22, 2] [1, 3] r1和r3的结果一致,因为两者用的是同一个引用 def func(a, b=[]): b.append(a) print(b) func(1) # [1,] func(2, [11, 22]) # [11, 22, 2] func(3) # [1, 3] - 1.2 返回值
- 分析函数执行内存中的数据存储情况
def func(name): def inner(): print(name) return 123 return inner v1 = func('alex') v2 = func('eric') v1() v2()- 辨认闭包
# 不是闭包:只封装了值但内部函数没有使用 def func1(name): def inner(): return 123 return inner # 是闭包:封装值 + 内层函数需要使用 def func2(name): def inner(): print(name) return 123 return inner - 1.3 递归
- 函数自己调用自己
- 执行效率低,内存一直在被消耗
- 务必加上递归终止条件
def func(): print(1) func() func() # 这段代码不会无限制递归调用- Python做了递归深度的限制,超过限制会报错,具体多少跟电脑系统有关,默认为1000次
![]()
- 案例
def func(i): print(1) func(i+1) func(1) # 1 2 3 4 5 ... 无尽递归 def func(a, b): print(b) func(b, a+b) # func(0, 1) # 1 1 2 3 5 8 斐波那契数列 无尽递归 def func(a): if a == 5: return 100000 result = func(a+1) + 10 return result v = func(1)

2.装饰器(续)
- 2.1 基本格式
def x(func):
def inner():
return func()
return inner
@x
def index():
pass
- 2.2 关于参数
def x(func):
def inner(a1):
return func(a1)
return inner
@x
def index(a1):
pass
# index ---> inner
# index()
def x(func):
def inner(a1, a2):
return func(a1, a2)
return inner
@x
def index(a1, a2):
pass
# index ---> inner
index(1, 2)
###########参数的统一目的是为了给原来的index函数传参
def x(func):
def inner(a1, a2):
return func()
return inner
@x
def index():
pass
# func ---> 原来的index函数
# index ---> inner
index(1, 2) # 这样调用不会出错
# 如果给好几个函数写一个统一的装饰器,怎么办?
def x1(func):
def inner():
return func()
return inner
def x2(func):
def inner(a1):
return func(a1)
return inner
@x1
def f1():
