
Hadoop学习笔记(10) ——搭建源码学习环境
Hadoop学习笔记(10)
——搭建源码学习环境
上一章中,我们对整个hadoop的目录及源码目录有了一个初步的了解,接下来计划深入学习一下这头神象作品了。但是看代码用什么,难不成gedit?,单步调试呢? 看程序不能调那多痛苦啊,想看跟踪一下变量,想看一下执行路径都难。
所以这里,我们得把这个调试环境搭建起来。Hadoop的主要代码是用java编写的,所以这里就选用eclipse作为环境。
Hadoop目录下,本身就可以为作eclipse的一个工程来操作,但这里我不想,我想自己来建一个工程,然后把它的代码自己添加进来。
创建一普通的java工程:
点下一步,输入工程名:HadoopSrcStudy,然后再下一步
然后一路下一步,再Finish完成:
接下来,添加源码了,打开hadoop下面的src文件夹,复制哪些呢? 我们先学学核心的吧,core,hdfs,marped这三个目录,复制到工程里面。(如何复制? 先在选中三个文件夹,然后回到eclipse中,选中HadoopSrcStudy工程,然后直接按一下ctrl+v)
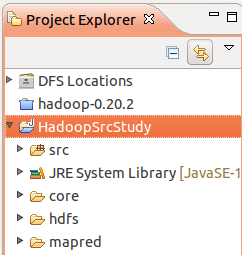
好了,进来了,但现在这三个文件夹还不能当成源码进行编译,所以我们右健工程属性:

然后选中Java Build Path,在右边的tab页选中Source,然后点Add Folder:
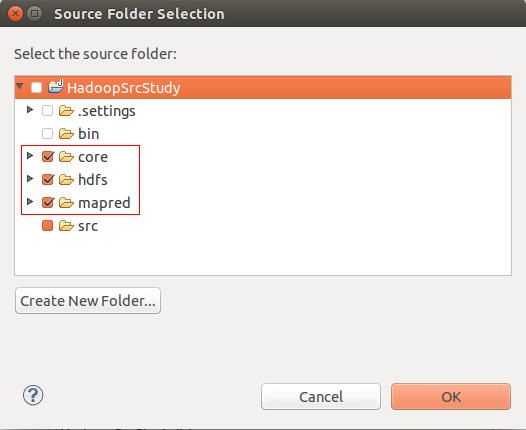
在弹出页面中,选中core、hdfs、mapred三个目录,然后点两次OK,完成设置。
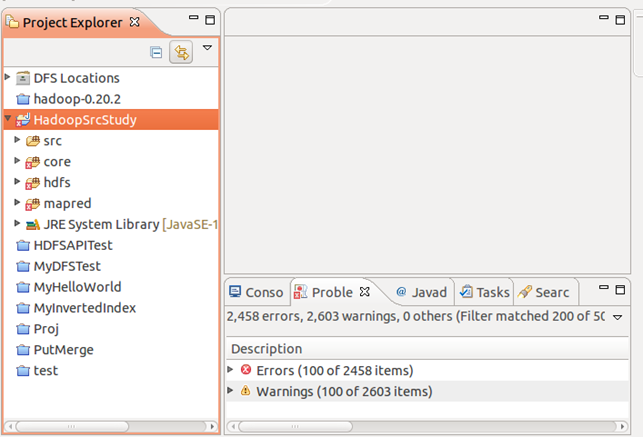
然后再看工程,这三个目录已经跟src文件夹的图标一样了,所以里面的java程序也就当成了源码,进行了编译,但发现2K多个Error。怎么回事?难不成还要引用其他的源码文件? 答案是少jar包。
所以我们先在源码目录下建一个jar的文件夹。然后将以下目录下的jar文件都复制进来。
hadoop-0.20.2/build/ivy/lib/Hadoop/common/*.jar
hadoop-0.20.2/lib/jsp-2.1/*.jar
hadoop-0.20.2/lib/kfs-0.2.2.jar
hadoop-0.20.2/lib/hsqldb-1.8.0.10.jar
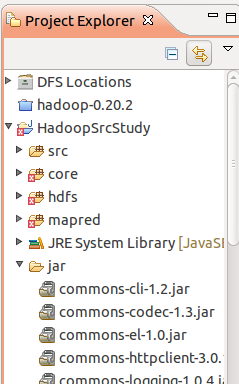
然后右健工程,选属性页,在BuildPath页,选Libraiers:
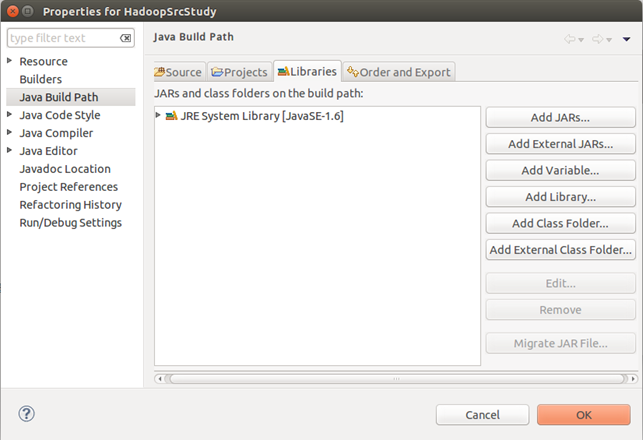
点击Add Jars:
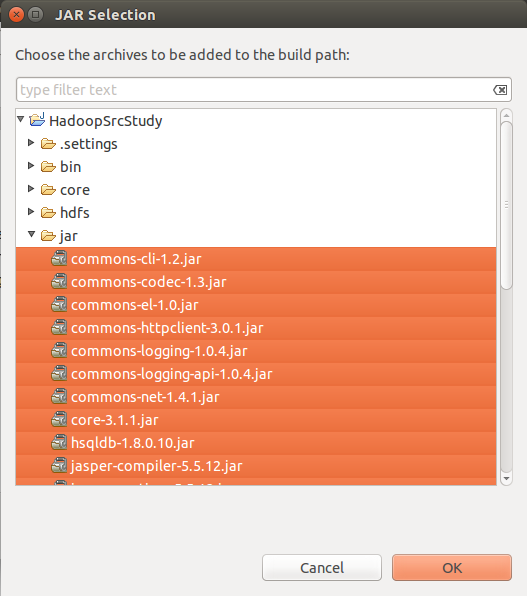
选择jar文件夹下所有的jar文件,然后点两次OK。
这些发现bug立即减少:
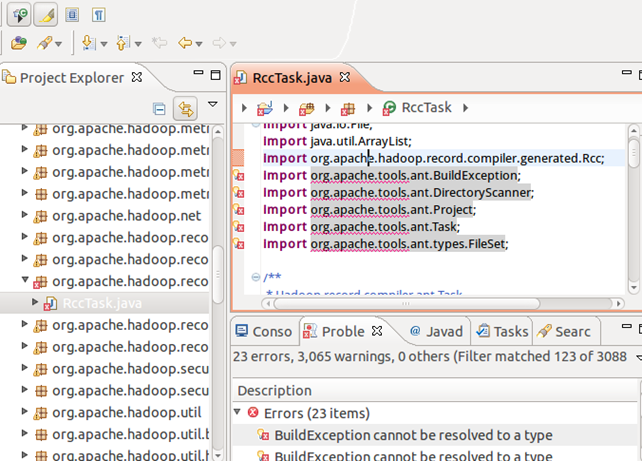
