

1. OLAP分类
1.1 MOLAP
特点
一般会根据用户定义的数据维度、度量(也可以叫指标)在数据写入时生成预聚合数据;Query查询到来时,实际上查询的是预聚合的数据而不是原始明细数据,在查询模式相对固定的场景中,这种优化提速很明显。
优点
数据预处理,将原始数据按照指定的计算规则预先做聚合计算,这样避免了查询过程中出现大量的即使计算,提升了查询性能。
缺点
但是这样的预聚合处理,需要预先定义维度,会限制后期数据查询的灵活性;如果查询工作涉及新的指标,需要重新增加预处理流程,损失了灵活度,存储成本也很高;同时,这种方式不支持明细数据的查询,仅适用于聚合型查询(如:sum,avg,count)。
典型代表
Druid,Kylin,Doris
1.2 ROLAP
特点
ROLAP收到Query请求时,会先解析Query,生成执行计划,扫描数据,执行关系型算子,在原始数据上做过滤(Where)、聚合(Sum, Avg, Count)、关联(Join),分组(Group By)、排序(Order By)等,最后将结算结果返回给用户,整个过程都是即时计算,没有预先聚合好的数据可供优化查询速度,拼的都是资源和算力的大小。
优点
不需要进行数据预处理 ( pre-processing ),因此查询灵活,可扩展性好。
缺点
使用 MPP 架构,通过扩大并发来增加计算资源,可以高效处理大量数据。但是当数据量较大或 query 较为复杂时,查询性能也无法像 MOLAP 那样稳定。所有计算都是即时触发 ( 没有预处理 ),因此会耗费更多的计算资源,带来潜在的重复计算。
典型代表
Presto,Impala,GreenPlum,Clickhouse,Elasticsearch,Spark SQL,Flink SQL
1.3 HOLAP
特点
是 MOLAP 和 ROLAP 的一种融合。当查询聚合性数据的时候,使用MOLAP 技术;当查询明细数据时,使用 ROLAP 技术。在给定使用场景的前提下,以达到查询性能的最优化。
