Python(线程进程3)
四 协程


协程,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程。
协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此:
协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态,换种说法:进入上一次离开时所处逻辑流的位置。
4.1 yield与协程
import time """ 传统的生产者-消费者模型是一个线程写消息,一个线程取消息,通过锁机制控制队列和等待,但一不小心就可能死锁。 如果改用协程,生产者生产消息后,直接通过yield跳转到消费者开始执行,待消费者执行完毕后,切换回生产者继续生产,效率极高。 """ # 注意到consumer函数是一个generator(生成器): # 任何包含yield关键字的函数都会自动成为生成器(generator)对象 def consumer(): r = '' while True: # 3、consumer通过yield拿到消息,处理,又通过yield把结果传回; # yield指令具有return关键字的作用。然后函数的堆栈会自动冻结(freeze)在这一行。 # 当函数调用者的下一次利用next()或generator.send()或for-in来再次调用该函数时, # 就会从yield代码的下一行开始,继续执行,再返回下一次迭代结果。通过这种方式,迭代器可以实现无限序列和惰性求值。 n = yield r if not n: return print('[CONSUMER] ←← Consuming %s...' % n) time.sleep(1) r = '200 OK' def produce(c): # 1、首先调用c.next()启动生成器 next(c) n = 0 while n < 5: n = n + 1 print('[PRODUCER] →→ Producing %s...' % n) # 2、然后,一旦生产了东西,通过c.send(n)切换到consumer执行; cr = c.send(n) # 4、produce拿到consumer处理的结果,继续生产下一条消息; print('[PRODUCER] Consumer return: %s' % cr) # 5、produce决定不生产了,通过c.close()关闭consumer,整个过程结束。 c.close() if __name__=='__main__': # 6、整个流程无锁,由一个线程执行,produce和consumer协作完成任务,所以称为“协程”,而非线程的抢占式多任务。 c = consumer() produce(c) ''' result: [PRODUCER] →→ Producing 1... [CONSUMER] ←← Consuming 1... [PRODUCER] Consumer return: 200 OK [PRODUCER] →→ Producing 2... [CONSUMER] ←← Consuming 2... [PRODUCER] Consumer return: 200 OK [PRODUCER] →→ Producing 3... [CONSUMER] ←← Consuming 3... [PRODUCER] Consumer return: 200 OK [PRODUCER] →→ Producing 4... [CONSUMER] ←← Consuming 4... [PRODUCER] Consumer return: 200 OK [PRODUCER] →→ Producing 5... [CONSUMER] ←← Consuming 5... [PRODUCER] Consumer return: 200 OK '''
4.2 greenlet
greenlet机制的主要思想是:生成器函数或者协程函数中的yield语句挂起函数的执行,直到稍后使用next()或send()操作进行恢复为止。可以使用一个调度器循环在一组生成器函数之间协作多个任务。greentlet是python中实现我们所谓的"Coroutine(协程)"的一个基础库.
from greenlet import greenlet def test1(): print (12) gr2.switch() print (34) gr2.switch() def test2(): print (56) gr1.switch() print (78) gr1 = greenlet(test1) gr2 = greenlet(test2) gr1.switch()
4.2 基于greenlet的框架
4.2.1 gevent模块实现协程
Python通过yield提供了对协程的基本支持,但是不完全。而第三方的gevent为Python提供了比较完善的协程支持。
