
分布式架构的演进(转)
系统架构演化历程-初始阶段架构

初始阶段的小型系统 应用程序、数据库、文件等所有的资源都在一台服务器上通俗称为LAMP(linux、apache、mysql、php)。
特征:
应用程序、数据库、文件等所有的资源都在一台服务器上。
描述:
通常服务器操作系统使用linux,应用程序使用PHP开发,然后部署在Apache上,数据库使用Mysql,汇集各种免费开源软件以及一台廉价服务器就可以开始系统的发展之路了。
例子:
一个小公司,有一个仓库,有人时不时的来这个仓库放东西,存东西,资讯一些情况。因为这家公司很小,所以在前台又要一个客服人员就行了,你问我什么,我答复你; 你要文件,我抛去放文件的位置给你取文件,你要数据,我跑到存数据的地方给你取数据。。 一切都还行。
系统架构演化历程-应用服务和数据服务分离
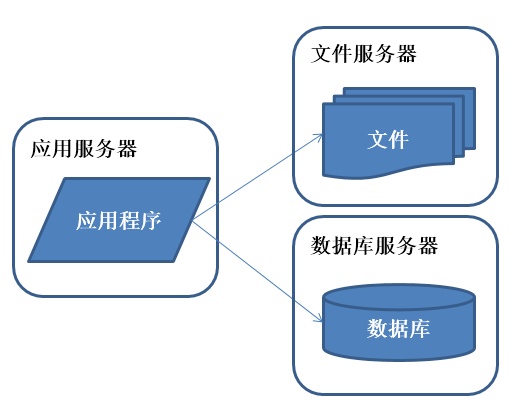
好景不长,发现随着系统访问量的再度增加,webserver机器的压力在高峰期会上升到比较高,这个时候开始考虑增加一台webserver。
特征:
应用程序、数据库、文件分别部署在独立的资源上。
描述:
数据量增加,单台服务器性能及存储空间不足,需要将应用和数据分离,并发处理能力和数据存储空间得到了很大改善。
例子:
慢慢的,公司越做越大,越来越多的人要来咨询、存东西、放东西。 而前台就一个人在服务,有人要取文件了,这人就得跑的老远去去文件,然后回来给客户; 有人要取数据库了,它又要跑好远,去取回来数据,再给用户。 但是人越来越多啊,这一个人就不够干了,于是,公司又安排了两个人,一个人专门负责看管文件,一个人专门负责看管数据。等到人来了要文件,前台小姐姐只需要给管理文件的人打一个电话,管文件的人就把东西送来了;一会又有人来取数据, 小姐姐又打一个电话给管理数据的人,这样数据又给送来了。
系统架构演化历程-使用缓存改善性能

特征:
数据库中访问较集中的一小部分数据存储在缓存服务器中,减少数据库的访问次数,降低数据库的访问压力。
描述:
系统访问特点遵循二八定律,即80%的业务访问集中在20%的数据上。
缓存分为本地缓存和远程分布式缓存,本地缓存访问速度更快但缓存数据量有限,同时存在与应用程序争用内存的情况。
例子:
但是啊,前台小姐姐发现,客户来要一些数据和文件的时候,很多人就要那么几种,有其他很多种要的就很少啊,于是她想了个办法,实现准备好一些客人常要数据和文件放在身边,这样他们来取的时候,不就方便的多了吗!不用大老远的送东西了。
系统架构演化历程-使用应用服务器集群
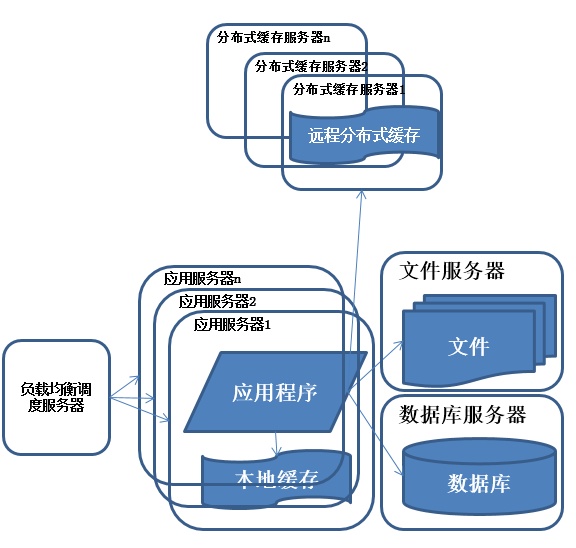
这里的应用服务器集群是说: 多个应用服务器做的是同样的事情,目的是负载均衡。为什么要负载均衡呢? 比如一台应用服务器提供服务,那么用户访问量很大的时候,肯定响应不过来,所以,我们可以让用户访问不同的服务器,但是提供的时同样的功能,这也是集群的特点。
使用集群是系统解决高并发、海量数据问题的常用手段。通过向集群中追加资源,提升系统的并发处理能力,使得服务器的负载压力不再成为整个系统的瓶颈。
例子:
慢慢的,访问的客人越来越多了,前台的小姐姐一个人忙不过来了,于是公司给前台又安排了几个客服人员,但是啊,他们干的事情都是一样的。 另外,还得专门有一个人来分配任务,比如A、B客服那已经有很多人了,但是C却没有人,这是这个负载均衡的人就会把来了的客人安排给C。。 这样,效率就又得到提高了!
系统架构演化历程-数据库读写分离

