【阅读】Transformer
 简要阅读 Attention Is All You Need 🤔
简要阅读 Attention Is All You Need 🤔
参考
Attention Is All You Need
A General Survey on Attention Mechanisms in Deep Learning
注意力足矣(Attention Is All You Need)
一般注意力模型
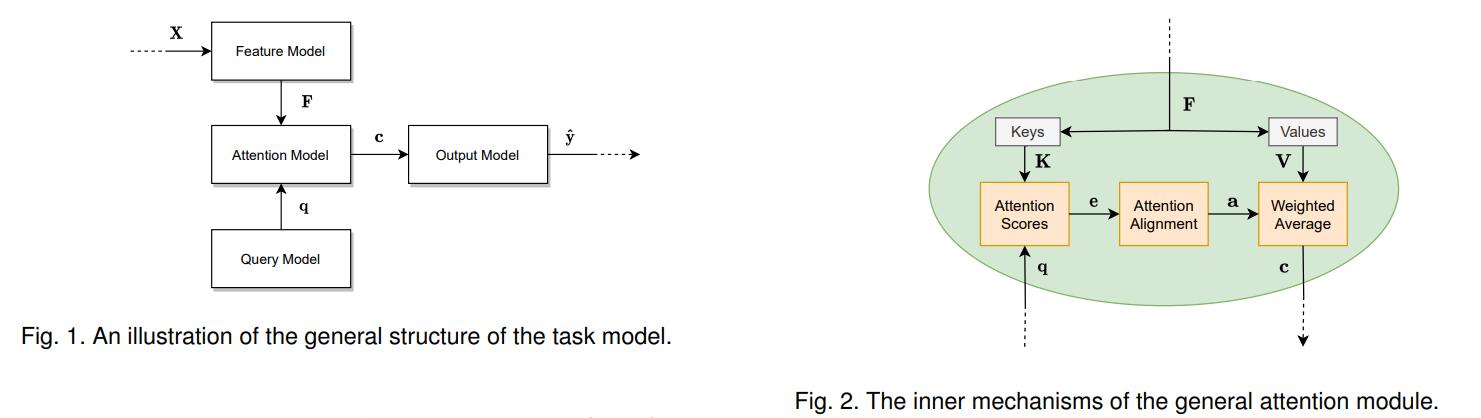
这个模型接受一个输入,执行指定的任务,然后产生所需的输出
- 输入 \(X _{d _x\times n _x} = [{\boldsymbol x} _1, \dots, {\boldsymbol x} _{n _x}]\),每个向量 \({\boldsymbol x} \in \R ^{d _x}\) 为词、像素、声音序列特征等
- 特征模型 feature model:输入 \(X\),输出特征 \(F _{d _f\times n _f} = [{\boldsymbol f} _1, \dotsb, {\boldsymbol f} _{n _f}]\),特征向量 \({\boldsymbol f} \in \R ^{d _f}\)
- 查询模型 query model:得到查询向量 \({\boldsymbol q} \in \R ^{d _q}\),用于提示注意力模型需要注意哪些特征部分
- 注意力模型 attention model,由单个或多个注意力模块 (Fig.2) 构成:输入特征向量 \(F\) 和查询向量 \({\boldsymbol q}\),对特征向量用权重矩阵 \(W _K, W _V\) 线性变换出键矩阵 \(K _{d _k \times n _f}=W _K F = [{\boldsymbol k} _1,\dotsb, {\boldsymbol k} _{n _f}]\) 和值矩阵 \(V _{d _v\times n _f} = W _V F = [{\boldsymbol v} _1, \dotsb, {\boldsymbol v} _{n _f}]\);\(W _K, W _V\) 可以是可训练的或者预先指定的
