总结一下最近整合的两段训练的代码(猫狗图片分类)以供以后学习参考使用
第一种代码
点击查看代码
import os
import random
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader,Dataset
import torchvision.transforms as transforms
import torch.optim as optim
from PIL import Image
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed() # 设置随机种子-使结果具有重复性,重现结果,这功能就是为了DataLoader中的shuffle,使每一次训练都乱的一样
#功能上,torch.manual_seed(0)=set_seed(),设置随机种子后,是每次运行py文件的输出结果都一样,而不是每次随机函数生成的结果一样
#同时需注意,必须使用相同的生成随机数函数才能保证每次执行 torch.manual_seed()语句后生成相同随机数,否则无效
pet_label={'cat':0,'dog':1}
#参数设置
Max_epoch=5
Batch_size=100
Lr=0.02
#创建MyDataset类
class MyDataset(Dataset):
def __init__(self,data_dir,transform=None):
self.label_name={'cat':0,'dog':1}
self.data_info = self.get_img_info(data_dir)
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.data_info)
@staticmethod #静态方法绑定到一个类而不是该类对象,意味着可以在没有该类对象的情况下调用静态方法
def get_img_info(data_dir):
data_info=list()
for root,dirs,_ in os.walk(data_dir):
for sub_dir in dirs:
img_names=os.listdir(os.path.join(root,sub_dir))
for i in range(len(img_names)):
img_name=img_names[i]
path_img=os.path.join(root,sub_dir,img_name)
label=pet_label[sub_dir]
data_info.append((path_img,int(label)))
return data_info
#定义网络
class Net(nn.Module):
def __init__(self,classes):
super(Net,self).__init__()
self.conv1=nn.Sequential(
nn.Conv2d(3,6,5),
nn.ReLU(),
nn.MaxPool2d(2,2)
)
self.conv2=nn.Sequential(
nn.Conv2d(6,16,5),
nn.ReLU(),
nn.MaxPool2d(2,2)
)
self.fc=nn.Sequential(
nn.Linear(16*5*5,120),
nn.ReLU(),
nn.Linear(120,84),
nn.ReLU(),
nn.Linear(84,classes)
)
def forward(self,x):
out=self.conv1(x)
out=self.conv2(out)
out=out.view(out.size(0),-1)
out=self.fc(out)
return out
#------------------------------------step 1 数据--------------------------------------------
train_dir='/home/yanhua/Documents/catdogxunlian/dogcat/train'
test_dir='/home/yanhua/Documents/catdogxunlian/dogcat/test'
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
common_transform=transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean,norm_std)
])
#构建MyDataset实例
train_data=MyDataset(data_dir=train_dir,transform=common_transform)
test_data=MyDataset(data_dir=test_dir,transform=common_transform)
#构建DataLoder
train_loader=DataLoader(dataset=train_data,batch_size=Batch_size,shuffle=True)
test_loader=DataLoader(dataset=test_data,batch_size=Batch_size)
#------------------------------------step 2 模型-------------------------------------------
net=Net(classes=2)
#------------------------------------step 3 损失函数---------------------------------------
criterion=nn.CrossEntropyLoss()
#------------------------------------step 4 优化器-----------------------------------------
optimizer=optim.SGD(net.parameters(),lr=Lr,momentum=0.8)
#------------------------------------step 5 训练-------------------------------------------
for epoch in range(Max_epoch):
loss_mean=0.
correct=0.
total=0.
