论文阅读:Borrowing wisdom from world: modeling rich external knowledge for Chinese named entity recognition
问题定义
由于词级中文 NER 存在第三方解析器分割的边界错误,因此考虑将字符级 NER 作为默认设置。
使用'BMES'标记方案进行字符级NER,将标记表述为序列标记问题。即,对于句子\(s={c_1,...,c_n}\)中的每个字符\(c_i\),使用标签集中的标签进行标记\(L={B,M,E,S,O}\)。
- O:非实体元素
- B:实体起始token
- M:位于实体范围内,且在实体起始token之后
- E:实体结束token
- S:独立实体
模型框架
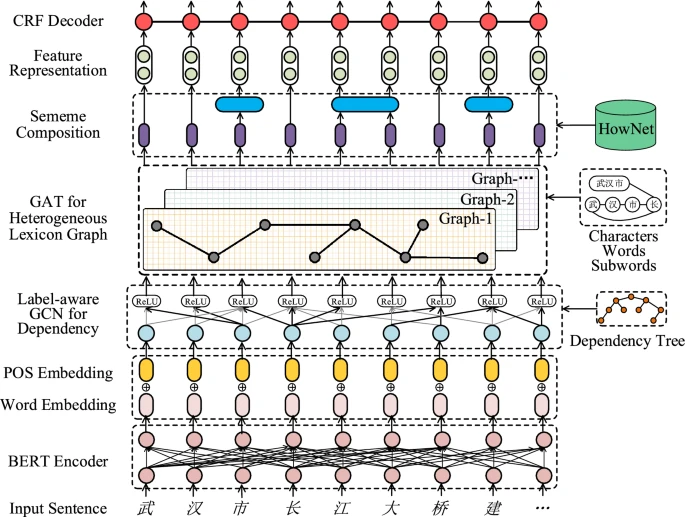
模型的处理过程从下至上为:
- 首先,
BERT编码器接受原始中文句子作为输入,并生成字符嵌入。 - 接着,这些字符嵌入与
POS嵌入联合,形成统一的输入表示。 - 紧接着,通过
标签感知的GCN编码器对字符级依赖结构及依赖标签进行编码,为每个字符提供具有语法感知的表示。 - 之后,
GAT编码器整合了由多粒度词典输入构成的异构图。 - 然后,
sememe组成层将HowNet中的sememe表示融入每个节点,进一步丰富节点的上下文信息。 - 最终,
CRF层根据各节点的表示输出实体及其类型。
BERT编码器
BERT编码器将原始中文句子作为输入,并产生字符嵌入\(v_i\)。
POS嵌入
将单词级别的标记扩展到字符级别的标记:
- 原始:武汉市/NR 长江/NR 大桥/NN 建成/LC 通向/VV 天河/NR 国际机场/NN
- 扩展:武/NR 汉/NR 市/NR 长/NR 江/NR 大/NN 桥/NN 建/LC 成/LC 通/VV 向/VV 天/NR 河/NR 国/NN 际/NN 机/NN 场/NN
每个标签\(p_i\)通过查找表由向量嵌入表示:
\[x_i^p = E_p()p_i
\]
然后,将 POS 标签嵌入与每个字符的 BERT 表示连接起来:
\[x_i = [x_i^p; v_i]
\]
用于语法依赖的标签感知 GCN
构建依赖标签
- 输入句子及其依赖结构:首先,给定一个包含依赖结构的输入句子s,依赖结构包括边(edges)和标签(labels)。
- 邻接矩阵定义:定义一个邻接矩阵\(A\),这个矩阵用于表示每一对字符之间是否存在依赖边。
- 依赖标签矩阵:定义一个依赖标签矩阵\(L\),其中每个元素\(L[i][j]\)表示字符\(i\)到字符\(j\)之间的依赖关系标签\(l\)。
- 标签拓展:除了在矩阵\(L\)中预定义的标签外,额外添加了几个特殊标签:
- ‘self’标签:表示字符自身的环
- ‘inner’标签:表示同一词内字符之间的连接
- ‘none’标签:表示字符之间无连接
- 依赖标签的向量嵌入:为矩阵\(L\)中的每一个依赖标签维护一个向量嵌入\(x_{i,j}^r\)。
标签感知 GCN (LGCN)
LGCN由 \(L\) 层组成,\(l\)层的隐藏表示为:
\[{x}^{(l)}_i = \text {ReLU}\left( \begin{matrix} \sum\limits _{j=1}^n \end{matrix} \gamma _{i,j}^{(l)} ( {W}_{a} \cdot {x}^{(l-1)}_j + {W}_{b} \cdot {x}^r_{i,j} + b ) \right)
\]
其中,\(\gamma _{i,j}^{(l)}\)是通过 SoftMax 函数计算的邻居连接强度分布:
\[\gamma _{i,j}^{(l)} = \frac{ b_{i,j} \cdot \exp {( {x}^{n}_i \cdot {x}^{n}_j )} }{ \sum _{j=1}^n b_{i,j} \cdot \exp {( {x}^{n}_i \cdot {x}^{n}_j )} }
\]
其中,\(x_i^n\)是\(x_i^{(l-1)}\)和\(x_{i,j}^r\)元素相加。
通过 GAT 集成异构词典图
(1)用字符、单词和子词扩展信息的粒度,并构建多粒度词汇信息的异构图。
(2)通过图注意力神经网络(GAT)对它们进行编码。
构建异构图
- 每个字符节点\(c_i\),将 LGCN 输出表示作为其嵌入。
- 对于单词和子单词,我们使用外部中文词典\(D\),并查找输入句子中在词典中共存的所有可能的单词和子单词。将单词或子词表示为\(w_j\),并通过可训练的查找表获取其嵌入\(x_j^w = E_w(w_j)\)。
GAT编码
- 输入:GAT的输入是一组节点表示:\({h_1,...,h_M}\),以及一个邻接矩阵\(A\)。其中,\(M\)代表节点的数量。
