Python基础1——变量 输入 字符串 编码
0.关于python2和python3的区别
-
1.解释器默认的编码方式不同
- python2:ASCII编码
- python3:UTF-8编码
-
2.输入函数名不同
- python2:name = raw_input('请输入姓名')
- python3: name = input('请输入姓名')
-
3.输出的语法不同
- python2:print ""
- python3:print()
-
4.对整型数的处理不同
- python2
- 32bit机器上的整型占32bit,64bit机器上的整型占64bit,超出长度后会转换为long型
- 9/2 = 4,整型除法只能保留整数位
- 导入
from __future__ import division上述结果变成4.5
- python3
- 所有整型都用int,没有long
- 9/2 = 4.5,整型除法保留所有
- python2
-
5.range()方法
- python2
- xrange(num) 不会在内存中立即创建,而是在循环时边循环边创建,能节省内存
- range(num) 在内存中立即生成所有的元素,消耗一定内存=
- python3
- range(num) 类似python2中的xrange(num),节省内存
- list(range(num))
- python2
-
6.定义模块
- python2:文件中必须有__init__.py
- python3:不需要__init__.py
-
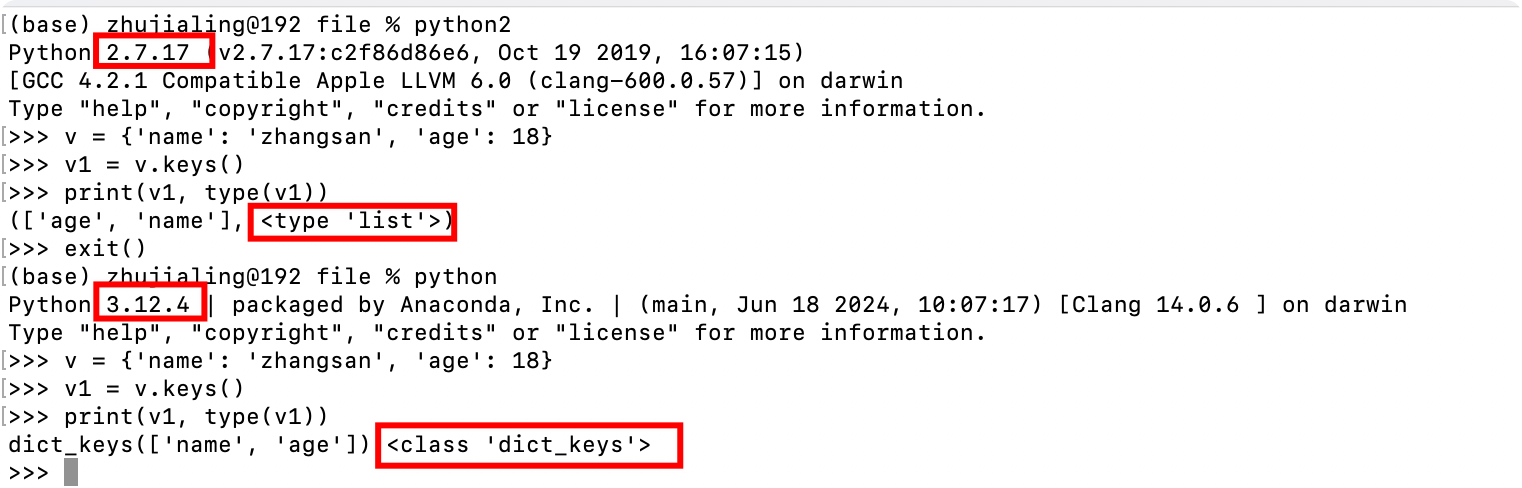
7.字典的键、值、键值对方法
- keys() values() items()
- python2:列表
- python3:迭代器 可以循环但不可以索引取值
![]()
- keys() values() items()
-
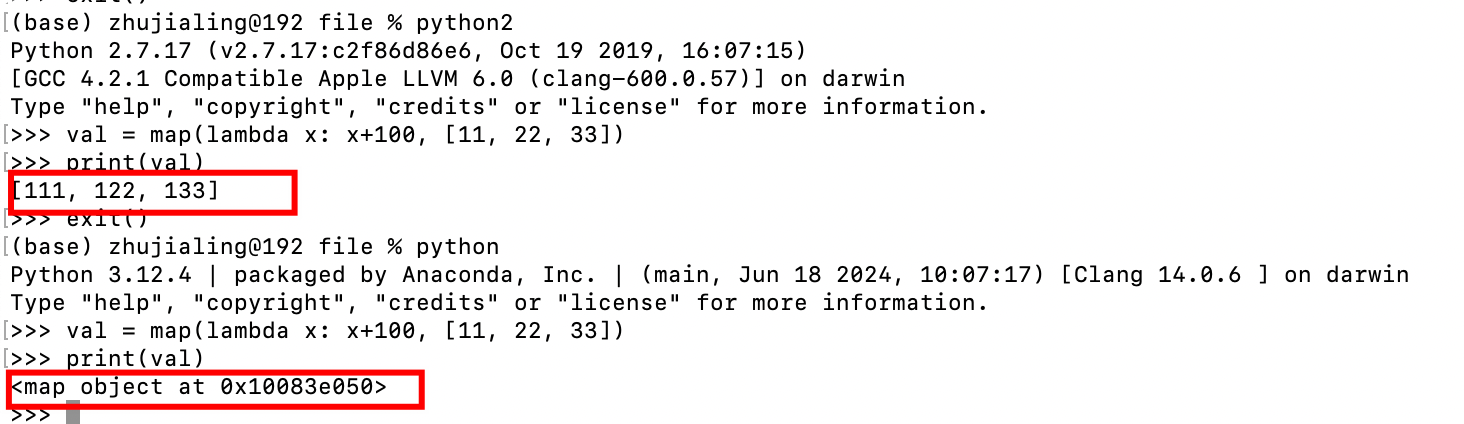
8.map/filter
- val = map(lambda x:x+100, [11, 22, 33])
- py2:返回列表
- py3:不直接生成列表,而是返回一个迭代器,可以循环但不可以索引,可强制list(val)转换后使用索引
![]()
-
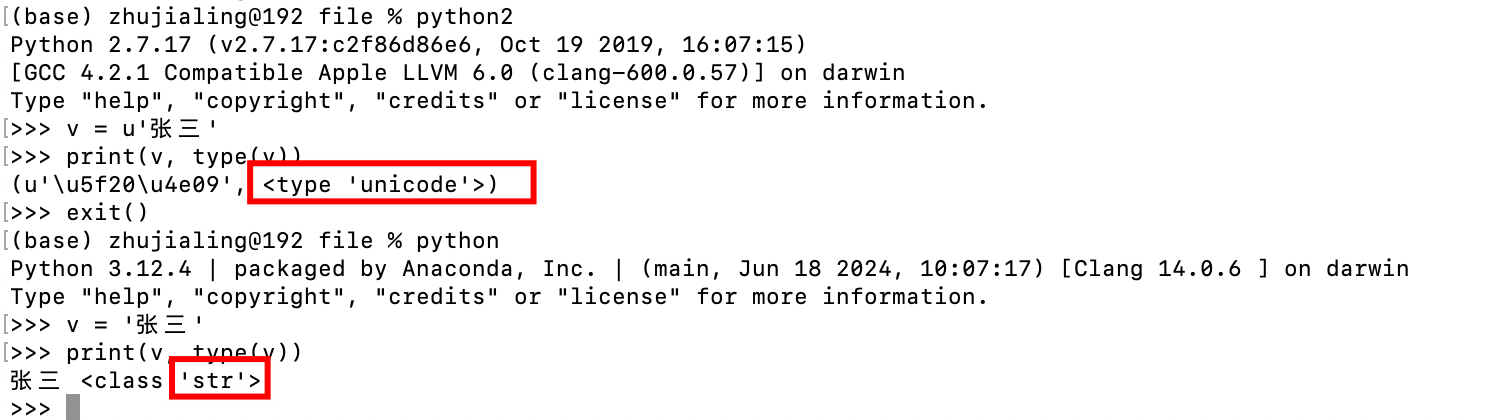
9.字符串类型不同
- python3:str bytes
- python2:unicode str
- python3中的str、bytes分别与python2中的Unicode、str对应
![]()
-
补充:解释器与编译器
- 编译型(C C++ Java C# Go):代码写完后,编译器将其变成另外一个文件,然后交给计算机执行
- 解释型(python php ruby javascript perl):写完代码交给解释器,解释器会从上到下一行行代码执行:边解释边执行