pass
# func ---> 原f1函数
# f1 ---> inner
# f1()
@x2
def f2(a1):
pass
# func ---> f2函数
# f2 ---> inner
# f2(12)
def f3(a1, a2):
pass
# 以上方法中的装饰器不具有统一性
# 建议按照以下方法装饰
def x1(func):
def inner(*args, **kwargs):
return func(*args, **kwargs)
return inner
- 2.3 关于返回值
# 代码段1
def x1(func):
def inner(*args, **kwargs):
return func(*args, **kwargs)
return inner
@x1
def f1():
print(123)
v1 = f1()
print(v1)
# 123
# None
# 代码段2
def x1(func):
def inner(*args, **kwargs):
data = func(*args, **kwargs)
return data
return inner
@x1
def f1():
print(123)
return 666
v1 = f1()
print(v1)
# 123
# 666
# 代码段3
def x1(func):
def inner(*args, **kwargs):
data = func(*args, **kwargs)
return inner
@x1
def f1():
print(123)
return 666
v1 = f1()
print(v1)
# 123
# None
- 2.4 关于装饰器的建议写法
def x1(func):
def inner(*args, **kwargs):
data = func(*args, **kwargs)
return data
return inner
- 2.5 关于函数执行前后
# 代码段1
def x1(func):
def inner(*args, **kwargs):
print("调用原函数之前")
data = func(*args, **kwargs) # 执行原函数并获取返回值
print("调用原函数之后")
return data
return inner
@x1
def index():
print(123)
index()
# 调用原函数之前
# 123
# 调用原函数之后
# 代码段2
def x1(func):
def inner(*args, **kwargs):
print("调用原函数之前")
data = func(*args, **kwargs)
return data
print("调用原函数之后") # 永远不执行
return inner
- 2.6 带参数的装饰器
- 1.普通装饰器的执行过程
- 第1步:将函数index作为参数传递给wrapper,执行 inner = wrapper(index)
- 第2步:将返回值重新赋值给index,即index = inner