for step,(batch_x,batch_y) in enumerate(train_loader): #因为enumerate的返回特性,才有step这个变量
optimizer.zero_grad()
outputs=net(batch_x)
loss=criterion(outputs,batch_y)
loss.backward()
optimizer.step()
_, predicted = torch.max(outputs.data, 1)
total+=batch_y.size(0)
correct+=(predicted ==batch_y).squeeze().sum().numpy()
loss_mean+=loss.item()
if (step+1) %5 == 0:
loss_mean = loss_mean / 5
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(epoch, Max_epoch, step+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0. #这里correct和total并不需要清零,因为这两哥们都是共进退的
#torch.save(net.state_dict(),'/home/yanhua/Documents/catdogxunlian/lenet.pth')--保存模型参数
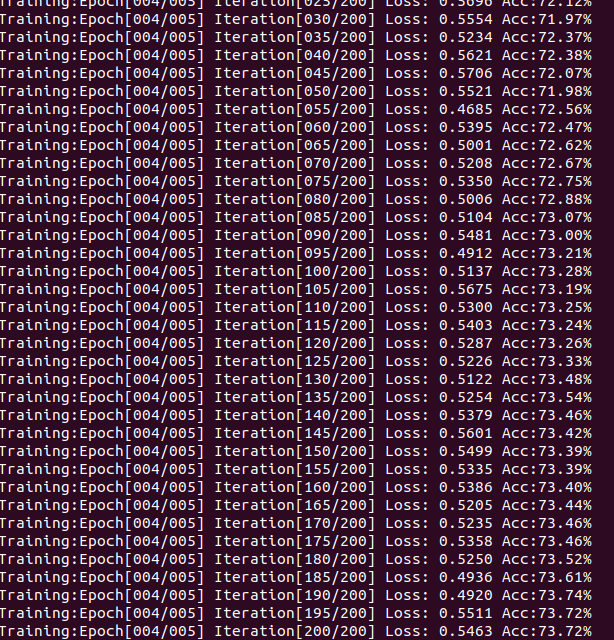
上述代码的标签和网络都是自己定义,至于文件的分类另外自己写一个不会很难。该实验使用的网络结构类似Lenet,且首次实验得到的最后准确率是73%左右,哦?忘了写测试代码了,算了,下次有时间在补上去。虽然忘了写测试代码,但我保存了模型参数后,在网上随便找了两组照片,每组猫狗的图片加起来都是十张,将保存后的模型读入网络后,用这两组照片实验,统计了一下,刚好猜中了7或8张,这符合逻辑和数据。
上述代码是我个人认为比较全面的(啥都有),它使用了torchvison中已有的resnet18网络,当然也可以自己构建别的网络,并且在每个大循环结束后就进行了验证。
这里突然想看一下有shuffle和没有的情况
第二种代码
点击查看代码
from torchvision.transforms import transforms
from torchvision.datasets import ImageFolder #ImageFolder用于加载图片与相应的标签
import torch
from torch.utils.data import DataLoader
from torchvision import models
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
#1、准备数据
simple_transform=transforms.Compose(
[
transforms.Resize((224,224)), #这里一定要注意((224,224))的两个括号或([])
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]