2. 定义
Apache Kylin是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的表。
3. 发展历史
2013 年年初,在 eBay 内部使用的传统数据仓库及商业智能平台碰到了“瓶颈”,
2014 年 9 月底,代号 Kylin 的大数据平台在 eBay 内部正式上线,
2014 年 10 月 1 日,Kylin 项目负责人韩卿将 Kylin 的源代码提交到 github.com 并正式开源,
2014 年 11 月 Kylin 项目于正式加入 Apache 孵化器项目,
2015 年 9 月,Apache Kylin 与 Apache Spark、Apache Kafka、H2O、Apache Zeppelin 等一同获得了 2015 年度“最佳开源大数据工具奖”。
2015 年 10 月,Apache Kylin 1.0 正式发布。
2015 年 11 月,Apache 软件基金会宣布 Apache Kylin 正式成为顶级项目。这是第一个完全由中国团队贡献到全球最大的开源软件基金会的顶级项目。
2016 年 3 月,由 Apache Kylin 核心开发者组建的创业公司 Kyligence 正式成立。
2016 年一些新兴项目如 Google 领导的 TensorFlow、Apache Beam 崭露头角,与Apache Kylin 再次登上领奖台,蝉联“最佳开源大数据工具奖”。
4. 名词说明
Cube:一个cube就是一个Hive表的数据按照指定维度与指标计算出的所有组合结果
Cuboid:其中每一种维度组合称为cuboid,一个cuboid包含一种具体维度组合下所有指标的值。
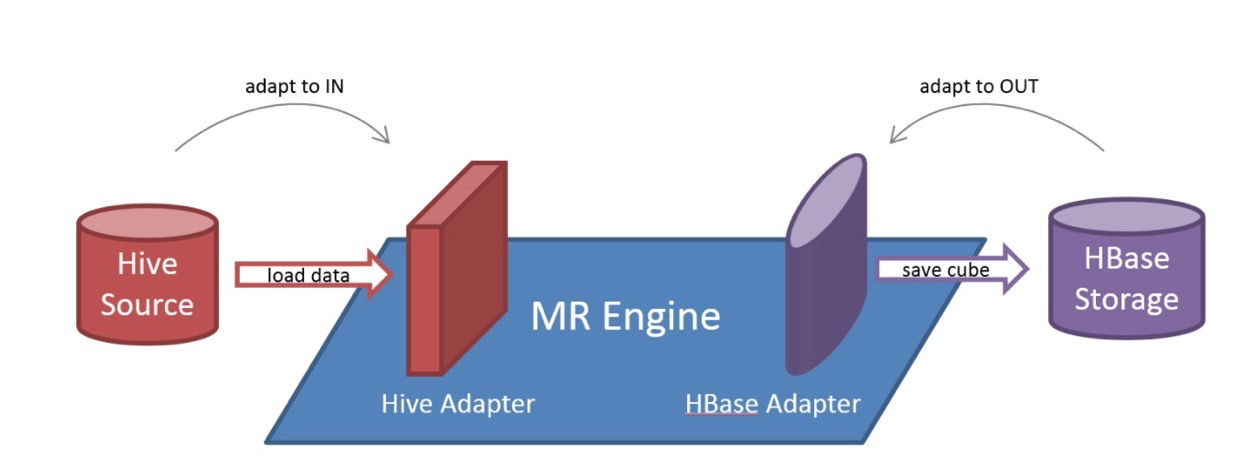
5. 架构

图一
图二
图一模块解释:插件式架构