注意力模块为了得到 \(V\) 中的值向量的加权平均值——特征 \(F\) 中对查询 \(\boldsymbol q\) 重要的信息。为每个键向量 \({\boldsymbol k}\),通过某个打分函数计算其和查询向量 \(\boldsymbol q\) 的注意力得分 \(e _l = \text{score}({\boldsymbol q}, {\boldsymbol k} _l)\)(通常在 \([0,1]\)),组成得分向量 \({\boldsymbol e} = [e _1,\dotsb, e _{n _f}]\);
通过对齐层 (alignment) 归一化,比如 Softmax \(a _l = \frac{\exp e _l}{\sum _j \exp e _j}\),得到注意力权重向量 \({\boldsymbol a}\)
对 \(V\) 加权平均,得到上下文向量 (context vector) \({\boldsymbol c} = \sum _l a _l {\boldsymbol v} _l\) - 输出模型 output model:输入上下文向量 \({\boldsymbol c}\in \R ^ {d _v}\),训练模型输出预测值 \(\hat {\boldsymbol y}\in \R ^ {d _{\hat y}}\)
自注意力 self att
若注意力模型 attention model 完全通过特征 \(F\) 得到
例如,查询向量也由 \(F\) 得到:\(Q _{d _q\times n _f} = W _Q F = [{\boldsymbol q} _1, \dotsb, {\boldsymbol q} _{n _f}]\);当使用 \({\boldsymbol q} _l\) 查询时,生成 \({\boldsymbol c} _l\),即 \(C = \text{self-att}(Q, K, V)\)
多头注意力 multi-head att
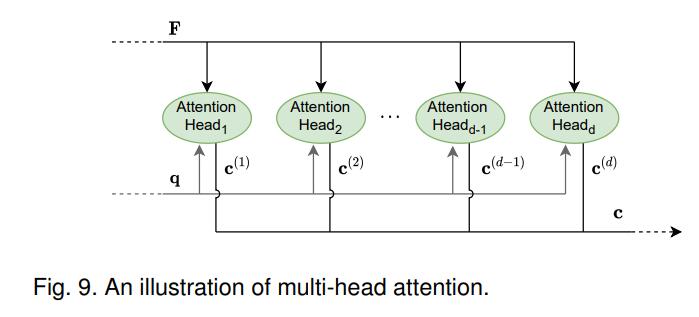
如图 Fig.9 有 \(d\) 个并行的注意力模块,思想是使用不同的权重矩阵对查询 \(\boldsymbol q\) 进行线性变换得到多个查询,每个查询期望专注于不同类型的信息,从而使得注意模型在上下文向量计算中引入更多信息。
每个 att head 都有自己训练的矩阵:\(W ^{(l)}_{\boldsymbol q}, W ^{(l)}_K, W ^{(l)}_V\),得到查询向量、键矩阵和值矩阵 \({\boldsymbol q} ^{(l)}, K ^{(l)}, V ^{(l)}\),过一遍注意力模型得到上下文向量 \({\boldsymbol c} ^{(l)}\);将它们连接然后线性变换 \(W _O\),得到最终的上下文向量 \({\boldsymbol c} = W _O \text{concat}({\boldsymbol c} ^{(1)}, \dotsb, {\boldsymbol c} ^{(d)})\)
