python2与python3的字符编码问题
一、字符编码
1.什么是字符?
字符是各种文字和符号的总称,包括各个国家文字、标点符号、图形符号、数字等。
2.什么是字符集?
字符集是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集有:ASCII字符集、ISO 8859字符集、GB2312字符集、BIG5字符集、GB18030字符集、Unicode字符集等
3.什么是字符编码?
1、计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。
2、字符编码(encoding)和字符集不同。字符集只是字符的集合,不一定适合作网络传送、处理,有时须经编码(encode)后才能应用。如Unicode可依不同需要以UTF-8、UTF-16、UTF-32等方式编码。
3、字符编码就是以二进制的数字来对应字符集的字符。 因此,对字符进行编码,是信息交流的技术基础。
Unicode与utf8的关系:
一言以蔽之:Unicode是内存编码表示方案(是规范),而UTF是如何保存和传输Unicode的方案(是实现)这也是UTF与Unicode的区别。
4.概括
1、使用哪些字符。也就是说哪些汉字,字母和符号会被收入标准中。所包含“字符”的集合就叫做“字符集”。
2、规定每个“字符”分别用一个字节还是多个字节存储,用哪些字节来存储,这个规定就叫做“编码”。
3、各个国家和地区在制定编码标准的时候,“字符的集合”和“编码”一般都是同时制定的。因此,平常我们所说的“字符集”,比如:GB2312, GBK, JIS 等,除了有“字符的集合”这层含义外,同时也包含了“编码”的含义。
4、注意:Unicode字符集有多种编码方式,如UTF-8、UTF-16等;ASCII只有一种;大多数MBCS(包括GB2312,GBK)也只有一种。
//ASCII 记住一句话:计算机中的所有数据,不论是文字、图片、视频、还是音频文件,本质上最终都是按照类似 01010101 的二进制存储的。 再说简单点,计算机只懂二进制数字! 所以,目的明确了:如何将我们能识别的符号唯一的与一组二进制数字对应上?于是美利坚的同志想到通过一个电平的高低状态来代指0或1, 八个电平做为一组就可以表示出 256种不同状态,每种状态就唯一对应一个字符,比如A--->00010001,而英文只有26个字符,算上一些特殊字符和数字,128个状态也够 用了;每个电平称为一个比特为,约定8个比特位构成一个字节,这样计算机就可以用127个不同字节来存储英语的文字了。这就是ASCII编码。 #扩展ANSI编码 刚才说了,最开始,一个字节有八位,但是最高位没用上,默认为0;后来为了计算机也可以表示拉丁文,就将最后一位也用上了, 从128到255的字符集对应拉丁文啦。至此,一个字节就用满了! //GB2312 计算机漂洋过海来到中国后,问题来了,计算机不认识中文,当然也没法显示中文;而且一个字节所有状态都被占满了,万恶的帝国主义亡 我之心不死啊!我党也是棒,自力更生,自己重写一张表,直接生猛地将扩展的第八位对应拉丁文全部删掉,规定一个小于127的字符的意 义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到0xF7,后面一个字节 (低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了;这种汉字方案叫做 “GB2312”。GB2312 是对 ASCII 的中文扩展。 //GBK 和 GB18030编码 但是汉字太多了,GB2312也不够用,于是规定:只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的 内容。结果扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。 //UNICODE编码: 很多其它国家都搞出自己的编码标准,彼此间却相互不支持。这就带来了很多问题。于是,国际标谁化组织为了统一编码:提出了标准编码准 则:UNICODE 。 UNICODE是用两个字节来表示为一个字符,它总共可以组合出65535不同的字符,这足以覆盖世界上所有符号(包括甲骨文) //utf8: unicode都一统天下了,为什么还要有一个utf8的编码呢? 大家想,对于英文世界的人们来讲,一个字节完全够了,比如要存储A,本来00010001就可以了,现在吃上了unicode的大锅饭, 得用两个字节:00000000 00010001才行,浪费太严重! 