STL学习总结
前言
STL 主要由容器类、迭代器和算法组成。容器类相当于数据结构,算法用于操作数据结构中的数据,而迭代器则是它们之间的一个桥梁。STL 各组成部分的关系如图所示。

STL 中的所有东西都是基于模板的,它们适用于很多数据类型。大量使用模板并不会降低程序的性能,因为对模板的解释在编译期就已经完成了。
一、容器类
容器主要有三种类型:序列容器类,有序关联容器类以及无序关联容器类。
1.所有容器的共同操作
下列为所有容器类(以及 string 类)的共通操作:
-
equality(==)和 inequality((! =)运算符,返回 true 或 false。
-
assignment(=)运算符,将某个容器复制给另一个容器。
-
empty()会在容器无任何元素时返回 true,否则返回 false。
-
size()返回容器内目前持有的元素个数。
-
clear()删除所有元素。
以下函数实际演练了上述操作:
void comp(vector<int> &vl, vector<int> &v2)
{
//两个 vector 是否相等
if (v1 == v2)
return;
//两个vector之中是否有一个为空
if (v1.empty()||v2.empty())
return;
//当我们要使用变量(对象)时,オ加以定义
vector<int> t;
// 将较大的vector赋值给
t = v1.size > v2.size() ? v1 : v2;
//...使用t..
// 清除t的元素,让t变成空。此后t.empty()会返回true,
//t.size()会返回0。
t.clear();
//... 填充 t,继续使用。
}
每个容器都提供了 begin()和 end()两个函数,分返回指向容器的第一个元素和最后一个元素的下一位置的 iterator;
-
begin()返回一个 Iterator,指向容器的第一个元素。
-
end() 返回一个 Iterator,指向容器的最后一个元素的下一位置。
通常我们在容器身上进行的迭代操作都是始于 begin()而终于 end()。所有容器都提供 insert()用以插入元素,以及 erase()用以删除元素。
-
insert()将单一或某个范围内的元素插入容器内。
-
erase()将容器内的单一元素或某个范围内的元素删除。
insert()和 erase()的行为视容器本身为顺序性(sequential)容器或关联(associative)容器而有所不同。
以下表格是为所有容器定义的操作
| 表达式 | 返回类型 | 说明 | 复杂度 |
|---|---|---|---|
| X u | 创建一个名为 u 的空对象 | 固定 | |
| X() | 创建一个匿名的空对象 | 固定 | |
| X (a) | 创建对象 x 的拷贝 | 线性 | |
| X u(a) | u 是 a 的拷贝(复制构造函数) | 线性 | |
| X u= a | u 是 a 的拷贝(复制构造函数) | 线性 | |
| r = a | X& | r 等于 a 的值(复制赋值) | 线性 |
| X u(rv) ,c++11新增 | u 等于 rv 的原始值(移动构造函数) | 线性 | |
| X u=rv ,c++11新增 | u等于 rv 的原始值(移动构造函数) | ||
| a=rv ,c++11新增 | X& | u等于 rv 的原始值(移动赋值) | 线性 |
| (&a) -> ~X() | void | 对 a 的每个元素执行析构函数 | |
| begin() | 迭代器 | 返回一个指向第一个元素的迭代器 | 固定 |
| end() | 迭代器 | 返回一个指向超尾的迭代器 | 固定 |
| cbegin() ,c++11新增 | const_iterator | 返回一个指向第一个元素的 const 迭代器 | 固定 |
| cend() ,c++11新增 | const_iterator | 返回一个指向超尾的 const 迭代器 | 固定 |
| size() | 无符号整型 | 返回元素数目 | 固定 |
| maxsize() | 无符号整型 | 返回容器的最大可能长度 | |
| empty() | bool | 如果容器为空,则返回 true | |
| swap() | void | 交换两个容器的内容 | 固定 |
| == | bool | 如果两个容器的长度相同、包含的元素相同且元素排列的顺序相同,则返回 true | 线性 |
| != | bool | a!=b 返回!(a==b) | 线性 |
使用双向或随机迭代器的容器(vector, list, deque、array, set和map)是可反转的,它们提供了下表所示的方法。
以下表格是为可反转容器定义的操作
| 表达式 | 返回类型 | 说明 | 复杂度 |
|---|---|---|---|
| X::reverse iterator | 指向类型T的反向迭代器 | ||
| X::const reverse iterator | 指向类型T的const反向迭代器 | ||
| a.rbegin() | 返回一个反向迭代器,指向a的超尾 | ||
| a.rend() | 返回一个指向a的开头的反向迭代器 | ||
| a.crbegin() | 返回一个const反向迭代器,指向a的超尾 | ||
| a.crend() | 返回一个指向a的开头的const反向迭代器 |
2.序列容器
- vector:内部数据结构是动态数组,随机访问性能好
- list:内部数据结构是双向链表,快速插入与删除,不支持数组表示法和随机访问
- queue:是一个适配器类,底层类是deque,不支持随机访问和遍历队列
- deque:双向队列,与vector类似,支持随机访问
- priority_queue:是一个适配器类,底层类是vector,支持的操作跟queue相同,区别是priority_queue中最大的元素被移到队首,
- stack:是一个适配器类,底层类是vector,不支持随机访问栈元素和遍历栈
- forward_list(c++11新增):内部数据结构是单向链表;不可双向遍历,只能从前到后地遍历;其它的特性同 list
- array(c++11新增):
详细介绍这7种序列容器类型:
(1) vector
头文件:
#include<vector>
vector是数组的一种类表示,它提供了自动内存管理功能,可以动态地改变vector对象的长度,并随着元素的添加和删除而增大和缩小。它提供了对元素的随机访问。在尾部添加和删除元素的时问是固定的,但在头部或中间插入和删除元素的复杂度为线性时间。
除序列外,vector还是可反转容器( reversible container)概念的模型。这增加了两个类方法:rbegin()和rend(),前者返回一个指向反转序列的第一个元素的迭代器,后者返回反转序列的超尾迭代器。因此,如果dice是一个vector<int>容器,而Show(int)是显示一个整数的函数,则下面的代码将首先正向显示dice的内容,然后反向显示:
for_each(dice.begin(), dice.end(), Show);
cout << endl;
for_each(dice.rbegin(), dice.rend(), Show);
cout << endl;
(2) list
头文件:
#include<list>
list容器表示双向链表。除了第一个和最后一个元素外,每个元素都与前后的元素相链接,这意味着可以双向遍历链表。list和vector之间关键的区别在于,list在链表中任一位置进行插入和删除的时间都是固定的(vector模板提供了除结尾处外的线性时间的插入和删除,在结尾处,它提供了固定时间的插入和删除)。因此,vector强调的是通过随机访问进行快速访问,而list强调的是元素的快速插入和删除。
与vector相似,list也是可反转容器。与vector不同的是,list不支持数组表示法和随机访问。与矢量迭代器不同,从容器中插入或删除元素之后,链表迭代器指向元素将不变。我们来解释一下这句话。例如,假设有一个指向vector容器第5个元素的迭代器,并在容器的起始处插入一个元素。此时,必须移动其他所有元素,以便腾出位置,因此插入后,第5个元索包含的值将是以前第4个元素的值。因此,迭代器指向的位置不变,但数据不同。然后,在链表中插入新元素并不会移动已有的元素,而只是修改链接信息。指向某个元素的迭代器仍然指向该元素,但它链接的元素可能与以前不同。
除序列和可反转容器的函数外,list模板类还包含了链表专用的成员函数。下表列出了其中一些(有关STL方法和函数的完整列表)。通常不必担心Alloc模板参数,因为它有默认值。

程序演示了这些方法和insert()方法(所有模拟序列的STL类都有这种方法)的用法。