多头自注意力
Transformer 所使用的;后面就不强调自注意力了
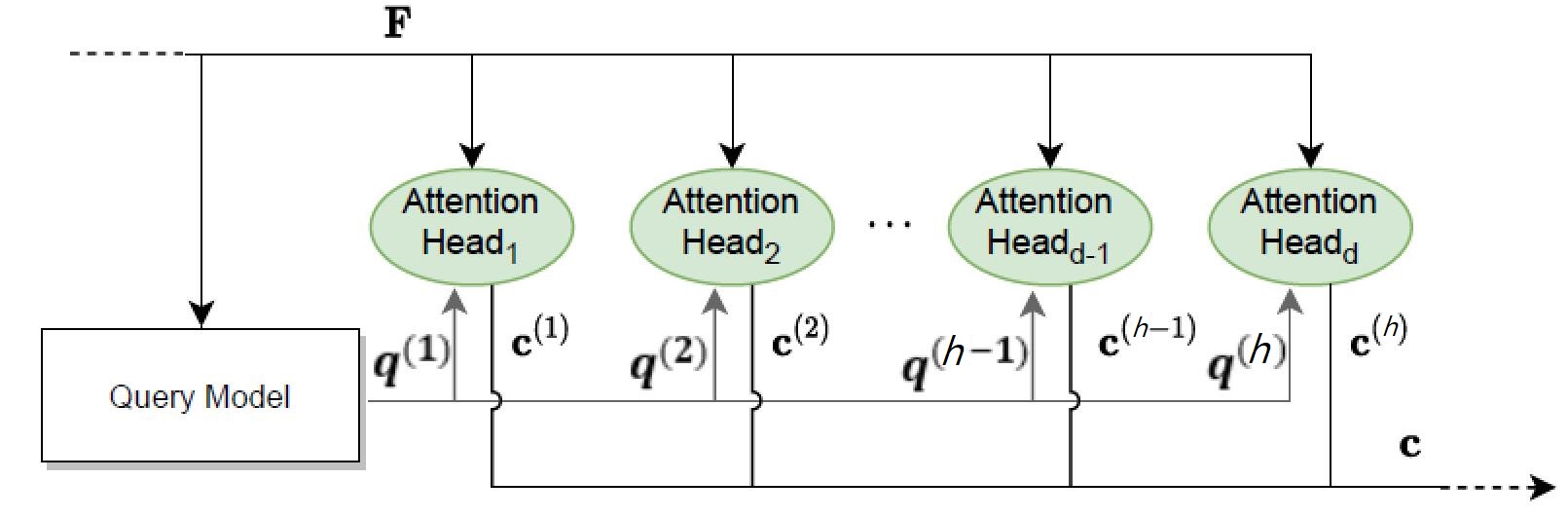
Transformer 介绍
Transformer 是一种序列转录模型 (sequence transduction models);序列转录模型输入、输出都为序列,通常由编码器 encoder 和解码器 decoder 组成,并用一种注意力机制 attention mechanism 连接它们
Transformer 模型在提出时仅作为机器翻译用,后来用于图像等其他领域
传统翻译通常是顺着序列跑,根据上一个位置对应的隐藏状态 \(h _{t-1}\) 和位置 \(t\) 的输入,确定 \(h _t\)——这是一个难以并行的过程,且会面临历史信息存储过大或者丢失的问题
而 Transformer 能更好地支持并行,而且只使用注意力机制(在此之前通常使用 RNN 做)
Transformer 结构
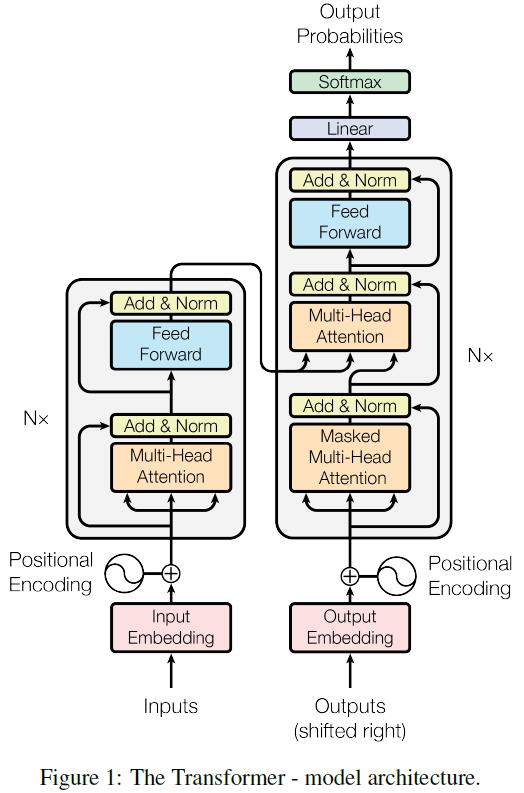
概述
一般编码器/解码器结构:对于输入序列(比如单词序列)\(X = [\boldsymbol{x} _1,\dotsb,\boldsymbol{x} _{n}]\),编码器输出 \(Z = [\boldsymbol{z} _1,\dotsb,\boldsymbol{z} _{n}]\)(序列长度不变);\(Z\) 丢进解码器输出 \(Y = [\boldsymbol{y} _1,\dotsb,\boldsymbol{y} _{m}]\)(序列长度可能改变)
如上图,Transformer 由左侧堆叠的 \(N\) 个编码器、右侧堆叠的 \(N\) 个解码器构成,\(N=6\)
对于解码器,它是自回归 auto-regressive 的:依次输出 \({\boldsymbol y} _j\),且 \({\boldsymbol y} _j\) 需要通过引入 \({\boldsymbol y} _1,\dotsb, {\boldsymbol y} _{j-1}\) 的信息而得到;因此解码器也以 Outputs 作为输入,其每次右移一位 (shifted right)