享受了一段时间的系统访问量高速增长的幸福后,发现系统又开始变慢了,这次又是什么状况呢,经过查找,发现数据库写入、更新的这些操作的部分数据库连接的资源竞争非常激烈,导致了系统变慢。
特征:
多台服务器通过负载均衡同时向外部提供服务,解决单台服务器处理能力和存储空间上限的问题。
描述:
使用集群是系统解决高并发、海量数据问题的常用手段。通过向集群中追加资源,使得服务器的负载压力不在成为整个系统的瓶颈。
例子:
后面啊,对于数据的要求越来越高了,有人来去数据,有人想要把数据存放在这。 这时管理数据的人忙不过来了,一会取数据,一会存数据,是在是混乱不堪,头晕眼花啊!
所以,公司决定为了以后更好地发展,就给数据管理这再安排一个人,一个人专门负责存取数据,一个人专门负责存数据,这样,分工合作,效率又提高了,满足了当前的要求!
系统架构演化历程-反向代理和CDN加速
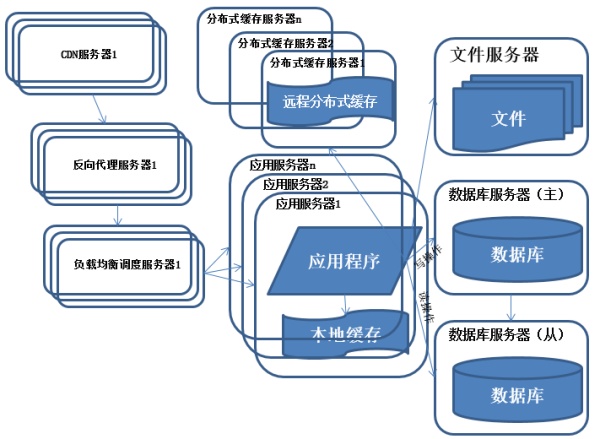
特征:
采用CDN和反向代理加快系统的 访问速度。
描述:
为了应付复杂的网络环境和不同地区用户的访问,通过CDN和反向代理加快用户访问的速度,同时减轻后端服务器的负载压力。CDN与反向代理的基本原理都是缓存。
即我们FQ的时候,需要通过正向代理服务器请求一个国外的服务器,它来帮助我们请求,而服务器不知道真正的请求者是谁。 即正向代理的对象是用户,我们是用户,所以为正。
而比如我们打10086的时候,不同地区会有不同地区的人来回答,那么我们是无法知道真正提供服务的服务器是哪个。 即反向代理的对象是服务器, 我们是用户,而服务器是对方,反方,所以是反。
那么为什么要做反向代理呢?
因为在计算机的世界里,由于单个服务器的处理客户端(用户)请求能力有一个极限,当用户的接入请求蜂拥而入时,会造成服务器忙不过来的局面,可以使用多个服务器来共同分担成千上万的用户请求,这些服务器提供相同的服务,对于用户来说,根本感觉不到任何差别。 且反向代理都是为了实现负载均衡的。
https://www.jianshu.com/p/d766d966cebc 这篇文章介绍正向代理和反向代理介绍的特别好。
无论是正向代理还是反向代理都有代理器。只是两者中前者是代理客户端,后者是代理服务器。
正向代理 - 代理客户端 - 我们是客户端,代理我们即为正义。比如中国有墙,想要访问google.com,是不可能直接访问的,所以可以来一个代理vpn,这个代理服务器去帮助我们请求google.com,且这时google.com服务器不知道是谁在请求,客户端是隐藏的,即为正向代理。
反向代理 - 代理服务器 - 比如春节期间12306购票,服务器压力很大,所以使用nginx做反向代理,即代理服务器拿到我们的请求后,去上万台的12306.com服务器请求,不一定是哪台服务器响应,这时服务器是隐藏的,即为反向代理。
记住:反向代理是实现负载均衡的手段。
所以在上图中,基本的步骤就是:用户访问的时CDN服务器,然后访问方向代理服务器,接着反向代理服务器通过负载均衡给用户提供空闲的服务器提供服务,这样来减小压力。
例子:
接着啊,客服人员这边管理有些混乱,就需要使用反向代理了。
系统架构演化历程-分布式文件系统和分布式数据库