A:数据源,目前主要是 Hadoop、Hive、Kafka 和 RDBMS,保存着待分析的用户数据,作为Kylin的输入。
B:存储引擎。默认是HBase,可支持parquet存储 [https://kyligence.io/blog/apache-kylin-on-apache-parquet/]
C:Kylin 核心:
- REST Server:是一套面向应用程序开发的入口点。可以提供查询、获取结果、触发cube构建任务、获取元数据以及获取用户权限等,也可以通过Restful接口实现SQL查询。
- 查询引擎(Query Engine)当cube准备就绪后,查询引擎就能够获取并解析用户查询。它随后会与系统中的其它组件进行交互,从而向用户返回对应的结果。 在Kylin中,使用Calcite对SQL进行解析。
- Routing:负责将解析的SQL生成的执行计划转换成cube缓存的查询,cube是通过预计算缓存在Storage中,查询可以在亚秒级完成。
- 元数据管理工具(Metadata):元数据管理,用于对保存在Kylin当中的所有元数据进行管理,其中包括最为重要的cube元数据。其它全部组件的正常运作都需以元数据管理工具为基础。 Kylin的元数据存储在hbase中。
- 任务引擎(Cube Build Engine):Map Reduce,Spark, Kylin。
D:上层应用:BI,JDBC查询,RESTful查询
6. Cube
6.1 Cube 构建流程
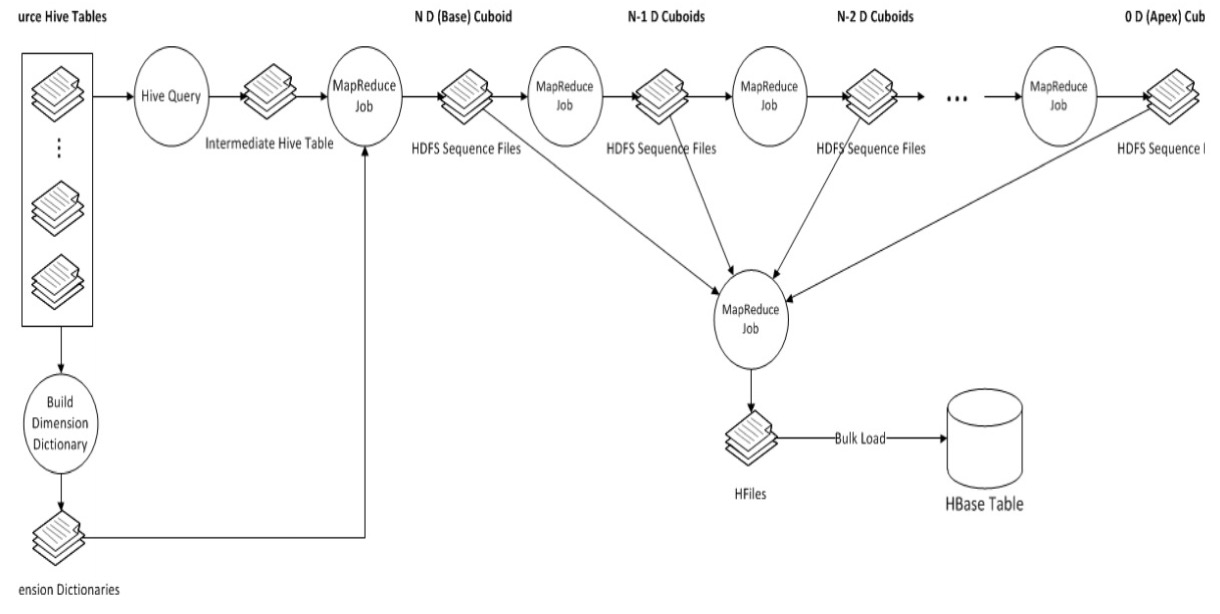
主要步骤如下:
- 构建一个中间平表(Hive Table):将Model中的fact表和look up表构建成一个大的Flat Hive Table。
- 重新分配Flat Hive Tables。
- 从事实表中抽取维度的Distinct值。
- 对所有维度表进行压缩编码,生成维度字典。