#include <iostream>
#include <list>
#include <iterator>
#include <algorithm>
void outint(int n) {std::cout << n << " ";}
int main()
{
using namespace std;
list<int> one(5, 2); // list of 5 2s
int stuff[5] = {1,2,4,8, 6};
list<int> two;
two.insert(two.begin(),stuff, stuff + 5 );
int more[6] = {6, 4, 2, 4, 6, 5};
list<int> three(two);
three.insert(three.end(), more, more + 6);
cout << "List one: ";
for_each(one.begin(),one.end(), outint);
cout << endl << "List two: ";
for_each(two.begin(), two.end(), outint);
cout << endl << "List three: ";
for_each(three.begin(), three.end(), outint);
three.remove(2);
cout << endl << "List three minus 2s: ";
for_each(three.begin(), three.end(), outint);
three.splice(three.begin(), one);
cout << endl << "List three after splice: ";
for_each(three.begin(), three.end(), outint);
cout << endl << "List one: ";
for_each(one.begin(), one.end(), outint);
three.unique();
cout << endl << "List three after unique: ";
for_each(three.begin(), three.end(), outint);
three.sort();
three.unique();
cout << endl << "List three after sort & unique: ";
for_each(three.begin(), three.end(), outint);
two.sort();
three.merge(two);
cout << endl << "Sorted two merged into three: ";
for_each(three.begin(), three.end(), outint);
cout << endl;
// cin.get();
return 0;
}
输出:
List one: 2 2 2 2 2
List two: 1 2 4 8 6
List three: 1 2 4 8 6 6 4 2 4 6 5
List three minus 2s: 1 4 8 6 6 4 4 6 5
List three after splice: 2 2 2 2 2 1 4 8 6 6 4 4 6 5
List one:
List three after unique: 2 1 4 8 6 4 6 5
List three after sort & unique: 1 2 4 5 6 8
Sorted two merged into three: 1 1 2 2 4 4 5 6 6 8 8
程序说明:
insert()和splice()之间的主要区别在于:insert()将原始区间的副本插入到目标地址,而splice()则将原始区间移到目标地址。因此,在one的内容与three合并后,one为空。( splice()方法还有其他原型,用于移动单个元素和元素区间)。splice()方法执行后,迭代器仍有效。也就是说,如果将迭代器设置为指向one中的元素,则在splice()将它重新定位到元素three后,该迭代器仍然指向相同的元素。
注意,unique()只能将相邻的相同值压缩为单个值。程序执行three.unique( )后,three中仍包含不相邻的两个4和两个6。但应用sortt()后再应用unique()时,每个值将只占一个位置。
还有非成员sort()函数,但它需要随机访问迭代器。因为快速插入的代价是放弃随机访问功能,所以不能将非成员函数sort()用于链表。因此,这个类中包括了一个只能在类中使用的成员版本。
list工具箱
list方法组成了一个方便的工具箱。例如,假设有两个邮件列表要整理,则可以对每个列表进行排序,合并它们,然后使用unique()来删除重复的元素。
sort( ), merge()和unique()方法还各自拥有接受另一个参数的版本,该参数用于指定用来比较元素的函数。同样,remove()方法也有一个接受另一个参数的版本,该参数用于指定用来确定是否删除元素的函数。这些参数都是谓词函数。
(3) forward_list(c++11新增)
头文件:
#include<forward_list>
C++ 11新增了容器类forward_ list,它实现了单链表。在这种链表中,每个节点都只链接到下一个节点,而没有链接到前一个节点。因此forward list只需要正向迭代器,而不需要双向迭代器。因此,不同于vector和list, forward_ list是不可反转的容器。相比于list,forward_list更简单、更紧凑,但功能也更少。
(4) deque
头文件:
#include<deque>
deque容器是一个双端队列,在STL中,其实现类似于vector容器,支持随机访问。主要区别在于,从deque对象的开始位置插入和删除元素的时间是固定的,而不像vector中那样是线性时间的。所以,如果多数操作发生在序列的起始和结尾处,则应考虑使用deque数据结构。
为实现在deque两端执行插入和删除操作的时间为固定的这一目的,deque对象的设计比vector对象更为复杂。因此,尽管二者都提供对元素的随机访问和在序列中部执行线性时间的插入和删除操作,但vector容器执行这些操作时速度要快些。
(5) queue
头文件:
#include<queue>
queue是一个适配器类,让底层类(默认为deque)展示典型的队列接口,queue模板的限制比deque更多。它不仅不允许随机访问队列元素,甚至不允许遍历队列。它把使用限制在定义队列的基本操作上,可以将元素添加到队尾、从队首删除元素、查看队首和队尾的值、检查元素数目和测试队列是否为空。下表列出了这些操作。
(6) priority_queue
头文件:
#include<queue>
priority_queue也是一个适配器,它支持的操作与queue相同。两者之间的主要区别在于,在priority_queue中,最大的元素被移到队首(生活不总是公平的,队列也一样)。内部区别在于,默认的底层类是vector。可以修改用于确定哪个元素放到队首的比较方式,方法是提供一个可选的构造函数参数:
priority_queue<int> pq1; // default version
priority_queue<int> pq2(greater<int>); // use greater<int> to order
(7) stack
头文件:
#include<stack>
与queue相似,stack也是一个适配器类,它给底层类(默认情况下为vector)提供了典型的栈接口。
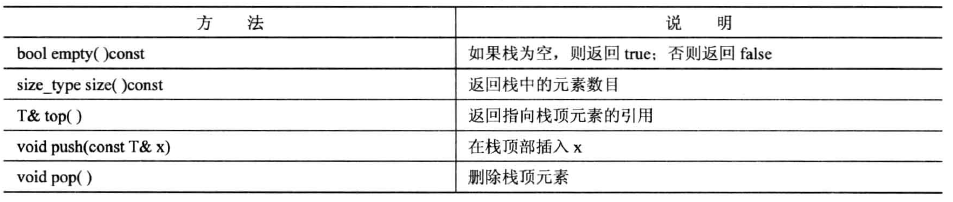
stack模板的限制比vector更多。它不仅不允许随机访问栈元素,甚至不允许遍历栈。它把使用限制在定义栈的基本操作上,即可以将压入推到栈顶、从栈顶弹出元素、查看栈顶的值、检查元素数目和测试栈是否为空。下表列出了这些操作。

与queue相似,如果要使用栈中的值,必须首先使用top()来检索这个值,然后使用pop()将它从栈中删除。
(8) array(c++11新增)
头文件:
#include<array>
模板类array是否头文件array中定义的,它并非STL容器,因为其长度是固定的。因此,array没有定义调整容器大小的操作,如push_ back()和insert( ),但定义了对它来说有意义的成员函数,如operator 和at( )。可将很多标准STL算法用于array对象,如copy()和for_each()。
array对象的长度是固定的,因此无法使用众多序列方法。下表列出除array外的.序列容器可用的其他方法(forward_ list的resize()方法的定义稍有不同)。同样,其中X是容器类型,如vector
