论文阅读:基于实体边界组合的关系抽取方法
李昊, 陈艳平, 唐瑞雪, 等. 基于实体边界组合的关系抽取方法[J]. 计算机应用, 2022, 42(6): 1796.
主要工作
- 提出了一种边界组合的关系抽取方法,跳过实体直接使用实体边界进行关系抽取;
- 本文方法结合了Chen等提出的多通道深度神经网络模型思想以及特征组合的方法以减轻错误扩散对关系抽取的影响;
- 在ACE 2005英文数据集上验证了该方法的宏平均F1值优于表格-序列编码器方法。
模型
- 本文中关系抽取分为两个阶段,分别为边界识别阶段和关系抽取阶段。
- 其中,边界识别阶段用边界识别模型来识别实体边界;
- 关系抽取阶段利用边界识别模型识别出来的实体边界通过关系抽取模型识别实体间的关系。
边界识别模型
- 在边界识别阶段,本文根据Chen等提出的一种基于深度边界组合的嵌套命名实体识别模型的方法采用两个
双向长短期记忆条件随机场模型分别识别实体的开始边界和结束边界,它们均由字嵌入层、Bi-LSTM层和CRF层组成。
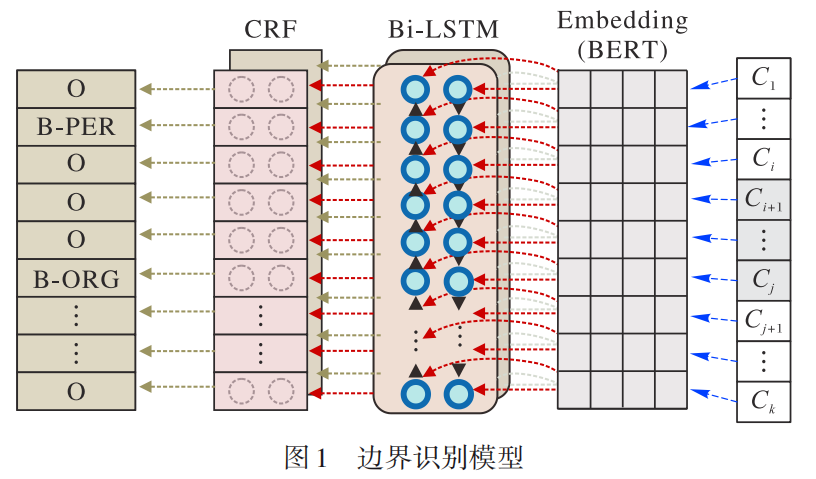
- 在
Embedding层中本文通过BERT预训练技术将每个字转化为低维稠密向量。 - 在
Bi-LSTM层,为了捕获上下文信息,本文利用了其可长度依赖和避免梯度消失或爆炸的能力。 - 最后在
CRF层,本文在此获取最大概率转移路径,从而得到识别出来的实体边界以及实体类型。
关系抽取模型
- 在本文中,给定句子S,当句子中存在两个及以上不同实体的开始边界或结束边界时,通过将不同实体的开始边界或结束边界组合成实体边界对进行关系抽取。
- 本文方法的网络模型架构如图2所示,通过实体边界组合将句子划分作为模型的
输入生成句向量,经过卷积层和最大池化层,将输出的最大池化层的结果与特征元素生成的特征向量进行拼接输入全连接层,最后通过softmax函数得到最终的关系结果。
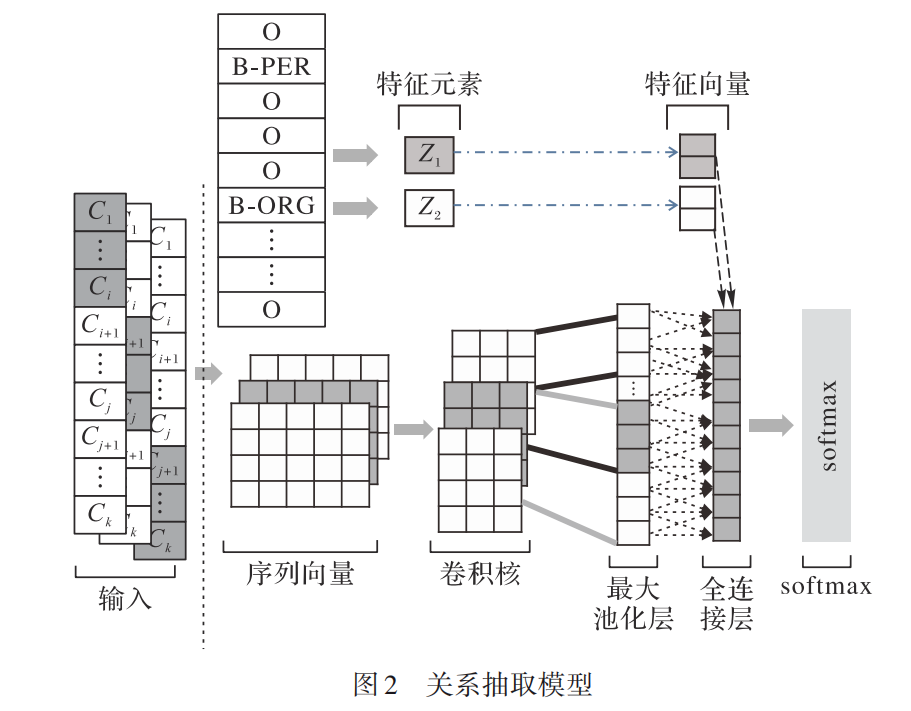
实体边界组合
- 该部分是通过
CNN模型构建句子分布式表示。当单个句子中有不少于一个实体时,就能够以不同实体的开始边界(或结束边界)两两组合生成实体边界对。 - 利用两个实体的开始边界或结束边界将每个句子分为三个部分Si={L,M,R}。
- L 代表处于实体一开始边界或结束边界左边的句子部分;
- M 代表处于实体一开始边界和实体二开始边界或结束边界中间的句子部分;
- R 代表处于实体二开始边界或结束边界右边的句子部分。
- 将划分后的句子中的字通过
字嵌入表示为向量,作为卷积层的输入。 - 在卷积层中将从输入矩阵中抽取不同尺度的序列信息,而为了抽取到的序列信息的尺寸不同,会设置不同窗口大小的
Filter。 - 然后,在
最大池化层,将每个Filter向量取最大值,以此来捕获最重要的特征。
特征组合
- 该部分是利用特征组合方法生成带有句子结构信息的复合特征。
- 设特征函数TypeOf(xe*)代表获取xe的类型,xe代表一个句子中的任意单个实体。
- 特征函数PositionOf(xe1, xe2)代表获取xe1和xe2两个实体之间的位置结构信息(如前后信息)。
- 本文将得到的特征进行分组后取得的特征集设为D = {TypeOf(xe1), TypeOf(xe2), PositionOf(xe1, xe2)}。
- 针对这些特征集可以进行特征组合,生成新的复合特征。本文采用了两种复合特征:
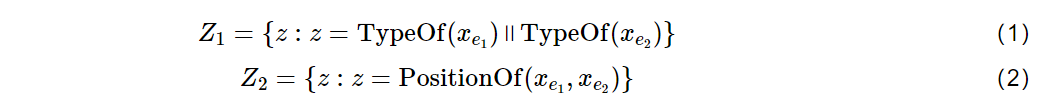
CNN模型
- 假设S={w1,w2,...,wn}是一个将要作为CNN模型输入的句子,其中wi表示句子S的第i个字。
- 因为CNN模型的输入为
固定长度,所以设句子固定长度为m,如果句子过长,应将句子舍弃一部分直到长度为m;如果句子过短,则需要对句子进行填充使之长度达到m。 - 然后将字进行
嵌入。

