爬虫(四)数据清洗-正则表达式
正则表达式介绍
正则表达式
即,数据筛选的表达方式(匹配)
import re strr = "张三李四王五赵六" pat = "王五" # 正则表达式 rst = re.search(pat,strr) print(rst)

体验-分析《天龙八部》主角到底是谁
import re
with open(r"C:\\Users\\Administrator\\Desktop\\tianlong.txt","rb") as f:
data = f.read().decode()
pat1 = "乔峰"
pat2 = "萧峰"
pat3 = "乔帮主"
pat4 = "段誉"
pat5 = "虚竹"
n1 = re.findall(pat1,data)
n2 = re.findall(pat2,data)
n3 = re.findall(pat3,data)
n4 = re.findall(pat4,data)
n5 = re.findall(pat5,data)
print("乔峰出现次数:",len(n1)+len(n2)+len(n3),"段誉出现次数:",len(n4),"虚竹出现次数:",len(n5))

匹配普通字符
原子:正则表达式中实现匹配的基本单位
元字符:正则表达式中具有特殊含义的字符
以普通字符作为原子(匹配一个普通字符)
import re a = "湖南湖北广东广西" pat = "湖北" result = re.search(pat,a) print(result)

匹配通用字符
匹配通用字符
- \w 任意字母、数字、下划线
- \W 和小写w相反
- \d 十进制数字
- \D 除了十进制以外的值
- \s 空白字符
- \S 非空白字符
import re b = "13617054927" part = "\d\d\d\d\d\d\d\d\d\d\d" result = re.search(part,b) print(result)

import re # b = "13617054927" # # part = "\d\d\d\d\d\d\d\d\d\d\d" # # result = re.search(part,b) # # print(result) c1 = "fj2d9fj92jfoejf934jtoerjgfosjgo3u0t34" c2 = "@@@@@@@@2jfoejf934jtoerjgfosjgo3u0t34" part = r"\w\w\w" print(re.search(part,c1)) print(re.search(part,c2))

匹配数字、中文、英文
数字:[0,9]
英文:[A-Z][a-z]
中文:[\u4e00-\u9fa5]
import re
# 数字:[0,9]
# 英文:[A-Z][a-z]
# 中文:[\u4e00-\u9fa5]
d = "f920U)F)jf302rk3fkrelgb即300为热裤股票开盘部分的可怕扩容394u093rfj34ofH"
part1 = r"[0,9][0,9]"
part2 = r"[a-z][a-z]"
part3 = r"[\u4e00-\u9fa5][\u4e00-\u9fa5]"
result1 = re.search(part1,d)
result2 = re.search(part2,d)
result3 = re.search(part3,d)
print("result1:",result1,"result2:",result2,"result3:",result3)

原子表
原子表:是定义一组平等的原子,这组原子中,只要有一个满足条件那就匹配成功
import re b = "13822748902" part = "1[3572]\d\d\d\d\d\d\d\d\d" # 可以匹配以1开头第二位3、5、7或2的数字 print(re.search(part,b)) c = "djfoejfoj4pychonrj4oj43o9r034" part2 = r"py[abcdt]hon" # 可以匹配以py开头后面a\b\c\d\t当中满足任意一个即可 print(re.search(part2,c))