| 操作 | 说明 |
|---|---|
| X(n,t) | 创建一个序列容器,它包含t的n个拷贝 |
| X a(n, t) | 创建一个名为a的序列容器,它包含t的n个拷贝 |
| X( i, j) | 使用区间[i, j)内的值创建一个序列容器 |
| X a( i, j) | 使用区间[i, j)内的值创建一个名为a的序列容器 |
| X(il) | 创建一个序列容器,井将其初始化为il的内容 |
| a=il | 将il的复制到a中 |
| a.emplace(p, args) | 在p前面插入一个类型为T的对象,创建该对象时使用与args封装的参数匹配的构造函数 |
| a. insert(p, t) | 在p之前插入t的拷贝,并返回指向该拷贝的迭代器。T的默认值为T(),即在没有显式初始化时,用于T类型的值 |
| a.insert(p, rv) | 在p之前插入rv的拷贝,并返回指向该拷贝的迭代器;可能使用移动语义 |
| a.insert(p, n, t) | 在p之前插入t的n个拷贝 |
| a.insert(p, i, j) | 在p之前插入[i, j)区间内元素的拷贝 |
| a.insert(p, il) | 等价于a.insert(p, il.begin(),il.end()) |
| a.resize(n) | 如果n > a.size(),则在a.end()之前插入n-a.size() 个元素 ;用于新元素的值为没有显式初始化时,用于T类型的值;如果n < a.size( ),则删除第n个元素之后的所有元素 |
| a.resize(n,t) | 如果n > a.size(),则在a.end()之前插入t的n-a.size()个拷贝:如果n < a.size( ),则删除第n个元素 之后的所有元索 |
| a.assign(i,j) | 使用区间[i, j)内的元素拷贝并替换a当前的内容 |
| a.assign(n,t) | 使用t的n个拷贝替换a的当前内容。t的默认值为T(),即在没有显式初始化时,用于T类型的值 |
| a. assign(il) | 等价于a.assign(il.begin(),il.end())) |
| a.erase(q) | 删除q指向的元索;返回一个指向q后面的元素的迭代器 |
| a.erase(q1,q2) | 删除区间[q1, q2]内的元素;返回一个迭代器,该迭代器指向q2原来指向的元素 |
| a.clear() | erase(a.begin(),a. end())等效 |
| a. front() | 返回*a.begin()(第一个元素) |
下表列出了一些序列类(vector, forward_ list, list和deque)都有的方法。
| 操作 | 说明 | 容器 |
|---|---|---|
| a. back() | 返回*a.end()(最后一个元素) | vector、list、deque |
| a.push_back(t) | 将t插入到a.end()前面 | vector、list、deque |
| a.push_back(rv) | 将rv插入到a.end()前面;可能使用移动语义 | vector、list、deque |
| a.pop_back() | 删除最后一个元素 | vector、list、deque |
| a.emplace_back(args) | 追加一个类型为T的对象,创建该对象时使用与args封装的参数匹配的构造函数 | vector、list、deque |
| a.push_front(t) | 将t的拷贝插入到第一个元素面前 | forward_ list、list、deque |
| a.push_front(rv) | 将rv的拷贝插入到第一个元素前面;可能使用移动语义 | forward_ list、list、deque |
| a .emplace_ front() | 在最前面插入一个类型为T的对象,创建该对象时使用与args封装的参数匹配的构造函数 | forward_ list、list、deque |
| a.pop_front() | 删除第一个元素 | forward_ list、list |
| a[n] | 返回*(a.begin( )+ n) | vector、deque、array |
| a. at(n) | 返回*(a.begin( )+ n);如果n>a.size,则引发out_ of_range异常 | vector、deque、array |
模板vector还包含下表列出vector的其他操作。其中,a是vector容器,n是x::size_type型整数。
vector的其他操作
| 操作 | 说明 |
|---|---|
| a. capacity() | 返回在不要求重新分配内存的情况下,矢量能存储的元素总量 |
| a.reserve(n) | 提醒a对象:至少需要存储n个元素的内存。调用该方法后,容量至少为n个元素。如果n大于当前的容量,则需要重新分配内存。如果n大于a.max_ size() ,该方法将引发length_error异常 |
list模板还包含下表其他的方法。其中,a和b是list容器;T是存储在链表中的类型,如int; t是类型为T的值;i和j是输入迭代器;q2和p是迭代器;q和q1是可解除引用的迭代器;n是x::size_type型整数。该表使用了标准的STL表示法[i,j),这指的是从i到j(不包括j)的区间。
list的其他操作
| 操作 | 说明 |
|---|---|
| a.splice(p, b) | 将链表b的内容移到链表a中,并将它们插在p之前 |
| a.splice(p, b, i) | 将i指向的链表b中的元素移到链表a的p位置之前 |
| a.splice(p, b, i,j) | 将链表b中[i, j)区间内的元素移到链表a的p位置之前 |
| a .remove(const T& t) | 删除链表a中值为t的所有元素 |
| a.remove_if(Predicate pred) | 如果i是指向链表a中元素的迭代器,则删除pred(*i)为true的所有值(Predicate是布尔值函数或函数对象) |
| a.unique() | 删除连续的相同元素组中除第一个元索之外的所有元素 |
| a.unique(BinaryPredicate bin_pred) | 删除连续的bin_pred(*i, *(i-1))为true的元素组中除第一个元素之外的所有元素( BinaryPredicate是布尔值函数或函数对象) |
| a .merge(b) | 使用为值类型定义的<运算符,将链表b与链表a的内容合并。如果链表a的某个元素与链表b的某个元素相同,则a中的元素将放在前而。合并后,链表b为空 |
| a.merge(b, Compare comp) | 使用comp函数或函数对象将链表b与链表a的内容合并。如果链表a的某个元素与链表b的某个元素相同,则链表a中的元素将放在前面。合并后,链表b为空 |
| a.sort() | 使用<运算符对链表a进行排序 |
| a.sort(Compare comp) | 使用comp函数或函数对象对链表a进行排序 |
| a.reverse() | 将链表a中的元素顺序反转 |
forward_ list的操作与此类似,但由于模板类forward_list的迭代器不能后移,有些方法必须调整。因此,用insert_after(). erase_after()和spice after( )替代了insert( )、erase()和splice( ),这些方法都对迭代器后面而不是前面的元素进行操作。
序列容器小结
-
(1)如果容器只需要支持随机访问和只往尾部插入或删除元素,则一般使用vector;如果容器需要支持任意位置插入或删除元素,不要求能随机访问,则一般使用list;vector强调的是通过随机访问进行快速访问,而list强调的是元素的快速插入和删除。
-
(2)支持随机访问的容器:vector,deque,array;不支持随机访问的容器:list,stack,forward_list,queue,priority_queue。
3.有序关联容器
有序关联容器使用某种树实现,相对于链表,查找速度更快
- map:值的类型与键可以不一致,键是唯一的,每个键只对应一个值;
- multimap:值的类型与键可以不一致,键是唯一的,每个键可以与多个值相关联;
- set:值的类型与键一致,值就是键,键是唯一的
- multiset:值的类型与键一致,键可以重复
有序关联容器的优点在于,它提供了对元素的快速访问。与序列相似,关联容器也允许插入新元素,但不能指定元素的插入位置。原因是关联容器通常有用于确定数据放置位置的算法,以便能够快速检索信息。