gevent是第三方库,通过greenlet实现协程,其基本思想是:
当一个greenlet遇到IO操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO。
由于切换是在IO操作时自动完成,所以gevent需要修改Python自带的一些标准库,这一过程在启动时通过monkey patch完成:
import gevent import time def foo(): print("running in foo") gevent.sleep(2) print("switch to foo again") def bar(): print("switch to bar") gevent.sleep(5) print("switch to bar again") start=time.time() gevent.joinall( [gevent.spawn(foo), gevent.spawn(bar)] ) print(time.time()-start)
当然,实际代码里,我们不会用gevent.sleep()去切换协程,而是在执行到IO操作时,gevent自动切换,代码如下:
from gevent import monkey monkey.patch_all() import gevent from urllib import request import time def f(url): print('GET: %s' % url) resp = request.urlopen(url) data = resp.read() print('%d bytes received from %s.' % (len(data), url)) start=time.time() gevent.joinall([ gevent.spawn(f, 'https://itk.org/'), gevent.spawn(f, 'https://www.github.com/'), gevent.spawn(f, 'https://zhihu.com/'), ]) # f('https://itk.org/') # f('https://www.github.com/') # f('https://zhihu.com/') print(time.time()-start)
eventlet实现协程(了解)
''' eventlet 是基于 greenlet 实现的面向网络应用的并发处理框架,提供“线程”池、队列等与其他 Python 线程、进程模型非常相似的 api,并且提供了对 Python 发行版自带库及其他模块的超轻量并发适应性调整方法,比直接使用 greenlet 要方便得多。 其基本原理是调整 Python 的 socket 调用,当发生阻塞时则切换到其他 greenlet 执行,这样来保证资源的有效利用。需要注意的是: eventlet 提供的函数只能对 Python 代码中的 socket 调用进行处理,而不能对模块的 C 语言部分的 socket 调用进行修改。对后者这类模块,仍然需要把调用模块的代码封装在 Python 标准线程调用中,之后利用 eventlet 提供的适配器实现 eventlet 与标准线程之间的协作。 虽然 eventlet 把 api 封装成了非常类似标准线程库的形式,但两者的实际并发执行流程仍然有明显区别。在没有出现 I/O 阻塞时,除非显式声明,否则当前正在执行的 eventlet 永远不会把 cpu 交给其他的 eventlet,而标准线程则是无论是否出现阻塞,总是由所有线程一起争夺运行资源。所有 eventlet 对 I/O 阻塞无关的大运算量耗时操作基本没有什么帮助。 '''
总结
协程的好处:
无需线程上下文切换的开销
无需原子操作锁定及同步的开销
方便切换控制流,简化编程模型
高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理。
缺点:
无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU上.当然我们日常所编写的绝大部分应用都没有这个必要,除非是cpu密集型应用。
进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序
五 IO模型
