
摘要: 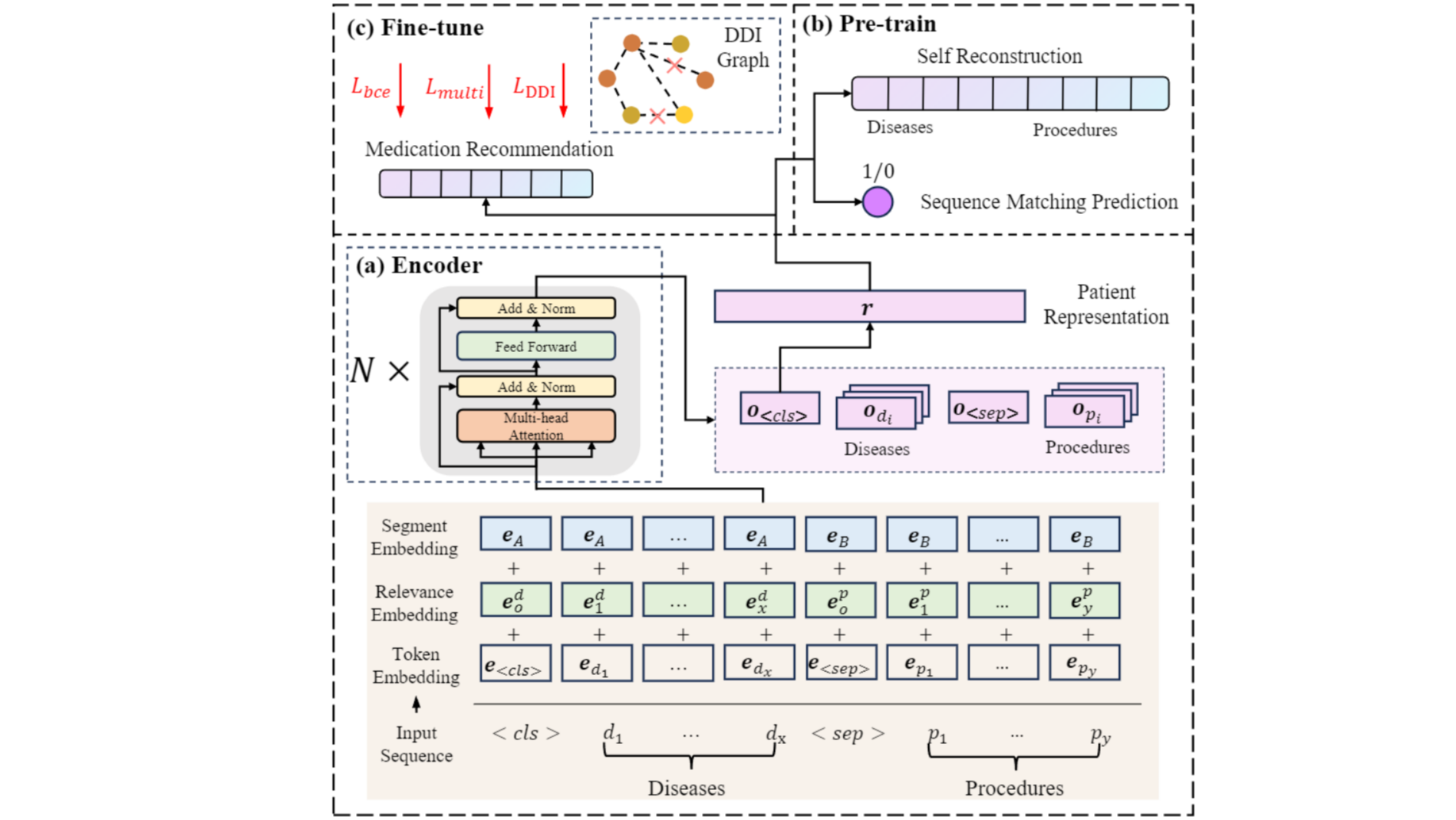 在本文中,我们针对药物推荐模型对罕见病患者推荐精度低的问题,提出了一种新的基于预训练-微调的药物推荐模型框架**RAREMed**,并提出了两个针对性的预训练任务,来提高模型对患者病情,尤其是罕见病患者病情的表示学习能力,帮助药物推荐模型提高对罕见病患者的推荐准确度,从而提升药物推荐模型的公平性。我们在两个常用的公开数据集上的实验结果显示出我们的方法在药物推荐模型的准确度和公平性方面有着显著优势。 阅读全文
在本文中,我们针对药物推荐模型对罕见病患者推荐精度低的问题,提出了一种新的基于预训练-微调的药物推荐模型框架**RAREMed**,并提出了两个针对性的预训练任务,来提高模型对患者病情,尤其是罕见病患者病情的表示学习能力,帮助药物推荐模型提高对罕见病患者的推荐准确度,从而提升药物推荐模型的公平性。我们在两个常用的公开数据集上的实验结果显示出我们的方法在药物推荐模型的准确度和公平性方面有着显著优势。 阅读全文
在本文中,我们针对药物推荐模型对罕见病患者推荐精度低的问题,提出了一种新的基于预训练-微调的药物推荐模型框架**RAREMed**,并提出了两个针对性的预训练任务,来提高模型对患者病情,尤其是罕见病患者病情的表示学习能力,帮助药物推荐模型提高对罕见病患者的推荐准确度,从而提升药物推荐模型的公平性。我们在两个常用的公开数据集上的实验结果显示出我们的方法在药物推荐模型的准确度和公平性方面有着显著优势。 阅读全文
posted @ 2024-10-11 22:50
子豪君
阅读(803)
评论(0)
推荐(2)
 浙公网安备 33010602011771号
浙公网安备 33010602011771号