def wrapper(func): def inner(*args, **kwargs): print("调用原函数之前") data = func(*args, **kwargs) return data return inner @wrapper def index(): pass def wrapper(func): print('wrapper函数') def inner(*args, **kwargs): print('inner函数') data = func(*args, **kwargs) return data return inner @wrapper def index(): pass # wrapper函数 - 2.带参数装饰器的执行过程
- 第1步:执行 wrapper = x(9)
- 第2步:@uuu(9)等价于@wrapper
- 将函数index作为参数传递给wrapper,执行 inner = wrapper(index)
- 将返回值重新赋值给index,即index = inner
def x(counter): def wrapper(func): def inner(*args, **kwargs): data = func(*args, **kwargs) return data return inner return wrapper @x(9) # 等价于@wrapper def index(): pass def f(counter): print('f函数') def wrapper(func): print('wrapper函数') def inner(*args, **kwargs): print('inner函数') data = func(*args, **kwargs) return data return inner return wrapper @f(9) # index = f(9)(index) def index(): pass index() # f函数 # wrapper函数 # inner函数- 带参数装饰器的应用
- 不同网页的超时时间不同,可以用传参(时间)的装饰器实现
- 3.练习题
# 1.写一个带参数的装饰器,要求传入的参数是多少,被装饰的函数就执行多少次,每次的结果添加到列表中,最终返回列表 def f(counter): def wrapper(func): def inner(*args, **kwargs): result = [] for i in range(0, counter): data = func(*args, **kwargs) result.append(data) return result return inner return wrapper @f(9) def index(): # pass return 1 v = index() print(v) # 2.写一个带参数的装饰器,实现传入的参数是多少,被装饰的函数就要执行多少次,并返回最后一次执行的结果 def f(counter): def wrapper(func): def inner(*args, **kwargs): for i in range(0, counter): data = func(*args, **kwargs) return data return inner return wrapper @f(9) def index(): # pass return 1 v = index() print(v) # 1 # 3.写一个带参数的装饰器,实现传入的参数是多少,被装饰的函数就要执行多少次,并返回执行结果中最大的值 def f(counter): def wrapper(func): def inner(*args, **kwargs): value = 0 for i in range(0, counter): data = func(*args, **kwargs) if data > value: value = data return value return inner return wrapper @f(9) def index(): # pass return 1 v = index() print(v) # 1 - 1.普通装饰器的执行过程
3.模块
