爬虫(三)requests库数据挖掘
requests安装和使用
pip install requests
用requests获取百度html代码
import requests url = 'http://www.baidu.com' response = requests.get(url).content.decode() print(response)
添加请求头和参数
import requests
url = 'http://www.baidu.com/s?'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36"
}
wd = {"wd":"中国"}
response = requests.get(url,params=wd,headers=headers)
data = response.text # 表示返回一个字符串形式数据
data2 = response.content # 表示返回一个二进制形式数据
print(data)

处理POST请求
使用上一章正则表达式获取有道翻译的post请求
import requests
import re
#构造请求头信息
header={
"User-Agent":"Mozilla/5.0 (Linux; U; An\
droid 8.1.0; zh-cn; BLA-AL00 Build/HUAW\
EIBLA-AL00) AppleWebKit/537.36 (KHTML, l\
ike Gecko) Version/4.0 Chrome/57.0.2987.13\
2 MQQBrowser/8.9 Mobile Safari/537.36"
}
url="http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
key="自学"
#post请求需要提交的参数
formdata={
"i":key,
"from":"AUTO",
"to":"AUTO",
"smartresult":"dict",
"client":"fanyideskweb",
"salt":"15503049709404",
"sign":"3da914b136a37f75501f7f31b11e75fb",
"ts":"1550304970940",
"bv":"ab57a166e6a56368c9f95952de6192b5",
"doctype":"json",
"version":"2.1",
"keyfrom":"fanyi.web",
"action":"FY_BY_REALTIME",
"typoResult":"false"
}
response = requests.post(url,headers=header,data=formdata)
data = response.json()
data2 = response.text
data3 = response.content
# 正则表达式,提取"tgt":"self-study"}]]}中间的变量
pat = r'"tgt":"(.*?)"}]]}'
result = re.findall(pat,response.text)
print(result)

代理IP
import requests
# 设置ip地址
# proxy = {"http":"http://代理IP地址:端口号"}
proxy = {"http":"http://118.113.247.26:9999"}
url = "http://www.baidu.com"
response = requests.get(url,proxies=proxy)
print(response)
获取响应cookie
import requests url = 'http://www.baidu.com' response = requests.get(url) # 1、获取返回的cookiejar对象 cookiejar = response.cookies # 2、将cookiejar转换成字典 cookiedict = requests.utils.dict_from_cookiejar(cookiejar) print(cookiedict)

seesion实现登录
import requests
url = "http://www.renren.com/Plogin.do"
header={
"User-Agent":"Mozilla/5.0 (Linux; U; An\
droid 8.1.0; zh-cn; BLA-AL00 Build/HUAW\
EIBLA-AL00) AppleWebKit/537.36 (KHTML, l\
ike Gecko) Version/4.0 Chrome/57.0.2987.13\
2 MQQBrowser/8.9 Mobile Safari/537.36"
}
# 创建一个session对象
ses = requests.session()
# 构造登录需要的参数
data={"email":"binzi_chen@126.com","password":"5tgb^YHN"}
# 通过传递用户名密码得到cookie信息
ses.post(url,data=data)
# 请求需要的页面
response = ses.get("http://www.renren.com/880151237/profile")
print(response.text)