位置编码
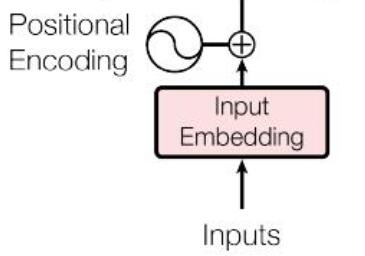
输入特征向量序列 \(X = [\boldsymbol{x} _1,\dotsb,\boldsymbol{x} _{n}], {\boldsymbol x} \in \R ^ d\)(这里的 \(n\) 就是之后的 \(n _f\))
在之后的 att-head 中我们只考虑键和查询的距离,并没有引入序列自带的时序信息;所以我们先为每个向量 \({\boldsymbol x} _t\) 添加它所在位置 \(t\) 的信息:构造关于位置 \(t\) 的位置编码 positional encodings \({\boldsymbol p} _t\in \R ^ d\),并直接加给 \({\boldsymbol x} _t\):
\({\boldsymbol p} _t = [\sin (\omega _0 t)\ \cos (\omega _0 t)\ \sin (\omega _1 t)\ \cos (\omega _1 t)\ \dotsb\ \sin (\omega _{\frac{d}{2}-1} t)\ \cos (\omega _{\frac{d}{2}-1} t)]^T\)
其中 \(\omega _k = \frac{1}{10000 ^{2k/d}}\)
下图中🔗,从上往下每一行依次为一个 \({\boldsymbol p} _t\)
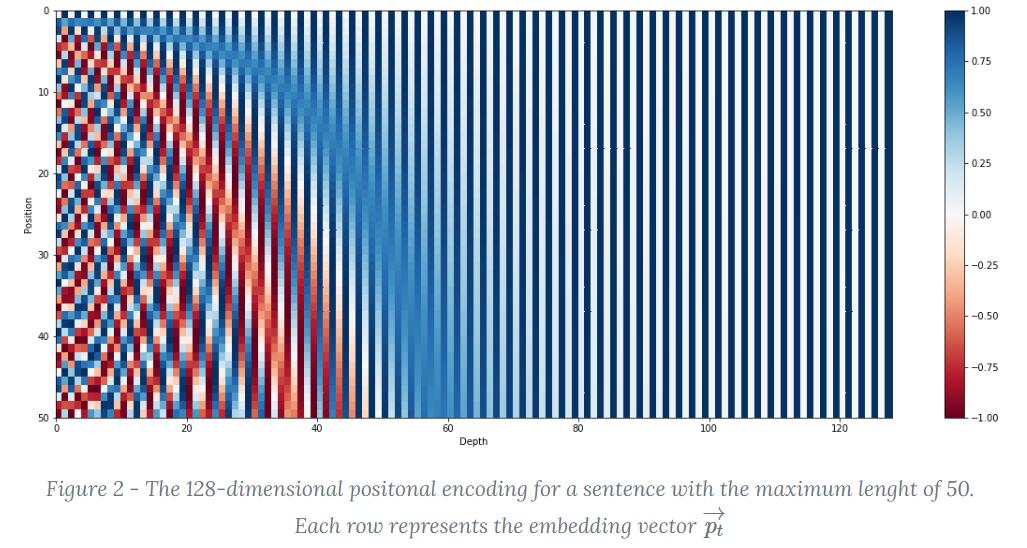
使用三角函数有一个好处,就是可以用线性变换刻画相对位置:对于 \({\boldsymbol x} _t\) 使用 \(\omega _k\) 编码的片段 \([\sin (\omega _k t)\ \cos (\omega _k t)]\),和相对位置为 \(\phi\) 的 \({\boldsymbol x} _{t + \phi}\) 的编码片段 \([\sin (\omega _k (t+\phi))\ \cos (\omega _k (t + \phi))]\),可以用线性变换得到:
编码器
多头自注意力
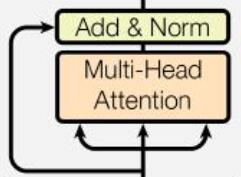
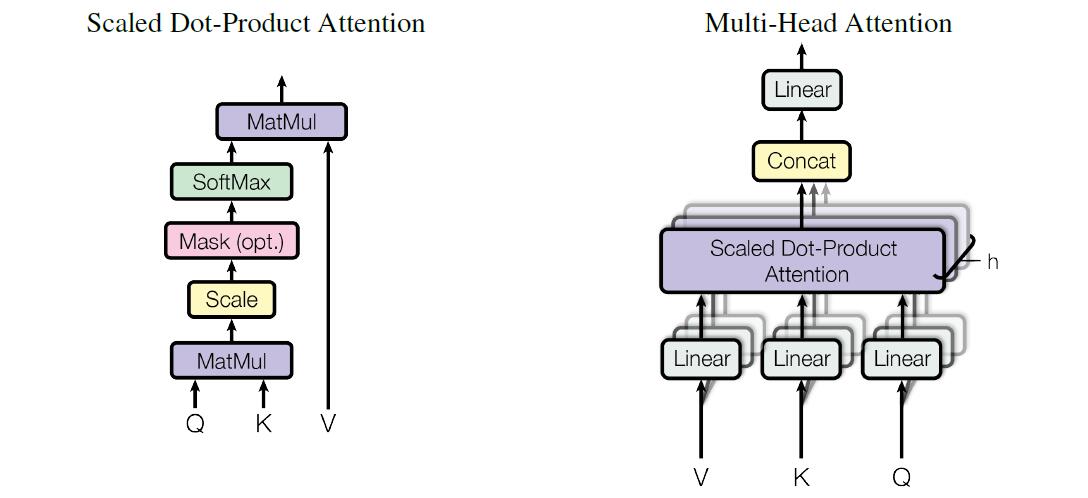
如上图所示,Multi-Head Att 亦如图,其为多头注意力,\(h=8\)(相当于 \(8\) 个通道,学习出不同的距离空间)
