
批处理-- SparkCore
数据源-source
1. 加载本地集合,转换为RDD
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//parallelize :并行化,平行化
object Parallelize {
def main(args: Array[String]): Unit = {
//1. 创建上下文对象,并加载参数配置对象 (相当于创建客户端连接对象)
//1.1 创建参数配置对象
val sparkConf: SparkConf = new SparkConf()
//获取本类class文件的类名,并剔除结尾的$
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[*]")
//1.2 创建上下文对象,加载参数配置
val sc = new SparkContext(sparkConf)
//设置log级别
sc.setLogLevel("WARN")
//2. 加载指定文件(绝对路径),生成了一个RDD
//2.1 创建一个scala集合,Seq相当于List列表
val linesSeq:Seq[String] = Seq(
"tian di ren jie",
"tian di ren",
"tian di",
"ren"
)
//2.2 加载scala本地集合Seq得到RDD (并行化)
val inputRDD:RDD[String] = sc.parallelize(linesSeq,2)
//3. 处理RDD (\s表示广义的空白符,包括换行,空格,tab键等)
val wordcountRDD:RDD[(String,Int)] = inputRDD
.flatMap(_.split("\\s+"))
.map((_,1))
.reduceByKey(_+_)
//4. 将结果输出到指定目录
//将结果打印出来
wordcountRDD.foreach(println(_))
//5. 关闭上下文对象(客户端连接对象)
sc.stop()
}
}
2. 加载外部数据源
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//parallelize :并行化,平行化
object TextFile {
def main(args: Array[String]): Unit = {
//1. 创建上下文对象,并加载参数配置对象 (相当于创建客户端连接对象)
//1.1 创建参数配置对象
val sparkConf: SparkConf = new SparkConf()
//获取本类class文件的类名,并剔除结尾的$
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[*]")
//1.2 创建上下文对象,加载参数配置
val sc = new SparkContext(sparkConf)
//设置log级别
sc.setLogLevel("WARN")
//2. 加载指定文件(绝对路径),生成了一个RDD
//使用textFile加载文本形成RDD
val inputRDD: RDD[String] = sc.textFile("data/words.txt",2)
//3. 处理RDD (\s表示广义的空白符,包括换行,空格,tab键等)
val wordcountRDD:RDD[(String,Int)] = inputRDD
.flatMap(_.split("\\s+"))
.map((_,1))
.reduceByKey(_+_)
//4. 将结果输出到指定目录
//将结果打印出来
wordcountRDD.foreach(println(_))
//5. 关闭上下文对象(客户端连接对象)
sc.stop()
}
}
3. 加载多个小文件
- 使用SparkContext中提供:【wholeTextFiles】方法,专门读取小文件数据。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WhoTextFiles {
def main(args: Array[String]): Unit = {
//1. 创建上下文对象,并加载参数配置对象 (相当于创建客户端连接对象)
//1.1 创建参数配置对象
val sparkConf: SparkConf = new SparkConf()
//获取本类class文件的类名,并剔除结尾的$
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[*]")
//1.2 创建上下文对象,加载参数配置
val sc = new SparkContext(sparkConf)
//设置log级别
sc.setLogLevel("WARN")
//2. 加载指定文件(绝对路径),生成了一个RDD
//用wholeTextFile加载ratings10下面的小文件,设置分区数为2,得到RDD
val inputRDD: RDD[(String,String)] = sc.wholeTextFiles("data/input/ratings10",2)
println("分区数:" + inputRDD.getNumPartitions)
inputRDD.foreach(println(_))
//3. 处理RDD (\s表示广义的空白符,包括换行,空格,tab键等)
//--->统计RDD共有多少行
inputRDD.map(_._2).foreach(println(_))
val linesRDD:RDD[String] = inputRDD.map(_._2).flatMap(_.split("\n"))
//4. 将结果输出到指定目录
//将结果打印出来
println("总共的行数:" + linesRDD.count())
//5. 关闭上下文对象(客户端连接对象)
sc.stop()
}
}
4. 读写MySQL
- 分析结果RDD保存至MySQL表中,使用foreachPartition函数;此外Spark中提供JdbcRDD用于从MySQL表中读取数据。
- 调用RDD#foreachPartition函数将每个分区数据保存至MySQL表中,保存时考虑降低RDD分区数目和批量插入,提升程序性能。
import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet}
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.{JdbcRDD, RDD}
/**
* Author itcast
* Desc 演示使用Spark将数据写入到MySQL,再从MySQL读取出来
*/
object SparkJdbcDataSource {
def main(args: Array[String]): Unit = {
//1.创建SparkContext
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[*]")
val sc: SparkContext = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
//2.准备数据
val data: RDD[(String, Int)] = sc.parallelize(List(("jack", 18), ("tom", 19), ("rose", 20)))
//3.将RDD中的数据保存到MySQL中去
//将每一个分区中的数据保存到MySQL中去,有几个分区,就会开启关闭连接几次
//data.foreachPartition(itar=>dataToMySQL(itar))
data.foreachPartition(dataToMySQL) //方法即函数,函数即对象
//4.从MySQL读取数据
/*
class JdbcRDD[T: ClassTag](
sc: SparkContext,
getConnection: () => Connection,
sql: String,
lowerBound: Long,
upperBound: Long,
numPartitions: Int,
mapRow: (ResultSet) => T = JdbcRDD.resultSetToObjectArray _)
*/
val getConnection = ()=> DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8","root","root")
val sql:String = "select id,name,age from t_student where id >= ? and id <= ?"