- 在CNN模型的
卷积层中,卷积运算表示为:

- 卷积层可以被形式化为:

- 卷积层可以被形式化为:
- 在
池化层中,为了选择出信息最为丰富的特征,将会对c中的每个元素进行最大池化操作。
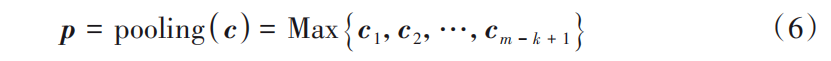
- 池化层之后为
全连接层,将会给出全局规则,实现表示为Wf·p的转换。

- 最后再由
softmax层输出预测类别的概率分布。

- 总的来说,本文关系抽取模型可以被表示为:
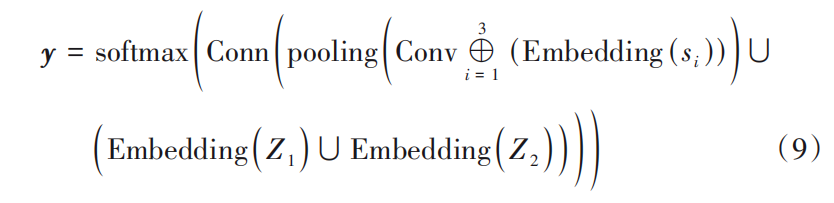

 浙公网安备 33010602011771号
浙公网安备 33010602011771号