STL提供了4种有序关联容器:set,multiset. map和multimap。前两种是在头文件set(以前分别为set.h和multiset.h)中定义的,而后两种是在头文件map(以前分别为map.h和multimap.h)中定义的。
最简单的关联容器是set,其值类型与键相同,键是唯一的,这意味着集合中不会有多个相同的键。确实对于set来说,值就是键。multiset类似于set,只是可能有多个值的键相同。例如,如果键和值的类型为int,则multiset对象包含的内容可以是1、2、2、2、3、5、7、7。
在map中,值与键的类型不同,键是唯一的,每个键只对应一个值。multimap与map相似,只是一个键可以与多个值相关联。
有序关联容器(集合和映射是这种容器的模型)带有模板参数Key和Compare,这两个参数分别表示用来对内容进行排序的键类型和用于对键值进行比较的函数对象(被称为比较对象)。对于set和multiset容器,存储的键就是存储的值,因此键类型与值类型相同。对于map和multimap容器,存储的值(模板参数T>与键类型(模板参数Key)相关联,值类型为pair<const Key, T>。关联容器有其他成员来描述这些特性.
为关联容器定义的类型
| 类型 | 值 |
|---|---|
| X::key_type | Key,键类型 |
| X::key_compare | Compare,默认为less<key_type> |
| X::value_compare | 二元谓词类型,与set和multiset的key_compare相同,为map或multimap容器中的pair<const Key, T>值提供了排序功能 |
| x::mapped_type | T,关联数据类型(仅限于map和multimap) |
关联容器提供了下表的方法。通常,比较对象不要求键相同的值是相同的;等价键(equivalentkey)意味着两个值(可能相同,也可能不同)的键相同。在该表中,X为容器类,a是类型为X的对象。如果X使用唯一键(即为set或map,则a_uniq将是类烈为X的对象。如果X使用多个键(即为multiset或multimap,则a_eq将是类型为X的对象。和前而一样,i和j也是指向value_type元素的输入迭代器,[i, j]是一个有效的区间,p和q2是指向a的迭代器,q和q1是指向a的可解除引用的迭代器,[q1, q2]是有效区间, t是X::value_type值(可能是一对),k是X::key_ type值,而il是initializer_list<value_type>对象。
为set、multiset、map和multimap定义的操作
| 操作 | 说明 |
|---|---|
| X(i, j, c) | 创建一个空容器,插入区间[i, j)中的元素,并将c用作比较对象 |
| X a(i, j, c) | 创建一个名为a的空容器,插入区间[i, j)中的元素,并将c用作比较对象 |
| X(i, j) | 创建一个空容器,插入区间[i, j)中的元素,并将Compare()用作比较对象 |
| X a(i, j) | 创建一个名为a的空容器,插入区间[i, j)的元素,并将Compare()用作比较对象 |
| X(il) | 等价于X(il.begin( ), il.end( )) |
| a=1 | 将区间[il.begin( ), il.end( )]的内容赋给a |
| a.key_comp() | 返回在构造a时使用的比较对象 |
| a.value_comp() | 返回一个value_compare对象 |
| a_uniq.insert(t) | 当且仅当a不包含具有相同键的值时,将t值插入到容器a中。该方法返回一个pair<iterator, bool>值。如果进行了插入,则bool的值为true,否则为false。iterator指向键与t相同的元素 |
| a_eq.insert(t) | 插入t并返回一个指向其位置的迭代器 |
| a.insert(p, t) | 将P作为inset()开始搜索的位置,将t插入。如果a是键唯一的容器,则当且仅当a不包含拥有相同键的元素时,才插入;否则,将进行插入。无沦是否进行了插入,该方法都将返回一个迭代器,该迭代器指向拥有相同键的位置 |
| a. insert(i, j) | 将区间[i, j)中的元素插入到a中 |
| a. insert(il) | 将initializer_list il中的元素插入到a中 |
| a_uniq.emplace(args) | 类似于 a_uniq.insert(t),但使用参数列表与参数包args的内容匹配的构造函数 |
| a_eq.emplace(args) | 类似于a_eq.insert(t),但使用参数列表与参数包args的内容匹配的构造函数 |
| a.emplace_hint(args) | 类似于a.insert(p, t) ,但使用参数列表与参数包args的内容匹配的构造函数 |
| a.erase(k) | 删除a中键与k相同的所有元索,并返回删除的元素数目 |
| a.erase(q) | 删除q指向的元素 |
| a.erase(ql, q2) | 删除区间[q1, q2)中的元素 |
| a.clear() | 与erase(a.begin(),a.end())等效 |
| a.find(k) | 返回一个迭代器,该迭代器指向键与k相同的元素;如果没有找到这样的元素,则返回a.end( ) |
| a.count(k) | 返回键与k相同的元素的数量 |
| a.lower_bound(k) | 返回一个迭代器,该迭代器指向第一个键不小于k的元索 |
| a.upper_bound(k) | 返回一个迭代器,该迭代器指向第一个键大于k的元索 |
| a.equal_range(k) | 返回第一个成员为a.lower_bound(k),第二个成员为a.upper_bound(k)的值对 |
| a. operator[ ](k) | 返回一个引用,该引用指向与键k关联的值(仅限于map容器) |
方法运用:
(1)set实例
#include <iostream>
#include <string>
#include <set>
#include <algorithm>
#include <iterator>
int main()
{
using namespace std;
const int N = 6;
string s1[N] = {"buffoon", "thinkers", "for", "heavy", "can", "for"};
string s2[N] = {"metal", "any", "food", "elegant", "deliver","for"};
set<string> A(s1, s1 + N);
set<string> B(s2, s2 + N);
ostream_iterator<string, char> out(cout, " ");
cout << "Set A: ";
copy(A.begin(), A.end(), out);
cout << endl;
cout << "Set B: ";
copy(B.begin(), B.end(), out);
cout << endl;
cout << "Union of A and B:\n";
set_union(A.begin(), A.end(), B.begin(), B.end(), out);
cout << endl;
cout << "Intersection of A and B:\n";
set_intersection(A.begin(), A.end(), B.begin(), B.end(), out);
cout << endl;
cout << "Difference of A and B:\n";
set_difference(A.begin(), A.end(), B.begin(), B.end(), out);
cout << endl;
set<string> C;
cout << "Set C:\n";
set_union(A.begin(), A.end(), B.begin(), B.end(),
insert_iterator<set<string> >(C, C.begin()));
copy(C.begin(), C.end(), out);
cout << endl;
string s3("grungy");
C.insert(s3);
cout << "Set C after insertion:\n";
copy(C.begin(), C.end(),out);
cout << endl;
cout << "Showing a range:\n";
copy(C.lower_bound("ghost"),C.upper_bound("spook"), out);
