

kettle从入门到精通 第106课 ETL之kettle Cache数据库单表6000万+数据轻松提取
场景:
周四的时候群里一个小伙伴发出求助信息,大概意思是要从Cache(业内医疗同仁都知道东华的医疗系统有使用Cache数据库)单表中抽取数据到sqlserver数据库,该表数据量为6000万+,在使用kettle抽取的过程中总是遇到内存溢出的问题。
群友提供帮助信息:1、增大内存。2、分批处理。不过对于经验不足的小伙伴,上面两个建议有可能无法帮助他解决问题,今天下班刚好有时间连麦了这位小伙伴一起搞demo解决了此问题,
先梳理成章,分享给大家。

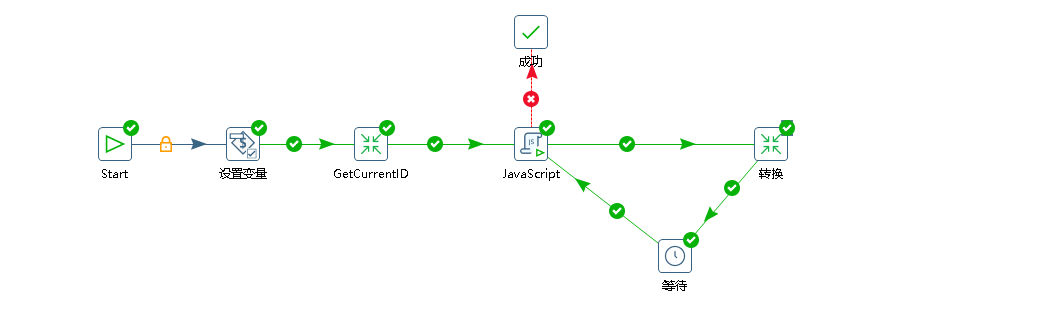
1、原始设计
这位小伙伴最初的设计是这样的(如下图),经沟通了解,他的设计思想是对的:由于该表的id字段为自增id,想通过循环方式分页来提取数据,但是实现方式却没有达到分页效果。
2、重新设计
1)获取大表最大id,假如这里的最大id为10,那么循环的最大id(maxId=10+1)
2)设置每次抽取数据的开始id(beginId,这里假设id从1开始)、结束id(endId)和每次抽取记录条数recordSize(这里假设为3),,单次抽取的区间为[beginId,endId),也就是左闭右开区间
3)根据上述条件计算出所有的抽数区间[1,4),[4,7),[7,10),[10,11)
4)根据第三步计算的抽取区间循环抽数据