- 计算和统计所有的维度组合,并保存,其中,每一种维度组合,称为一个Cuboid。
- 创建HTable。
- 构建最基础的Cuboid数据。
- 利用算法构建N维到0维的Cuboid数据。
- 构建Cube。
- 将Cuboid数据转换成HFile。
- 将HFile直接加载到HBase Table中。
- 更新Cube信息。
- 清理Hive。
6.2 Cube 构建算法
6.2.1 逐层算法(Layer Cubing)
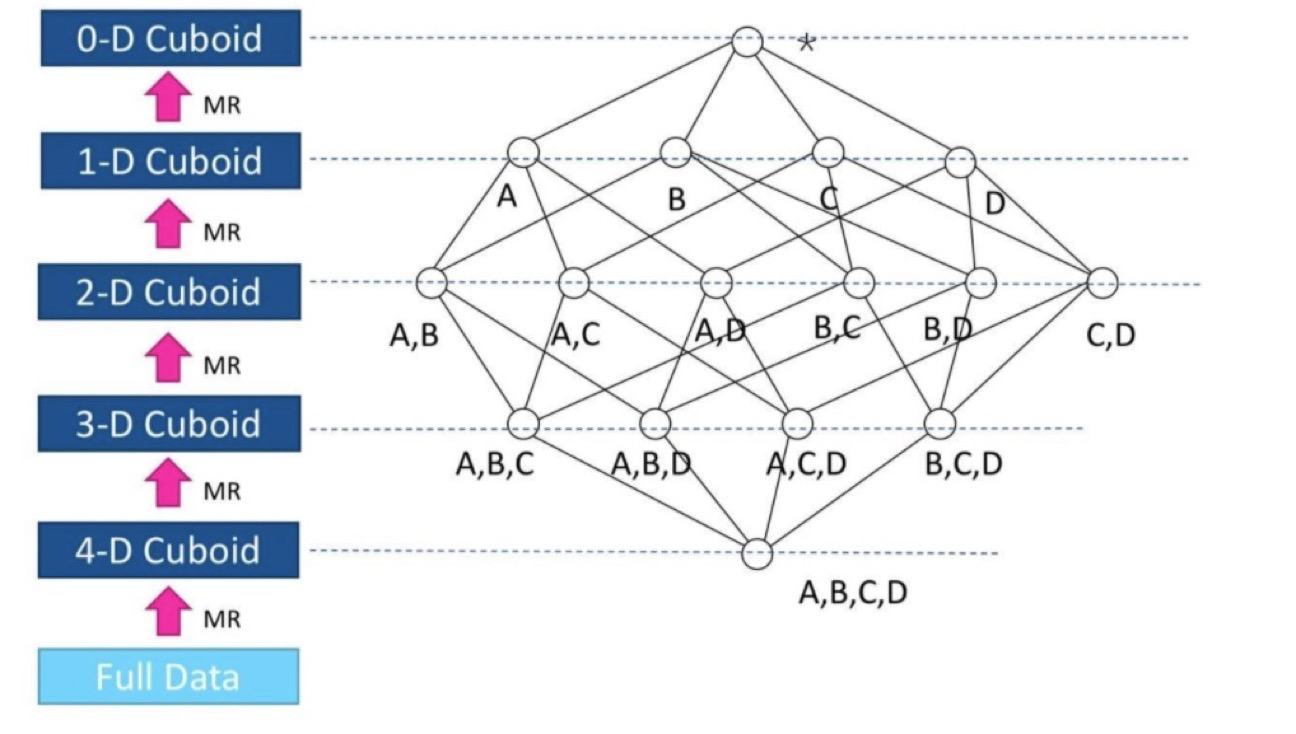

图三 示例1
此算法的Mapper和Reducer较简单。Mapper以上一层Cuboid的结果(Key-Value对)作为输入。由于Key是由各维度值拼接在一起,从其中找出要聚合的维度,去掉它的值成新的Key,并对Value进行操作,然后把新Key和Value输出,进而Hadoop MapReduce对所有新Key进行排序、洗牌(shuffle)、再送到Reducer处;Reducer的输入会是一组有相同Key的Value集合,对这些Value做聚合计算,再结合Key输出就完成了一轮计算。
每一轮的计算都是一个MapReduce任务,且串行执行; 一个N维的Cube,至少需要N次MapReduce Job。
优点
此算法充分利用了MapReduce的能力,处理了中间复杂的排序和洗牌工作,故而算法代码清晰简单,易于维护;得益于Hadoop的成熟,此算法对集群要求低,运行稳定。
缺点
当Cube有比较多维度的时候,所需要的MapReduce任务也相应增加;由于Hadoop的任务调度需要耗费额外资源,特别是集群较庞大的时候,反复递交任务造成的额外开销会相当可观;
由于Mapper不做预聚合,此算法会对Hadoop MapReduce输出较多数据; 虽然已经使用了Combiner来减少从Mapper端到Reducer端的数据传输,所有数据依然需要通过Hadoop MapReduce来排序和组合才能被聚合,无形之中增加了集群的压力