cout << endl;
// cin.get();
return 0;
}
输出:
Set A: buffoon can for heavy thinkers
Set B: any deliver elegant food for metal
Union of A and B:
any buffoon can deliver elegant food for heavy metal thinkers
Intersection of A and B:
for
Difference of A and B:
buffoon can heavy thinkers
Set C:
any buffoon can deliver elegant food for heavy metal thinkers
Set C after insertion:
any buffoon can deliver elegant food for grungy heavy metal thinkers
Showing a range:
grungy heavy metal
(2)multimap实例
与set相似,multimap也是可反转的、经过排序的关联容器,但键和值的类型不同,一且同一个键可能与多个值相关联。
基本的multimap声明使用模板参数指定键的类型和存储的值类型。例如,下面的声明创建一个multimap对象,其中键类型为int,存储的值类型为string:
multimap<int,string>codes;
为将信息结合在一起,实际的值类型将键类型和数据类型结合为一对。为此,STL使用模板类pair<class T, class U>将这两种值存储到一个对象中。如果keytype是键类型,而datatype是存储的数据类型,则值类型为pair<const keytype, datatype>。例如,前面声明的codes对象的值类型为pair<const int, string>。
例如,假设要用区号作为键来存储城市名(这恰好与codes声明一致,它将键类型声明为int,数据类型声明为string,则一种方法是创建一个pair,再将它插入:
multimap<int,string>codes;
pair<const int,string>item(213,”Los Angeles”);
codes.insert(item);
也可使用一条语句创建匿名pair对象并将它插入:
codes.insert(pair<const int,string>(213,”Los Angeles”);
因为数据项是按键排序的,所以不需要指出插入位置。
对于pair对象,可以使用first和second成员来访问其两个部分了:
pair<const int,string>item(213,”Los Angeles”);
cout << item.first << ' ' << item.second << endl;
如何获得有关multimap对象的信息呢?成员函数count()接受键作为参数,并返回具有该键的元素数目。成员函数lower_bound()和upper_bound()将键作为参数,且工作原理与处理set时相同。成员函数equal_range()用键作为参数,且返回两个迭代器,它们表示的区间与该键匹配。为返回两个值,该方法将它们封装在一个pair对象中,这里pair的两个模板参数都是迭代器。例如,下面的代码打印codes对象中区号为718的所有城市:
pair<multimap<KeyType, string> iterator,
multimap<KeyType, string> iterator> range = codes.equal_range(718);
cout << "Cities with area code 718:\n";
std::multimap<KeyType, string>::iterator it;
for (it = range.first; it != range.second; ++it)
cout << (*it).second << endl;
在声明中可使用c++11自动类型推断功能,这样代码将简化为如下所示:
auto range = codes.equal_range(718);
cout << "Cities with area code 718:\n";
std::multimap<KeyType, string>::iterator it;
for (auto it = range.first; it != range.second; ++it)
cout << (*it).second << endl;
以下程序演示了上述大部分技术,它也使用typedef来简化代码:
// multmap.cpp -- use a multimap
#include <iostream>
#include <string>
#include <map>
#include <algorithm>
typedef int KeyType;
typedef std::pair<const KeyType, std::string> Pair;
typedef std::multimap<KeyType, std::string> MapCode;
int main()
{
using namespace std;
MapCode codes;
codes.insert(Pair(415, "San Francisco"));
codes.insert(Pair(510, "Oakland"));
codes.insert(Pair(718, "Brooklyn"));
codes.insert(Pair(718, "Staten Island"));
codes.insert(Pair(415, "San Rafael"));
codes.insert(Pair(510, "Berkeley"));
cout << "Number of cities with area code 415: "
<< codes.count(415) << endl;
cout << "Number of cities with area code 718: "
<< codes.count(718) << endl;
cout << "Number of cities with area code 510: "
<< codes.count(510) << endl;
cout << "Area Code City\n";
MapCode::iterator it;
for (it = codes.begin(); it != codes.end(); ++it)
cout << " " << (*it).first << " "
<< (*it).second << endl;
pair<MapCode::iterator, MapCode::iterator>
auto range = codes.equal_range(718);
cout << "Cities with area code 718:\n";
for (it = range.first; it != range.second; ++it)
cout << (*it).second << endl;
// cin.get();
return 0;
}
输出:
Number of cities with area code 415: 2
Number of cities with area code 718: 2
Number of cities with area code 510: 2
Area Code City
415 San Francisco
415 San Rafael
510 Oakland
510 Berkeley
718 Brooklyn
718 Staten Island
Cities with area code 718:
Brooklyn
Staten Island
4.无序关联容器
无序关联容器是基于数据结构哈希表的,相比有序关联容器,目的提高添加和删除元素的速度以及提高查找算法的效率。
- unordered_set
- unordered_multiset
- unordered_map
- unordered_multimap
无序关联容器的接口类似于关联容器。具体地说,表也适用于无序关联容器,但存在如下例外:不需要方法lower bound()和upper_bound(),构造函数X(i, j, c)亦如此。常规关联容器是经过排序的,这让它们能够使用表示“小于”概念的比较谓词。这种比较不适用于无序关联容器,因此它们使用基于概念“等于”的比较谓词。
为无序关联容器定义的类型
| 类型 | 值 |
|---|---|
| X::key_type | Key,键类型 |