基于此,美利坚的科学家们提出了天才的想法:utf8. UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,它可以使用1~4个字节表示一个符号,根据 不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示,所以是兼容ASCII编码的。 这样显著的好处是,虽然在我们内存中的数据都是unicode,但当数据要保存到磁盘或者用于网络传输时,直接使用unicode就远不如utf8省空间啦! 这也是为什么utf8是我们的推荐编码方式。 Unicode与utf8的关系: 一言以蔽之:Unicode是内存编码表示方案(是规范),而UTF是如何保存和传输Unicode的方案(是实现)这也是UTF与Unicode的区别。
二、Python2编码
字节与字符
计算机存储的一切数据,文本字符、图片、视频、音频、软件都是由一串01的字节序列构成的,一个字节等于8个比特位。
而字符就是一个符号,比如一个汉字、一个英文字母、一个数字、一个标点都可以称为一个字符。
字节方便存储和网络传输,而字符用于显示,方便阅读。例如字符 "p" 存储到硬盘是一串二进制数据 01110000,占用一个字节的长度
编码与解码
我们用编辑器打开的文本,看到的一个个字符,最终保存在磁盘的时候都是以二进制字节序列形式存起来的。那么从字符到字节的转换过程就叫做编码(encode),反过来叫做解码(decode),两者是一个可逆的过程。编码是为了存储传输,解码是为了方便显示阅读。
例如字符 "p" 经过编码处理保存到硬盘是一串二进制字节序列 01110000 ,占用一个字节的长度。字符 "禅" 有可能是以 "11100111 10100110 10000101" 占用3个字节的长度存储,为什么说是有可能呢?这个放到后面再说。
Python 的编码为什么那么蛋疼?当然,这不能怪开发者。
这是因为 Python2 使用 ASCII 字符编码作为默认编码方式,而 ASCII 不能处理中文,那么为什么不用 UTf-8 呢?因为 Guido 老爹为 Python 编写第一行代码是在1989年的冬天,1991年2月正式开源发布了第一个版本,而 Unicode 是1991年10月发布的,也就是说 Python 这门语言创立的时候 UTF-8 还没诞生,这是其一。
Python 把字符串的类型还搞成两种,unicode 和 str ,以至于把开发者都弄糊涂了,这是其二。python3 彻底把 字符串重新改造了,只保留一种类型,这是后话,以后再说。
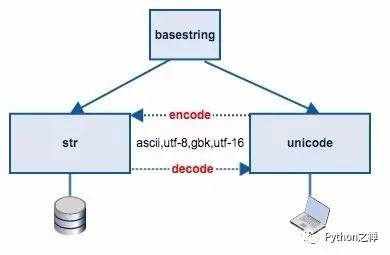
str与unicode
Python2 把字符串分为 unicode 和 str 两种类型。本质上 str 是一串二进制字节序列,下面的示例代码可以看出 str 类型的 "禅" 打印出来是十六进制的 \xe7\xa6\x85。
>>> s = '禅' >>> s '\xe7\xa6\x85' >>> type(s) <type 'str'>
而 unicode 类型的 u"禅" 对应的 unicode 符号是 u'\u7985'
>>> u = u"禅" >>> u u'\u7985' >>> type(u) <type 'unicode'>
我们要把 unicode 符号保存到文件或者传输到网络就需要经过编码处理转换成 str 类型,于是 python 提供了 encode 方法,从 unicode 转换到 str,反之亦然。
encode
>>> u = u"禅" >>> u u'\u7985' >>> u.encode("utf-8") '\xe7\xa6\x85'
decode
>>>'\xe7\xa6\x85'.decode("utf-8") u'\u7985'
不少初学者怎么也记不住 str 与 unicode 之间的转换用 encode 还是 decode,如果你记住了 str 本质上其实是一串二进制数据,而 unicode 是字符(符号),编码(encode)就是把字符(符号)转换为 二进制数据的过程,因此 unicode 到 str 的转换要用 encode 方法,反过来就是用 decode 方法。
encoding always takes a Unicode string and returns a bytes sequence, and decoding always takes a bytes sequence and returns a Unicode string".