-
3.1 sys:与Python解释器相关的数据
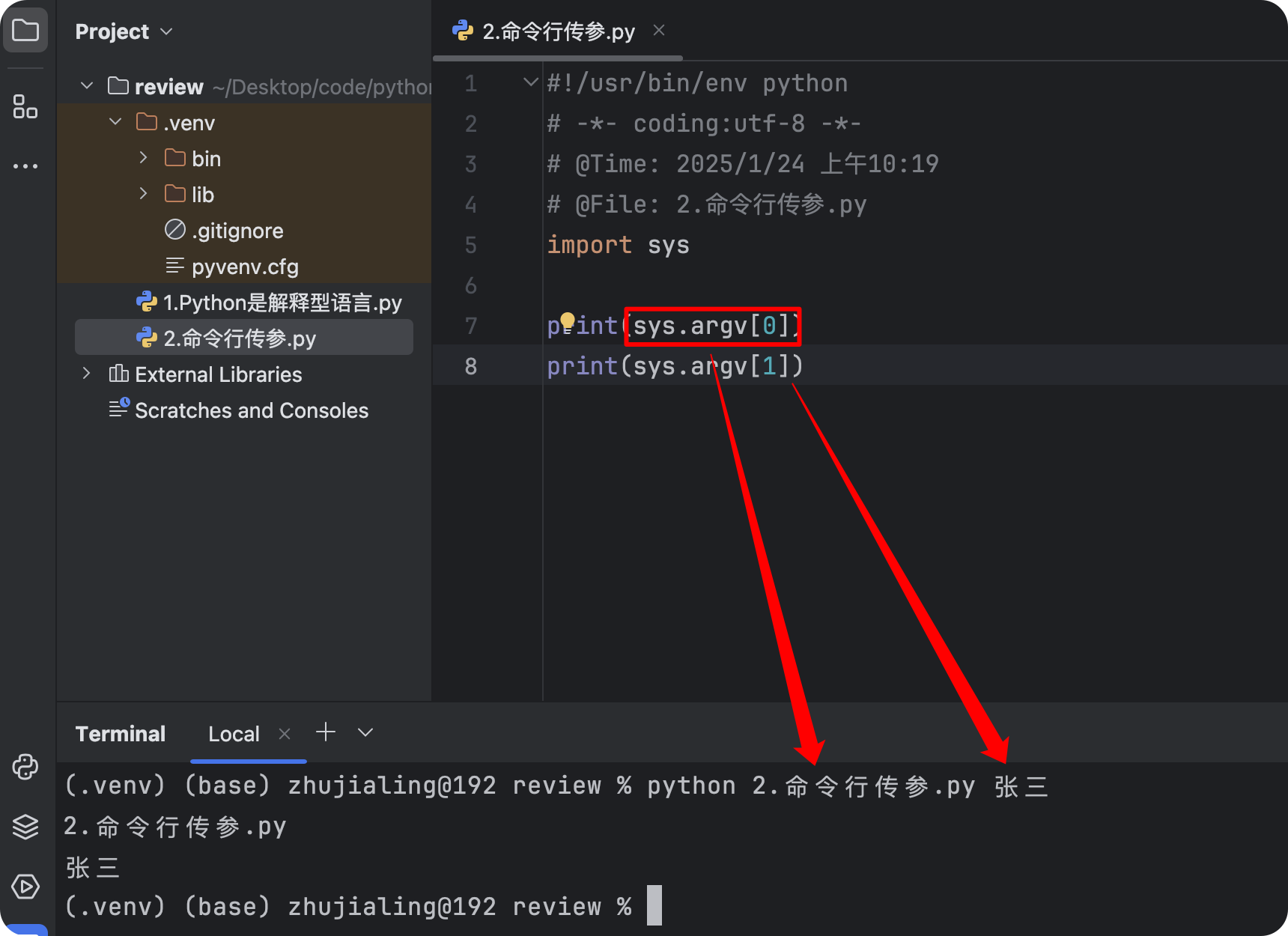
- 1.sys.argv
- 命令行传参,shell脚本运维时用的比较多
import sys print(sys.argv[0]) print(sys.argv[1])
![]()
- 2.sys.getrefcount(param)
- 获取变量的引用数量
import sys a = [11, 22, 33] # 1次 print(sys.getrefcount(a)) # 2次 获取一个值的引用计数 b = a print(sys.getrefcount(a)) # 3次 - 3.sys.getrecursionlimit()
- 获取默认支持的递归层级
v1 = sys.getrecursionlimit() print(v1) - 4.sys.stdout.write("string")
- 输出,打印时不换行,print()内部使用的它
sys.stdout.write("你好") sys.stdout.write("呀") # 你好呀
- 1.sys.argv
-
3.2 time
- 1.时间分类
- UTC/GMT:世界时间
- 本地时间:本地时区的时间
- 2.time.sleep(t)
- sleep函数接收一个参数,即暂停的时间(以秒为单位),让程序睡眠t秒
- 转义字符\r,使光标回到行首
print('123123\r', end="") print("你好", end="") # 生成进度条的代码 import time for i in range(1, 100): msg = "%s%%\r" %i print(msg, end='') time.sleep(0.05) - 3.time.time()
- 时间戳,返回自1970年1月1日00:00:00 UTC以来经过的秒数,通常以浮点数形式表示
import time time.time() # 1738580513.86146 - 4.time.timezone
- 获取当前时区和0时区相差的秒数
time.timezone # -28800 8 * 3600
- 1.时间分类
-
3.3 datetime
- 1.datetime.now()
- 获取当前本地时间
import time form datetime import datetime, timezone, timedelta #获取datetime格式时间 from datetime import datetime, timezone, timedelta val = datetime.now() print(val) # 2025-02-03 19:15:39.761784 - 2.datetime.utcnow()
- 获取当前utc时间
v = datetime.utcnow() print(v) # 2025-02-01 08:20:18.812692 - 3.timezone(timedelta(param))