- 输出:GAT处理后的输出是更新后的节点表示:\({h'_1,...,h'_M}\)。
- GAT通过\(P\)个独立的注意力头来执行计算。每个注意力头基于节点间的相对重要性分配注意力系数\(\alpha _{ij}\):
\[\begin{aligned} \begin{aligned} {h}^{'}_{i}&=\left[ \sigma \left( \sum _{j\in M_i} \alpha ^{1}_{ij} {W}^1 {h}_{j}\right) ; \cdots ; \sigma \left( \sum _{j\in M_i} \alpha ^{P}_{ij} {W}^P {h}_{j}\right) \right] ,\\ \alpha ^{p}_{ij}&= \text {Softmax}( \text {LeakyReLU}( {a}^T [{W}^p {h}_{i} ; {W}^P {h}_{j} ]) ), \end{aligned} \end{aligned}
\]
- 使用非线性激活函数\(\sigma\)进一步处理计算结果。:
\[\begin{aligned} {h}^{'}_{i} = \sigma \left( \frac{1}{P} \sum _{p=1}^P \sum _{j \in M_i} \alpha ^{1}_{ij} {W}^1 {h}_{j}\right) , \end{aligned}
\]
- 在实际应用中,通常使用多层GAT来充分传播节点间的信息,以获取更加深入的图结构理解。
- 异构图的集成处理:
- 通过GAT获取每种类型的图中的节点表示:
\[G^* ( \in \{\text {Con},\text {Lat},\text {Trn}\})
\]
- 然后,使用融合层来集成由异构图捕获的不同知识:
\[\begin{aligned} {r}_{i} = \sigma ( {W}^{\text {Con}}{h}^{\text {Con}} + {W}^{\text {Lat}}{h}^{\text {Lat}} + {W}^{\text {Trn}}{h}^{\text {Trn}} + {W}{h} ) \,, \end{aligned}
\]
Sememe组成层
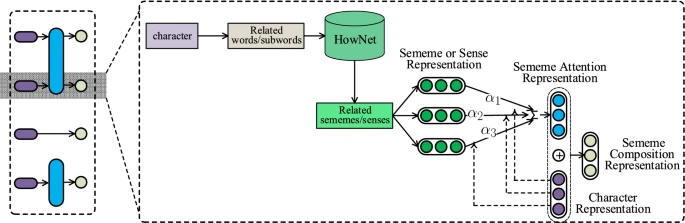
- 节点表示的获取: GAT处理得到的
字符节点表示\(r_i\)。 - 寻找相关词及其sememe:给定字符的节点表示\(r_i\),首先找到它的所有
相关词或子词,然后从知网中查阅其所有可能的sememe。 - Sememe项的嵌入:将从知网中提取的每个sememe转换为
分布式表示向量。 - 语素注意表示的获取: 得到sememe的分布式向量后,接下来使用
注意力机制来计算每个sememe对于节点表示\(r_i\)的贡献。 - 加权组合: 通过注意力权重调整后,各sememe的表示被
加权组合,以生成最终的、增强的节点表示。
解码和学习
最后,将CRF层集成为输出序列标签的编码器。CRF的概率模型为:
\[\begin{aligned} p(y|{h}^s) = \frac{ \prod ^{n}_{i=1} \psi _{i} (y_{i-1}, y_{i}, {h}^s) }{\sum _{y^{'} \in Y ({h}^s)} \prod ^{n}_{i=1} \psi _{i} (y^{'}_{i-1}, y^{'}_{i}, {h}^s) } \,, \end{aligned}
\]
使用\(L_2\)正则化进行最小化:
\[\begin{aligned} \mathcal {L} = - \sum _{i=1}^N \mathrm{log}( P(y_i|s_i)) + \frac{\lambda }{2} ||\varTheta ||^2 , \end{aligned}
\]
数据集:
- **OntoNotes 4.0 **包含带有各种注释的多语言语料库,该数据集总共包含 18 种类型的实体。
- MSRA是新闻领域的CNER数据集,其中有3种类型的实体。
- 微博由中国社交媒体新浪微博Footnote1中带注释的CNER标签组成,其中涉及4个实体标签。
- Resume包含8种中文文本的命名实体。
Nie, Y., Zhang, Y., Peng, Y. et al. Borrowing wisdom from world: modeling rich external knowledge for Chinese named entity recognition. Neural Comput & Applic 34, 4905–4922 (2022). https://doi.org/10.1007/s00521-021-06680-6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号