第四次作业Hadoop思想与原理
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
从与谷歌系统的关系,关键时间节点,1.x,2.x与3.x的区别,不同公司发行版本等方面来讲。
(1)Hadoop最早起源于lucene下的Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
(2)2003年、2004年谷歌发表的三篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
——分布式的结构化数据存储系统Bigtable,用来处理海量结构化数据。
(3) Doug Cutting基于这三篇论文完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。
从狭义上来说,Hadoop就是单独指代Hadoop这个软件(HDFS+MAPREDUCE)
从广义上来说,Hadoop指代大数据的一个生态圈(Hadoop生态圈),包括很多其他的软件。

Hadoop的历史版本
0.x系列版本:Hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本
1.x版本系列:Hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性
用图与自己的话,简要描述名称节点、数据节点的主要功能及相互关系、名称节点的工作机制。
名称节点:名称节点负责管理分布式文件系统的命名空间,它保存了两个核心的数据结构——FsImage、EditLog;
HDFS命名空间:目录、文件、块。
HDFS命名空间的管理,是指对HDFS中目录、文件、块做类似文件系统的创建、修改、删除等基本操作。
FsImage:维护文件系统树 以及 文件树中的文件和文件夹的元数据;
EditLog:记录针对文件的创建、删除、重命名等这样的更新操作;
FsImage、EditLog工作原理:
名称节点运行期间,HDFS内的更新操作被写入到EditLog文件中,随着更新操作的不断发生,EditLog也将不断变大。
名称节点在每次重启时,将FsImage加载到内存中,再逐条执行EditLog中的记录,使FsImage保持最新状态。
存在问题:EditLog过大时
名称节点在启动过程中处于“安全模式”,只能对外提供读操作,无法提供写操作。当启动过程结束之后,系统将退出安全模式,对外提供正常的读写操作。但是,若EditLog很大会使得启动过程运行很慢,名称节点长期处于安全模式下,无法对外提供写操作。
解决问题:第二名称节点SecondaryNameNode
SecondaryNameNode有两个主要功能,针对此问题,它的功能主要是——完成EditLog与FsImage的合并操作,减小EditLog的文件大小,以缩短名称节点启动时间。
每隔一段时间,SecondaryNameNode会与NameNode进行通信,请求NameNode停止使用EditLog文件,让NameNode将这之后新到达的写操作写入到一个新的文件EditLog.new中;然后SecondaryNameNode将EditLog、FsImage拉回至本地,加载到内存中——即将FsImage加载到内存中,再逐条执行EditLog中的记录,使FsImage保持最新。
以上,便是EditLog与FsImage的合并过程,合并完成之后,SecondaryNameNode将已经更新的FsImage文件发送到NameNode,NameNode收到后,就用这个最新的FsImage文件替换掉旧的FsImage,同时用EditLog.new文件去替换EditLog文件,这样一替换,同时也减小的EditLog文件的大小。
SecondaryNameNode的第二个功能:作为名称节点的检查点
从以上“合并过程”能看出,SecondaryNameNode会定期与NameNode通信,获取旧文件合并后得到一个FsImage的新文件。SecondaryNameNode周期性的备份NameNode中的元数据信息,当NameNode发生故障时,可用SecondaryNameNode中记录的元数据信息进行恢复。
但是,在合并、文件替换期间的更新操作并没有被写到新的FsImage文件中去,所以如果在这回期间发生故障,系统会丢失部分元数据信息。
数据节点:是HDFS的工作节点,负责数据的存储和读取。
客户端从HDFS读取数据过程:在HDFS内部,一个文件是被分片成了若干个数据块了的,这些数据块被分布的存储到若干个数据节点上。
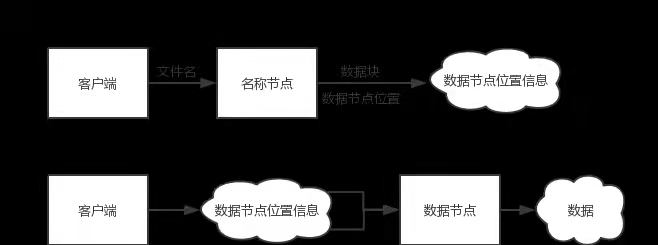
客户端从HDFS获取数据
客户端要获取HDFS内的数据时,首先将文件名发送给名称节点;名称节点根据文件名找到对应数据块信息,再根据数据块信息,找到存储了这些块的数据节点位置信息。
找到数据节点位置信息后将这些信息发送给客户端,客户端据此直接访问数据节点,并获取数据。
在以上所述的访问过程中,名称节点并不参与数据的传输,它只是实现了类似索引的功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号