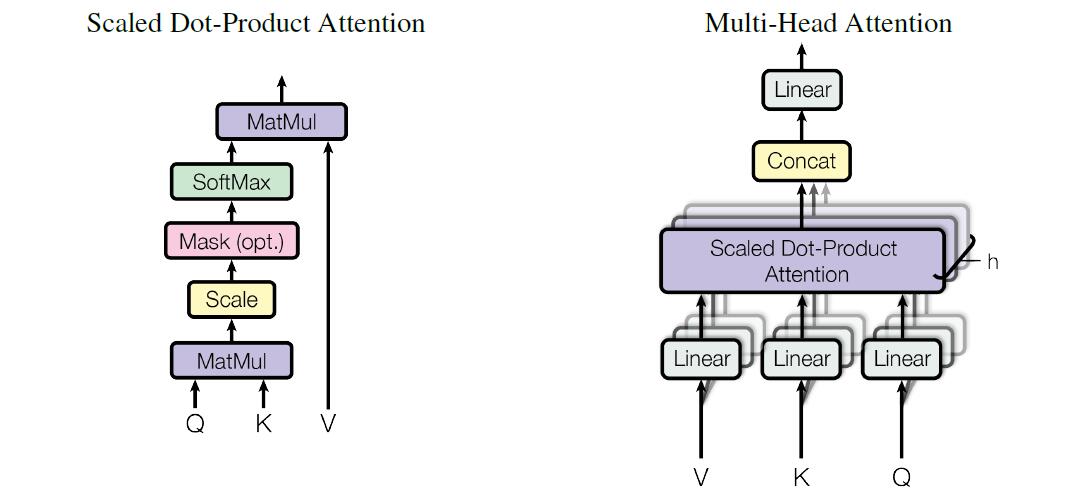
- 对第 \(l\) 个 att-head 先使用这个头自己的线性变换,将 \(F ^\text{(old)}\) 变换出 \(K ^{(l)} _{d _k \times n _f}, V ^{(l)} _{d _v\times n _f}, Q ^{(l)} _{d _q \times n _f}\)
(给我:\(K,V,Q\) 作为长度仍为 \(n _f\) 的序列,保持了一定的 \(F\) 的序列信息,就是说“作为单词序列看还是有意义的”——不知道怎么更好地表述这个感觉;而之后通过 Multi-Head Att 的输出,也是同样长度的序列,其中每一项都是输入的加权和、而权重来自于这一项——类似卷积里的自相关给人的感觉) - 以缩放点乘 (Scaled Dot-Product) 计算注意力得分,\({\boldsymbol e} _j^{(l)}\) 为第 \(j(1\le j\le n _f)\) 个查询向量 \({\boldsymbol q} _j\) 依次与所有键向量 \(\{{\boldsymbol k}\} _{i=1}^{n _f}\) 的点积、列出的向量
此外还要 Scale:除以 \(\sqrt{d _k}\) 防止某些向量因为长度较大导致得分占据优势\[E ^{(l)} = [{\boldsymbol e} _1 ^{(l)}, {\boldsymbol e} _2 ^{(l)},\dotsb, {\boldsymbol e} _{n _f} ^{(l)}] = \frac{{K ^{(l)}}^T Q ^{(l)}}{\sqrt{d _k}}\\ {\boldsymbol e} _j ^{(l)} = \frac{1}{\sqrt{d _k}} \begin{bmatrix} {{\boldsymbol k} _1 ^{(l)}}^T \\ {{\boldsymbol k} _2 ^{(l)}}^T \\ \vdots \\ {{\boldsymbol k} _{n _f} ^{(l)}}^T \end{bmatrix} {\boldsymbol q} _j^{(l)} \] - 以 Softmax 对齐得 \(A ^{(l)}\),给 \(V ^{(l)}\) 加权得 \(C ^{(l)}\)