- 编译型语言和解释型语言的区别类似于全文翻译VS实时翻译
- 有时候运行软件会提示“xxx.dll文件缺失”,该文件就是编译后的结果。
- 出现错误时
- python代码要运行到某一句才知道错误(边解释边执行),所以错误之前的print可以正常输出
- C语言代码必须通过编译才能知道错误,如果有错误,错误前方的语句中即使前方有printf也无法输出
1.变量与常量
- 一个数据值(字符串、整数、列表等)在程序中可能被使用多次,为方便表示,可以为它起一个“别名”,叫做变量。
- “别名”不是随便取的,变量名有两个要求
- 变量名只能包含字母、数字、下划线
- 数字不能开头且不能是python的关键字(皇帝名字中的字别人不能带)
- 常量是不允许修改的值,Python中没有真正意义上的常量,只是执行了一种约定
2.数据输入
- input输入得到的内容永远是字符串,如果要进行数据运算记得强制类型转换
a = int(input("输入一个整数:"))
print(a+3)
3.注释
"""
在这里写多行注释 使用一对三引号
"""
# 在这里写单行注释
4.引号
- 1.单引号
print('hello')
print('床前明月光,\n疑是地上霜')
- 2.双引号
print("hello")
- 3.三引号
print('''床前明月光,
疑是地上霜''')
print("""床前明月光,
疑是地上霜""")
5.字符串:本身不能修改或删除【不可变类型】
- 5.1格式化
- 1.%s
name = input('姓名:') do = input('在干什么:') template = "%s在教室, %s."%(name, do,) template2 = "我是%s, 年龄%s, 职业%s."%("tom", "20", "吃饭",)- 2.%d
template = "我是%s, 年龄%d, 职业%s."%("tom", 20, "吃饭",)- 3.%%
name = 'tom' template = "%s现在手机的电量是100%%"%(name,) - 5.2常用方法
- 1.特有方法
- upper() 将所有英文字母转为大写,有返回值
- lower() 将所有英文字母转为小写,有返回值
- isdigit() 判断字符是否是数字,有返回值
- strip() 移除字符串头尾指定的字符 (默认为空白符,也可以是换行符、制表符有),返回值
- lstrip() 移除字符串左侧开头的特定字符(可以是换行符、制表符),有返回值
- rstrip() 移除字符串右侧开头的特定字符(可以是换行符、制表符),有返回值
- replace("被替换的字符/子序列", "要替换为的内容") 全部替换,有返回值
- replace("被替换的字符/子序列", "要替换为的内容", 1) 只替换找到的第一个,有返回值
