论文阅读:使用集合预测网络进行联合实体和关系提取
github代码:http://github.com/DianboWork/SPN4RE
目的
- 从本质上讲,句子中提到的关系三元组是
集合的形式,它没有元素之间的内在顺序,并表现出排列不变的特征。(多个三元组的抽取顺序,对抽取结果没有影响) - 然而,
以前基于 seq2seq 的模型需要事先使用一些启发式全局规则将关系三元组的集合排序为一个序列,这破坏了自然集合结构。 - 为了打破这一瓶颈,我们
将联合实体和关系抽取视为直接集合预测问题,这样抽取模型就不会有预测多个三元组顺序的负担。
引言
- 早期的研究,使用
管道技术,先识别实体,再预测实体之间的关系,忽略了实体识别和关系预测的相关性,并存在严重的错误传播问题。 - 因此出现了联合抽取,可以分为三类。
- 将联合实体和关系提取任务视为
端到端的表填充问题。(尽管使用了共享参数,但实体和关系的提取是单独提取的,且会产生冗余信息)- 将联合实体和关系提取转化为
序列标记。(需要设计复杂的标注框架)- 由
序列到序列模型驱动,以直接生成关系三元组。
本模型沿用序列到序列的思想。当前基于seq2seq的模型不仅需要学习如何生成三元组,还需要考虑多个三元组的提取顺序。本文将联合实体和关系抽取的任务表述为一个集合预测问题,避免考虑多个三元组的顺序。
集合预测模型(SPN)
- SPN由三部分组成:
句子编码器、集合生成器和基于集合的损失函数。
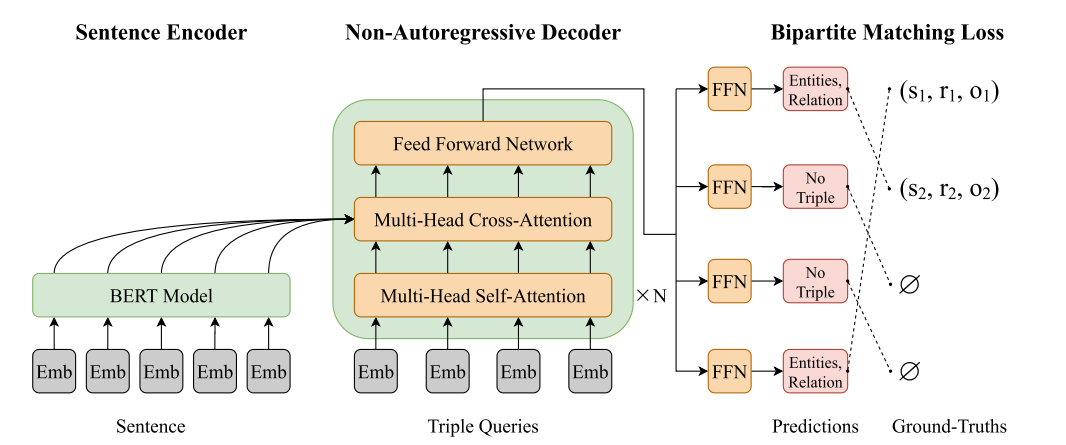
- 使用
BERT作为编码器,以获得给定句子的上下文感知表示。- 利用
基于transformer的非自回归解码器作为集合生成器,它可以一次预测所有三元组并避免对三元组进行排序。- 提出了受运筹学中的分配问题启发的
二分匹配损失函数。
句子编码器
- 此组件的目标是获取输入句子中每个标记的上下文感知表示。
- 输入:在BERT编码器中,
输入句子通过字节对编码与标记进行分割,然后输入编码器。 - 输出:BERT模型的输出是
标记的上下文感知嵌入。
集合生成器
- 将联合实体和关系提取视为一个集合预测问题,并使用基于transformer的非自回归解码器直接生成三元组集。
- 输入:解码开始前,解码器需要知道
目标集的大小,设为统一的m个(其中m设置为明显大于句子中中典型的三元组数)。解码器的输入不是从编码器端复制令牌,而是通过m个可学习的嵌入进行初始化,称之为三元组查询。 - 解码器架构:非自回归解码器由
N个相同的Transformer模块组成。(在每个 transformer 模块中,都有一个多头自注意力子层,用于建模三元组之间的关系,还有一个多头交叉注意力子层,用于融合给定句子的信息。) - 通过非自回归解码器,将
m 个三元组查询转化为m 个输出嵌入。然后,通过前馈网络将输出嵌入独立解码为关系类型和实体,从而产生 m 个最终预测的三元组。
基于集合的损失函数
论文中提出的基于集合的损失函数,即二分匹配损失,是为了解决关系三元组提取任务中的一个核心问题:三元组的顺序不应影响模型的性能。在传统的使用交叉熵损失函数的模型中,如果预测的三元组顺序与目标顺序不一致,即使三元组是正确的,模型也会受到惩罚。这种情况在关系三元组的提取中是不理想的,因为三元组的顺序本质上是不重要的。
- 工作原理:二分匹配损失是基于
最优匹配算法(如匈牙利算法或KM算法),它在模型预测的输出集合和真实标签集合之间寻找最佳的一一对应关系。这种对应关系的目标是最小化整体的匹配成本,即最小化预测三元组与真实三元组之间的差异。 - 计算步骤:
1. 成本矩阵计算:首先,构建一个
成本矩阵,其中矩阵的每个元素代表一个预测三元组和一个真实三元组之间的匹配成本。这个成本通常是基于某种距离度量(如欧氏距离、汉明距离等)计算的。
2. 寻找最佳匹配:使用匈牙利算法或其他算法在成本矩阵中找到成本最小的匹配方式。这意味着算法会试图找到一种方式,通过这种方式,每个预测的三元组都与一个真实的三元组相匹配,且总体匹配成本最小。
3.损失计算:一旦确定了最佳匹配,模型的损失就是这些匹配对应的成本之和。
- 优势:
- 排列不变性:由于损失计算不依赖于三元组的顺序,模型可以自由地预测任何顺序的三元组,只要这些三元组是正确的。
- 关注关键信息:这种方法强制模型专注于预测正确的三元组内容(实体和关系),而不是它们的排列顺序。
实验
- 数据集:
纽约时报(NYT)和WebNLG。 - 评估指标:采用
micro-average precision,micro-average recall, andmicro-average F1 scores来评估。

@ARTICLE{10103602,
author={Sui, Dianbo and Zeng, Xiangrong and Chen, Yubo and Liu, Kang and Zhao, Jun},
journal={IEEE Transactions on Neural Networks and Learning Systems},
title={Joint Entity and Relation Extraction With Set Prediction Networks},
year={2023},
volume={},
number={},
pages={1-12},
keywords={Decoding;Task analysis;Predictive models;Feature extraction;Training;Pipelines;Transformers;Bipartite matching;joint entity and relation extraction;non-autoregressive decoder;set prediction},
doi={10.1109/TNNLS.2023.3264735}}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号