


WordCount结对项目
合作者:201631062429,201631062413
队友博客地址:http://www.cnblogs.com/wdqznb/p/9807122.html
代码地址:https://gitee.com/gitdq/WC2.0
本次作业的链接地址:https://edu.cnblogs.com/campus/xnsy/2018Systemanalysisanddesign/homework/2188
一、PSP表格
|
PSP |
PSP阶段 |
预估耗时 (分钟) |
实际耗时 (分钟) |
|
Planning |
计划 |
45 |
30 |
|
Estimate |
估计这个任务需要多少时间 |
20 |
30 |
|
Development |
开发 |
420 |
600 |
|
Analysis |
需求分析 (包括学习新技术) |
90 |
60 |
|
Design Spec |
生成设计文档 |
0 |
0 |
|
Design Review |
设计复审 (和同事审核设计文档) |
30 |
15 |
|
Coding Standard |
代码规范 (为目前的开发制定合适的规范) |
30 |
20 |
|
Design |
具体设计 |
60 |
30 |
|
Coding |
具体编码 |
420 |
480 |
|
Code Review |
代码复审 |
90 |
120 |
|
Test |
测试(自我测试,修改代码,提交修改) |
120 |
120 |
|
Reporting |
报告 |
120 |
90 |
|
Test Report |
测试报告 |
15 |
30 |
|
Size Measurement |
计算工作量 |
30 |
30 |
|
Postmortem & Process Improvement Plan |
事后总结, 并提出过程改进计划 |
30 |
15 |
|
|
合计 |
1520 |
1670 |
二、代码审核及合并
代码风格:阿里巴巴公司 java 规范的官方网站:https://github.com/alibaba/p3c
| 代码自审 | 代码互审 | 代码合并 |
| 检查关键部分代码逻辑是否有问题,跟踪参数的值的变化是否存在问题 | 运行代码,进行基本功能的审查 |
将各自自审稳定的部分进行选择性地功能整合,再对合并后的版本进行共审,确定为将要使用的基础版本 |
| 检查在非法输入时是否有异常抛出 | 测试代码的稳定性,看程序对异常输入或者其他异常操作能否抛出异常或做相应处理 |
三、设计过程
(1)、结构设计
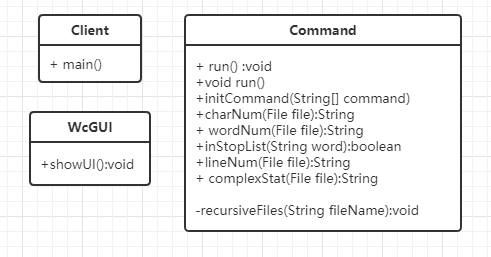
1.类:
a.Client 客户端
b.Command 命令处理及功能实现
c.WcGUI 界面
2.方法分别为处理命令行参数,对各部分功能实现,读文件函数,以及界面显示等。
如下:
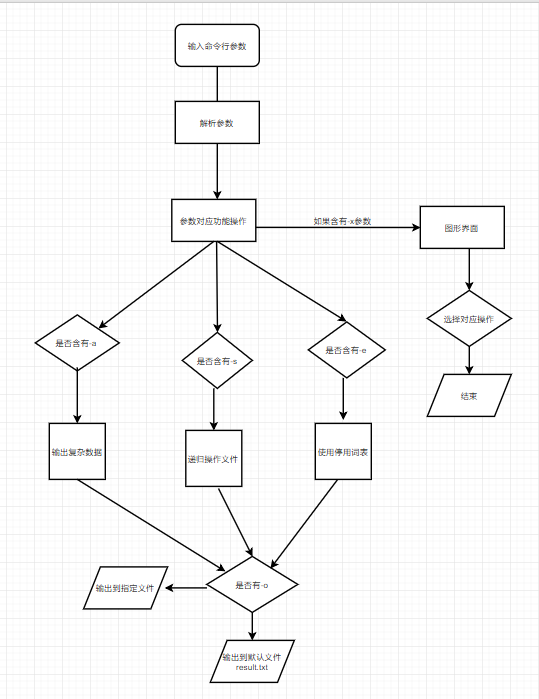
(2)、算法设计流程图
四、代码说明
我负责的部分是扩展功能中的停用词表,返回更复杂的数据的实现。
这里只贴出了关键部分代码,其他功能代码详见gitee。
停用词表
/**
* 计算字符串是否在停用词表的方法
* @param word 需要计算是否在停用词表内的字符串
*/
public boolean inStopList(String word) {
try{
File file = new File(this.stopList);
BufferedReader br=null;
br = new BufferedReader(new FileReader(file));
String temp;
while ((temp=br.readLine())!= null) {
String[] des = temp.split(" |,");
for (String de : des) {
if(!"".equals(de)){
//停用词表内逐个单词与传入参数对比,如果相等,说明当前参数是在停用词表内
if (de.equals(word)){
br.close();