对HDFS的读写操作较多:由于每一层计算的输出会用做下一层计算的输入,这些Key-Value需要写到HDFS上;当所有计算都完成后,Kylin还需要额外的一轮任务将这些文件转成HBase的HFile格式,以导入到HBase中去。
总体而言,该算法的效率较低,尤其是当Cube维度数较大的时候。
6.2.2 快速Cube算法(Fast Cubing)
快速Cube算法(Fast Cubing)是Kylin对新算法的一个统称,它还被称作“逐段”(By Segment) 或“逐块”(By Split) 算法。
该算法的主要思想是,对Mapper所分配的数据块,将它计算成一个完整的小Cube 段(包含所有Cuboid);每个Mapper将计算完的Cube段输出给Reducer做合并,生成大Cube,也就是最终结果;
新算法的核心思想就是最大化利用Mapper端的CPU和内存,对分配的数据块,将需要的组合全都做计算后再输出给Reducer;由Reducer再做一次合并(merge),从而计算出完整数据的所有组合。只需经过一轮Map-Reduce就完成了以前需要N轮的Cube计算。
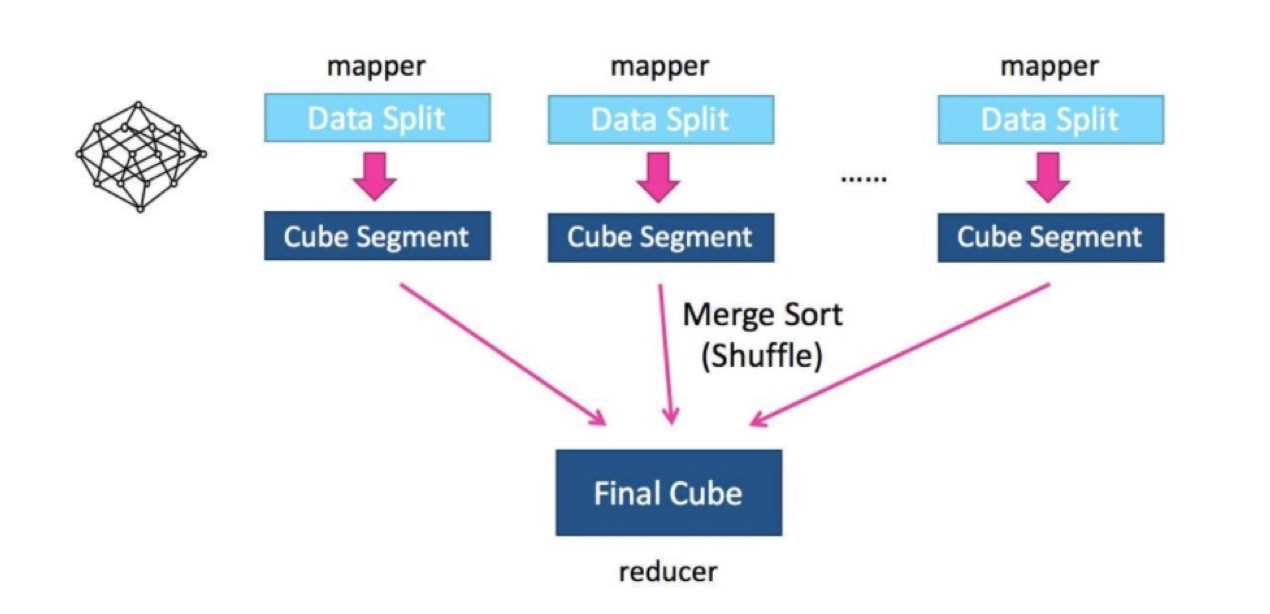
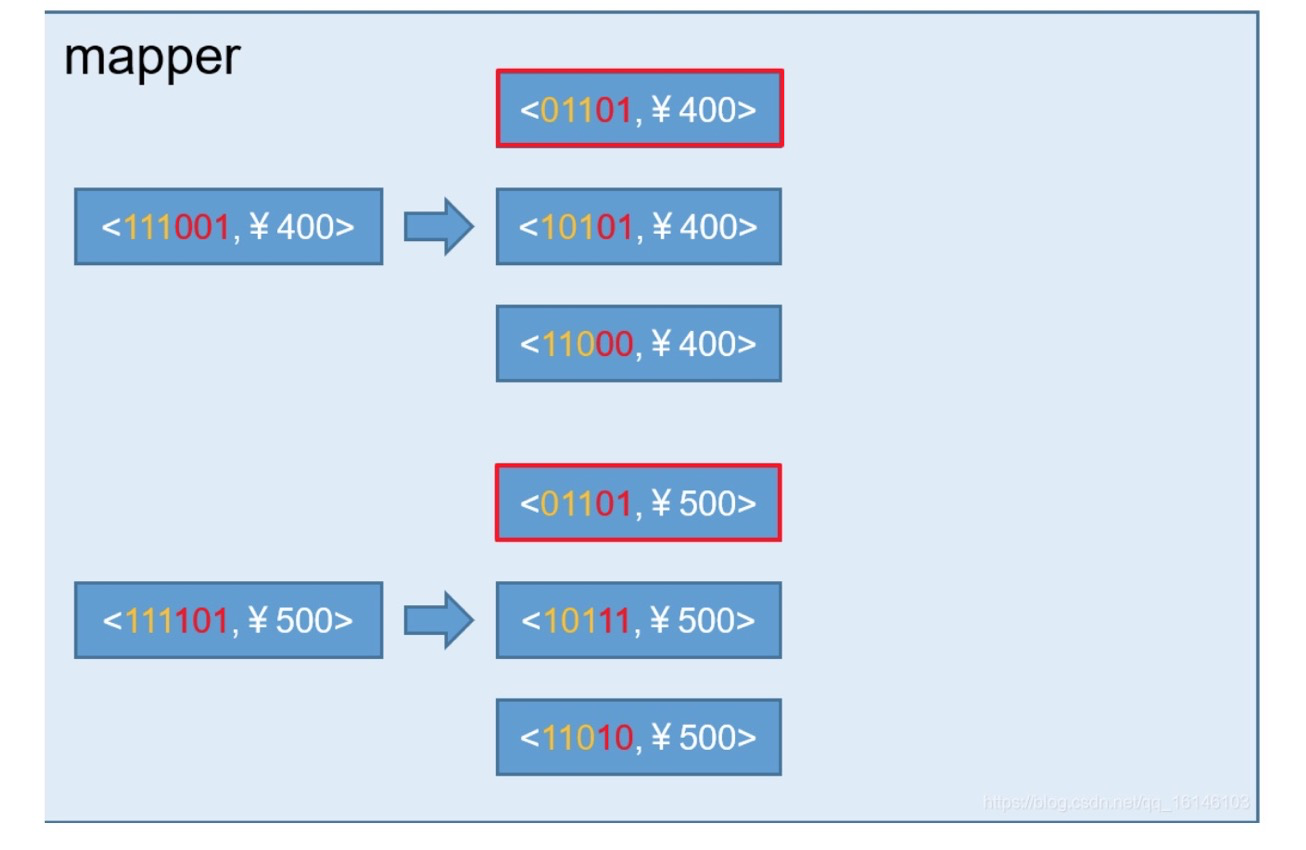
图四 示例2.1
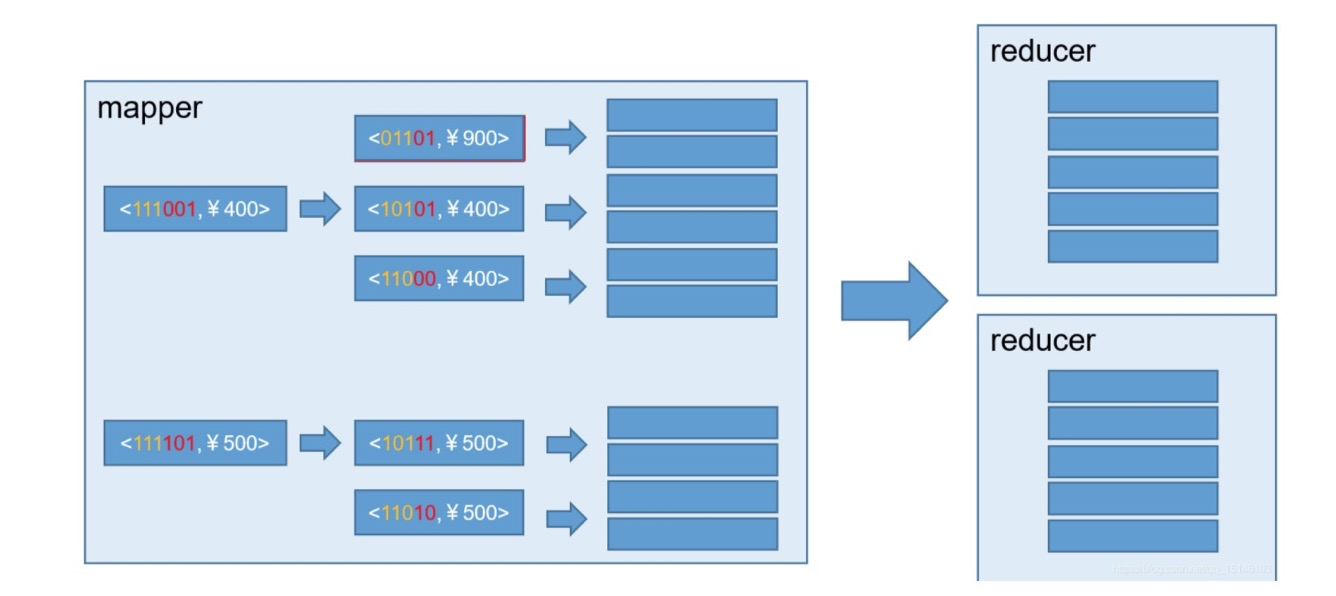
图四 示例2.2
在Mapper内部, 也有一些优化,如下图:
一个典型的四维Cube的生成树;第一步会计算Base Cuboid(所有维度都有的组合),再基于它计算减少一个维度的组合。基于parent节点计算child节点,可以重用之前的计算结果;当计算child节点时,需要parent节点的值尽可能留在内存中; 如果child节点还有child,那么递归向下,所以它是一个深度优先遍历。当有一个节点没有child,或者它的所有child都已经计算完,这时候它就可以被输出,占用的内存就可以释放。