常用元字符
元字符:正则表达式中具有特殊意义的字符
- · . 匹配任意字符 \n除外
- · ^ 匹配字符串开始的位置 ^136
- · $ 匹配字符串结束的位置 6666$
- · * 重复0次1次多次前面的原子 /d*
- · ? 重复一次或者多次前面的原子 /d?要么有1个数字或者多个数字
- · + 重复一次或多次前面的原子 /d+
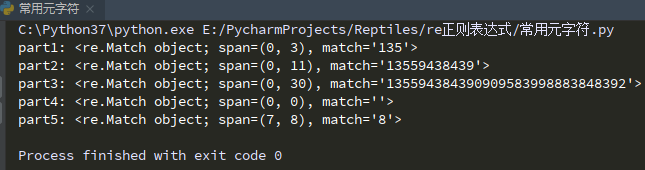
import re
d = "135594384390909583998883848392"
part1 = "..."
part2 = "135\d\d\d\d\d\d\d\d"
part3 = ".*8392$"
part4 = "8*"
part5 = "8+"
print("part1:",re.search(part1,d))
print("part2:",re.search(part2,d))
print("part3:",re.search(part3,d))
print("part4:",re.search(part4,d))
print("part5:",re.search(part5,d))
匹配固定次数
我们需要元组固定出现多少次
{n} 前面的原子出现了n次
{n,} 至少出现n次
{n,m} 出现次数介于n-m之间
import re
a = "2345654jisw"
part1 = r"\d{6}"
part2 = r"\d{4,}" # 至少4位字符
part3 = r"\S{8,10}" # \S 非空白字符
print(re.search(part1,a))
print(re.search(part2,a))
print(re.search(part3,a))

匹配多个正则表达式
多个表达式 |
import re
a = "13409537832"
b = "021-8333627"
part1 = r"1[3578]\d{9}"
part2 = r"\d{3}-\d{7}"
part3 = r"1[3578]\d{9}|\d{3}-\d{7}" # 满足两个正则表达式
print(re.search(part1,a))
print(re.search(part2,b))
print(re.search(part3,a))
print(re.search(part3,b))

分组
import re
# 分组()
a = "jiwdfdjskjfoe#pythonR$Wr2roef2#rjavafdsfe#$@$FSFWFDS13876439027FSF#@$RGFSA@$34"
part1 = r"python.{0,}java.{0,}1[3578]\d{9}"
part2 = r"(python).{0,}(java).{0,}(1[3578]\d{9})"
part3 = r"FDS(.*?)FSF"
print(re.search(part1,a))
print(re.search(part2,a).group(1)) # 1表示第一个分组python
print(re.search(part2,a).group(2)) # 2表示第一个分组java
print(re.search(part3,a).group(1)) # 只获取括号内的电话号码
print(re.findall(part3,a)) # 只获取括号内的电话号码

贪婪模式和非贪婪模式
贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配
非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配
python里默认是贪婪的
import re strr = "aa<div>test1</div>bb<div>test2</div>cc<div>test3</div>dd" part1 = r"<div>.*</div>" part2 = r"<div>.*?</div>" # 加上问好 就是【非贪婪模式】 part3 = r"<div>(.*?)</div>" print(re.search(part1,strr)) # 贪婪模式 print(re.search(part2,strr)) # 非贪婪模式 print(re.findall(part3,strr))

compile函数
compile函数--将正则表达式转换成内部格式,提高执行效率
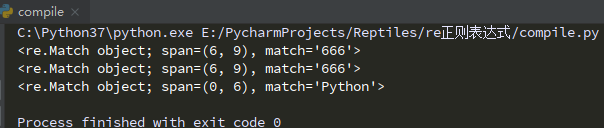
import re strr = "Python666java" part1 = r"\d+" part2= re.compile(r"\d+") part3= re.compile(r"python",re.I) # re.I模式修正符:忽略大小写 print(re.search(part1,strr)) print(part2.search(strr)) print(part3.search(strr))
match函数和search函数
· match函数-匹配开头
· search函数-匹配任意位置
这两个函数都是一次匹配,就是说匹配到一次就不再匹配了
import re strr = "pythonjavahtmljs" part1 = re.compile(r"python") part2 = re.compile(r"java") print(part1.match(strr)) print(part2.search(strr)) print(part1.match(strr).group())

findall()函数finditer()函数
· findall() 查找所有匹配的内容,装到列表中
· finditer() 查找所有匹配的内容,装到迭代器中
迭代器:可以用for循环取出来
import re
strr = r"hello-----------------------------------\------------------\--------hello--hello-----------------hello----------\hello------"
part1 = re.compile(r"hello")
print(part1.findall(strr)) # findall效率更高一些
data = part1.finditer(strr)
list1 = []
for i in data:
print(i.group())
list1.append(i.group())
print("list:",list1)

