scrapy关键字爬取百度图库(一)
刚入门学习python的菜鸟,如有错误,还望指教
爬取百度图库需要知道百度图库的加载方式是通过下拉加载的,所以我们需要分析Ajax请求来爬取每一页的数据信息
表述不清直接上图片
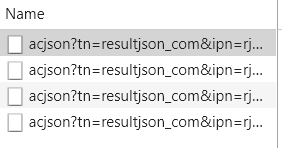
图片一是刷新页面后加载的四条json格式的数据,随便点开一条,可以看到它的Requset URL,每一个json数据中包含了30张图片。
所根据观察发现,每一条URL变化的地方在queryword=(关键字)和pn=(从零开始,以30为步长),所以根据此我们可以通过改变请求的URL来加载下一个json数据,这样就可以实现下拉功能。
点开data中的一项我们可以看到想要的信息都在里面,我们选取它的名称和图片地址来存储
代码实现:
scrapy框架好的地方在于它已经把每一个过程分块化,我们只需要关注每一块要实现的功能,而不用关心块与块如何连接的问题
settings.py


MONGO_URI='localhost' MONGO_DB='picture' # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'Pic_search (+http://www.yourdomain.com)' # Obey robots.txt rules #协议文件 ROBOTSTXT_OBEY = False
要把信息存入MongoDB中
items.py
import scrapy class PicSearchItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() img_title = scrapy.Field() img_url = scrapy.Field()
Item 对象是种简单的容器,保存了爬取到得数据。 其提供了 类似于词典(dictionary-like) 的API以及用于声明可用字段的简单语法。
spiders.py
# -*- coding: utf-8 -*- #初始化spider:scrapy genspider spider image.baidu.com #运行spider:scrapy crawl spider from scrapy import Spider,Request import json from Pic_search.items import PicSearchItem import itertools import urllib
import time u_word = input("请输入你要下载的图片关键词:\n")
word = urllib.parse.quote(u_word) pn = 0 urls = "https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&fp=result&queryWord={word}&cl=2&lm=-1&ie=utf-8&oe=utf-8&st=-1&ic=0&word={word}&face=0&istype=2&nc=1&pn={pn}&rn=30" class SpiderSpider(Spider): name = 'spider' allowed_domains = ['image.baidu.com'] headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36', } def start_requests(self): #print(word) url = urls.format(word=word,pn=0) yield Request(url, headers=self.headers) def parse(self, response): hjsons = json.loads(response.body) img_datas = hjsons['data'] if hjsons: for data in img_datas: try: item = PicSearchItem() print(data['fromPageTitleEnc']) print(data['thumbURL']) item['img_url'] = data['thumbURL'] item['img_title'] = data['fromPageTitleEnc'] yield item except: pass
for x in itertools.count(start=30, step=30): next_url = urls.format(word=word,pn=x) #生成下一页地址 yield Request(url=next_url, callback=self.parse) #回调
time.sleep(1)

pipelines.py
import pymongo from scrapy.exceptions import DropItem class MongoPipeline(object): def __init__(self,mongo_uri,mongo_db): self.mongo_uri = mongo_uri self.mongo_db = mongo_db @classmethod def from_crawler(cls,crawler): return cls( mongo_uri=crawler.settings.get('MONGO_URI'), mongo_db=crawler.settings.get('MONGO_DB') ) def open_spider(self,spider): self.client = pymongo.MongoClient(self.mongo_uri) self.db = self.client[self.mongo_db] def process_item(self,item,spider): name = item.__class__.__name__ #两条下划线 self.db[name].insert(dict(item)) return item def close_spider(self,spider): self.client.close()
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理
以下是item pipeline的一些典型应用:
清理HTML数据
验证爬取的数据(检查item包含某些字段)
查重(并丢弃)
将爬取结果保存到数据库中
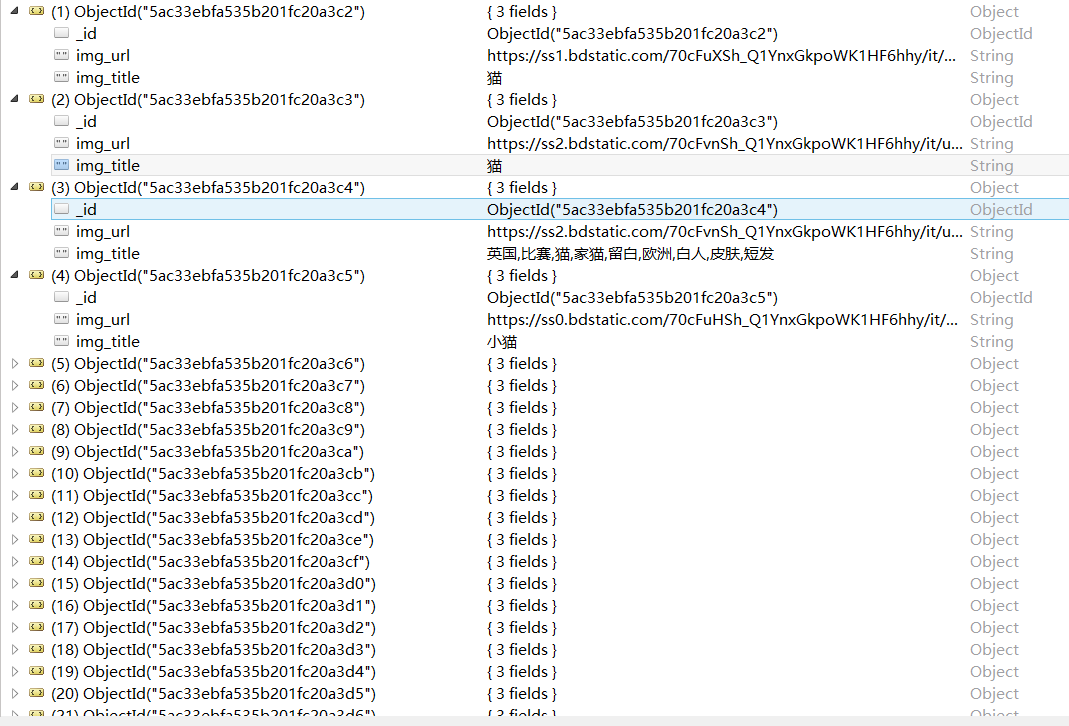
结果图片:
但是代码还是存在问题和不足,还有需要很多提升
1.解决无限循环,解决异常问题
2.采用分布式爬取
3.爬取多个网站图片
所以未完,待续。。。。。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号