val mapRow = (rs:ResultSet) => {
val id: Int = rs.getInt(1)
val name: String = rs.getString(2)
val age: Int = rs.getInt("age")
(id,name,age)
}
val studentRDD: JdbcRDD[(Int, String, Int)] = new JdbcRDD(sc,getConnection,sql,4,5,2,mapRow)
println(studentRDD.collect().toBuffer)
}
/**
* 将分区中的数据保存到MySQL
* @param itar 传过来的每个分区有多条数据
*/
def dataToMySQL(itar: Iterator[(String, Int)]): Unit = {
//0.加载驱动
//Class.forName("") //源码中已经加载了
//1.获取连接
val connection: Connection =
DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8","root","root")
//2.编写sql
val sql:String = "INSERT INTO `t_student` (`name`, `age`) VALUES (?, ?);"
//3.获取ps
val ps: PreparedStatement = connection.prepareStatement(sql)
itar.foreach(data=>{
//4.设置参数
ps.setString(1,data._1)
ps.setInt(2,data._2)
//5.执行sql
ps.addBatch()
})
ps.executeBatch()
ps.close()
connection.close()
}
}
5. 读写HBase
- Spark可以从HBase表中读写(Read/Write)数据,底层采用TableInputFormat和TableOutputFormat方式,与MapReduce与HBase集成完全一样,使用输入格式InputFormat和输出格式OutputFoamt。
读Hbase
- MapReduce从读HBase表中的数据,使用TableMapper,其中InputFormat为TableInputFormat,读取数据Key:ImmutableBytesWritable,Value:Result。
- 从HBase表读取数据时,同样需要设置依赖Zookeeper地址信息和表的名称,使用Configuration设置属性,形式如下:
![image]()
- 此外,读取的数据封装到RDD中,Key和Value类型分别为:ImmutableBytesWritable和Result,不支持Java Serializable导致处理数据时报序列化异常。设置Spark Application使用Kryo序列化,性能要比Java 序列化要好,创建SparkConf对象设置相关属性,如下所示:
![image]()

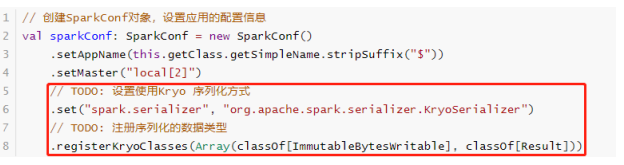
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.{CellUtil, HBaseConfiguration}
import org.apache.hadoop.hbase.client.Result
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 从HBase 表中读取数据,封装到RDD数据集
*/
object SparkReadHBase {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[*]")
val sc: SparkContext = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
// 读取HBase Client 配置信息
val conf: Configuration = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "node1")
conf.set("hbase.zookeeper.property.clientPort", "2181")
conf.set("zookeeper.znode.parent", "/hbase")
// 设置读取的表的名称
conf.set(TableInputFormat.INPUT_TABLE, "htb_wordcount")
/*
def newAPIHadoopRDD[K, V, F <: NewInputFormat[K, V]](
conf: Configuration = hadoopConfiguration,
fClass: Class[F],
kClass: Class[K],
vClass: Class[V]
): RDD[(K, V)]
*/
val resultRDD: RDD[(ImmutableBytesWritable, Result)] = sc.newAPIHadoopRDD(
conf,
classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result]
)
println(s"Count = ${resultRDD.count()}")
resultRDD
.take(5)
.foreach { case (rowKey, result) =>
println(s"RowKey = ${Bytes.toString(rowKey.get())}")
// HBase表中的每条数据封装在result对象中,解析获取每列的值
result.rawCells().foreach { cell =>
val cf = Bytes.toString(CellUtil.cloneFamily(cell))
val column = Bytes.toString(CellUtil.cloneQualifier(cell))
val value = Bytes.toString(CellUtil.cloneValue(cell))
val version = cell.getTimestamp
println(s"\t $cf:$column = $value, version = $version")
}
}
// 应用程序运行结束,关闭资源
sc.stop()
}
}
写Hbase