- 获取某时区时间
tz = timezone(timedelta(hours=7)) # 正数表示东某区 负数表示西某区 v2 = datetime.now(tz) # 获取东七区的时间,编程中用的很少 print(v2, type(v2)) # 2025-02-03 18:20:51.130646+07:00 <class 'datetime.datetime'> - 4.datetime.now().strftime(param)
- 将datetime格式转换成字符串
v1 = datetime.now() print(v1, type(v1)) val = v1.strftime("%Y-%m-%d %H:%M:%S") print(val) # 2025-02-03 19:23:36.337796 <class 'datetime.datetime'> # 2025-02-03 19:23:36 - 5.datetime.strptime(date_string, format)
- 把字符串转换成datetime格式
v1 = datetime.strptime('2011-11-11', '%Y-%m-%d') print(v1, type(v1)) # 2011-11-11 00:00:00 <class 'datetime.datetime'> - 6.timedelta(param)
- datetime时间的加减
v1 = datetime.strptime('2024-12-23', '%Y-%m-%d') v2 = v1 + timedelta(days=40) print(v2) # 2025-02-01 00:00:00 - 7.datetime.fromtimestamp(时间戳)
- 将时间戳转为datetime类型
ctime = time.time() print(ctime) v1 = datetime.fromtimestamp(ctime) print(v1) # 1738582694.75777 # 2025-02-03 19:38:14.757770 - 8.datetime.timestamp()
- 将datetime类型转为时间戳类型
v1 = datetime.now() val = v1.timestamp() print(val) # 1738582824.594569
- 1.datetime.now()
-
3.4 os:与操作系统相关的数据
- 1.os.path.exists(path)
- 如果path存在,则返回True;否则返回False
- 2.os.stat(file_path).st_size
- 获取文件大小
- 3.os.path.abspath(path)
- 获取一个文件的绝对路径
import os path = './file/river.jpg' v1 = os.path.abspath(path) print(v1) # /Users/zhujialing/Desktop/code/python/file/river.jpg - 4.os.path.dirname(path)
- 获取路径的上级目录