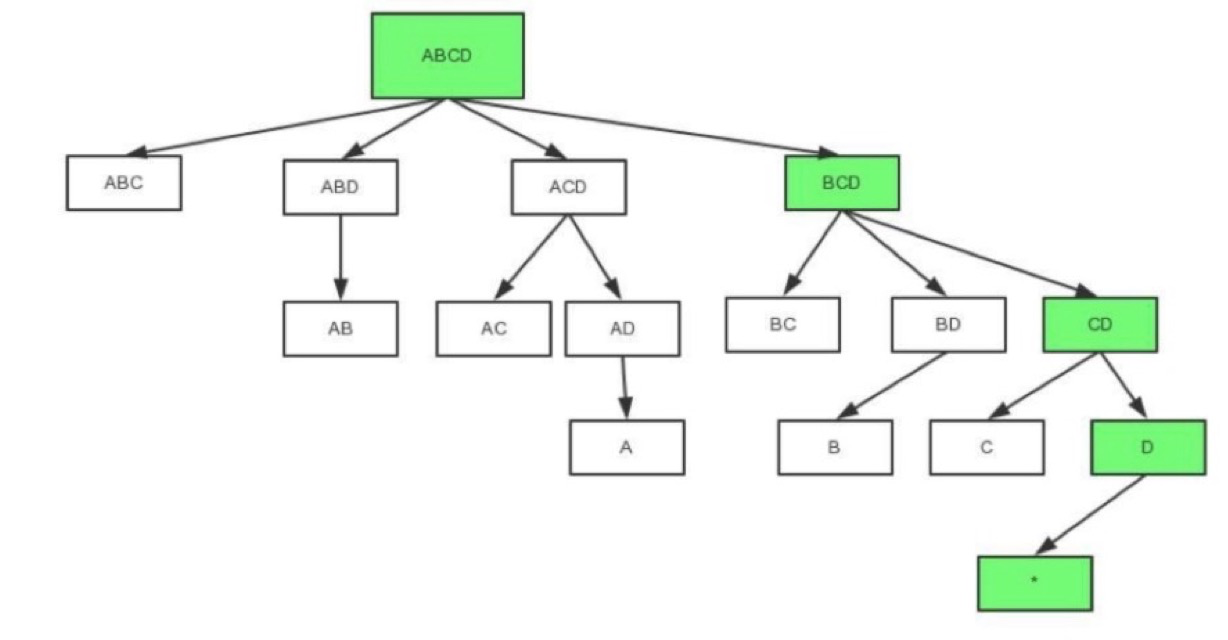
优点
总的IO量比以前大大减少。
此算法可以脱离Map-Reduce而对数据做Cube计算,故可以很容易地在其它场景或框架下执行,例如Streaming 和Spark。
缺点
代码比以前复杂了很多: 由于要做多层的聚合,并且引入多线程机制,同时还要估算JVM可用内存,当内存不足时需要将数据暂存到磁盘,所有这些都增加复杂度。
对Hadoop资源要求较高,用户应尽可能在Mapper上多分配内存;如果内存很小,该算法需要频繁借助磁盘,性能优势就会较弱。在极端情况下(如数据量很大同时维度很多),任务可能会由于超时等原因失败。
6.2.3 Cube 存储原理
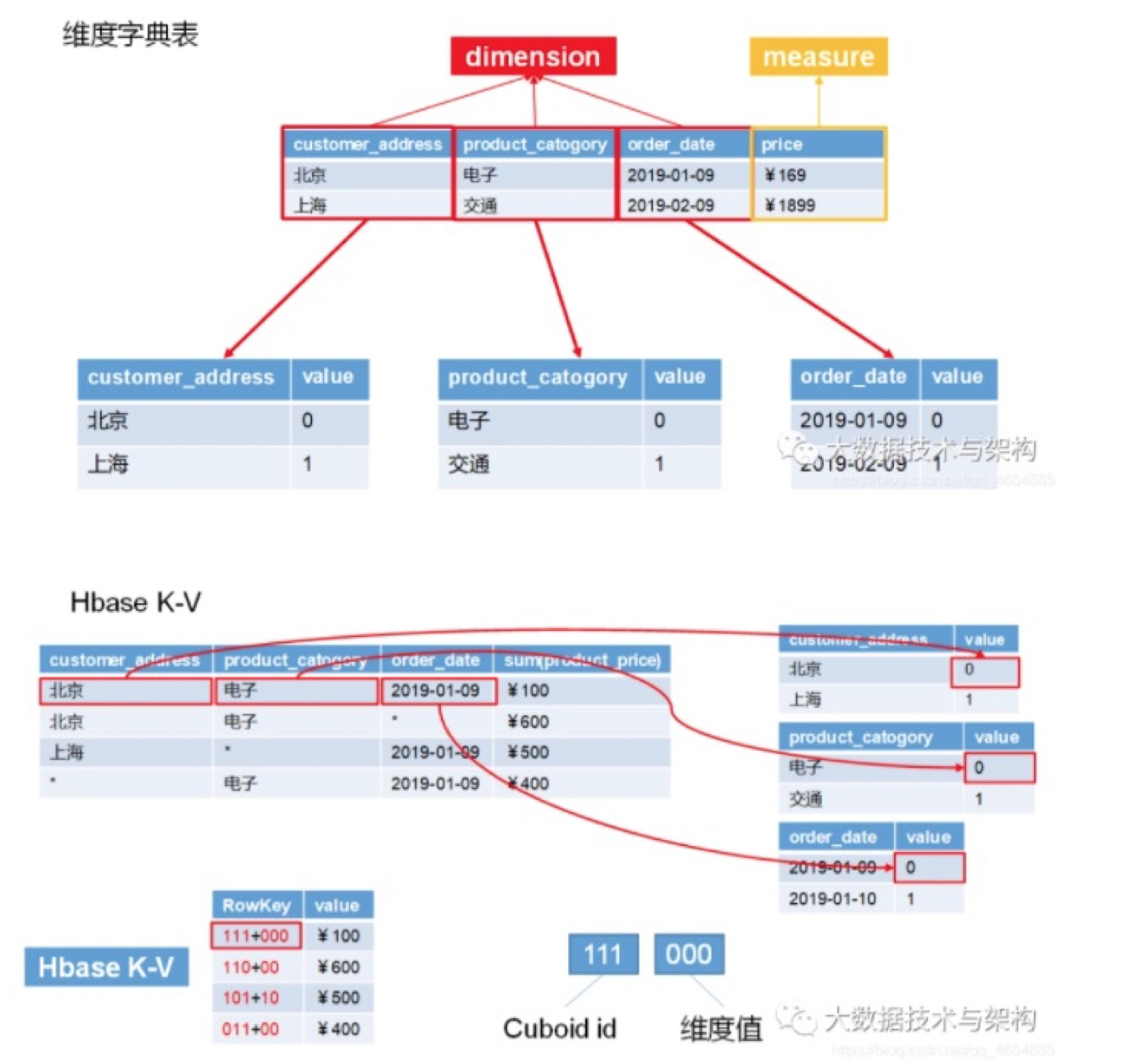
6.2.4 Cube 优化
- 衍生维度
衍生维度用于在有效维度内将维度表上的非主键维度排除掉,并使用维度表的主键(其实是事实表上相应的外键)来替代它们
- 聚合组
1)强制维度(Mandatory),如果一个维度被定义为强制维度,那么这个分组产生的所有Cuboid中每一个Cuboid都会包含该维度;
2)层级维度(Hierarchy),每个层级包含两个或更多个维度,上下级关系;
3)联合维度(Joint),每个联合中包含两个或更多个维度,如果某些列形成一个联合,那么在该分组产生的任何Cuboid中,这些联合维度要么一起出现,要么都不出现。
7. RowKey 设计
7.1 RowKey 顺序
- 将经常出现在查询中的维度,放在不经常出现的维度的前面,被用作where过滤的维度放在前边。这样,在需要进行后聚合的场景中查询效率会更高。
![]()
-

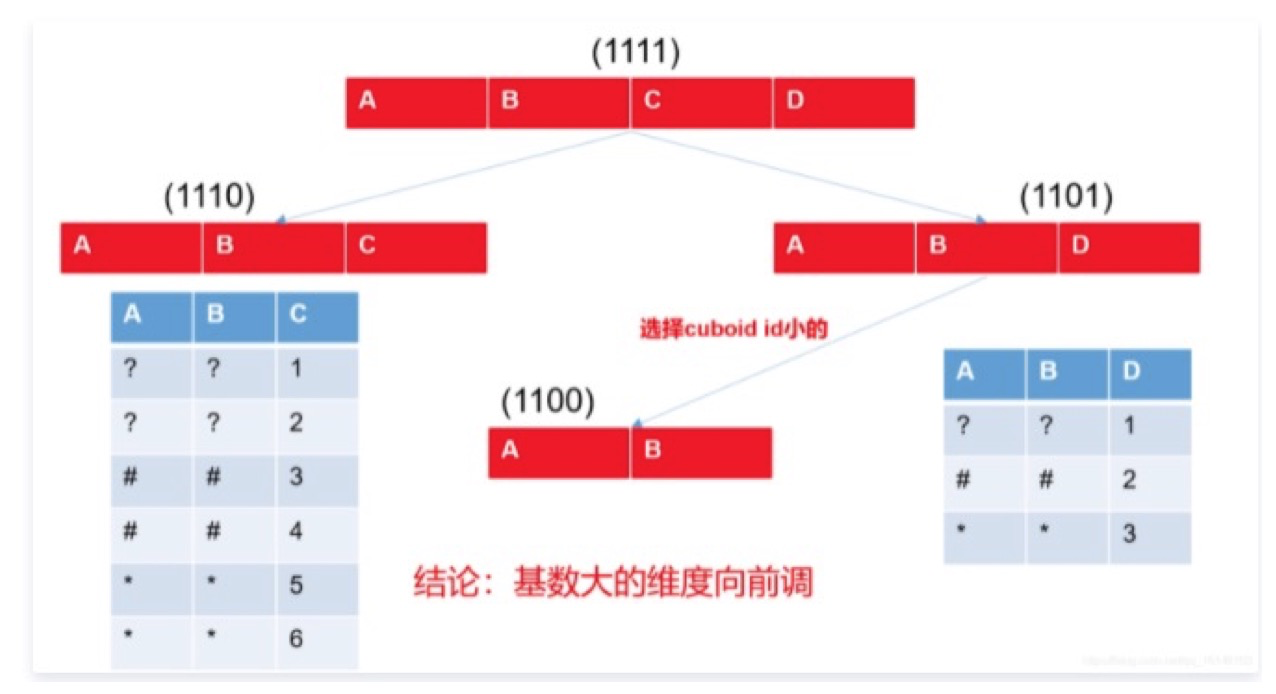