- MapReduce向HBase表中写入数据,使用TableReducer,其中OutputFormat为TableOutputFormat,读取数据Key:ImmutableBytesWritable,Value:Put。
- 写入数据时,需要将RDD转换为RDD[(ImmutableBytesWritable, Put)]类型,调用saveAsNewAPIHadoopFile方法数据保存至HBase表中。
- HBase Client连接时,需要设置依赖Zookeeper地址相关信息及表的名称,通过Configuration设置属性值进行传递。
![image]()
![image]()


import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.Put
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 将RDD数据保存至HBase表中
*/
object SparkWriteHBase {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[*]")
val sc: SparkContext = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
// 构建RDD
val list = List(("hadoop", 234), ("spark", 3454), ("hive", 343434), ("ml", 8765))
val outputRDD: RDD[(String, Int)] = sc.parallelize(list, numSlices = 2)
// 将数据写入到HBase表中, 使用saveAsNewAPIHadoopFile函数,要求RDD是(key, Value)
// 组装RDD[(ImmutableBytesWritable, Put)]
/**
* HBase表的设计:
* 表的名称:htb_wordcount
* Rowkey: word
* 列簇: info
* 字段名称: count
*/
val putsRDD: RDD[(ImmutableBytesWritable, Put)] = outputRDD.mapPartitions { iter =>
iter.map { case (word, count) =>
// 创建Put实例对象
val put = new Put(Bytes.toBytes(word))
// 添加列
put.addColumn(
// 实际项目中使用HBase时,插入数据,先将所有字段的值转为String,再使用Bytes转换为字节数组
Bytes.toBytes("info"), Bytes.toBytes("cout"), Bytes.toBytes(count.toString)
)
// 返回二元组
(new ImmutableBytesWritable(put.getRow), put)
}
}
// 构建HBase Client配置信息
val conf: Configuration = HBaseConfiguration.create()
// 设置连接Zookeeper属性
conf.set("hbase.zookeeper.quorum", "node1")
conf.set("hbase.zookeeper.property.clientPort", "2181")
conf.set("zookeeper.znode.parent", "/hbase")
// 设置将数据保存的HBase表的名称
conf.set(TableOutputFormat.OUTPUT_TABLE, "htb_wordcount")
/*
def saveAsNewAPIHadoopFile(
path: String,// 保存的路径
keyClass: Class[_], // Key类型
valueClass: Class[_], // Value类型
outputFormatClass: Class[_ <: NewOutputFormat[_, _]], // 输出格式OutputFormat实现
conf: Configuration = self.context.hadoopConfiguration // 配置信息
): Unit
*/
putsRDD.saveAsNewAPIHadoopFile(
"datas/spark/htb-output-" + System.nanoTime(), //
classOf[ImmutableBytesWritable], //
classOf[Put], //
classOf[TableOutputFormat[ImmutableBytesWritable]], //
conf
)
// 应用程序运行结束,关闭资源
sc.stop()
}
}
- hbase shell 查询 : scan "htb_wordcount"
======================================================
SparkCore案例
- 读取File文件,写入Mysql表中
import java.util
import com.hankcs.hanlp.HanLP
import com.hankcs.hanlp.seg.common.Term
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
/**
* 用户查询日志(SogouQ)分析,数据来源Sogou搜索引擎部分网页查询需求及用户点击情况的网页查询日志数据集合。
* 1. 搜索关键词统计,使用HanLP中文分词
* 2. 用户搜索次数统计
* 3. 搜索时间段统计
* 数据格式:
* 访问时间\t用户ID\t[查询词]\t该URL在返回结果中的排名\t用户点击的顺序号\t用户点击的URL
* 其中,用户ID是根据用户使用浏览器访问搜索引擎时的Cookie信息自动赋值,即同一次使用浏览器输入的不同查询对应同一个用户ID
*/
object SogouQueryAnalysis {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[*]")
val sc: SparkContext = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
// TODO: 1. 本地读取SogouQ用户查询日志数据
val rawLogsRDD: RDD[String] = sc.textFile("data/input/SogouQ.sample")