- split("进行分割的基准字符") 将字符串按照基准字符进行分割,结果返回一个列表
- split("进行分割的基准字符", 1) 1表示从找到的第1个目标字符处开始分割,结果返回一个列表,2个元素
- rsplit("进行分割的基准字符") 表示从右边开始分割,结果返回一个列表
- rsplit("进行分割的基准字符", 1) 表示从右边找到的第1个目标字符开始分割,结果返回一个列表,2个元素
data = "吴用|root|wuyong@qq.com|hi" v2 = data.split("|", 2) print(v2) # ['吴用', 'root', 'wuyong@qq.com|hi'] 从右边找到的第2个"|"开始分割,列表中3个元素 file_path = "/Library/Frameworks/code.cc/python/movie.mp4" ret = file_path.rsplit(".", 1) print(ret) # ['/Library/Frameworks/code.cc/python/movie', 'mp4']- startswith("字符串") 判断是否以指定字符串开头,返回布尔值
- endswith("字符串") 判断是否以指定字符串结尾,返回布尔值
- format() 格式化字符串
name = '我叫{0}, 年龄:{1}'.format('张三', 20)- encode('utf-8') 将字符串使用utf-8进行编码,可用来证明各种编码下单个汉字占据的字节数量
name = '张三' v1 = name.encode('utf-8') v2 = name.encode('gbk') print(v1, v2) # 证明了utf-8编码一个汉字用3B,而gbk编码一个汉字用2B- join() 循环每个元素,并在元素和元素之间加入连接符,不用写if,尤其要注意只用于字符串,不能用于列表等其他类型
name = 'lisi' result = "**".join(name)- zfill() 填充0,常用于将二进制填充为8bit
# 应用场景:处理二进制数据 data = "101" # "00000101" v1 = data.zfill(8) print(v1) # "00000101" - 2.公共方法
- 切片
- v[1:5]
- 索引
- 索引取值下标从0开始
- v = "oldboy" v1 = v[0] 下标非负表示从前往后取 v2 = v[-1] 下标为负数表示从后往前取
- len() 计算字符串的长度
- 步长
- v[1:7:2] 第三个参数为步长
- for循环
- range(0, 10)
- 生成一个数字列表 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
- 成员运算 in
- 切片
- 1.特有方法
6.浮点型(float)
- 1.在类型转换时需要,在浮点型转换为整型时,会将小数部分去掉。