清楚了 str 与 unicode 之间的转换关系之后,我们来看看什么时候会出现 UnicodeEncodeError、UnicodeDecodeError 错误。
UnicodeEncodeError
UnicodeEncodeError 发生在 unicode 字符串转换成 str 字节序列的时候,来看一个例子,把一串 unicode 字符串保存到文件
# -*- coding:utf-8 -*- def main(): name = u'Python之禅' f = open("output.txt", "w") #open这个函数在py2里和py3中是不同的,py3中有了一个encoding=None参数 f.write(name)
错误日志
UnicodeEncodeError: 'ascii' codec can't encode characters in position 6-7: ordinal not in range(128)

为什么会出现 UnicodeEncodeError?
因为调用 write 方法时,Python 会先判断字符串是什么类型,如果是 str,就直接写入文件,不需要编码,因为 str 类型的字符串本身就是一串二进制的字节序列了。
如果字符串是 unicode 类型,那么它会先调用 encode 方法把 unicode 字符串转换成二进制形式的 str 类型,才保存到文件,而 encode 方法会使用 python2 默认的 ascii 码来编码
相当于:
>>> u"Python之禅".encode("ascii")
但是,我们知道 ASCII 字符集中只包含了128个拉丁字母,不包括中文字符,因此 出现了 'ascii' codec can't encode characters 的错误。要正确地使用 encode ,就必须指定一个包含了中文字符的字符集,比如:UTF-8、GBK。
>>> u"Python之禅".encode("utf-8") 'Python\xe4\xb9\x8b\xe7\xa6\x85' >>> u"Python之禅".encode("gbk") 'Python\xd6\xae\xec\xf8'
所以要把 unicode 字符串正确地写入文件,就应该预先把字符串进行 UTF-8 或 GBK 编码转换。
def main(): name = u'Python之禅' name = name.encode('utf-8') with open("output.txt", "w") as f: f.write(name)
当然,把 unicode 字符串正确地写入文件不止一种方式,但原理是一样的,这里不再介绍,把字符串写入数据库,传输到网络都是同样的原理
UnicodeDecodeError
UnicodeDecodeError 发生在 str 类型的字节序列解码成 unicode 类型的字符串时
>>> a = u"禅" >>> a u'\u7985' >>> b = a.encode("utf-8") >>> b '\xe7\xa6\x85' >>> b.decode("gbk") Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'gbk' codec can't decode byte 0x85 in position 2: incomplete multibyte sequence
把一个经过 UTF-8 编码后生成的字节序列 '\xe7\xa6\x85' 再用 GBK 解码转换成 unicode 字符串时,出现 UnicodeDecodeError,因为 (对于中文字符)GBK 编码只占用两个字节,而 UTF-8 占用3个字节,用 GBK 转换时,还多出一个字节,因此它没法解析。避免 UnicodeDecodeError 的关键是保持 编码和解码时用的编码类型一致。
这也回答了文章开头说的字符 "禅",保存到文件中有可能占3个字节,有可能占2个字节,具体处决于 encode 的时候指定的编码格式是什么。
再举一个 UnicodeDecodeError 的例子
>>> x = u"Python" >>> y = "之禅" >>> x + y Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128) >>>
str 与 unicode 字符串 执行 + 操作时,Python 会把 str 类型的字节序列隐式地转换成(解码)成 和 x 一样的 unicode 类型,但Python是使用默认的 ascii 编码来转换的,而 ASCII字符集中不包含有中文,所以报错了。相当于:
>>> y.decode('ascii') Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
正确地方式应该是找到一种包含有中文字符的字符编码,比如 UTF-8或者 GBK 显示地把 y 进行解码转换成 unicode 类型
>>> x = u"Python" >>> y = "之禅" >>> y = y.decode("utf-8") >>> x + y u'Python\u4e4b\u7985'
以上内容都是基于 Python2 来讲的。
三、Python3编码
Python3 最重要的一项改进之一就是解决了 Python2 中字符串与字符编码遗留下来的这个大坑。 Python2 字符串设计上的一些缺陷:
- 使用 ASCII 码作为默认编码方式,对中文处理很不友好。
- 把字符串的牵强地分为 unicode 和 str 两种类型,误导开发者
#Python2 把系统默认编码设置为 ASCII C:\Users\Administrator>python2 Python 2.7.15 (v2.7.15:ca079a3ea3, Apr 30 2018, 16:30:26) [MSC v.1500 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import sys >>> sys.getdefaultencoding() 'ascii'
Python 3不再会对bytes字节串进行自动解码。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。
#print('alvin'+u'yuan')#字节串和unicode连接 py2:alvinyuan
print(b'alvin'+'yuan')#字节串和unicode连接 py3:报错 can't concat bytes to str
注意:无论py2,还是py3,与明文直接对应的就是unicode数据,打印unicode数据就会显示相应的明文(包括英文和中文)
当然这并不算 Bug,只要处理的时候多留心也可以避免这些坑。但在 Python3 两个问题都很好的解决了。
首先,Python3 把系统默认编码设置为 UTF-8
C:\Users\Administrator>python3 Python 3.6.5 (v3.6.5:f59c0932b4, Mar 28 2018, 16:07:46) [MSC v.1900 32 bit (Intel)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import sys >>> sys.getdefaultencoding() 'utf-8'
然后,文本字符和二进制数据区分得更清晰,分别用 str 和 bytes 表示。文本字符全部用 str 类型表示,str 能表示 Unicode 字符集中所有字符,而二进制字节数据用一种全新的数据类型,用 bytes 来表示。
str
>>> a = "a" >>> a 'a' >>> type(a) <class 'str'> >>> b = "禅" >>> b '禅' >>> type(b) <class 'str'>
bytes
Python3 中,在字符引号前加‘b’,明确表示这是一个 bytes 类型的对象,实际上它就是一组二进制字节序列组成的数据,bytes 类型可以是 ASCII范围内的字符和其它十六进制形式的字符数据,但不能用中文等非ASCII字符表示。
>>> c = b'a' >>> c b'a' >>> type(c) <class 'bytes'> >>> d = b'\xe7\xa6\x85' >>> d b'\xe7\xa6\x85' >>> type(d) <class 'bytes'> >>> >>> e = b'禅' File "<stdin>", line 1 SyntaxError: bytes can only contain ASCII literal characters.
bytes 类型提供的操作和 str 一样,支持分片、索引、基本数值运算等操作。但是 str 与 bytes 类型的数据不能执行 + 操作,尽管在py2中是可行的。
>>> b"a"+b"c" b'ac' >>> b"a"*2 b'aa' >>> b"abcdef\xd6"[1:] b'bcdef\xd6' >>> b"abcdef\xd6"[-1] 214 >>> b"a" + "b" Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: can't concat bytes to str
python2 与 python3 字节与字符的对应关系
| Python2 | Python3 | 表现 | 转换 | 作用 |
| str | bytes | 字节 | encode | 存储 |
| unicode | str | 字符 | decode | 显示 |
四、encode 与 decode
在python3中
str 与 bytes 之间的转换可以用 encode 和从decode 方法。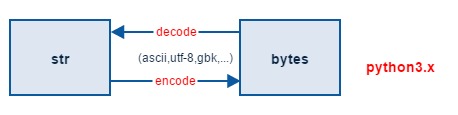
encode 负责字符到字节的编码转换。默认使用 UTF-8 编码转换。
>>> s = "Python之禅" >>> s.encode() #默认使用utf-8编码转换 b'Python\xe4\xb9\x8b\xe7\xa6\x85' >>> s.encode("gbk") #使用gbk编码转换 b'Python\xd6\xae\xec\xf8'
decode 负责字节到字符的解码转换,通用使用 UTF-8 编码格式进行转换。
>>> b'Python\xe4\xb9\x8b\xe7\xa6\x85'.decode() #默认使用utf-8解码转换 'Python之禅' >>> b'Python\xd6\xae\xec\xf8'.decode("gbk") #使用gbk解码转换 'Python之禅'
在python2中