//val rawLogsRDD: RDD[String] = sc.textFile("D:/data/sogou/SogouQ.reduced")
//println(s"Count = ${rawLogsRDD.count()}")
// TODO: 2. 解析数据,封装到CaseClass样例类中
val recordsRDD: RDD[SogouRecord] = rawLogsRDD
// 过滤不合法数据,如null,分割后长度不等于6
.filter(log => log != null && log.trim.split("\\s+").length == 6)
// 对每个分区中数据进行解析,封装到SogouRecord
.mapPartitions(iter => {
iter.map(log => {
val arr: Array[String] = log.trim.split("\\s+")
SogouRecord(
arr(0),
arr(1),
arr(2).replaceAll("\\[|\\]", ""),
arr(3).toInt,
arr(4).toInt,
arr(5)
)
})
})
println("====解析数据===")
println(s"Count = ${recordsRDD.count()},\nFirst = ${recordsRDD.first()}")
// 数据使用多次,进行缓存操作,使用count触发
recordsRDD.persist(StorageLevel.MEMORY_AND_DISK).count()
// TODO: 3. 依据需求统计分析
/*
1. 搜索关键词统计,使用HanLP中文分词
2. 用户搜索次数统计
3. 搜索时间段统计
*/
println("====3.1 搜索关键词统计===")
// =================== 3.1 搜索关键词统计 ===================
// a. 获取搜索词,进行中文分词
val wordsRDD: RDD[String] = recordsRDD.mapPartitions(iter => {
iter.flatMap(record => {
// 使用HanLP中文分词库进行分词
val terms: util.List[Term] = HanLP.segment(record.queryWords.trim)
// 将Java中集合对转换为Scala中集合对象
import scala.collection.JavaConverters._
terms.asScala.map(_.word)
})
})
//println(s"Count = ${wordsRDD.count()}, Example = ${wordsRDD.take(5).mkString(",")}")
// b. 统计搜索词出现次数,获取次数最多Top10
val top10SearchWords: Array[(Int, String)] = wordsRDD
.map((_, 1)) // 每个单词出现一次
.reduceByKey(_ + _) // 分组统计次数
.map(_.swap)
.sortByKey(ascending = false) // 词频降序排序
.take(10) // 获取前10个搜索词
top10SearchWords.foreach(println)
println("====3.2 用户搜索点击次数统计===")
// =================== 3.2 用户搜索点击次数统计 ===================
/*
每个用户在搜索引擎输入关键词以后,统计点击网页数目,反应搜索引擎准确度
先按照用户ID分组,再按照搜索词分组,统计出每个用户每个搜索词点击网页个数
*/
val clickCountRDD: RDD[((String, String), Int)] = recordsRDD
.map(record => {
// 获取用户ID和搜索词
val key = (record.userId, record.queryWords)
(key, 1)
})
// 按照用户ID和搜索词组合的Key分组聚合
.reduceByKey(_ + _)
clickCountRDD
.sortBy(_._2, ascending = false)
.take(10).foreach(println)
println(s"Max Click Count = ${clickCountRDD.map(_._2).max()}")
println(s"Min Click Count = ${clickCountRDD.map(_._2).min()}")
println(s"Avg Click Count = ${clickCountRDD.map(_._2).mean()}")
println("====3.3 搜索时间段统计===")
// =================== 3.3 搜索时间段统计 ===================
/*
从搜索时间字段获取小时,统计个小时搜索次数
*/
val hourSearchRDD: RDD[(String, Int)] = recordsRDD
// 提取小时和分钟
.map(record => {
// 03:12:50
record.queryTime.substring(0, 5)
})
// 分组聚合
.map((_, 1)) // 每个单词出现一次
.reduceByKey(_ + _) // 分组统计次数
.sortBy(_._2, ascending = false)
hourSearchRDD.foreach(println)
// 释放缓存数据
recordsRDD.unpersist()
// 应用结束,关闭资源
sc.stop()
}
/**
* 用户搜索点击网页记录Record
*
* @param queryTime 访问时间,格式为:HH:mm:ss
* @param userId 用户ID
* @param queryWords 查询词
* @param resultRank 该URL在返回结果中的排名
* @param clickRank 用户点击的顺序号
* @param clickUrl 用户点击的URL
*/
case class SogouRecord(
queryTime: String,
userId: String,
queryWords: String,
resultRank: Int,
clickRank: Int,
clickUrl: String
)
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号