''' 同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分别是什么,到底有什么区别?这个问题其实不同的人给出的答案都可能不同,比如wiki,就认为asynchronous IO和non-blocking IO是一个东西。这其实是因为不同的人的知识背景不同,并且在讨论这个问题的时候上下文(context)也不相同。所以,为了更好的回答这个问题,先限定一下本文的上下文。 本文讨论的背景是Linux环境下的network IO。 Stevens在文章中一共比较了五种IO Model: blocking IO nonblocking IO IO multiplexing signal driven IO asynchronous IO 由于signal driven IO在实际中并不常用,所以我这只提及剩下的四种IO Model。 再说一下IO发生时涉及的对象和步骤。 对于一个network IO (这里我们以read举例),它会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。当一个read操作发生时,它会经历两个阶段: 等待数据准备 (Waiting for the data to be ready) 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process) 记住这两点很重要,因为这些IO Model的区别就是在两个阶段上各有不同的情况。 '''
selectors模块
import selectors import socket sel = selectors.DefaultSelector() def accept(sock, mask): conn, addr = sock.accept() # Should be ready print('accepted', conn, 'from', addr) conn.setblocking(False) sel.register(conn, selectors.EVENT_READ, read) def read(conn, mask): data = conn.recv(1000) # Should be ready if data: print('echoing', repr(data), 'to', conn) conn.send(data) # Hope it won't block else: print('closing', conn) sel.unregister(conn) conn.close() sock = socket.socket() sock.bind(('localhost', 1234)) sock.listen(100) sock.setblocking(False) sel.register(sock, selectors.EVENT_READ, accept) while True: events = sel.select() for key, mask in events: callback = key.data callback(key.fileobj, mask)

5.1 blocking IO (阻塞IO)
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
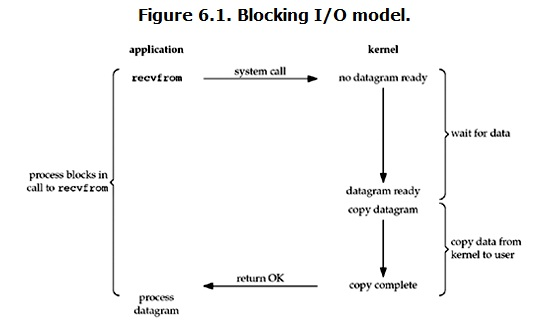
''' 当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据。对于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候kernel就要等待足够的数据到来。而在用户进程这边,整个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。 所以,blocking IO的特点就是在IO执行的两个阶段都被block了。 '''
5.2 non-blocking IO(非阻塞IO)
linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
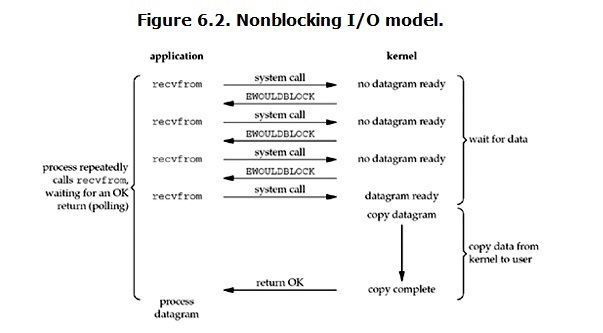
''' 从图中可以看出,当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。所以,用户进程其实是需要不断的主动询问kernel数据好了没有。 注意: 在网络IO时候,非阻塞IO也会进行recvform系统调用,检查数据是否准备好,与阻塞IO不一样,”非阻塞将大的整片时间的阻塞分成N多的小的阻塞, 所以进程不断地有机会 ‘被’ CPU光顾”。即每次recvform系统调用之间,cpu的权限还在进程手中,这段时间是可以做其他事情的, 也就是说非阻塞的recvform系统调用调用之后,进程并没有被阻塞,内核马上返回给进程,如果数据还没准备好,此时会返回一个error。进程在返回之后,可以干点别的事情,然后再发起recvform系统调用。重复上面的过程,循环往复的进行recvform系统调用。这个过程通常被称之为轮询。轮询检查内核数据,直到数据准备好,再拷贝数据到进程,进行数据处理。需要注意,拷贝数据整个过程,进程仍然是属于阻塞的状态。 ''' #############################server import time import socket sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM) sk.setsockopt sk.bind(('127.0.0.1',6667)) sk.listen(5) sk.setblocking(False) #非阻塞IO while True: try: print ('waiting client connection .......') connection,address = sk.accept() # 进程主动轮询,没有信息报错,用try、except捕获,并继续轮训 print("+++",address) client_messge = connection.recv(1024) print(str(client_messge,'utf8')) connection.close() except Exception as e: print (e) time.sleep(4) #############################client import time import socket sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM) while True: sk.connect(('127.0.0.1',6667)) print("hello") sk.sendall(bytes("hello","utf8")) time.sleep(2) break ''' 优点:能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在同时执行)。 缺点:任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。这会导致整体数据吞吐量的降低。 '''
5.3 IO multiplexing(IO多路复用)
select的优势在于可以处理多个连接,不适用于单个连接
IO multiplexing这个词可能有点陌生,但是如果我说select,epoll,大概就都能明白了。有些地方也称这种IO方式为event driven IO。我们都知道,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图:
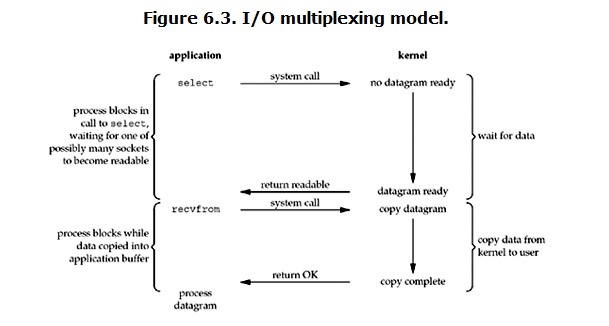
''' select(什么平台都有,Windows只能用这个,有最大链接上限,轮训(一定得走完一圈)) pool(没有链接上限,轮训(一定得走完一圈)) epoll(推荐,没有最大链接上限,不是轮训,是对象主动触发回调函数) '''
''' 当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。 这个图和blocking IO的图其实并没有太大的不同,事实上,还更差一些。因为这里需要使用两个system call (select 和 recvfrom),而blocking IO只调用了一个system call (recvfrom)。但是,用select的优势在于它可以同时处理多个connection。(多说一句。所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。) 在IO multiplexing Model中,实际中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。 结论: select的优势在于可以处理多个连接,不适用于单个连接 ''' # conn,addr=sock.accept() #默认是阻塞方式,等待客户端连接(accept 做了两件事,监听内存空间,拷贝收到的信息) #***********************server.py import socket import select sk=socket.socket() sk.bind(("127.0.0.1",8800)) sk.listen(5) sk.setblocking(False) inputs=[sk,] ##监听的套接字对象的列表 while True: r,w,e=select.select(inputs,[],[],5) #收,发,错误 三个列表,得到的r 也是列表 (只做了 监听工作,后面还得拷贝信息) print(len(r)) for obj in r: #r是监听的活动的socket if obj==sk: #sock 只是接收用户的链接信息,sock.accept()得到的conn才能接收客户端的之后发过来的具体信息 conn,add=obj.accept() print("conn:",conn) inputs.append(conn) else: data_byte=obj.recv(1024) print(str(data_byte,'utf8')) if not data_byte: inputs.remove(obj) continue