encode的正常使用:对Unicode类型进行encode,得到字节串str类型。也即是Unicode-> encode(根据指定编码) -> str。
decode的正常使用:对str类型进行decode,得到Unicode类型。也即是str -> decode(根据指定编码) -> Unicode。
encode的不正常使用:对str类型进行encode,因为encode需要的是Unicode类型,这个时候python会用默认编码decode成Unicode类型,再用你给出编码进行encode。(注意这里默认编码不是开头的encoding,而是ASCII编码)
decode的不正常使用:对Unicode类型进行decode,python会用默认的系统编码encode成str类型,再用你给出的编码进行decode。
另外,需要注意的是,用什么字符编码对Unicode进行编码(编码为str类型),就要用对应的字符编码对str类型进行解码(解码为Unicode类型)。
举个不正常使用的例子:
# encoding:utf-8 import sys s = "中文" print(sys.getdefaultencoding()) print (s.encode('utf-8'))
报错
Traceback (most recent call last): File "D:/PythonProject/testProject/test_mem/111.py", line 6, in <module> y3 = s.encode("utf-8") UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128) ascii
上面的代码可以看出,python2的默认编码是ASCII编码,直接对str类型的变量s进行encode时,python会使用默认编码ASCII码将变量s先deconde成Unicode,而文件开头已经声明代码用utf-8编码,所以会报ASCII码无法decode字节“0xe4”,而“0xe4”是utf-8编码存储变量s=“中文”的第一个字节的十六进制表示。
这时候只要改变python的默认编码ASCII码为utf-8,就运行正常。
# encoding:utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') s = "中文" print(sys.getdefaultencoding()) print (s.encode('utf-8'))
另外需要注意的是,
"中文".decode("utf-8")这句话跟u“中文”效果是等价的。
再举个不正常使用的例子:
当我们对unicode类型的变量进行str装成str类型时,代码会报错
# encoding:utf-8 import sys s = u"中文" print(sys.getdefaultencoding()) print (str(s))
报错
Traceback (most recent call last): File "D:/PythonProject/testProject/test_mem/111.py", line 6, in <module> print (str(s)) UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128) ascii
这时候也是只要改变python的默认编码ASCII码为utf-8,就运行正常。
# encoding:utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') s = u"中文" print(sys.getdefaultencoding()) print (str(s))
或者如果不通过setdefaultencoding改变默认编码,这里也可以通过encode的时候指定编码就不会报错了
# encoding:utf-8 import sys s = u"中文" print(sys.getdefaultencoding()) print (s.encode("utf-8")) # 如果不通过setdefaultencoding改变默认编码,这里也可以通过encode的时候指定编码就不会报错了
五、文件从磁盘到内存的编码(******)
抛开执行执行程序,请问大家,文本编辑器大家都是用过吧,如果不懂是什么,那么word总用过吧,ok,当我们在word上编辑文字的时候,不管是中文还是英文,计算机都是不认识的,那么在保存之前数据是通过什么形式存在内存的呢?yes,就是unicode数据,为什么要存unicode数据,这是因为它的名字最屌:万国码!解释起来就是无论英文,中文,日文,拉丁文,世界上的任何字符它都有唯一编码对应,所以兼容性是最好的。
好,那当我们保存了存到磁盘上的数据又是什么呢?
答案是通过某种编码方式编码的bytes字节串。比如utf8---一种可变长编码,很好的节省了空间;当然还有历史产物的gbk编码等等。于是,在我们的文本编辑器软件都有默认的保存文件的编码方式,比如utf8,比如gbk。当我们点击保存的时候,这些编辑软件已经"默默地"帮我们做了编码工作。
那当我们再打开这个文件时,软件又默默地给我们做了解码的工作,将数据再解码成unicode,然后就可以呈现明文给用户了!所以,unicode是离用户更近的数据,bytes是离计算机更近的数据。
说了这么多,和我们程序执行有什么关系呢?