| X::key_equal | Pred,一个二元一谓词,检查两个类型为Key的参数是否相等 |
| X::hasher | Hash,一个这样的二元函数对象,即如果hf的类型为Hash,k的类型为Key,则hf(k)的类型为std::size_t |
| X::local_iterator | 一个类型与X::iterator相同的迭代器,但只能用于一个桶 |
| X::const_local_iterator | 一个类型与X::const_ iterator相同的迭代器,但只能用于一个桶 |
| x::mapped_type | T,关联数据类型(仅限于map和multimap ) |
无序关联容器还包含其他一些必不可少的方法,在该表中,X为无序关联容器类,a是类型为X的对象,b可能是类型为X的常量对象,a_uniq是类型为unordered_set或unordered_map的对象,a_eq是类型为unordered_multiset或unordered_multimap的对象,hf是类型为hasher的值,eq是类型为key_equal的值,n是类型为size_type的值,z是类型为float的值。与以前一样,i和j也是指向value_type元素的输入迭代器,[i, j)是一个有效的区间,p和q2是指向a的迭代器,q和q1是指向a的可解除引用迭代器,f是有效区间,t是X::value_type值(可能是一对),kX::key_type值,而il是initializer_list<value_type>对象。
为无序关联容器定义的操作
| 操作 | 说明 |
|---|---|
| X(n, hf, eq) | 创建一个至少包含n个桶的空容器,并将hf用作哈希函数,将eq用作键值相等谓词。如果省略了eq,则将key_equal()用作键值相等谓词;如果也省略了hf.则将hasher()用作哈希函数 |
| X a(n, hf, eq) | 创建一个名为a的空容器,它至少包含n个桶,并将hf用作哈希函数,将eq用作键值相等谓词。如果省略eq,则将key_equal( )用作键值相等谓词;如果也省略了hf,则将hasher()用作哈希函数 |
| X(i, j, n, hf, eq) | 创建一个至少包含n个桶的空容器,将hf用作哈希函数,将eq用作键值相等谓词,并插入区间[i, j)中的元素。如果省略了eq,将key_equal()用作键值相等谓词;如果省略了hf,将hasher()用作哈希函数;如果省略了n,则包含桶数不确定 |
| X a(i, j, n, hf, eq) | 创建一个名为a的的空容器,它至少包含n个桶,将hf用作哈希函数,将eq用作键值相等谓词,并插入区间[i, j)中的元素。如果省略了eq,将key_equal( )用作键值相等谓词;如果省略了hf,将hasher()用作哈希函数;如果省略了n,则包含桶数不确定 |
| b .hash_function() | 返回b使用的哈希函数 |
| b.key_ eq() | 返回创建b时使用的键值相等谓词 |
| b.bucket_count() | 返回b包含的桶数 |
| b.max_bucket_ count() | 返回一个上限数,它指定了b最多可包含多少个桶 |
| b.bucket(k) | 返回键位为k的元素所属桶的索引 |
| b.bucket_size(n) | 返回索引为n的桶可包含的元素数 |
| b.begin(n) | 返回一个迭代器,它指向索引为n的桶中的第一个元素 |
| b.end(n) | 返回一个迭代器,它指向索引为n的桶中的最后一个元素 |
| b.cbegin(n) | 返回一个常量迭代器,它指向索引为n的桶中的第一个元素 |
| b.cend(n) | 返回一个常量迭代器,它指向索引为n的桶中的最后一个元素 |
| b.load_factor() | 返回每个桶包含的平均元素数 |
| b.max_load_factor() | 返回负载系数的最大可能取值;超过这个值后,容器将增加桶 |
| b.max_load_factor(z) | 可能修改最大负载系统,建议将它设置为z |
| a.rehash(n) | 将桶数调整为不小于n,并确保a.bucket_count( ) > a.size( ) /a.max_load_factor( ) |
| a.reserve(n) | 等价于a.rehash(ceil(n/a.max_load_factor())),其中ceil(x)返回不小于x的最小整数 |
二、算法
1.算法组
STL将算法库分成4组:
-
非修改式序列操作;
-
修改式序列操作;
-
排序和相关操作;
-
通用数字操作。
前3组在头文件algorithm(以前为algo.h )中描述,第4组是专用于数值数据的,有自己的头文件,称为numeric(以前它们也位于algol.h中)。
常见的算法函数及算法的用例请见:STL--常见的算法函数
2.算法的通用特征
所有泛型算法除了少数例外,前两个参数皆为一组iterator,用来标示欲遍历之容器元素的范围。范围从第一个iterator所指位置开始,至第二个iterator所指位置(并不包括)结束:
int iarray[7] = {1,10,8,4,3,14,8};
vector<int> vec(iarray, iarray+7);
int *pi = find(vec.begin(), vec.end(), value);
很多“会更改目标容器内容”的算法都提供两个版本:就地版本和复制版本。
- 就地版本:会改变容器的内容;
- 复制版本:不改变传入容器的内容,而是先为它制作一份副本,再改变副本的内容,然后返回该副本。
STL的约定是,复制版本的名称将以_copy结尾。复制版本将接受一个额外的输出迭代器参数,该参数指定结果的放置位置。例如,函数replace()的原型如下:
template<class ForwardIterator, class T>
void replace(ForwardIterator first, ForwardIterator last,
const T& old_value, const T& new_value)
它将所有的old_value替换为new_value,这是就地发生的。由于这种算法同时读写容器元素,因此迭代器类型必须是ForwardIterator或更高级别的。复制版本的原型如下:
template<class InputIterator, class OutIterator, class T>
OutIterator replace_copy(InputIterator first, InputIterator last,
OutIterator result,
const T& old_value, const T& new_value)
在这里,结果被复制到result指定的新位置,因此对于指定区间而言,只读输入迭代器足够了。
注意,replace_ copy()的返回类型为OutputIterator。对于复制算法,统一的约定是:返回一个迭代器,该迭代器指向复制的最后一个值后面的一个位置。
另一个常见的变体是:有些函数有这样的版本,即根据将函数应用于容器儿素得到的结果来执行操作。这些版本的名称通常以_if结尾,便是“可指定特定行为”的那个版本。例如,如果将函数用于旧值时,返回的值为true,则replace_if()将把旧值替换为新的值。下面是该函数的原型:
template<class ForwardIterator, class Predicate, class T>
void replace_if(ForwardIterator first, ForwardIterator last,
Predicate pred, const T& new_value)
如前所述,谓词是返回bool值的一元函数。还有一个replace_ copy_if()版本,您不难知道其作用和原型。
与InputIterator一样,Predicate也是模板参数名称,可以为T或U。然而,STL选择用Predicate来提醒用户,实参应模拟Predicate概念。同样,STL使用诸如Generator和BinaryPredicate等术语来指示必须模拟其他函数对象概念的参数。请记住,虽然文档可指出迭代器或函数符需求,但编译器不会对此进行检查。如果您使用了错误的迭代器,则编译器试图实例化模板时,将显示大量的错误消息。
三、迭代器
预定义的迭代器
- istream_iterator
- ostream_iterator
- reverse_iterator
- back_insert_iterator
- insert_iterator
- front_insert_iterator
1.使用iostream Iterator