v1 = 3.14
data = int(v1)
print(data) # 3
- 2.通过round函数保留小数点后N位
v1 = 3.1415926
result = round(v1,3)
print(result) # 3.142
- 3.浮点型的坑【所有语言中】
![]()
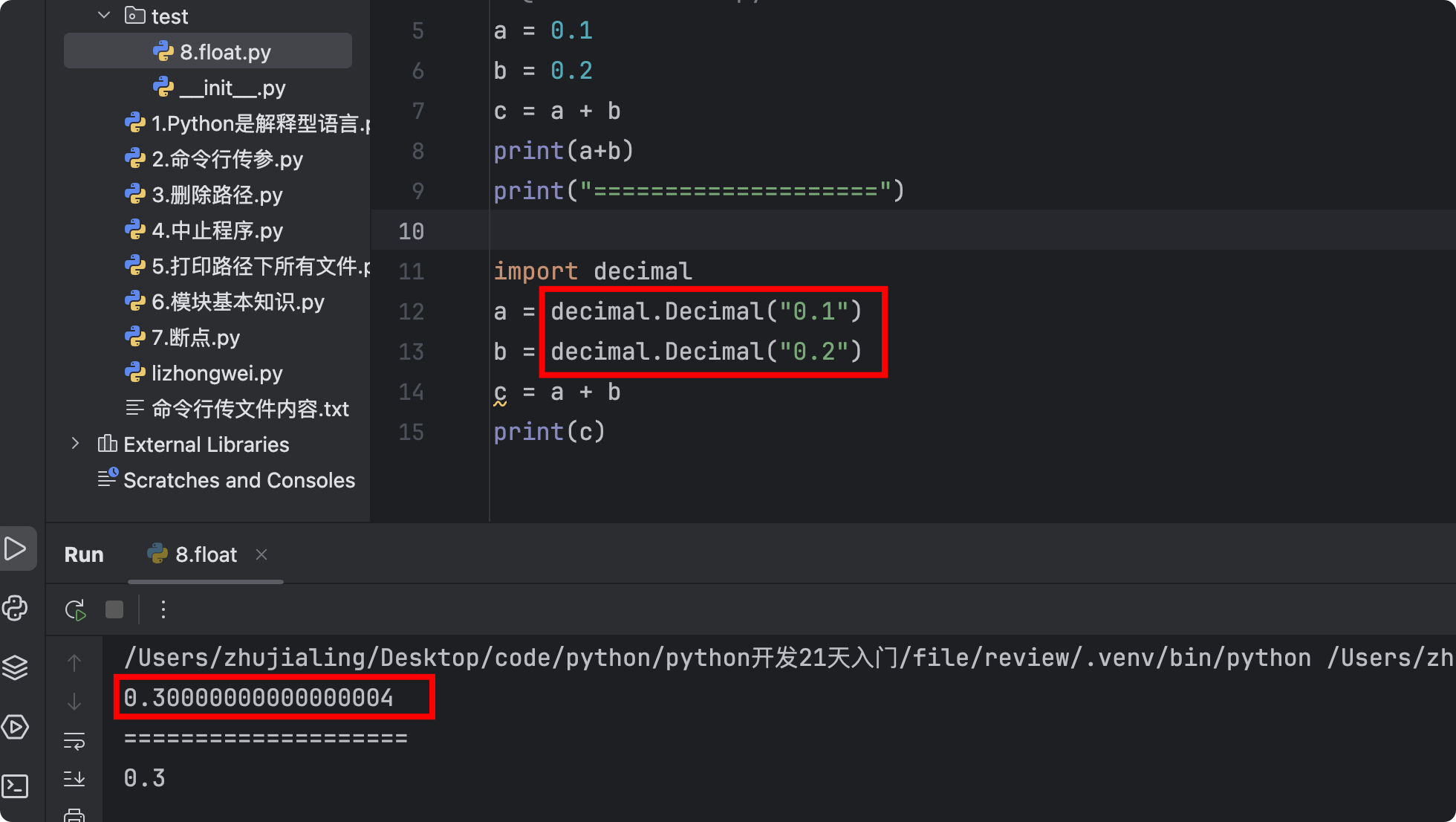
# 项目中如果遇到精确的小数计算可以用decimal库
import decimal
v1 = decimal.Decimal("0.1") # 以字符串的类型传入
v2 = decimal.Decimal("0.2")
v3 = v1 + v2
print(v3) # 0.3
7.数据类型转换
v2 = str(v1) # 数字转字符串
v2 = int(v1) # 字符串转数字
v2 = bool(v1) # 数字转bool值
v1 = 'alex' v2 = bool(v1) # 字符串转布尔值
v1 = True v2 = int(v1) # 布尔值转换其他
- 1."" 0 转换bool之后是False
- 2.or和and的短路特性
- x or y: if x is False, then y, else x
- 第一个值转换成布尔值如果是真 则value=第一个值
- 第一个值转换成布尔值如果是假 则value=第二个值
- 如果有多个or条件 则从左到右依次进行上述流程
- x and y: if x is False then x; else y
- 第一个值转换成布尔值如果是真 则value=第二个值
- 第一个值转换成布尔值如果是假 则value=第一个值
- 如果有多个and条件 则从左到右依次执行上述流程
- not x
- if x is False, then True, else False
- x or y: if x is False, then y, else x
8.编码
- 1.ascii
- 美国标准信息交换吗
- 共128个字符,范围为0~127
- 2.unicode
- 也称万国码
- ucs2 通过2B来表示的unicode
- ucs4 通过4B来表示的unicode
- 3.utf-8
- UTF-8通常用于网络传输和硬盘数据存储
- 表示中文字符时用3B代表一个汉字
- 公司中爬虫等涉及编码的统一采用utf-8
- 4.utf-16
- windows电脑另存文件时的unicode选项实际上不是unicode,而是utf-16
- 5.gbk
- 亚洲国家用,包含21886个中文汉字和图形符号
- 表示中文用2B
- 6.gb2312
- 亚洲国家用,包含6763个中文汉字
- 表示中文用2B
- 7.单位
- 某编码中字符占据多少字节
- 1024B = 1KB
- K M G T E Z Y N D
- 硬盘存储的大小本质上在于存多少个01代码
