论文阅读:BERT-Based Chinese Relation Extraction for Public Security
模型框架
包含一个BERT模型层(嵌入+编码+池化->得到句子的特征向量)、一个Dropout层(防止过拟合)。
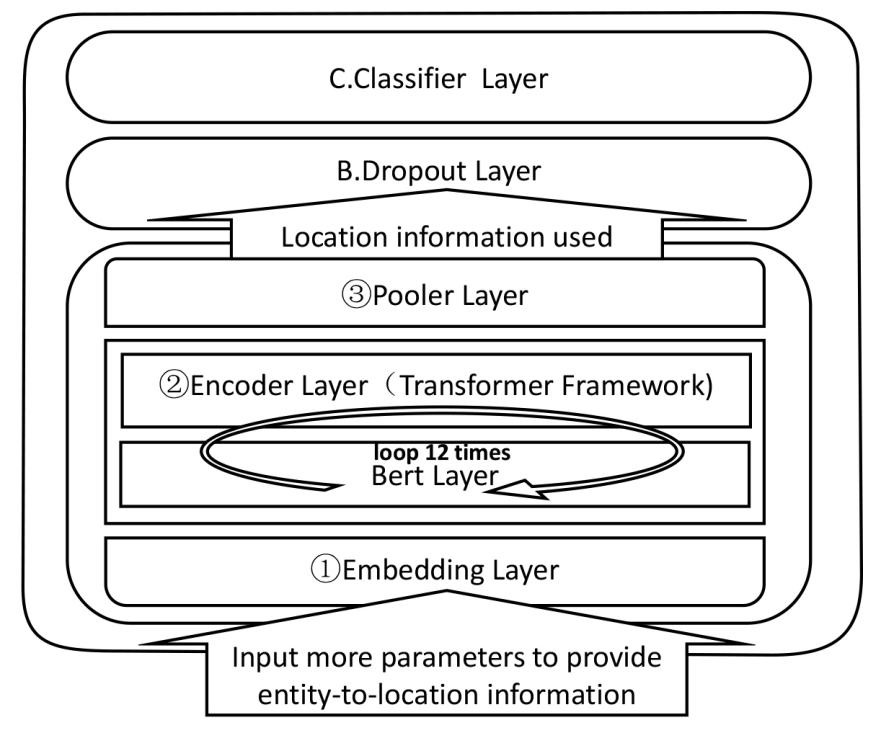
基于BERT的预训练模型
BERT模型是通过注意力机制对训练集进行处理。然后,通过Embedding层和Encoder层加载预训练的词向量。 最后,Pooling 层使用 BERT 模型来训练两个句子。
BERT嵌入层
输入层中,输入数据首先通过BERT嵌入部分,将每个单词转换为\(embedding_{word}\)、\(embedding_{position}\)和\(embedding_{token_type}\)。
实体对位置嵌入:在使用令牌级别特征提取句子后,实体对以矩阵的形式嵌入了位置信息。(对角线为位置信息的单位矩阵)
然后,将句子的特征向量矩阵与新生成的实体对位置矩阵相乘,就可以得到带有实体对位置信息的句子特征向量。
BERT编码层
BERT使用Transformer Encoder作为语言模型,Transformer模型采用Attention机制来计算输入和输出之间的关系。(Q、K、V)
BERT池化层
这是一个激活函数,它执行线性处理并使用 Tanh() 来池化 BERT 编码器的输出:
Dropout层
然后进行dropout - layerNorm - ReLU -线性操作。
数据集
一种面向中国文学文本的话语级命名实体识别与关系抽取数据集:Xu J, Wen J, Sun X, et al. A discourse-level named entity recognition and relation extraction dataset for chinese literature text[J]. arXiv preprint arXiv:1711.07010, 2017.
Hou J, Li X, Yao H, et al. BERT-based Chinese relation extraction for public security[J]. IEEE Access, 2020, 8: 132367-132375.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号