- 对于不会出现在过滤条件中的维度,按照其基数的高低,优先将低基数的维度放在 Rowkey 的后面。这是因为在逐层构建 Cuboid、确定 Cuboid 的生成树时,Kylin 会优先选择 Rowkey 后面的维度所在的父 Cuboid 来生成子 Cuboid,那么基数越低的维度,包含它的父 Cuboid 的行数就越少,聚合生成子 Cuboid 的代价就越小。
![]()
8. 特点
- 可扩展超快的基于大数据的分析型数据仓库: Kylin 是为减少在 Hadoop/Spark 上百亿规模数据查询延迟而设计;
- 交互式查询能力:通过 Kylin,用户可以与 Hadoop 数据进行亚秒级交互,在同样的数据集上提供比 Hive 更好的性能;
- Hadoop ANSI SQL 接口: 作为一个分析型数据仓库(也是 OLAP 引擎),Kylin 为 Hadoop 提供标准 SQL 支持大部分查询功能;
- 实时 OLAP:Kylin 可以在数据产生时进行实时处理,用户可以在秒级延迟下进行实时数据的多维分析;3.0以后
- 与BI工具无缝整合: Kylin 提供与 BI 工具的整合能力,如Tableau,PowerBI/Excel,MSTR,QlikSense,Hue 和 SuperSet
9. 缺点
- 集群依赖较多,如HBase,Hive,zk等,属于重量级方案,因此运维成本也较高;
- 查询的维度组合数量需要提前确定好,不适合即席查询分析;
- 预计算量大,资源消耗多;
- 聚合查询非常高效但不支持明细查询
- 不支持INSERT,UPDATE和DELETE
10. 实操 略
实时OLAP:

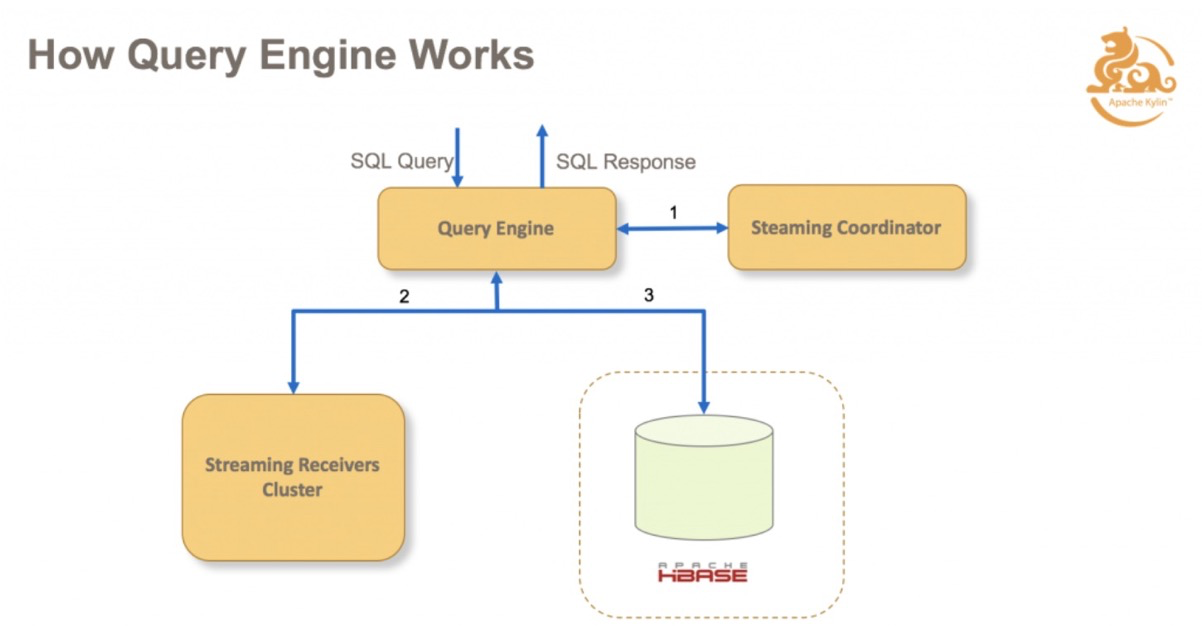
在整体框架中新增了 Real-time Streaming 的组件。包括一个 Streaming Coordinator,和若干个 Streaming Receiver。它的主要任务是去消费实时数据源的数据,并且存在我们实时集群里面去;Receiver 会定期的调用 Build Engine,把这些实时的数据构建到历史数据里。