)
train=ImageFolder('dogsandcats/train/',simple_transform) #train和valid两个对象包含了类别和相应数据集索引的映射
valid=ImageFolder('dogsandcats/valid/',simple_transform)
#print(train.class_to_idx)
#print(train.classes)
train_data_gen=DataLoader(train,batch_size=100,num_workers=3,shuffle=True)#num_workers负责并发
valid_data_gen=DataLoader(valid,batch_size=100,num_workers=3)
dataloaders={'train':train_data_gen,'valid':valid_data_gen}
dataset_sizes={'train':len(train_data_gen),'valid':len(valid_data_gen)}
torch.manual_seed(0)
#2、构建网络
model_ft=models.resnet18(pretrained=True) #pretrained是否使用预训练好的权重(ImageNet分类问题)
num_ftrs=model_ft.fc.in_features
model_ft.fc=nn.Linear(num_ftrs,2)
if torch.cuda.is_available():
model_ft=model_ft.cuda()
#3、选择loss和优化器
learning_rate=0.001
criterion=nn.CrossEntropyLoss()
optimizer_ft=optim.SGD(model_ft.parameters(),lr=learning_rate,momentum=0.9)
exp_lr_scheduler=lr_scheduler.StepLR(optimizer_ft,step_size=7,gamma=0.1) #StepLR帮助动态修改学习率
#4、训练模型
def train_model(model,criterion,optimizer,scheduler,num_epochs):
for epoch in range(num_epochs):
#每轮带有训练和验证阶段
for phase in ['train','valid']:
if phase == 'train':
model.train(True) # 模型设为训练模式——default=True,启用Batch Normalization和Dropout
else:
model.train(False) # 模型设为评估模式model.train(False)=model.eval(),不启用BN和Dropout
running_loss=0.0
running_corrects=0.0
total=0
#在数据上迭代
for step,(inputs,labels) in enumerate(dataloaders[phase]):