随着系统的不断运行,数据量开始大幅度增长,这个时候发现分库后查询仍然会有些慢,于是按照分库的思想开始做分表的工作。
特征:
数据库采用分布式数据库,文件系统采用分布式文件系统。
描述:
分布式数据库是系统数据库拆分的最后方法,只有在单表数据规模非常庞大的时候才使用,更常用的数据库拆分手段是业务分库,将不同的业务数据库部署在不同的物理服务器上。
系统架构演化历程-使用NoSQL和搜索引擎

特征 :
系统引入了NoSQL数据库以及搜索引擎。
描述:
随着业务越来越复杂,对数据存储和检索的需求也越来越复杂,系统需要采用一些非关系型数据库如NoSQL和分数据库查询技术如搜索引擎。应用服务器通过统一数据访问模块访问各种数据,减轻应用程序管理诸多数据源的麻烦。
例子:
每次客户来找东西的时候,其实前台小姐姐都要找一下东西在哪,然后才能分配,但是这个过程也是很浪费时间的啊,所以呢,对于一些比较复杂的,就用传统的方式,对于一些关系不强的文件和数据,就用nosql,这样,效率又得到了很大的提高。
系统架构演化历程-业务拆分
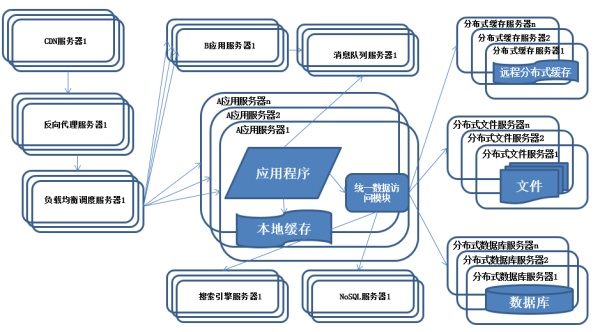
特征:
系统上按照业务进行拆分改造,应用服务器按照业务区分进行分别部署。
描述:
为了应对日益复杂的业务场景,通常使用分而治之的手段将整个系统业务分成不同的产品线,应用之间通过超链接建立关系,也可以通过消息队列进行数据分发,当然更多的还是通过访问同一个数据存储系统来构成一个关联的完整系统。
纵向拆分:
将一个大应用拆分为多个小应用,如果新业务较为独立,那么就直接将其设计部署为一个独立的Web应用系统。 纵向拆分相对较为简单,通过梳理业务,将较少相关的业务剥离即可。
横向拆分:
将复用的业务拆分出来,独立部署为分布式服务,新增业务只需要调用这些分布式服务
横向拆分需要识别可复用的业务,设计服务接口,规范服务依赖关系。
系统架构演化历程-分布式服务
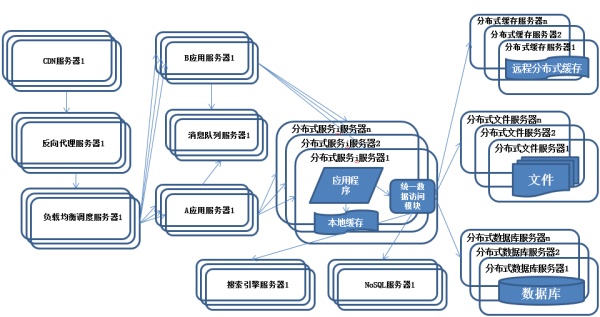
特征:
公共的应用模块被提取出来,部署在分布式服务器上供应用服务器调用。
描述:
随着业务越拆越小,应用系统整体复杂程度呈指数级上升,由于所有应用要和所有数据库系统连接,最终导致数据库连接资源不足,拒绝服务。
A:
(1) 当服务越来越多时,服务URL配置管理变得非常困难,F5硬件负载均衡器的单点压力也越来越大。
(2) 当进一步发展,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。
(3) 接着,服务的调用量越来越大,服务的容量问题就暴露出来,这个服务需要多少机器支撑?什么时候该加机器?
(4) 服务多了,沟通成本也开始上升,调某个服务失败该找谁?服务的参数都有什么约定?
(5) 一个服务有多个业务消费者,如何确保服务质量?
(6) 随着服务的不停升级,总有些意想不到的事发生,比如cache写错了导致内存溢出,故障不可避免,每次核心服务一挂,影响一大片,人心慌慌,如何控制故障的影响面?服务是否可以功能降级?或者资源劣化?
Java分布式应用技术基础