当查询进来之后,如果击中了一个实时的 Cube 的话,不仅会去查 HBase,还会去查实时集群里面的数据,这样结合两者的结果,可以保证最终数据的实时性,实时数据都能查到。
下图是整个数据流的过程,消息从数据源出来之后,在内存中聚合,内存的数据到达阈值或者是等到一定时间之后,会 flush 到我们实时集群里面磁盘上;再过一段时间之后,上传磁盘的数据,通过 MapReduce,将 Cuboid 数据构建到 HBase。整体而言,数据存在在以上三个部分。
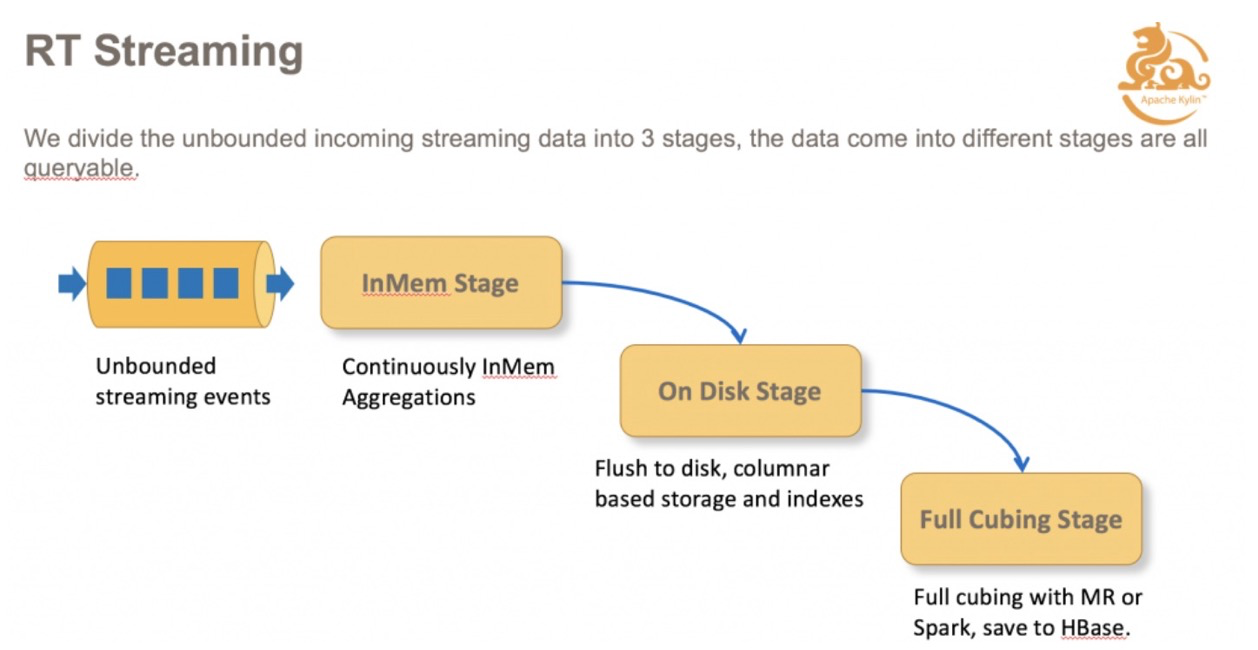
这三个部分的数据都是可以查询的,这样就保证了查询的实时性,数据一旦消费进来就可以被查到,就可以做到毫秒级的延迟。
实时集群,包括 Query Engine,Coordinator, Receiver,Metadata Store。
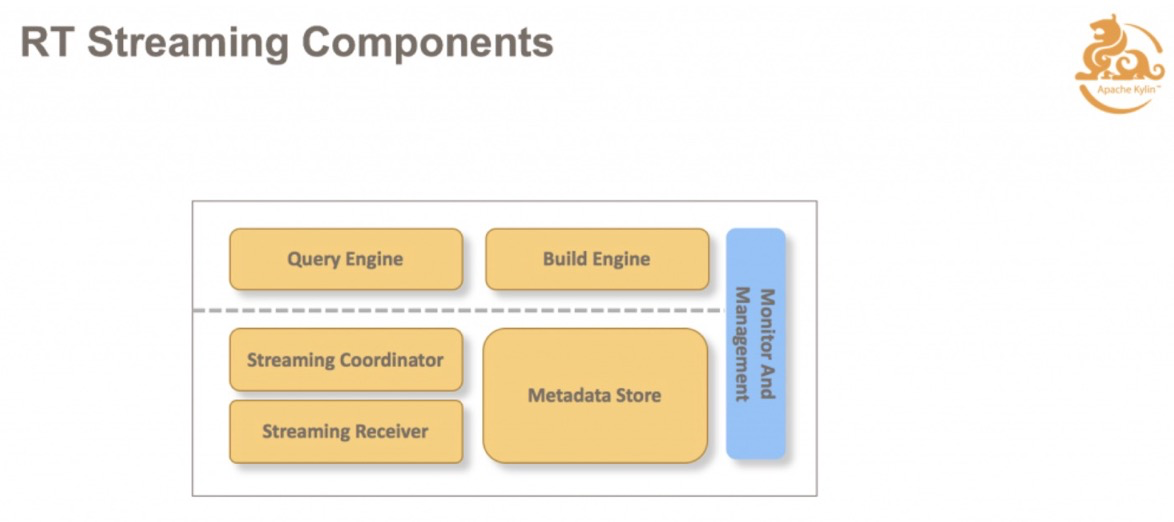
Query Engine 会先找负责消费数据源的数据 Receiver,根据查询去拉取数据。Receiver Cluster 是一个集群,所以需要有一个协调者,Streaming Coordinator 去协调哪些 Receiver 来负责消费 Kafka 里面的 Partition,待查询需求指令下达时,知道需要通过 Coordinator 来获取 Cube 的数据是在哪些 Receiver 里面的。另外,Metadata Store,主要是用来存分配方面的信息,哪个 Topic 的 Partition 被哪些 Receiver 承担摄入和查询任务;Metadata Store 还保存有一些HA信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号