- 8.补充
- 以什么编码存储就要以什么编码打开,建议Pycharm设置成UTF-8编码
- 在Python中,字符串的默认字符编码通常是Unicode(也称为UTF-16或UTF-32,取决于Python的内部实现细节)。Python 3.x 系列默认使用Unicode字符串,这意味着在Python 3中,所有的字符串都是Unicode字符串。
- 在Python 3中,当创建一个字符串字面量(例如 "Hello, world!"),Python会将其视为Unicode字符串。这意味着可以存储任何Unicode字符,包括那些在ASCII中不存在的字符(例如,中文、阿拉伯文字等)。
s = "你好,世界!" print(s) - 在Python 2.x中,默认的字符串类型是字节串(byte strings),而不是Unicode字符串。如果想要创建一个Unicode字符串,你需要使用前缀u或者使用unicode()函数。但在Python 2.x中,即使是加了u前缀的字符串,在Python内部仍然是以UTF-8或其他编码形式存储的Unicode对象。
s = u"你好,世界!" print(s) s = unicode("你好,世界!", "utf-8") print(s) - 从Python 3开始,推荐的做法是直接使用字符串字面量,因为它们默认就是Unicode。如果想明确指明一个字符串用UTF-8或其他编码解码,可使用encode()和decode()方法
# 将Unicode字符串编码为UTF-8字节串 s_encoded = s.encode('utf-8') print(s_encoded) # 将UTF-8字节串解码回Unicode字符串 s_decoded = s_encoded.decode('utf-8') print(s_decoded) - 综上,在Python 3中,默认的字符串类型是Unicode字符串。如果需要处理字节数据(例如读取或写入文件时),应该使用.encode()和.decode()方法来转换字节和字符串。在Python 2中需要更明确地区分和处理Unicode和字节串。在两种情况下,都可以指定使用特定的字符编码(如UTF-8)进行转换。
v = 'alex' # unicode编码存储在内存,因为Python3中所有字符串都是unicode编码 v = 'alex'.encode('utf-8') # 将字符串转换成字节(由unicode编码转换为utf-8编码) v = 'alex'.encode('gbk') # 将字符串转换成字节(由unicode编码转换为gbk编码)
9.案例
- 1.请通过循环打印 1 2 3 4 5 6 8 9 10
count = 1
while count <= 10:
if count != 7:
print(count)
count = count + 1
count = 1
while count <= 10:
if count == 7:
count = count + 1
continue
print(count)
count = count + 1
- 2.while...else结构
count = 1
while count < 10:
print(count)
count = count + 1
else: # 不再满足while后的条件时触发 或条件=False break强行跳出while循环时不执行else代码块
print('ELSE代码块')
print('结束')
count = 1
while True:
print(count)
if count == 10:
break
count = count + 1
else: # 不执行 因为while是强制退出 条件依然为True
print('ELSE代码块')
print('结束')
- 3.验证码检测
check_code = 'iyUF'
code = input('请输入验证码%s:'%(check_code,))
if code.lower() == check_code.lower():
print('登录成功')
- 4.gitee + gitbash 同步代码
- 4.1 建立仓库。登录Gitee账号,单击主页面右上角“+”新建仓库,输入仓库名称,“归属”选择“xxx组织”,“仓库介绍”写姓名,其余保持默认,单击“创建”。
- 4.2 选择目录。进入D盘存储代码的目录“codes”,右键鼠标——Open Git Bash here调出命令行。
- 4.3 初始化。在本地目录中创建一个新的Git仓库。
指令:git init- 4.4 关联用户。配置用户名和邮箱,因为后续在下载有权限验证的远程仓库代码的时候,需要验证身份,此时git会默认使用配置的用户名或者邮箱进行登录,然后手动输入密码。
指令:git config --global user.name "17862731832" git config --global user.email "1733041816@qq.com"- 4.5 关联仓库。将本地仓库和远程仓库进行关联。
指令:git remote add origin https://gitee.com/code_202206/22222222.git- 4.6 添加索引。将当前工作目录中的文件内容添加到索引(也称为暂存区),以准备进行下一次提交。
指令:git add .- 4.7 设置标记。提交更改并写入提交信息。
指令:git commit -m "homework"- 4.8 同步上传。将本地分支的更改推送到远程仓库的指定分支,此时Git Bash会缓冲一段时间,随后弹出登录的对话框,要求输入用户名和密码。
验证:在Gitee主页上出现了最新的同步信息。指令:git push -u origin master

 浙公网安备 33010602011771号
浙公网安备 33010602011771号