split()函数和sub()函数
· split() 按照能够匹配的子串将字符串分割后返回列表
· sub() sub方法用于替换
import re
strr1 = "张三,李四,,,王五,,,,,,赵六"
part1 = re.compile(r",+")
result1 = part1.split(strr1)
print(result1)
strr2 = "hello 123,hello 456"
part2 = re.compile(r"\d+")
result2 = part2.sub("666",strr2) # sub()里传两个参数
print(result2)

爬取网站电话号码
http://changyongdianhuahaoma.51240.com/
import requests
import re
#构造请求头信息
header={
"User-Agent":"Mozilla/5.0 (Linux; U; An\
droid 8.1.0; zh-cn; BLA-AL00 Build/HUAW\
EIBLA-AL00) AppleWebKit/537.36 (KHTML, l\
ike Gecko) Version/4.0 Chrome/57.0.2987.13\
2 MQQBrowser/8.9 Mobile Safari/537.36"
}
url = "http://changyongdianhuahaoma.51240.com/"
response = requests.get(url,headers=header).text
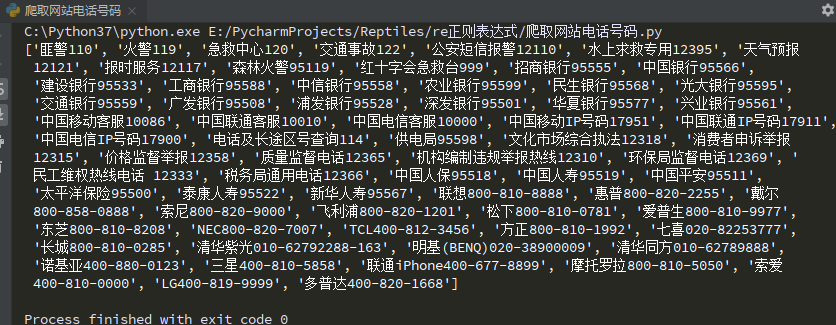
part1 = r'<tr bgcolor="#EFF7F0">[\s\S]*?<td>(.*?)</td>[\s\S]*?<td>[\s\S]*?</td>[\s\S]*?</tr>'
part2 = r'<tr bgcolor="#EFF7F0">[\s\S]*?<td>[\s\S]*?</td>[\s\S]*?<td>(.*?)</td>[\s\S]*?</tr>'
pattern1 = re.compile(part1)
pattern2 = re.compile(part2)
data1 = pattern1.findall(response)
data2 = pattern2.findall(response)
# print(data1)
# print(data2)
resultList = []
for i in range(0,len(data1)):
resultList.append(data1[i]+data2[i])
print(resultList)
爬取豆瓣电影排行榜
import re
import requests
import time
# 首 页html-url http://movie.douban.com/top250?start=0&filter=
# 第2页html-url http://movie.douban.com/top250?start=25&filter=
# 第2页html-url http://movie.douban.com/top250?start=50&filter=
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
resultList = []
for i in range(1,11):
url = "http://movie.douban.com/top250?start=" + str((i-1)*25) + "&filter="
response = requests.get(url,headers = header).text
part1 = r'<em class="">(.*?)</em>[\s\S]*?<a href="https://movie.douban.com/subject/[\s\S]*?/">[\s\S]*?<img width="100" alt="[\s\S]*?" src'
part2 = r'<em class="">[\s\S]*?</em>[\s\S]*?<a href="https://movie.douban.com/subject/[\s\S]*?/">[\s\S]*?<img width="100" alt="(.*?)" src'
parttern1 = re.compile(part1)
parttern2 = re.compile(part2)
data1 = parttern1.findall(response)
data2 = parttern2.findall(response)
for k in range(0,len(data1)):
resultList.append(data1[k]+data2[k])
print(resultList)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号