标准库定义有供输入及输出使用的iostream iterator类,称为istream_iterator和ostream_iterator,分别支持单一类型的元素读取和写人使用这两个iterator class之前,先得包含iterator 头文件:
#include <iterator>
istream_iterator的使用
可以利用istream_iterator从标准输入设备读取字符串。就像所有的iterator一样,我们需要一对iterator: first和last,用来标示元素范围。
istream_iterator<string> is(cin);
以上定义为我们提供了一个first iterator。它将is定义为一个‘’绑至标准输人设备”的istream_iterator。我们还需要一个last iterator,表示‘’要读取的最后一个元素的下一位置”。对标准输人设备而言,end-of-file即代表last。只要在定义istream_iterator时不为它指定istream 对象,它便代表了end-of-file,例如:
istream_iterator<string> eof; // 或者istream_iterator<string> eof();
与copy一起使用:
#include <iostream>
#include <string>
#include <algorithm>
#include <vector>
#include <iterator>
int main()
{
using std::vector;
using std::string;
using std::cin;
using std::istream_iterator;
vector<string> text;
istream_iterator<string> is(cin);
istream_iterator<string> eof;
copy(is, eof, text);
return 0;
}
ostream_iterator的使用
可以利用ostream_iterator定义一个“绑至标准输出设备”。此标准输出设备供我们输出类型为string的元素。
ostream_iterator<string> os( cout, " " )
上述第二个参数可以是C-style字符串.也可以是字符串常量。它用来表示各个元素被输出时的分隔符。默认情形下,输出的各个元素之间并无任何分隔符。本例我选择在各输出字符串之间以空格加以分隔。以下便是可能的使用方式:
copy( text.begin(), text.end(), os )
copy()会将储存在text中的每个元素一一写到由os所表示的ostream上。每个元素皆以空格分隔开来。以下是完整的程序:
#include <iostream>
#include <string>
#include <algorithm>
#include <vector>
#include <iterator>
int main()
{
using namespace std;
cout << "please enter some text, then indicate end of file!\n";
istream_iterator< string > is( cin );
istream_iterator< string > eof;
vector< string > text;
copy( is, eof, back_inserter( text ));
sort( text.begin(), text.end() );
ostream_iterator<string> os( cout, " " );
copy( text.begin(), text.end(), os );
return 0;
2.使用Iterator Inserter
所有‘’会对元索进行复制行为”的泛型算法,例如copy ( ) , copy_backwards ( ) , remove_copy ( ),replace_copy ( ),unique_copy ( )等等。每个算法都接受一个iterator,标示出复制的起始位置。每复制一个元素,都会被赋值,iterator则会递增至下个位置。我们必须保证在每一次复制操作中,目的端容器都足够大,可以储存这些被赋值进来的元素。既然有了这些算法,我们实在不需要重新写一个。
这意味着我们必须总是传人某个固定大小的容器至上述算法吗?这绝对不符合STL的精神。标准库提供了3个所谓的insertion adapter,这些adapter让我们得以避免使用容器的赋值(assignment)运算符。
三种插入迭代器通过将复制转换为插入解决了目的端容器空间大小问题和覆盖数据问题。插入将添加新的元素,而不会覆盖己有的数据,并使用自动内存分配来确保能够容纳新的信息。back_inserter将元素插入到容器尾部,而front_inserter将元素插入到容器的前端。最后,inserter将元素插入到insert_iterator构造函数的参数指定的位置前面。这三个插入迭代器都是输出容器概念的模型。
back_inserter()
back_inserter会以容器的push_back()函数取代assignmenet运算符。对vector来说,这是比较适合的inserter。传入back_inserter的参数,应该就是容器本身。
vector<int> ivec;
vector<int> result_vec;
unique_copy(ivec.begin(), ivec.end(), back_inserter(result_vec));
inserter()
inserter()会以容器的insert()函数取代assignmenet运算符。inserter()接受两个参数:一个是容器,另一个是iterator,指向容器内的插人操作起点。以vector而言,我们会这么写:
vector<int> ivec;
vector<int> result_vec;
unique_copy(ivec.begin(), ivec.end(), inserter(result_vec, result_vec.end()));
front_inserter()
front_ inserter()会以容器的push_front()函数取代assignmenet运算符。这个inserter只适用于list和deque:
list<int> ilist;
list<int> ilist_clone;
copy(ilist.begin(), ilist.end(), front_inserter(ilist_clone));
欲使用上述三种adapter,首先必须包含iterator头文件:
#include <iterator>
然而这些adapter并不能用在内置数组上。
三种插入迭代器通过将复制转换为插入解决了目的端容器空间大小问题和覆盖数据问题,以下程序说明:
#include <iostream>
#include <algorithm>
#include <vector>
#include <iterator>
int main()
{
using std::vector;
using std::replace_copy;
using std::less;
using std::back_inserter;
using std::endl;
using std::cout;
const int elem_size = 8;
int ia[elem_size] = {12,8,43,0,6,21,3,7};
int ia2[7];
vector<int> ivec(ia, ia+elem_size);
vector<int> ivec2;
cout << "replace integer 0 to 100\n";
replace_copy(ia, ia+elem_size, ia2, 0, 100); //ia2空间不足,报错
for (int i=0; i < elem_size; i++)
{
cout << ia2[i] << " ";
}
cout << "replace integer 0 to 100\n";
replace_copy(ivec.begin(), ivec.end(), back_inserter(ivec2), 0, 100);
for (int i=0; i < elem_size; i++)
{
cout << ivec2[i] << " ";
}
return 0;
}
以上程序运行中,将值赋值到ia2,因ia2的空间只有7,空间不足报错,而ivec2是使用back_inserter插入的,使用自动内存分配来确保ivec2能够容纳新的元素。
3.使用reverse Iterator
reverse_inserter()
假设要显示dice容器的内容,正如可以使用copy()和ostream_ iterator来将内容复制到输出流中:
vector<int> dice(10);
