ORB特征提取与匹配
ORB特征是目前最优秀的特征提取与匹配算法之一,下面具体讲解一下:
特征点的检测
图像的特征点可以简单的理解为图像中比较显著显著的点,如轮廓点,较暗区域中的亮点,较亮区域中的暗点等。ORB采用FAST(features from accelerated segment test)算法来检测特征点。这个定义基于特征点周围的图像灰度值,检测候选特征点周围一圈的像素值,如果候选点周围领域内有足够多的像素点与该候选点的灰度值差别够大,则认为该候选点为一个特征点。
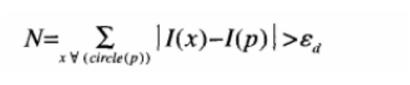
其中I(x)为圆周上任意一点的灰度,I(p)为圆心的灰度,Ed为灰度值差得阈值,如果N大于给定阈值,一般为周围圆圈点的四分之三,则认为p是一个特征点。
为了获得更快的结果,还采用了额外的加速办法。如果测试了候选点周围每隔90度角的4个点,应该至少有3个和候选点的灰度值差足够大,否则则不用再计算其他点,直接认为该候选点不是特征点。候选点周围的圆的选取半径是一个很重要的参数,这里为了简单高效,采用半径为3,共有16个周边像素需要比较。为了提高比较的效率,通常只使用N个周边像素来比较,也就是大家经常说的FAST-N。很多文献推荐FAST-9,作者的主页上有FAST-9、FAST-10、FAST-11、FAST-12,大家使用比较多的是FAST-9和FAST-12。

计算特征描述子
得到特征点后我们需要以某种方式描述这些特征点的属性。这些属性的输出我们称之为该特征点的描述子(Feature DescritorS).ORB采用BRIEF算法来计算一个特征点的描述子。
BRIEF算法的核心思想是在关键点P的周围以一定模式选取N个点对,把这N个点对的比较结果组合起来作为描述子。
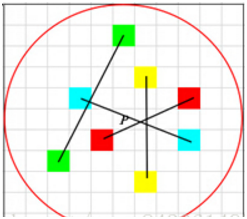
步骤:
1.以关键点P为圆心,以d为半径做圆O。
2.在圆O内某一模式选取N个点对。这里为方便说明,N=4,实际应用中N可以取512.
假设当前选取的4个点对如上图所示分别标记为:
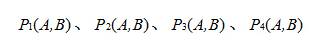
3.定义操作T

4.分别对已选取的点对进行T操作,将得到的结果进行组合。
假如:
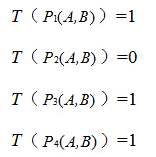
则最终的描述子为:1011
理想的特征点描述子应该具备的属性:
在现实生活中,我们从不同的距离,不同的方向、角度,不同的光照条件下观察一个物体时,物体的大小,形状,明暗都会有所不同。但我们的大脑依然可以判断它是同一件物体。理想的特征描述子应该具备这些性质。即,在大小、方向、明暗不同的图像中,同一特征点应具有足够相似的描述子,称之为描述子的可复现性。
当以某种理想的方式分别计算描述子时,应该得出同样的结果。即描述子应该对光照(亮度)不敏感,具备尺度一致性(大小 ),旋转一致性(角度)等。
ORB并没有解决尺度一致性问题,在OpenCV的ORB实现中采用了图像金字塔来改善这方面的性能。ORB主要解决BRIEF描述子不具备旋转不变性的问题。
回顾一下BRIEF描述子的计算过程:
在当前关键点P周围以一定模式选取N个点对,组合这N个点对的T操作的结果就为最终的描述子。当我们选取点对的时候,是以当前关键点为原点,以水平方向为X轴,以垂直方向为Y轴建立坐标系。当图片发生旋转时,坐标系不变,同样的取点模式取出来的点却不一样,计算得到的描述子也不一样,这是不符合我们要求的。因此我们需要重新建立坐标系,使新的坐标系可以跟随图片的旋转而旋转。这样我们以相同的取点模式取出来的点将具有一致性。
