

动态规划:剑指 Offer 47. 礼物的最大价值
题目描述:
在一个 m*n 的棋盘的每一格都放有一个礼物,每个礼物都有一定的价值(价值大于 0)。你可以从棋盘的左上角开始拿格子里的礼物,并每次向右或者向下移动一格、直到到达棋盘的右下角。
给定一个棋盘及其上面的礼物的价值,请计算你最多能拿到多少价值的礼物?

提示:
0 < grid.length <= 2000 < grid[0].length <= 200
解题思路:
题目说明:从棋盘的左上角开始拿格子里的礼物,并每次 向右 或者 向下 移动一格、直到到达棋盘的右下角。
根据题目说明,易得某单元格只可能从上边单元格或左边单元格到达。
设 f(i, j)为从棋盘左上角走至单元格 (i ,j)的礼物最大累计价值,易得到以下递推关系:f(i,j) 等于 f(i,j−1) 和 f(i−1,j) 中的较大值加上当前单元格礼物价值 grid(i,j) 。
f(i,j)=max[f(i,j−1),f(i−1,j)]+grid(i,j)
因此,可用动态规划解决此问题,以上公式便为转移方程。
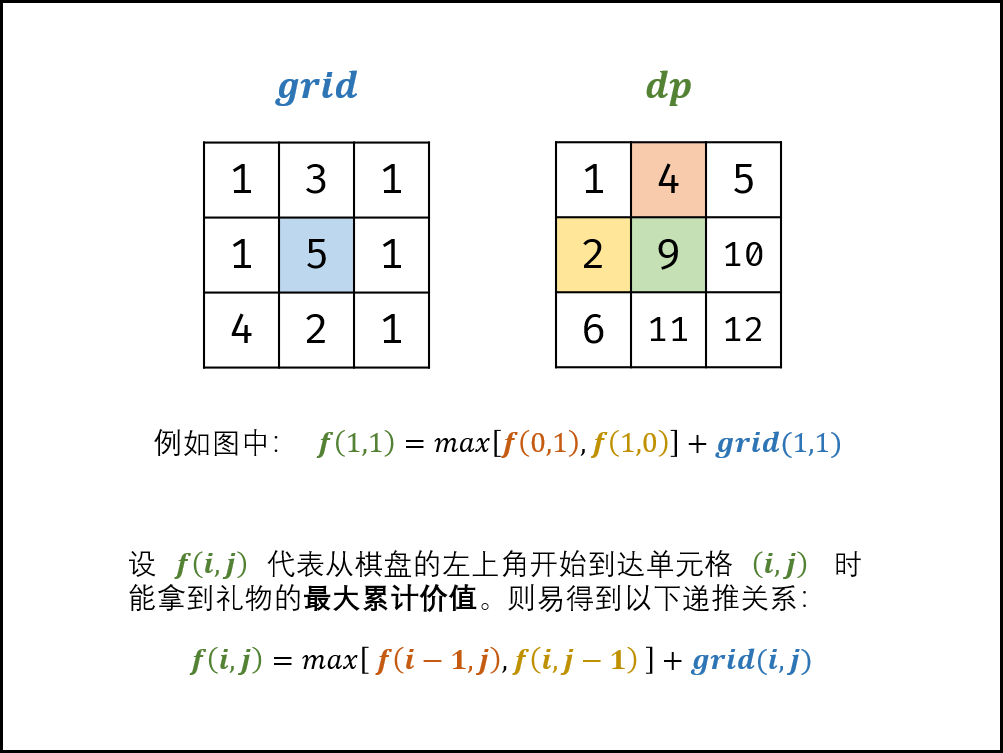
动态规划解析:
•状态定义: 设动态规划矩阵 dp ,dp(i,j) 代表从棋盘的左上角开始,到达单元格 (i,j) 时能拿到礼物的最大累计价值。
•转移方程:

•初始状态: dp[0][0]=grid[0][0] ,即到达单元格 (0,0) 时能拿到礼物的最大累计价值为 grid[0][0] ;
•返回值: dp[m−1][n−1] ,m,n 分别为矩阵的行高和列宽,即返回 dp 矩阵右下角元素。
空间复杂度优化:
由于 dp[i][j] 只与 dp[i-1][j] , dp[i][j−1] ,grid[i][j] 有关系,因此可以将原矩阵 grid 用作 dp 矩阵,即直接在 grid 上修改即可。
应用此方法可省去 dp 矩阵使用的额外空间,因此空间复杂度从 O(MN) 降至 O(1) 。
复杂度分析:
时间复杂度 O(MN) : M,N 分别为矩阵行高、列宽;动态规划需遍历整个 grid 矩阵,使用 O(MN) 时间。
空间复杂度 O(1) : 原地修改使用常数大小的额外空间。
class Solution{ public int maxValue(int grid[][]){ //m获取行数 n获取列数 int m = grid.length,n = grid[0].length; for (int i = 0;i<m;i++){ for(int j=0;j<n;j++){ if(i==0&&j==0) continue;//起始元素 if(i==0) grid[i][j]+=grid[i][j-1];//矩阵第一行元素,只可从左边到达 else if(j==0) grid[i][j]+=grid[i-1][j];//矩阵第一列元素,只可从上边到达 else grid[i][j]+=Math.max(grid[i-1][j],grid[i][j-1]);//可从左边或上边到达 } } return grid[m-1][n-1]; } }
动态规划4部曲:1.状态定义(设动态规划矩阵 dp) 2.转移方程(探讨下一状态与当前状态之间的关系) 3.初始状态(初始化) 4.返回值dp[l-1]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号