if torch.cuda.is_available():
inputs,labels=inputs.cuda(),labels.cuda()
#梯度参数清零
optimizer.zero_grad()
#前向传播
outputs=model(inputs)
loss=criterion(outputs,labels)
#只在训练阶段反向优化
if phase =='train':
loss.backward()
optimizer.step()
scheduler.step()
#统计
_,preds=torch.max(outputs.data,1) ##torch.max(tensor,dim)-dim:按索引消去维度,不加_,返回的是一行中最大的数,加_,则返回一行中最大数的位置
running_loss+=loss.item()
#running_corrects+=torch.sum(preds==labels.data)
running_corrects += (preds == labels).squeeze().sum().numpy()
total+=labels.size(0)
if (step+1)%5==0:
loss_mean=running_loss/5
print("{}:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(phase,epoch,num_epochs,step + 1,len(dataloaders[phase]),loss_mean,running_corrects/ total))
loss_mean=0.0
running_loss=0.0
if __name__=='__main__':
train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=10)
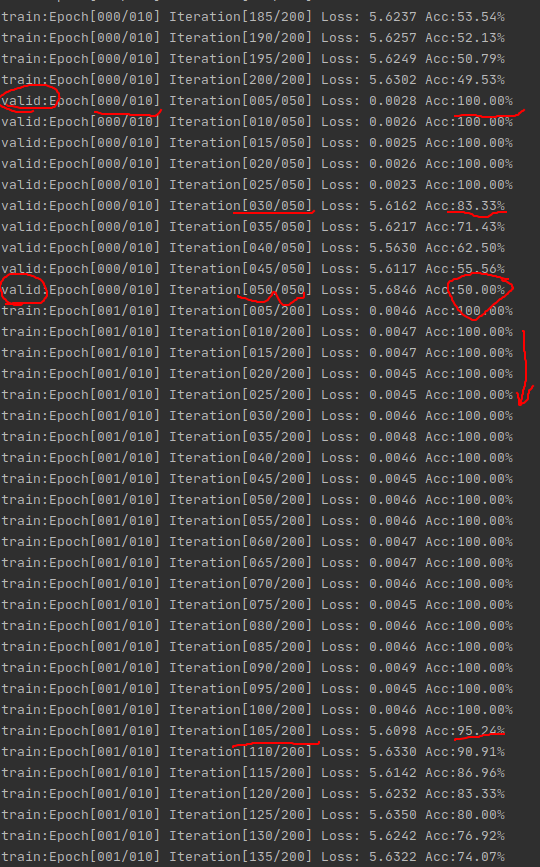
无shuffle时如下两图
![]()
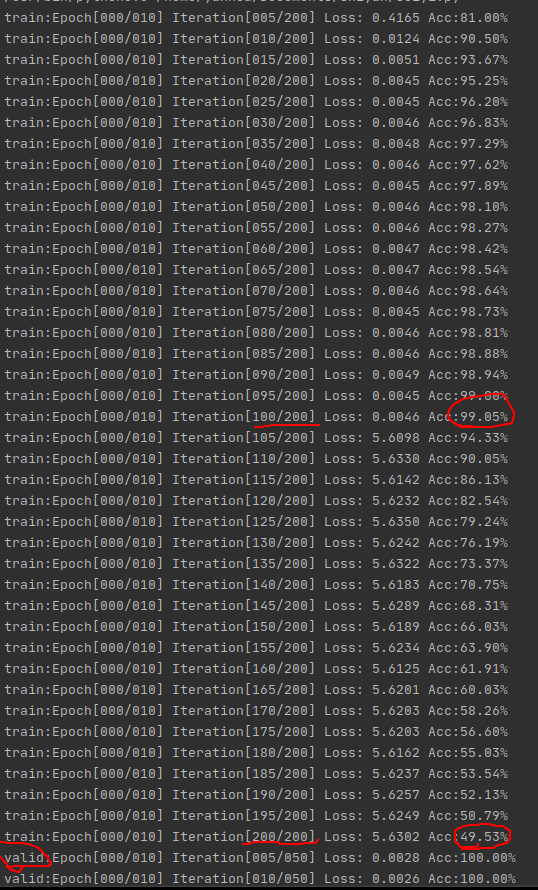
两张图有一点点重复的地方
![]()
有shuffle时如下两图
![]()
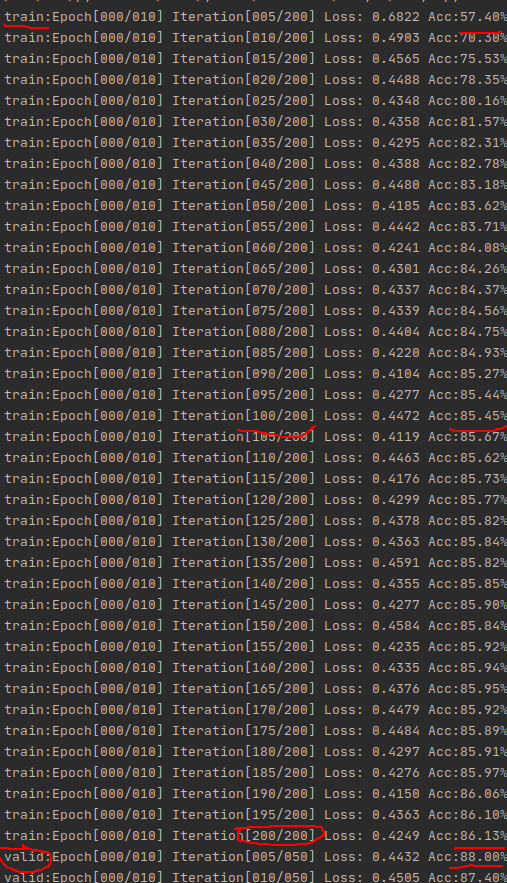
都是中间有点重复,很容易发现,截图导致的
![]()
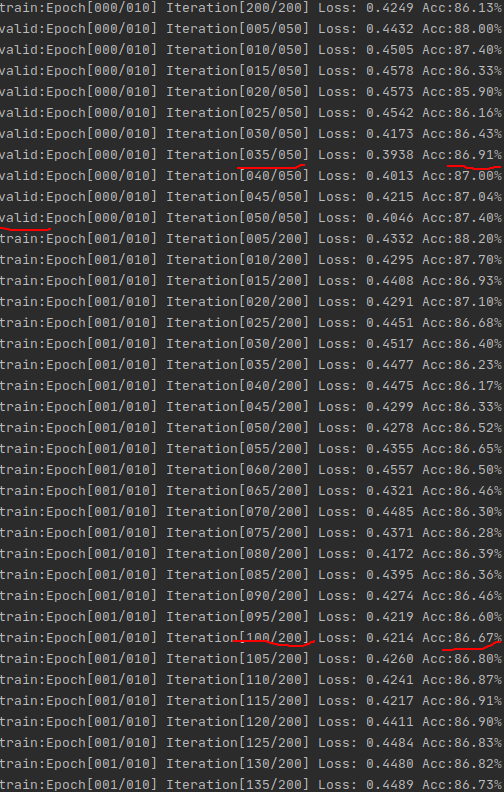
通过对比可以看出,无shuffle时,这个Acc啊跟坐过山车一样,振荡的老起劲,这肯定得训练很多次才能趋于收敛,这也不怪它,毕竟出现这种情况跟数据初期的准备有关,试着想一下,刚开始连续训练10000张猫,在训练到狗图之前,那准确率肯定蹭蹭往上涨,而一旦遇到狗图,因为之前没见过,权重都为猫准备的(类似训练的过拟合了),这不就突然掉了吗,所以出现这种情况也很正常并且符合逻辑。
而有shuffle时,这Acc是真的稳啊,数据也很好看,能清楚地发现Acc在稳步上升。
代码可能还有不完善的地方,不过先到这里吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号