# r用于原生显示,即不将转义字符进行转义,保持它们本来的含义 v = r'/Users/zhujialing/Desktop/code/python/file/river.jpg ' print(os.path.dirname(v)) # /Users/zhujialing/Desktop/code/python/file v = r'/Users/zhujialing/Desktop/code/python/python开发21天入门/file' print(os.path.dirname(v)) # /Users/zhujialing/Desktop/code/python/python开发21天入门 v = r'/Users/zhujialing/Desktop/code/python/python开发21天入门/file/' print(os.path.dirname(v)) # /Users/zhujialing/Desktop/code/python/python开发21天入门/file v = 'al\nex' # 默认将\n当换行 print(v) v = 'al\\nex' print(v) v = r'al\nex' # 推荐使用带r的方式 print(v) - 5.os.path.join(param1, param2, param3, ...)
- 路径拼接
path = "D:/code/s21day14" v = 'n.txt' print(os.path.join(path, v)) # D:/code/s21day14/n.txt 自动加上了“/” windows系统下是“\” - 6.os.listditr(path)
- 查看一个目录下所有的文件【第一层】
import os result = os.listdir(r"/Users/zhujialing/Desktop/code/C") for path in result: print(path)![]()
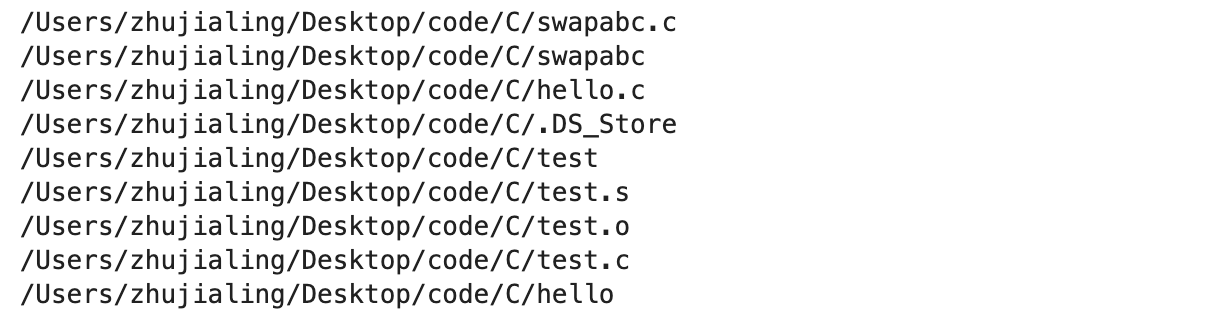
- 7.os.walk(path)
- 查看当前目录下所有的文件(含目录)【所有层】
result = os.walk(r'/Users/zhujialing/Desktop/code/C') print(result) # <generator object walk at 0x1501ed8b0> 结果返回一个生成器 for a, b, c in result: # a是正在查看的目录 b是此目录下的文件夹 c是此目录下的文件 print(a, '---->', b, '---->', c)![]()
# 练习1:打印当前目录下所有文件的绝对路径 import os result = os.walk(r'/Users/zhujialing/Desktop/code/C') for a, b, c in result: for item in c: path = os.path.join(a, item) print(path) break # 遍历完第1组a,b,c后接着强行退出,否则会输出后续子文件的路径![]()
# 练习2:文件读取进度条 import os import time # 1.读取文件的大小(字节) file_size = os.stat('./file/zhangsan.jpg').st_size #print(file_size) # 2.一点一点地读取文件 read_size = 0 with open('./file/zhangsan.jpg', mode='rb') as f1: while read_size < file_size: chunk = f1.read(1000) # 读取固定大小的内容,每次最多读取1000B read_size += len(chunk) val = int(read_size / file_size * 100) print("%s%%\r" %val, end="") time.sleep(0.01) # 睡眠0.01秒
- 1.os.path.exists(path)