分布式服务下的关键技术:消息队列架构
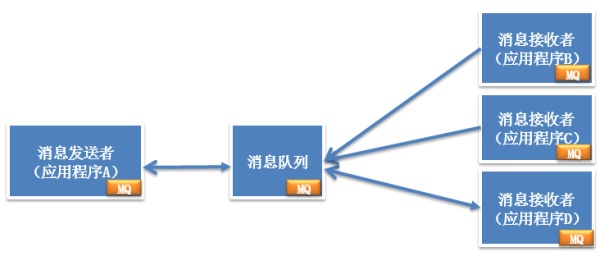
消息对列通过消息对象分解系统耦合性,不同子系统处理同一个消息
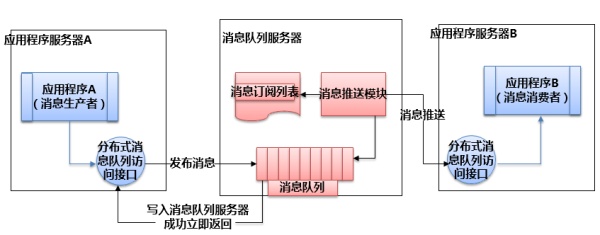
分布式服务下的关键技术:消息队列原理

分布式服务下的关键技术:服务框架架构
Q:Dubbo到底是神马?
A:淘宝开源的高性能和透明化的RPC远程调用服务框架
SOA服务治理方案
Q:Dubbo原理是?
A: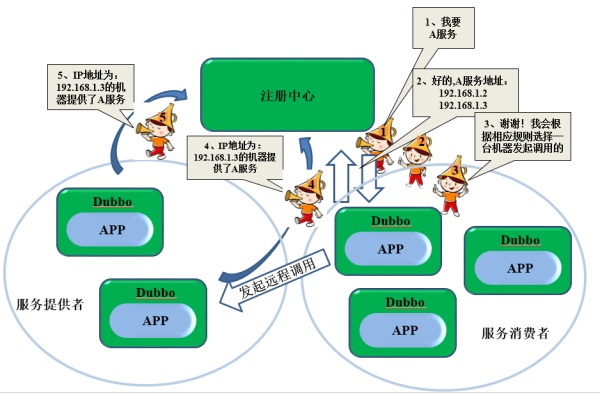

 浙公网安备 33010602011771号
浙公网安备 33010602011771号