inp=input('回答%s: >>>'%inputs.index(obj)) obj.sendall(bytes(inp,'utf8')) print('>>',r) #***********************client.py import socket sk=socket.socket() sk.connect(('127.0.0.1',8802)) while True: inp=input(">>>>") # how much one night? sk.sendall(bytes(inp,"utf8")) data=sk.recv(1024) print(str(data,'utf8')) ''' 思考1:select监听fd变化的过程 用户进程创建socket对象,拷贝监听的fd到内核空间,每一个fd会对应一张系统文件表,内核空间的fd响应到数据后,就会发送信号给用户进程数据已到;用户进程再发送系统调用,比如(accept)将内核空间的数据copy到用户空间,同时作为接受数据端内核空间的数据清除,这样重新监听时fd再有新的数据又可以响应到了(发送端因为基于TCP协议所以需要收到应答后才会清除)。 思考2: 上面的示例中,开启三个客户端,分别连续向server端发送一个内容(中间server端不回应),结果会怎样,为什么?(只显示第一个信息,回复之后第二个,之后第三个) '''
5.4 Asynchronous I/O(异步IO)
linux下的asynchronous IO其实用得很少。先看一下它的流程:
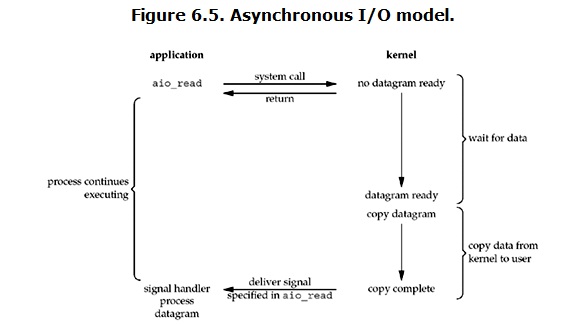
''' 用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。 '''
5.5 IO模型比较分析
各个IO Model的比较如图所示:
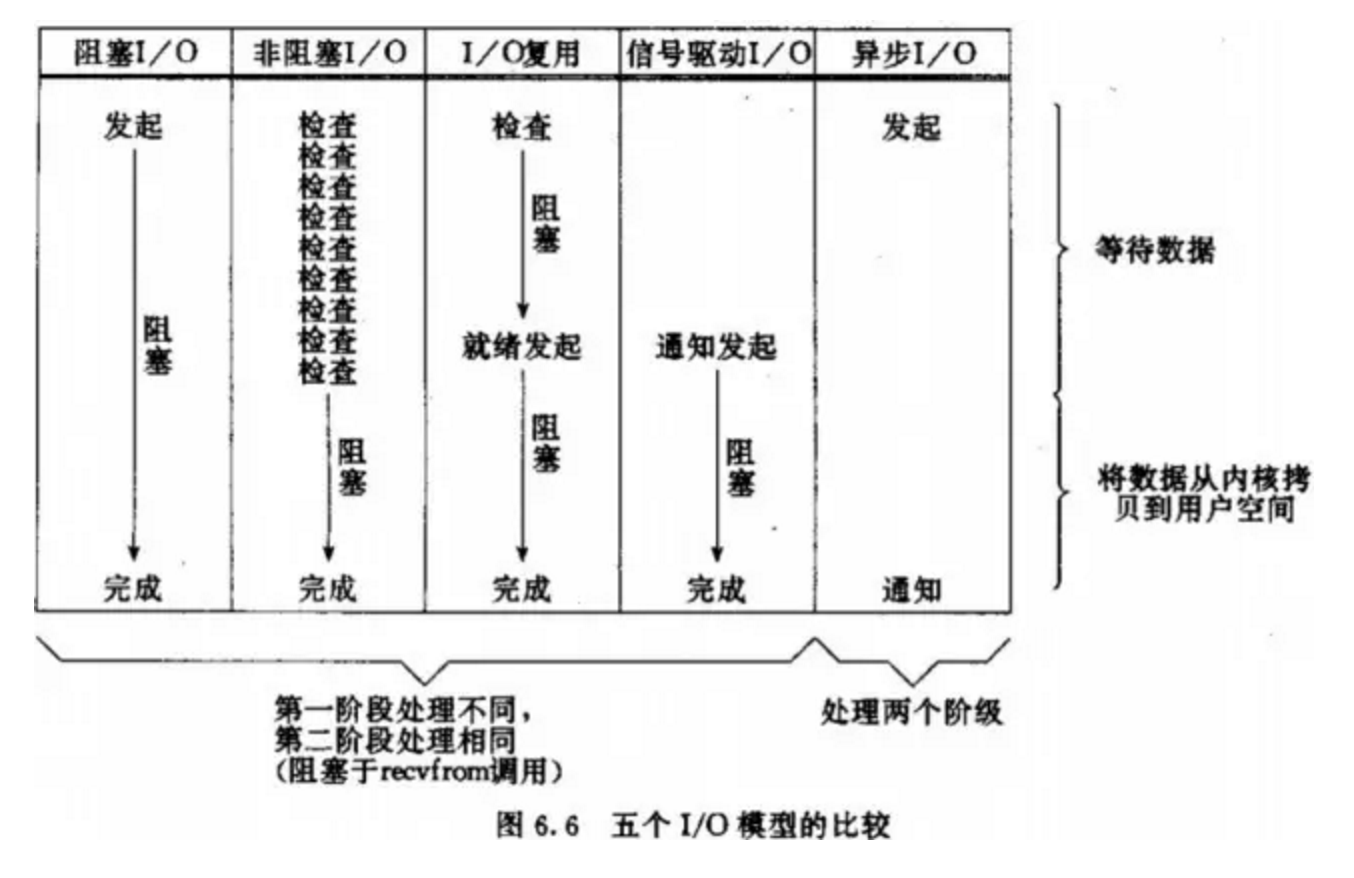
到目前为止,已经将四个IO Model都介绍完了。现在回过头来回答最初的那几个问题:blocking和non-blocking的区别在哪,synchronous IO和asynchronous IO的区别在哪。 先回答最简单的这个:blocking vs non-blocking。前面的介绍中其实已经很明确的说明了这两者的区别。调用blocking IO会一直block住对应的进程直到操作完成,而non-blocking IO在kernel还准备数据的情况下会立刻返回。 在说明synchronous IO和asynchronous IO的区别之前,需要先给出两者的定义。Stevens给出的定义(其实是POSIX的定义)是这样子的: A synchronous I/O operation causes the requesting process to be blocked until that I/O operationcompletes; An asynchronous I/O operation does not cause the requesting process to be blocked; 两者的区别就在于synchronous IO做”IO operation”的时候会将process阻塞。按照这个定义,之前所述的blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO。有人可能会说,non-blocking IO并没有被block啊。这里有个非常“狡猾”的地方,定义中所指的”IO operation”是指真实的IO操作,就是例子中的recvfrom这个system call。non-blocking IO在执行recvfrom这个system call的时候,如果kernel的数据没有准备好,这时候不会block进程。但是,当kernel中数据准备好的时候,recvfrom会将数据从kernel拷贝到用户内存中,这个时候进程是被block了,在这段时间内,进程是被block的。而asynchronous IO则不一样,当进程发起IO 操作之后,就直接返回再也不理睬了,直到kernel发送一个信号,告诉进程说IO完成。在这整个过程中,进程完全没有被block。 经过上面的介绍,会发现non-blocking IO和asynchronous IO的区别还是很明显的。在non-blocking IO中,虽然进程大部分时间都不会被block,但是它仍然要求进程去主动的check,并且当数据准备完成以后,也需要进程主动的再次调用recvfrom来将数据拷贝到用户内存。而asynchronous IO则完全不同。它就像是用户进程将整个IO操作交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查IO操作的状态,也不需要主动的去拷贝数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号