return true;
}
}
}
}
br.close();
}
catch(Exception e){
System.out.println("文件不存在");
}
//如果上面所以单词对比完成都没有触发if条件,则说明不在停用词表内
return false;
}
返回复杂数据
/**
* 代码行/空行/注释行 的计算方法
* @param file 需要计算 代码行/空行/注释行 的文件
*/
public String complexStat(File file) {
//多行注释正则表达式
String regexNodeBegin = "\\s*/\\*.*";
String regexNodeEnd = ".*\\*/\\s*";
//单行注释正则表达式
String regexNode = "\\s*/{2}.*";
//空行正则表达式
String regexSpace = "\\s*";
String str="";
try {
notesNum=0;
spaceNum=0;
codeNum=0;
BufferedReader br=null;
BufferedWriter bw=null;
br = new BufferedReader(new FileReader(file));
String temp;
while ((temp = br.readLine()) != null) {
if (temp.matches(regexNodeBegin)) {
//当前行匹配多行注释行首时执行
do {
notesNum++;
temp = br.readLine();
//直到读取当多行注释行尾前,没读取一行内容说明注释行加一
} while (!temp.matches(regexNodeEnd));
//行尾也算注释行,所以此处再加一
notesNum++;
} else if (temp.matches(regexSpace)) {
//当前行匹配空行时空行行加一
spaceNum++;
} else if (temp.matches(regexNode)) {
//当前行匹配单行注释时注释行加一
notesNum++;
} else{
//如果当前行既不是注释行也不是空行那就是代码行
codeNum++;
}
}
System.out.println(file.getName()+",代码行/空行/注释行:" + codeNum + "/" + spaceNum + "/" + notesNum);
str+=(file.getName()+",代码行/空行/注释行:" + codeNum + "/" + spaceNum + "/" + notesNum+"。\n");
File outFile = new File(this.outFile);
bw = new BufferedWriter(new FileWriter(outFile,true));
bw.write(file.getName()+",代码行/空行/注释行:" + codeNum + "/" + spaceNum + "/" + notesNum+"。\r\n");
bw.close();
br.close();
} catch (Exception e) {
e.printStackTrace();
System.out.println("文件不存在");
}
return str;
}
五、总结
在这次结对编程项目中,有一些出乎意料的地方,也有一些没有达到预期的地方。在项目计划以及需求分析的过程中,我们已经把工作分配好了。但是在实际开发过程中,各种遇到问题对方都会来帮忙解决,所以使得本来应该是独立的代码,最后也变成了一个整体,变成了共同创作出的东西,所以并没有达到预期的情况。但是也正因为在这个过程中,有队友不断地帮助,使我得到了很大提高,学到了很多东西。而且在一开始计划的时候,把一些需要交互的地方沟通好,其实并不会出现“两个人思想不一样,不如我一个人开发快”的情况。所以,经过这个结对项目,我明显感觉到1+1>2。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号