第 \(j\) 个上下文向量 \({\boldsymbol c} _j\),为在查询向量 \({\boldsymbol q} _j\) 的引导下、计算出的得分 \({\boldsymbol e} _j\) 归一化后的 \({\boldsymbol a} _j\) 作为权重、将值向量 \(\{{\boldsymbol v}\} _{i=1}^{n _f}\) 加权和后的结果\[\begin{aligned} A ^{(l)} &= [{\boldsymbol a} ^{(l)} _1, \dotsb, {\boldsymbol a} ^{(l)} _{n _f}] = [\text{softmax}({\boldsymbol e} ^{(l)} _1),\dotsb, \text{softmax}({\boldsymbol e} ^{(l)} _{n _f})] \\ C ^{(l)}&= [{\boldsymbol c} _1 ^{(l)},\dotsb, {\boldsymbol c} _{n _f} ^{(l)}] = V ^{(l)}A ^{(l)},\quad {\boldsymbol c} _j ^{(l)} =\sum _i {\boldsymbol v} _i ^{(l)} {\boldsymbol a} _{j i} ^{(l)} \end{aligned} \] - 创建一个上下文向量作为注意力模型的输出:对于第 \(j\) 个查询,将所有 att-head 的输出直接连接起来:\(\text{concat}(C ^{(1)},\dotsb, C ^{(h)}) \in \R ^{(d _v h)\times n _f}\),然后用权重矩阵 \({W _O} \in \R ^{d _c \times (d _v h)}\) 线性变换,得到最终 Multi-Head Attention 的输出 \(C\)\[\begin{aligned} C _{d _c\times n _f} &= W _O \begin{bmatrix} \text{concat}({\boldsymbol c} _1 ^{(1)},\dotsb,{\boldsymbol c} _1 ^{(h)}),\text{concat}({\boldsymbol c} _2 ^{(1)},\dotsb,{\boldsymbol c} _2 ^{(h)}), \dotsb, \text{concat}({\boldsymbol c} _{n _f} ^{(1)},\dotsb,{\boldsymbol c} _{n _f} ^{(h)}) \end{bmatrix} \\ &= W _O \begin{bmatrix} \begin{bmatrix} {\boldsymbol c} _1 ^{(1)} \\ {\boldsymbol c} _1 ^{(2)} \\ \vdots \\ {\boldsymbol c} _1 ^{(h)} \end{bmatrix} \begin{bmatrix} {\boldsymbol c} _2 ^{(1)} \\ {\boldsymbol c} _2 ^{(2)} \\ \vdots \\ {\boldsymbol c} _2 ^{(h)} \end{bmatrix} \dotsb \begin{bmatrix} {\boldsymbol c} _{n _f} ^{(1)} \\ {\boldsymbol c} _{n _f} ^{(2)} \\ \vdots \\ {\boldsymbol c} _{n _f} ^{(h)} \end{bmatrix}\end{bmatrix} \end{aligned} \]
- 对于上述的维度可以令 \(d _k = d _v = d _q = d _c / h\)
- 最后过一遍残差连接和层归一化 Add & Norm:\[F ^\text{(new)} = \text{LayerNorm}(F ^\text{(old)} + C) \]LayerNorm 是一个与 BatchNorm 有所异同的东西
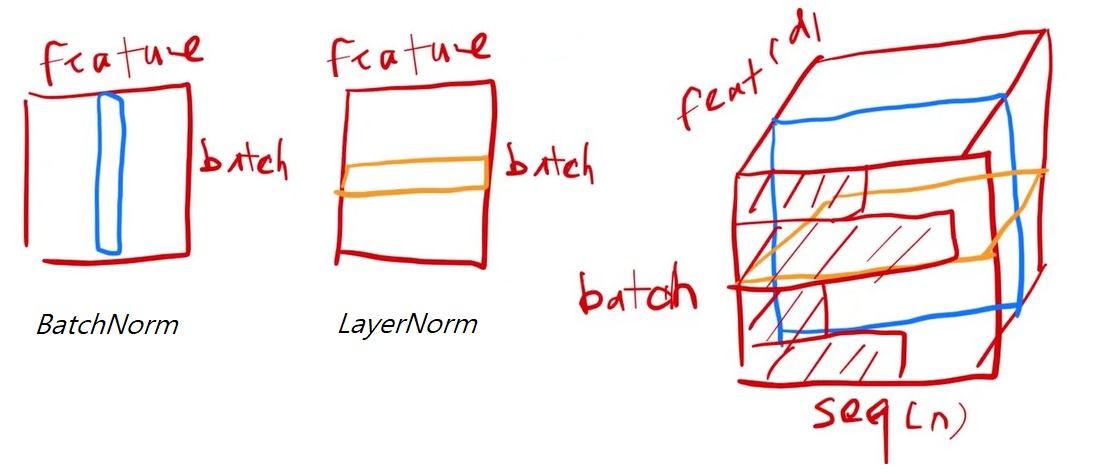
- BatchNorm 批标准化,输入 \(BN\) 层一批数据 \(\text{batch}\times {\boldsymbol x}\):
实际上是 \(\boldsymbol x\) 的每一维 feature 对整个 batch 标准化
而对于 文章集合-单词序列-词特征向量 的情况:\(\text{batch}\times\text{seq} \times {\boldsymbol x}\),就要 \(\boldsymbol x\) 的每一维 feature 对整个 batch×seq 标准化 - LayerNorm 对于 \(\text{batch}\times\text{seq} \times {\boldsymbol x}\),它是 batch 的每个样本在自己的 seq×feature 上标准化
这么选择的一个考量是,一个 batch 内,不同样本的 seq 不同,使用同一个均值/方差会估计不准确