但还是有,而且都只是这个RccTask文件里的,所以暂时先排掉吧,对着该文件右健菜单Build Path->Exclude即可。
好了,此时一个bug也没有了。
然后将hadoop-0.20.2目录下conf文件夹下的core-site.xml、hdfs-site.xml、mapred-site.xml、log4j.properties这几个文件,放在src目录下,
将hadoop-0.20.2目录下src文件夹下的,webapps复制到src目录下。
在eclipse中,src目录下建一个package,名为:org.apache.hadoop,然后将hadoop-0.20.2\build\src\org\apahe\hadoop\package-info.java文件,复制到该package下。目录如下:
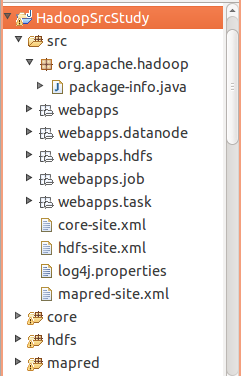
这样源码调试环境就OK了。
让Hadoop在eclipse中运行起来
源码已经加入,并且已经编译通过了,接下来得在eclipse中跑一下,试下是否能正常跑起来。
这里我们尝试,用命令行中执行namenode,然后用eclipse运行datanode,然后再开一个命令行,用fs命令,是否能查到之前的内容。
1.打开命令行,进入hadoop-0.20.2目录,执行bin/hadoop namenode
2.在eclipse中,进入hdfs目录,再进入org.apache.hadoop.hdfs.server.datanode目录,打开DataNode.java文件,然后点上面的运行,然后就可以看到在eclipse中,正常的输出信息,且没有错误。该信息,可以在log文件夹下,找到datanode的日志,其内容是一样的。 同时在前面的命令行窗体中,可以看到namenode程序中收到一个datanode的接入请求。
3.再打开一个命令行窗口,进入hadoop-0.20.2目录bin/hadoop fs –ls,就可以看到输出了文件列表。
4.然后再输入命令bin/hadoop fs -cat out/* 就可以看到之前程序运行生成在out目录下的数据了。
如果上面两个命令都执行成功,说明namenode和在eclipse中运行的datanode都起作用了。可以再观察下,当我们在执行cat命令时,在eclipse中的输出框中,看到有新的响应输出,说明它工作了。
同样,我们还可以反过来,在eclipse中运行namenode,在命令行中运行datanode。同样的效果。
为了可以看到更多的调试日志输出,我们还可以打开src下的log4j.properties文件,在第二行中的INFO改成DEBUG,这样输出的内容会更详细。
到此为止我们的源码学习环境已经搭建好了,可以方便的在eclipse中调试hadoop代码,甚至来修改它。
好了~~至此,第一季收工。 让思维飞一会儿,等后面看了些hadoop源码后,再来分享。 到时还会保持一向的处理方式:从简单入手。 程序分析就会main函数入手。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号