实战爬取音乐资源
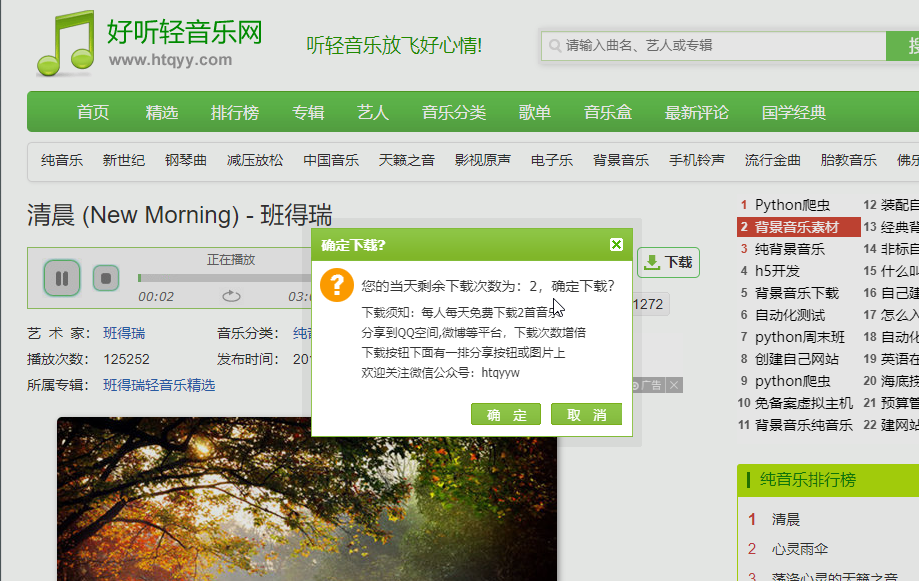
爬虫是为了破解只能下载两次的限制

import re # 引入正则表达式库
import requests
import time
# http://www.htqyy.com/top/musicList/hot?pageIndex=1&pageSize=20 # 第一页
# http://www.htqyy.com/top/musicList/hot?pageIndex=1&pageSize=20 # 第二页
# http://www.htqyy.com/top/musicList/hot?pageIndex=2&pageSize=20 # 第三页
# 页码-1
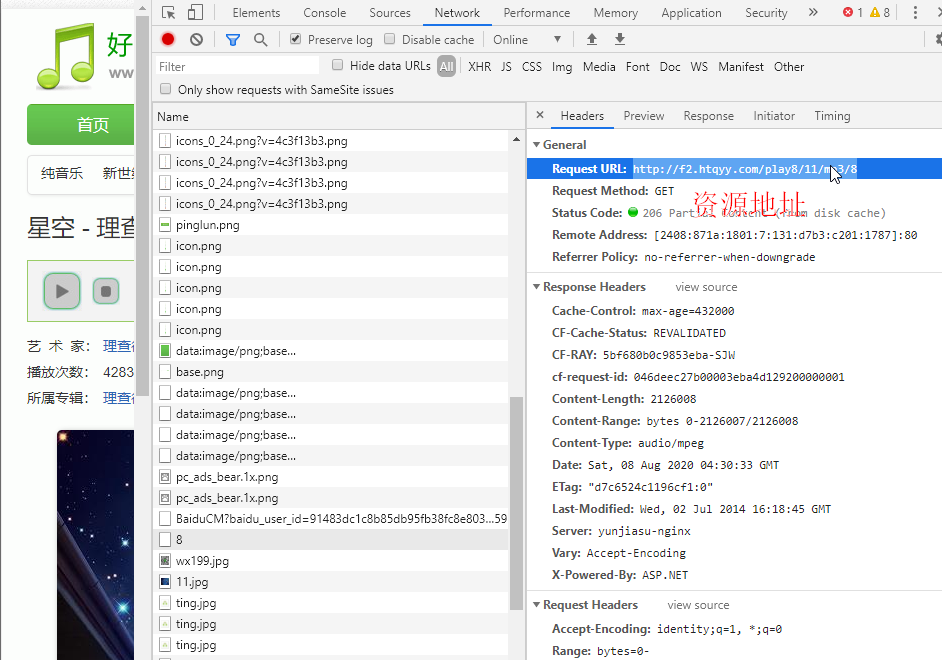
# 歌曲url http://www.htyy.com/play/20
# 播放资源 http://f2.htqyy.com/play8/11/mp3/8
# page = int(input("请输入您要爬取的页数:"))
header = {
"Referer":"http://www.htqyy.com/top/hot"
}
songID = []
songName = []
for i in range(0,2):
url = "http://www.htqyy.com/top/musicList/hot?pageIndex="+ str(i)+"&pageSize=20"
# 获取音乐榜单的网页信息
html = requests.get(url,headers=header)
strr = html.text
# print(strr)
# class ="title" > < a href="/play/33" target="play" title="清晨" sid="33" > 清晨 < / a > < / span >
part1 = r'title="(.*?)" sid'
part2 = r'sid="(.*?)"'
idlist = re.findall(part2,strr)
titlelist = re.findall(part1,strr)
songID.extend(idlist) # extend()把两个列表合成一个列表
songName.extend(titlelist)
print("歌曲列表:",songName)
print("歌曲ID:",songID)
for i in range(0,len(songID)):
songUrl = "http://f2.htqyy.com/play8/" + str(songID[i]) + "/mp3/8"
song = songName[i]
data = requests.get(songUrl).content
with open("D:\\Documents\\Music\\{}.mp3".format(song),"wb") as f:
f.write(data)
time.sleep(0.5)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号