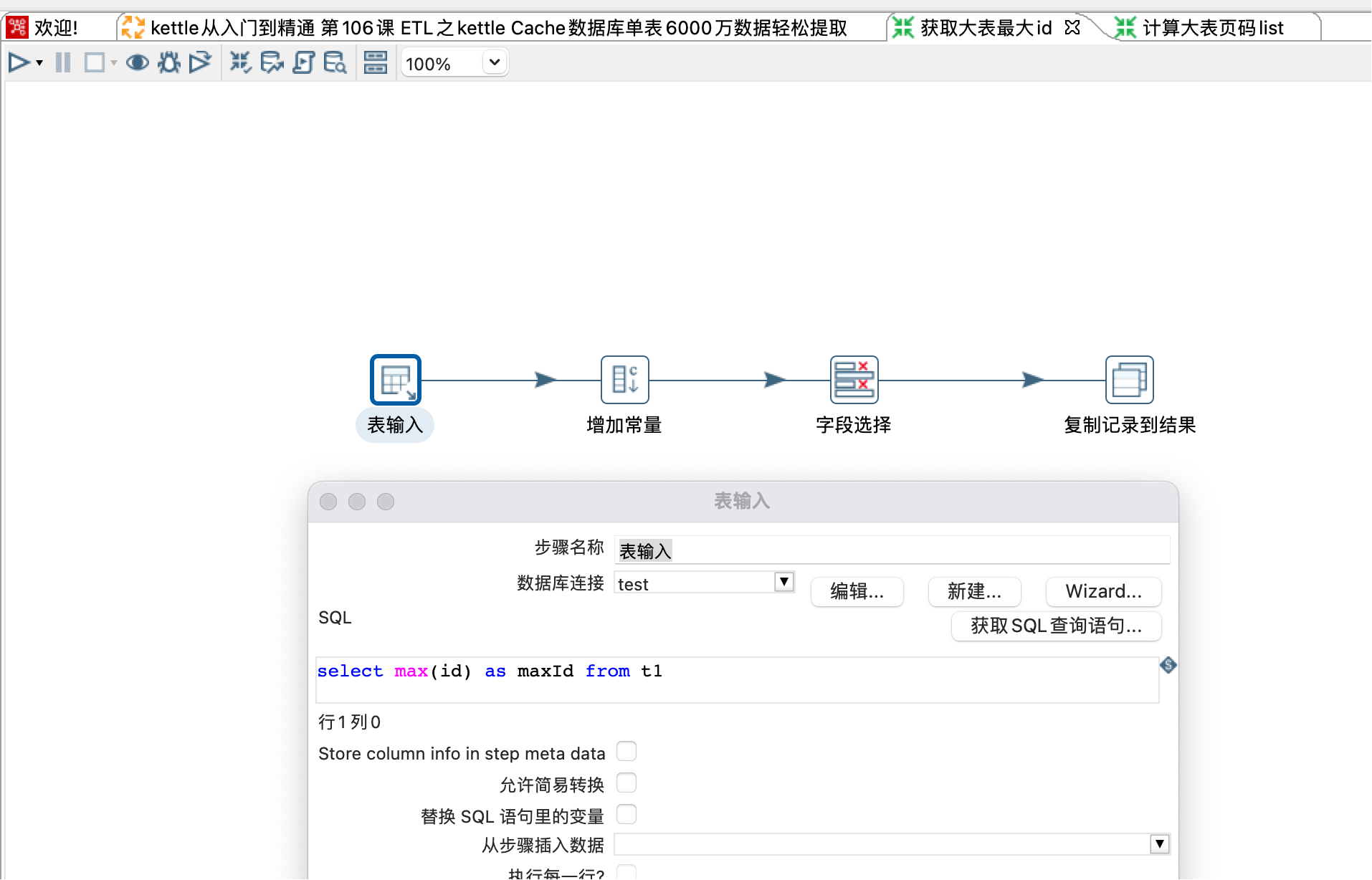
3、子转换:获取大表最大id
由于我本地没有cache数据库,这里我使用mysql数据库进行模拟演示,从t1 表获取最大id(select max(id) as maxId from t1)
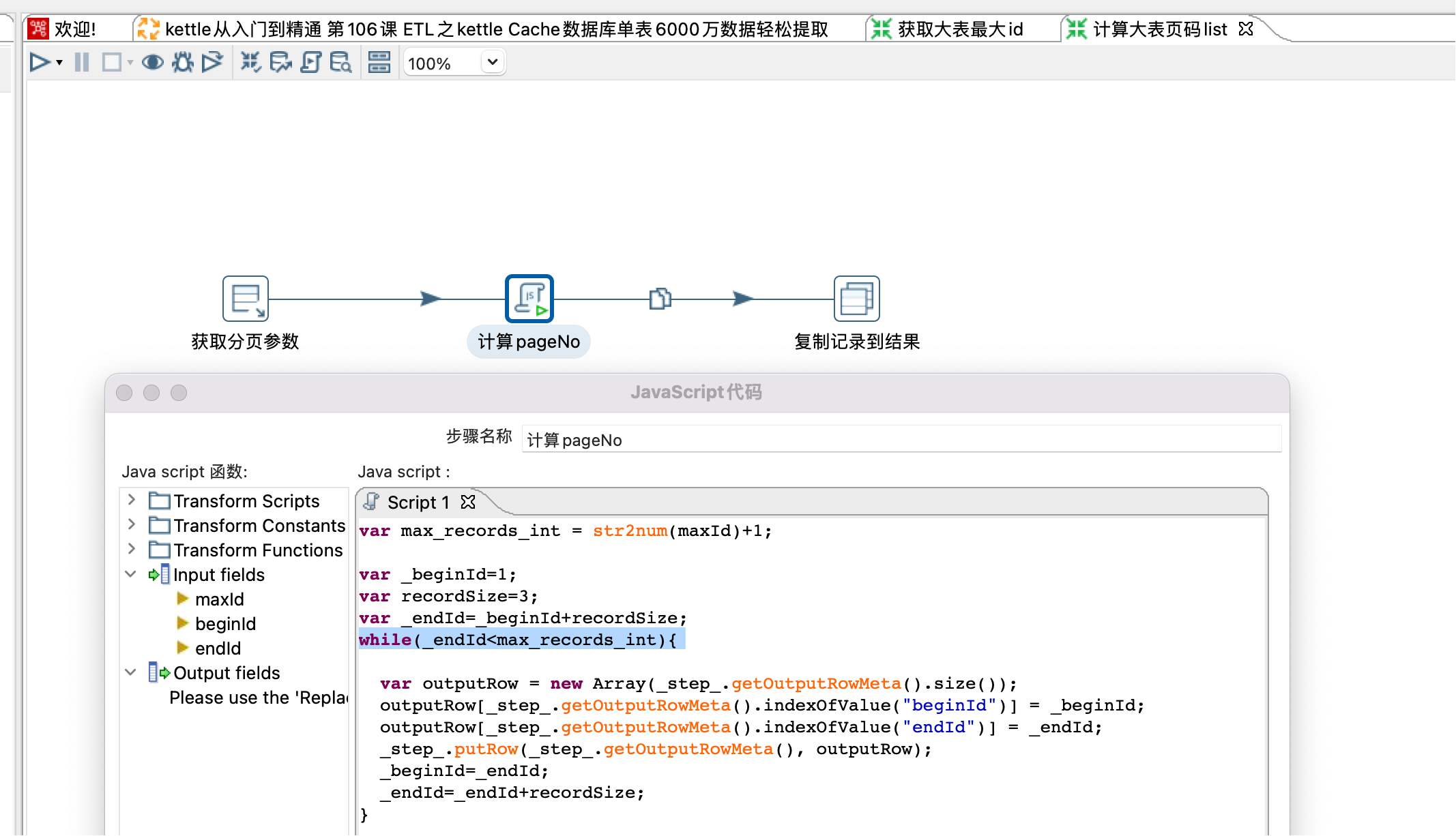
4、子转换:计算大表页码list
使用javascript步骤根据maxId,beginId,recordSize 计算提取区间list
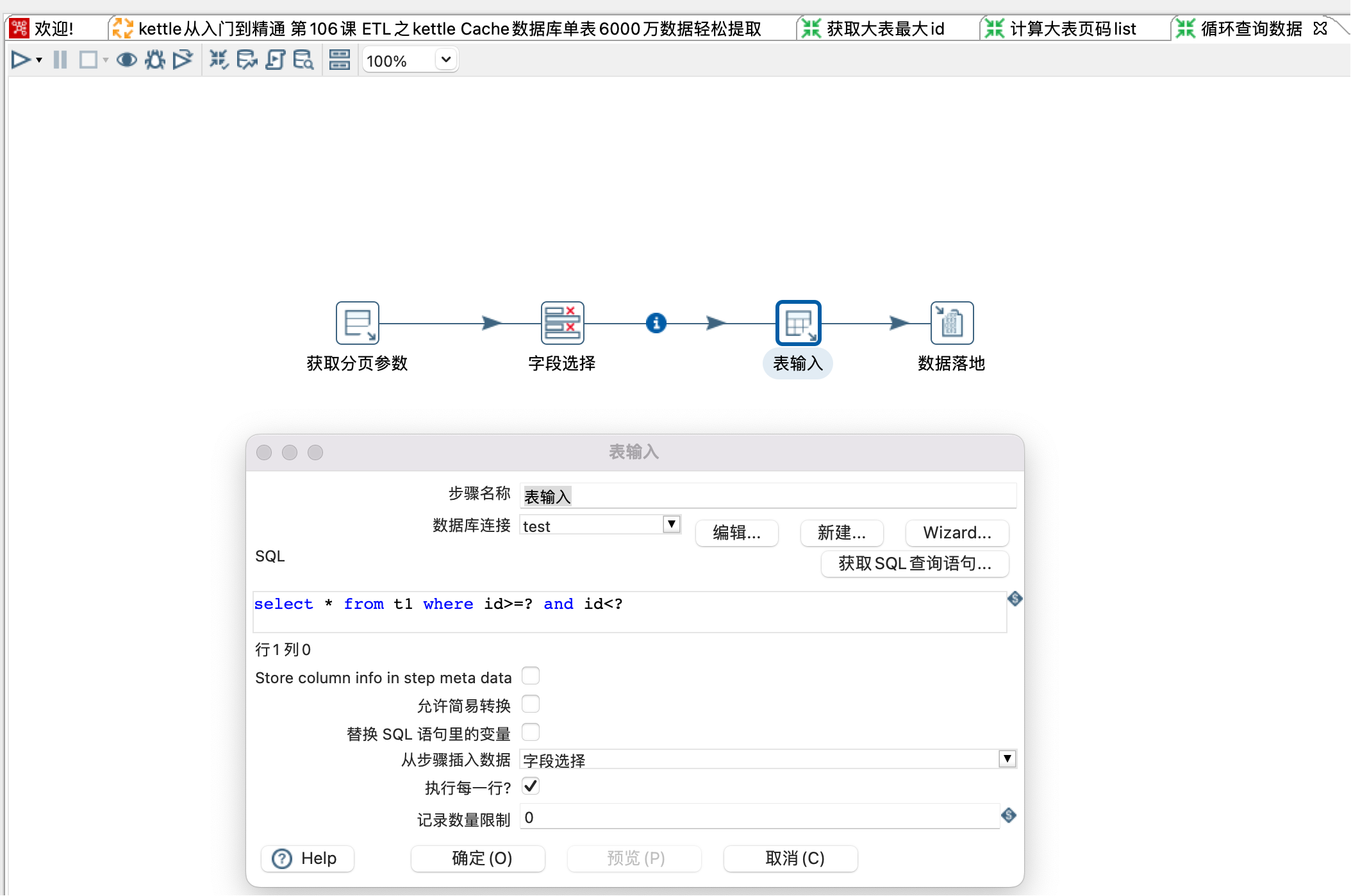
5、子转换:循环查询数据
这里根据前值步骤传递的左闭右开区间数据,将参数传递给表输入步骤,拼接成sql语句(select * from t1 where id>=beginId and id<endId)
6、保存&运行
从打印日志可以清晰的看出,每次查询三条数据,最后一次查询了剩余的一条数据,done!!!

7、一把过
本地测试之后差不多晚上23点了,把demo发给对方之后又连麦讲解了下实现思路,第二天小伙伴根据自己的实际业务调整子转换(循环查询数据),很顺利的解决了这个困扰自己很久的问题。

8、写在最后
伙伴们,今天咱们演示的demo是基于自增id,也可以基于时间区间来抽取,小伙伴你们还有其他好的方法吗?欢迎留言一起探讨。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号