- BatchNorm 批标准化,输入 \(BN\) 层一批数据 \(\text{batch}\times {\boldsymbol x}\):
前馈网络
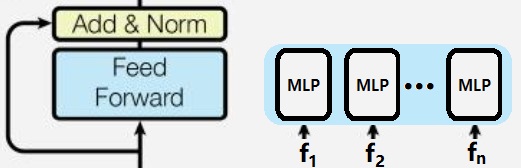
输入之前的 \(F ^\text{(new)} = [{\bf f} _1,\dotsb, {\bf f} _{n _f}]\),通过前馈网络(简单 MLP + Add&Norm),输出 \(Z=[{\bf z} _1,\dotsb, {\bf z} _{n _f}]\)
特别注意,我们将序列的每个向量分别丢进同一个 MLP,而不是将整个序列矩阵丢进 MLP
解码器
带掩码的多头自注意力
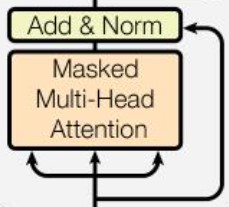
注意力层计算加权和为 \({\boldsymbol c} _j =\sum _i {\boldsymbol v} _i {\boldsymbol a} _{j i}\),但是解码器在预测过程是自回归的,对于某个时刻 \(j\),你输入给解码器的特征向量序列是之前的输出,即要求 \({\boldsymbol c} _j\) 只与 \({\boldsymbol v} _1, \dotsb, {\boldsymbol v} _j\) 有关;所以训练时不能把当前位置之后的信息也放进去了,这可以在打分函数的 Scale 之后、Softmax 之前增加一个掩码 Mask 实现
这样在之后过 Softmax 时,取 \(\ln\) 会使得 \(-\infty\) 变为 \(0\),也就是对每个 \(\boldsymbol e\) 的前缀的归一化、而后缀都变为 \(0\)
剩下同理:加权、连接、过一遍残差连接和层归一化,得到 \(F ^\text{(dec)}\)
以编码器输出作为输入的多头自注意力
如图,由编码器的输出 \(Z ^\text{(enc)}\) 得到键和值 \(K, V\)、由解码器第一部分的输出 \(F ^\text{(dec)}\) 得到查询 \(Q\):
也就是说,你从 \(V\) 中,根据来自解码器给的查询序列 \(Q\) 的每个位置 \(j\) 的查询 \({\bf q} _j\),用 \(K,{\bf q} _j\) 计算分数、从 \(V\) 中提取出 \({\bf q} _j\) 感兴趣的信息,作为输出序列中这个位置的值
前馈网络
与上文同理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号