ostream_iterator<int, char> out_iter(cout, " ");
copy(dice.begin(), dice.end(), out_iter);
假设要反向打印容器的内容。vector类有一个名为rbegin()的成员函数和一个名为rend()的成员函数,前者返回一个指向超尾的反向迭代器,后者返回一个指向第一个元素的反向迭代器。因为对迭代器执行递增操作将导致它被递减,所以可以使用下面的语句来反向显示内容:
copy(dice.rbegin(), dice.rend(), out_iter);
甚至不必声明反向迭代器。
注意:rbegin()和end()返回相同的值(超尾),但类型不同(reverse_ iterator和iterator )。同样,rend( )和begin()也返回相同的值(指向第一个元素的迭代器),但类型不同。
使用反向迭代器来反向显示内容:
vector<int>::reverse_iterator ri;
for (ri = dice.rbegin(); ri != dice.rend(); ++ri)
cout << *ri << ' ';
完整程序实例:
#include <iostream>
#include <iterator>
#include <vector>
int main()
{
using namespace std;
int casts[10] = {6, 7, 2, 9 ,4 , 11, 8, 7, 10, 5};
vector<int> dice(10);
// copy from array to vector
copy(casts, casts + 10, dice.begin());
cout << "Let the dice be cast!\n";
// create an ostream iterator
ostream_iterator<int, char> out_iter(cout, " ");
// copy from vector to output
copy(dice.begin(), dice.end(), out_iter);
cout << endl;
cout <<"Implicit use of reverse iterator.\n";
copy(dice.rbegin(), dice.rend(), out_iter);
cout << endl;
cout <<"Explicit use of reverse iterator.\n";
// vector<int>::reverse_iterator ri; // use if auto doesn't work
for (auto ri = dice.rbegin(); ri != dice.rend(); ++ri)
cout << *ri << ' ';
cout << endl;
// cin.get();
return 0;
}
输出:
Let the dice be cast!
6 7 2 9 4 11 8 7 10 5
Implicit use of reverse iterator.
5 10 7 8 11 4 9 2 7 6
Explicit use of reverse iterator.
5 10 7 8 11 4 9 2 7 6
如果可以在显式声明迭代器和使用STL函数来处理内部问题(如通过将rbegin()返回值传递给函数)之间选择,请采用后者。后一种方法要做的工作较少,人为出错的机会也较少。
四、函数对象
很多 STL 算法都使用函数对象--也叫函数符。函数符是可以以函数方式与()结合使用的任意对象。这包括函数名、指向函数的指针和重载了()运算符的类对象(即定义了函数 operator( )( )的类)。例如,可以像这样定义一个类:
class Linear
{
private
double slope;
double y0;
public:
Linear (double sl_ = 1, double y_ = 0 : slope (s1_), yo(y_) {}
double operator () (double x) (return y0 + slope *x;
}
这样,重载的()运算符将使得能够像函数那样使用 Linear 对象:
Linear fl;
Linear f2(2.5, 10.0);
double yl = f1(12.5) i //right-hand side is f1.operator()(12. 5)
double y2 = f2(0.4)
其中 y1 将使用表达式 0+1*2.5 来计算,y2 将使用表达式 10.0+2.5*0.4 来计算。在表达式 y0+ slope *x 中,y0 和 slope 的值来自对象的构造函数,而 x 的值来自 operator ()()的参数。还记得函数 for each 吗?它将指定的函数用于区间中的每个成员:
for each (books.begin(), books.end(), ShowReview);
通常,第 3 个参数可以是常规函数,也可以是函数符。
ShowReview()的原型如下:
void ShowReview(const Review &)
1. 函数符概念
STL定义了函数符的概念:
- 生成器(generator)是不用参数就可以调用的函数符。
- 一元函数(unary function)是用一个参数可以调用的函数符。
- 二元函数(binary function)是用两个参数可以调用的函数符。
例如,提供给 for_each()的函数符应当是一元函数,因为它每次用于一个容器元素。当然,这些概念都有相应的改进版:
-
返回 bool 值的一元函数是谓词(predicate);
-
返回 bool 值的二元函数是二元谓词(binary predicate)
一些STL函数需要谓词参数或二元谓词参数。例如sort()将二元谓词作为其第3个参数:
bool WorseThan(const Review &r1, const Review &r2);
sort(books.begin(), books.end(), WorseThan);
list 模板有一个将谓词作为参数的 remove_if)成员,该函数将谓词应用于区间中的每个元素,如果谓词返回 true,则删除这些元素。例如,下面的代码删除链表 three中所有大于 100 的元素:
bool tooBig(int n){return n > 100;}
list<int> scores;
scores.remove_if(tooBig);
2. 预定义的函数符
要使用预定义的函数符,要包含以下头文件:
#include <functional>
举个例子,默认情形下,sort( )会使用底部元素的类型所提供的 less-than 运算符,将元素升序排序。如果我们传入 greater_ than function object,元素就会以降序排序:
sort(vec.begin(), vec.end(), greater<int>());
其中的 greater <int> () 会产生一个未命名的 class template object,传给sort()。
binary_search( )期望其搜索对象先经过less-than运算符排序。为了正确搜索 vector,我们现在必须传给它某个 function object object,供 vector 排序使用:
binary_search(vec.begin(), vec.end(), elem, greater<int>());
现在,我以另外数种略加变化的方式来显示 Fibonacci 数列:每个元素和自身相加、和自身相乘被加到对应的 Pell 数列,等等。做法之一是使用泛型算法 transform()并搭配 plus<int>和multiplies<int>。
我们必须传给 transform (): (1) 一对 iterator,标示出欲转换的元素范围,(2) 一个 iterator,所指元素将应用于转换操作上,(3) 一个 iterator, 所指位置(及其后面的空间)用来存放转换结果,(4) 一个 function object,表现出我们想要应用的转换操作。以下便是将 Pel 数列加到 Fibonacci数列的写法:
transform(fib.begin(), fib.end(), // (1) 欲转换的元素范围
pell.begin(), // (2) 所指元素将应用于转换操作上
fib_plus_pell.begin(), // (3) 所指位置(及后续空间)用来存放转换结果
plus<int>() ); // (4) 想要应用的转换操作
下表列出了预定义的函数符:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号