打个比方,我有一个印章,上面刻着一些直线。用这个印章在一张图片上盖一个章子,图片上分处直线2头的点将被取出来。印章不变动的情况下,转动下图片,再盖一个章子,但这次取出来的点对就和之前的不一样。为了使2次取出来的点一样,我需要将章子也旋转同一个角度再盖章。(取点模式可以认为是章子上直线的分布情况)
ORB在计算BRIEF描述子时建立的坐标系是以关键点为圆心,以关键点和取点区域的形心的连线为X轴建立2维坐标系。
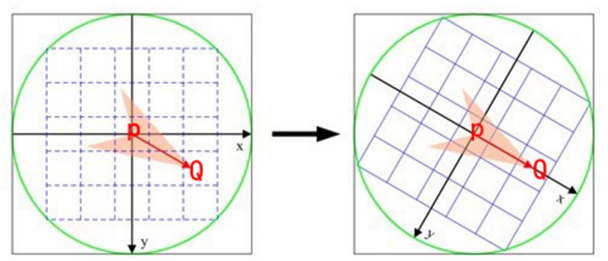
P为关键点。圆内为取点区域,每个小格子代表一个像素。现在我们把这块圆心区域看做一块木板,木板上每个点的质量等于其对应的像素值。根据积分学的知识我们可以求出这个密度不均匀木板的质心Q。计算公式如下。其中R为圆的半径。
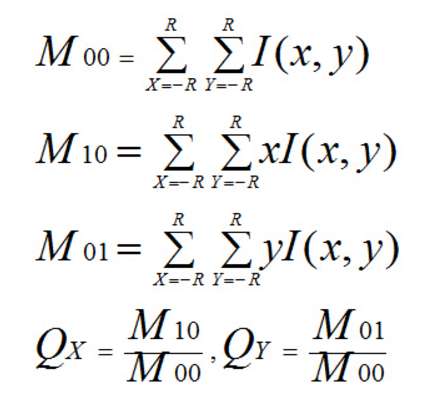
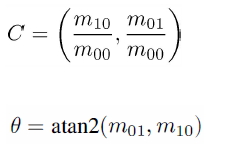
我们知道圆心是固定的而且随着物体的旋转而旋转。当我们以PQ作为坐标轴时,在不同的旋转角度下,我们以同一取点模式取出来的点是一致的。这就解决了旋转一致性的问题。
BRIEF中,采用了9x9的高斯算子进行滤波,可以一定程度上解决噪声敏感问题,但一个滤波显然是不够的。ORB中提出,利用积分图像来解决:在31x31的窗口中,产生一对随机点后,以随机点为中心,取5x5的子窗口,比较两个子窗口内的像素和的大小进行二进制编码,而非仅仅由两个随机点决定二进制编码。(这一步可有积分图像完成)
特征点的匹配
ORB算法最大的特点就是计算速度快 。 这首先得益于使用FAST检测特征点,FAST的检测速度正如它的名字一样是出了名的快。再次是使用BRIEF算法计算描述子,该描述子特有的2进制串的表现形式不仅节约了存储空间,而且大大缩短了匹配的时间。
例如特征点A、B的描述子如下。
A:10101011
B:10101010
我们设定一个阈值,比如80%。当A和B的描述子的相似度大于90%时,我们判断A,B是相同的特征点,即这2个点匹配成功。在这个例子中A,B只有最后一位不同,相似度为87.5%,大于80%。则A和B是匹配的。
我们将A和B进行异或操作就可以轻松计算出A和B的相似度。而异或操作可以借组硬件完成,具有很高的效率,加快了匹配的速度。
汉明距离:
汉明距离是以理查德•卫斯里•汉明的名字命名的。在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。例如:
1011101 与 1001001 之间的汉明距离是 2。
2143896 与 2233796 之间的汉明距离是 3。
"toned" 与 "roses" 之间的汉明距离是 3。
给予两个任何的字码,10001001和10110001,即可决定有多少个相对位是不一样的。在此例中,有三个位不同。要决定有多少个位不同,只需将xor运算加诸于两个字码就可以,并在结果中计算有多个为1的位。例如:
10001001
Xor 10110001
00111000
两个字码中不同位值的数目称为汉明距离(Hamming distance) 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号