-
3.5 shutil
-
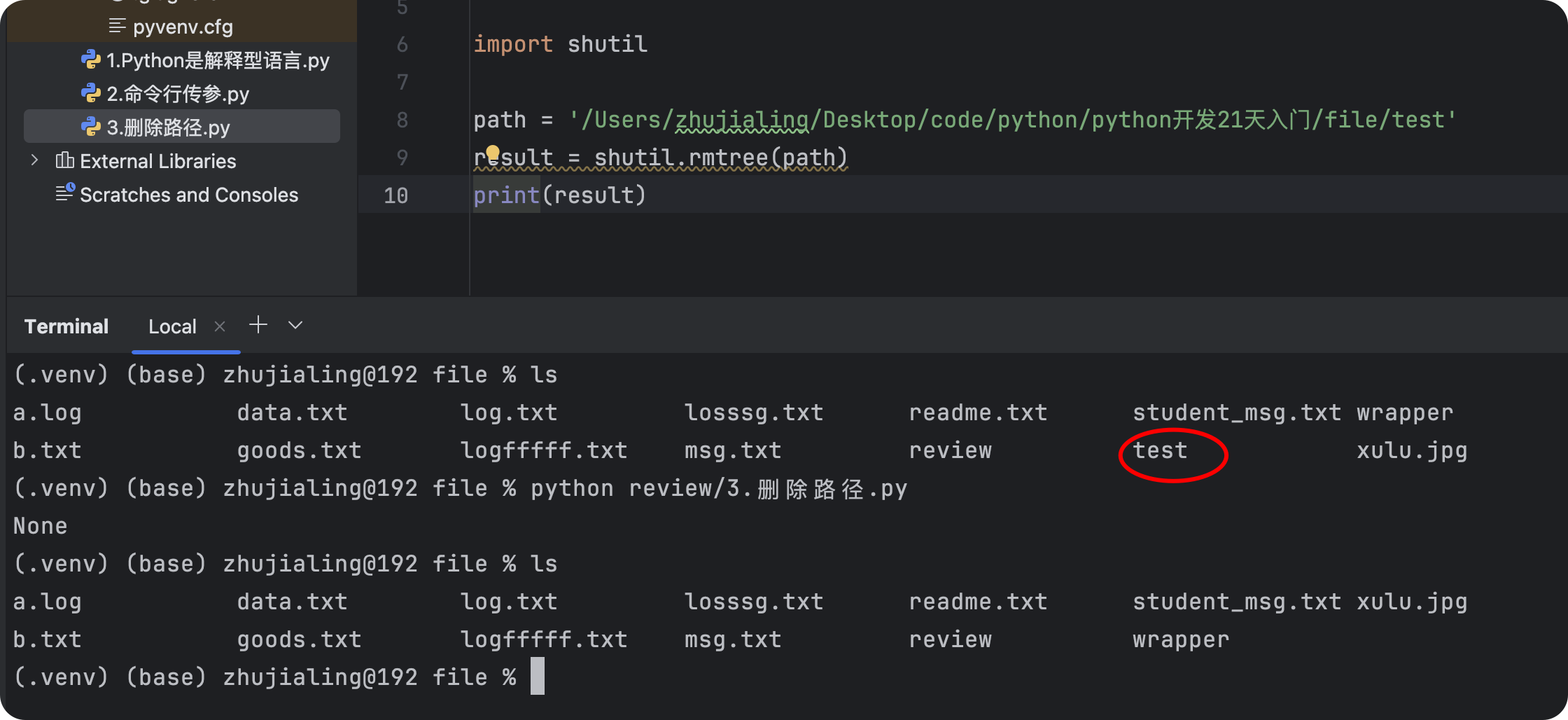
shutil.rmtree(path)
- 删除路径
![]()
-
shutil.move('./file/b.txt', './file/a.txt')
- 重命名,文件或路径均可
-
shutil.make_archive('zzh', 'zip', './file/bb')
- 压缩file下bb中的目录,在当前目录下生成zzh.zip
- '/Users/zhujialing/Desktop/code/python/python开发21天入门/zzh.zip'
- './file/bb'与'./file/bb/'的效果一致,都是将bb目录下的所有文件和目录压缩成zzh.zip
-
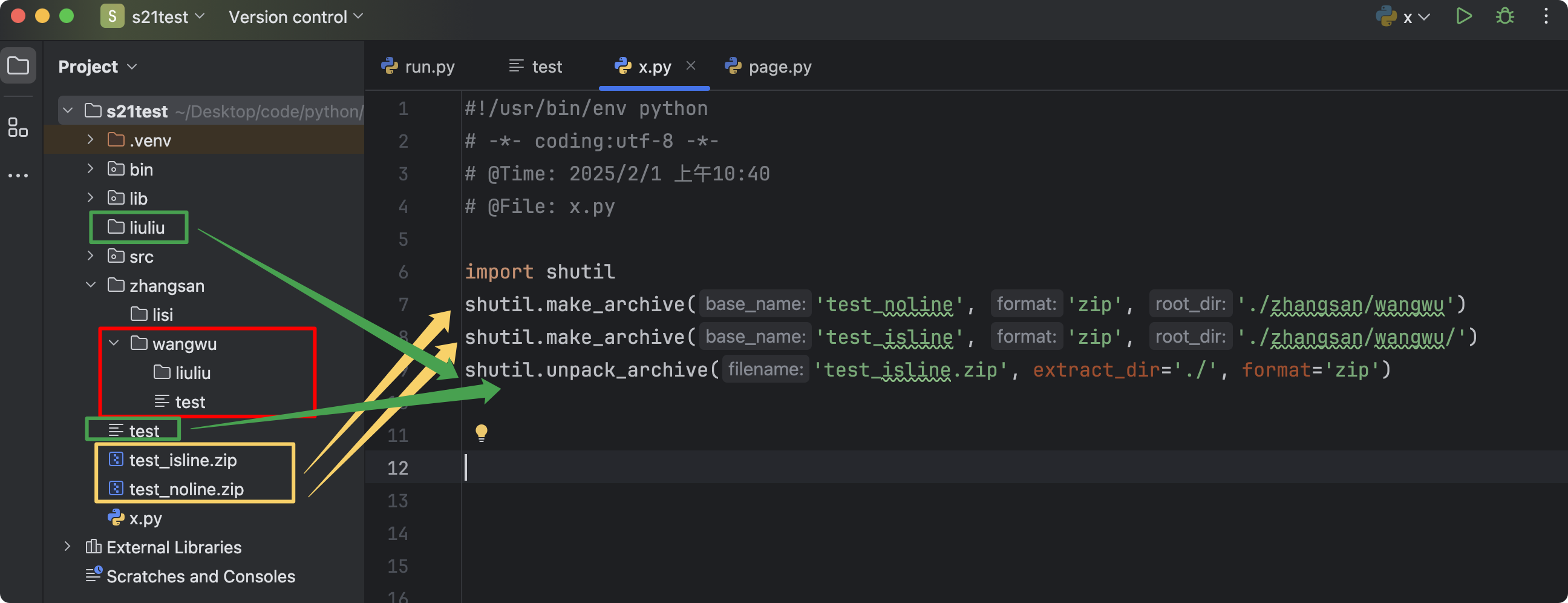
shutil.unpack_archive('zzh.zip', format='zip')
- 将zzh.zip中的文件(包含目录和普通文件)解压到当前目录
- 注意:直接把压缩文件的内容解压到指定路径下,而不是生成目录zzh内部包含着文件,好比“解压到当前目录”和“解压到dir_name文件夹”的区别
![]()
![]()
-
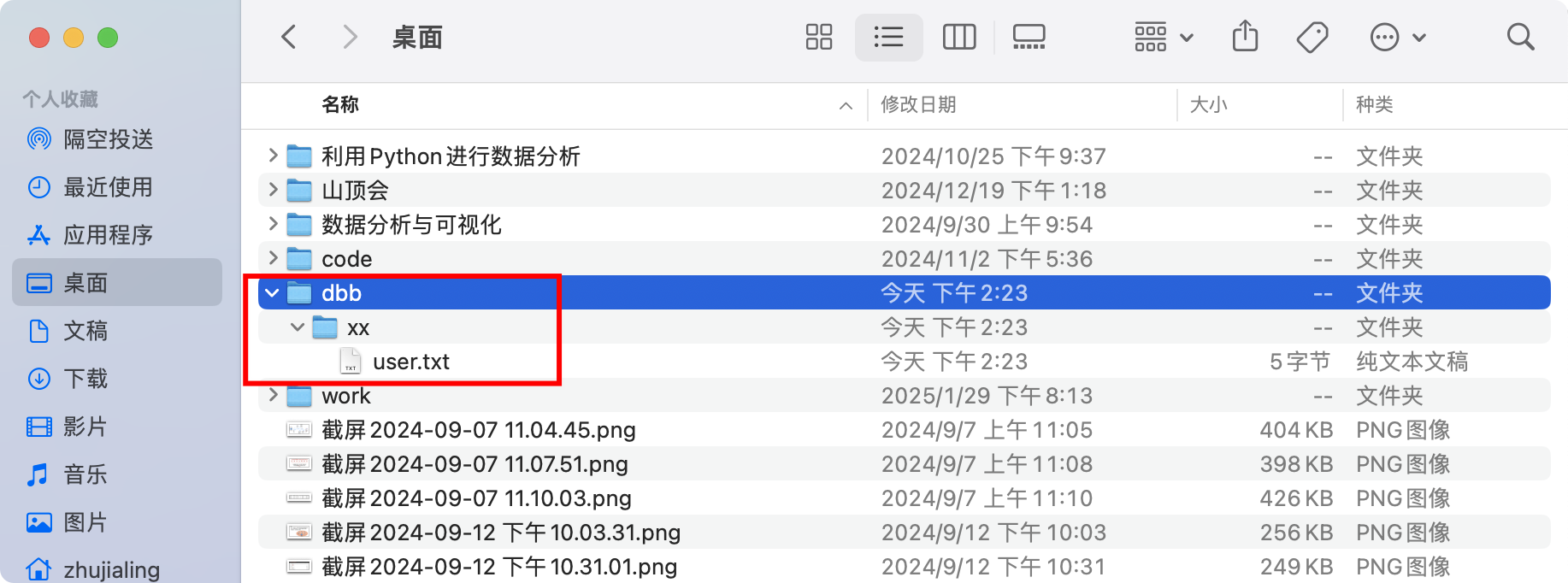
shutil.unpack_archive('zzh.zip', extract_dir='/Users/zhujialing/Desktop/', format='zip')
- extract_dir如果是递归的,没目录会自动创建
![]()
![]()
-
练习题
- 1.将“d21day16”项目下的包“lizhongwei”进行压缩,压缩包放到当前目录下的“code”目录中,以当前时间命名(年-月-日-时:分:秒),后缀为“zip”
- 2.code目录不一定存在
- 3.将压缩包解压到“/Users/zhujialing/Desktop”目录下
import os import shutil from datetime import datetime ctime = datetime.now().strftime('%Y-%m-%d-%H:%M:%S') if not os.path.exists('./code'): os.makedirs('./code') shutil.make_archive(os.path.join('code', ctime), 'zip', './lizhongwei') file_path = os.path.join('./code', ctime) + '.zip' shutil.unpack_archive(file_path, extract_dir='/Users/zhujialing/Desktop', format='zip') -




 浙公网安备 33010602011771号
浙公网安备 33010602011771号