先明确一个概念:py解释器本身就是一个软件,一个类似于文本编辑器一样的软件!
现在让我们一起还原一个py文件从创建到执行的编码过程:
打开pycharm,创建hello.py文件,写入
s='苑昊' print(s)
当我们保存的的时候,hello.py文件就以pycharm默认的编码方式保存到了磁盘;关闭文件后再打开,pycharm就再以默认的编码方式对该文件打开后读到的内容进行解码,转成unicode到内存我们就看到了我们的明文;
而如果我们点击运行按钮或者在命令行运行该文件时,py解释器这个软件就会被调用,打开文件,然后解码存在磁盘上的bytes数据成unicode数据,这个过程和编辑器是一样的,不同的是解释器会再将这些unicode数据翻译成C代码再转成二进制的数据流,最后通过控制操作系统调用cpu来执行这些二进制数据,整个过程才算结束。
那么问题来了,我们的文本编辑器有自己默认的编码解码方式,我们的解释器有吗?
当然有啦,py2默认ASCII码,py3默认的utf8,可以通过如下方式查询
import sys print(sys.getdefaultencoding())
大家还记得这个声明吗?
#coding:utf8
是的,这就是因为如果py2解释器去执行一个utf8编码的文件,就会以默认地ASCII去解码utf8,一旦程序中有中文,自然就解码错误了,所以我们在文件开头位置声明 #coding:utf8,其实就是告诉解释器,你不要以默认的编码方式去解码这个文件,而是以utf8来解码。而py3的解释器因为默认utf8编码,所以就方便很多了。
六、常见的编码问题
乱码的终极原因就是:对同一个字符串的 encode 和 decode 编码格式不一致。
1 cmd下的乱码问题
hello.py
#coding:utf8 print ('中国')
文件保存时的编码也为utf8。
思考:为什么在IDE下用2或3执行都没问题,在cmd.exe下3正确,2乱码呢?
我们在win下的终端即cmd.exe去执行,大家注意,cmd.exe本身也一个软件;当我们python2 hello.py时,python2解释器(默认ASCII编码)去按声明的utf8编码文件,而文件又是utf8保存的,所以没问题;问题出在当我们print('中国')时,解释器这边正常执行,也不会报错,只是print的内容会传递给cmd.exe用来显示,而在py2里这个内容就是utf8编码的字节数据,可这个软件默认的编码解码方式是GBK,所以cmd.exe用GBK的解码方式去解码utf8自然会乱码。
py3正确的原因是传递给cmd的是unicode数据,cmd.exe可以识别内容,所以显示没问题。
明白原理了,修改就有很多方式,比如:
print (u'中国')
改成Unicode类型编码后,cmd下用2也不会有问题了。
总之一句话:对于任何Unicode类型编码的字符,打印时python会自动根据环境编码转为特定编码后再显示
2 open()中的编码问题
创建一个hello文本,保存成utf8:
我爱中国
同目录下创建一个index.py
f=open('hello') print(f.read())
为什么 在linux下,结果正常:我爱中国,在win下,乱码:鑻戞槉(py3解释器)?
因为你的win的操作系统安装时是默认的gbk编码,而linux操作系统默认的是utf8编码;
当执行open函数时,调用的是操作系统打开文件,操作系统用默认的gbk编码去解码utf8的文件,自然乱码。
解决办法:
f=open('hello',encoding='utf8') print(f.read())
如果你的文件保存的是gbk编码,在win 下就不用指定encoding了。
另外,如果你的win上不需要指定给操作系统encoding='utf8',那就是你安装时就是默认的utf8编码或者已经通过命令修改成了utf8编码。
注意:open这个函数在py2里和py3中是不同的,py3中有了一个encoding=None参数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号