HTML-简介及header
首先说明一下,下面介绍的HTML都是用python写的
一、HTML介绍
1、HTML,HyperText Markup Language,超文本标记语言。
2、HTML实质上就是一长串字符串,特点是能够被浏览器解析。
3、学习HTML说简单点,就是学习每一个标签代表什么
4、HTML分为3部分----html、css、js
如果用一个人来比喻,html就是这个人,css是这个人的衣服,js是这个人的动作
二、header
1、什么是标签
新建一个html文件,会看到默认的是这样的。
尖括号里面的内容就是标签。
标签分为两种:
(1)主动闭合标签:比如<html></html>、<head></head>、<body></body>
(2)自闭和标签:比如<meta><input>
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> </body> </html>
运行之后是下图的页面。我们可以看到,除了顶部tab展示了标题“Title”,其他都是空白的。可以看出,头部中大部分是不可见的,但是title可见。
2、头部标签介绍
(1)meta标签
上文里有一个meta属性charset,是规定了字符格式。我们再来学一个刷新页面的属性。
<meta http-equiv="refresh" content="10;url=http://www.baidu.com">
解析:实现自动刷新页面的功能,每隔10s刷新一次,刷新后跳转到百度页面。注意url需要写到content里面。
(2)link标签
我们修改下title前面的图标

<link rel="shortcut icon" href="https://pic.cnblogs.com/avatar/1348269/20180311140943.png">
rel规定link的作用是什么,shortcut icon指的是浏览器的地址栏显示的图标。其他rel属性可以自己网上搜索查看,用法一样。
href代表路径,也就是图片的地址,这里我用的是我博客园的头像,运行后如下,图标已替换。

下面介绍一下如何获取网页上的图片地址,以下适用于Chrome浏览器,其他浏览器大致相同。
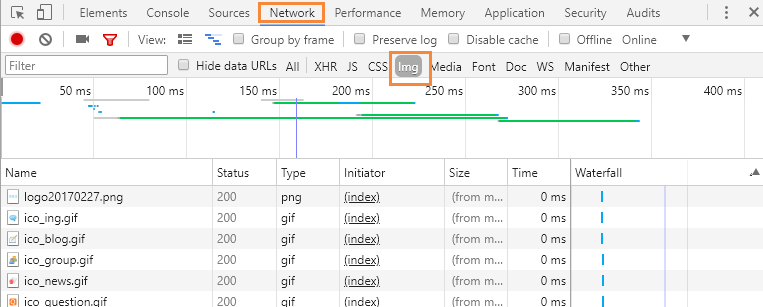
A、在目标网页单击右键,选择【检查】
B、选择【Network】,【Img】。然后刷新页面,即可看到该页面的图片。
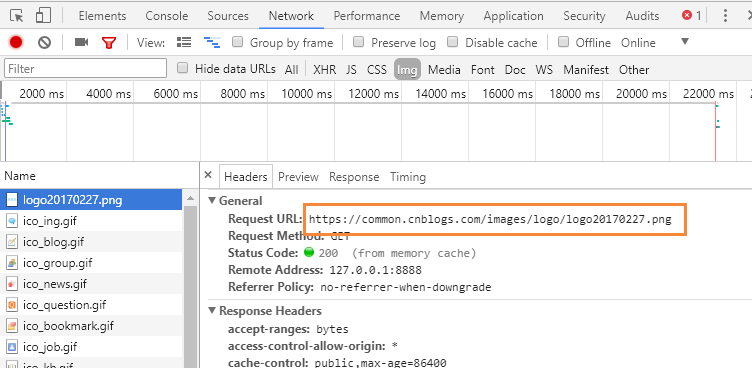
C、点击所需要的图片,就可以获取该图片的地址。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号