

python——scrapy利用cookie模拟登录
适用场景:cookie过期时间较长,足够你完成爬取过程
1、基础
2、找cookie,改start_urls
3、cookie转为字典
4、修改setting.py
> 1、基础
创建项目
```python
scrapy startproject 名称
```
生成爬虫
```python
scrapy genspider 爬虫名 允许爬取域名
```
运行
```python
scrapy crawl 爬虫名
```
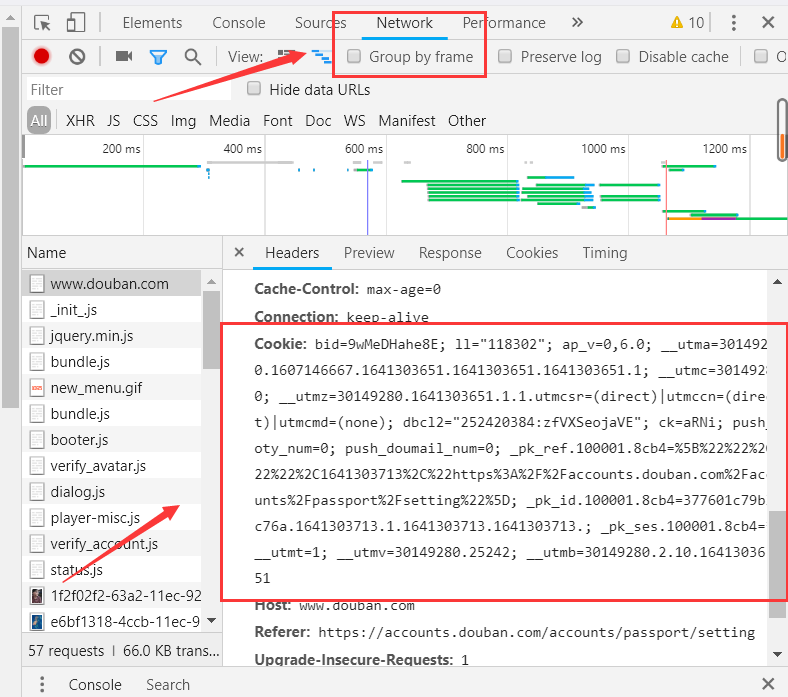
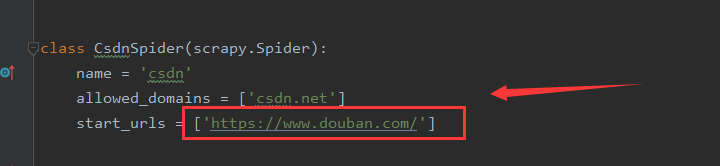
> 2、找cookie,按F12寻找,一般在network的第一个包中;将start_urls改为豆瓣网址,以豆瓣为例
> 3、cookie转为字典,构造请求并把请求交给引擎,callback指定解析函数名称,默认为parse;cookie接受字典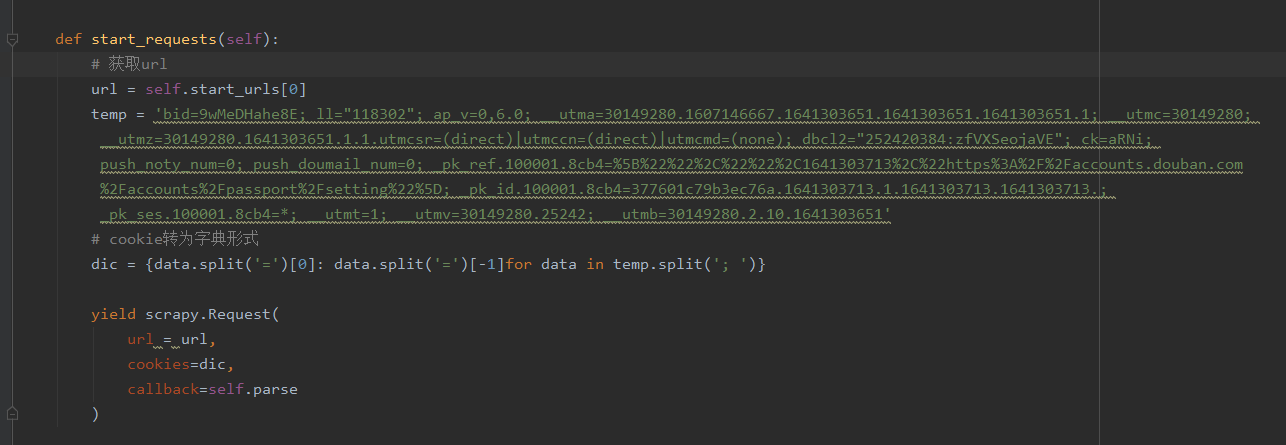
> 4、更改setting中的user_agent和和注释掉ROBOTSTXT_OBEY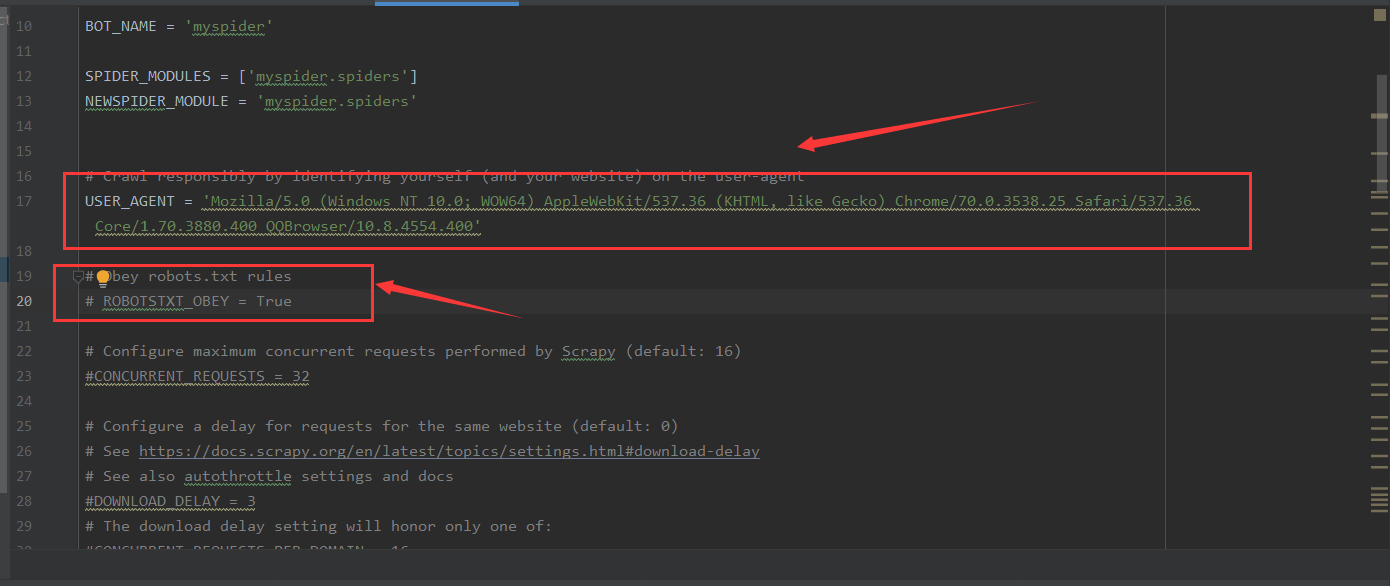
> 完成,部分结果截图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号