
算法
1、 从上到下按层打印二叉树,同一层结点从左至右输出。每一层输出一行。(层序遍历)
整体思想:从上到下,从左到右打印出这个二叉树。 需要使用一个队列作为过渡,两次while循环即可解决问题。值得注意的时,arr中的元素是node.val,而queue中的元素是node节点。
/* function TreeNode(x) { this.val = x; this.left = null; this.right = null; } */ function Print(pRoot) { // 层序遍历思想: 需要一个二维数组,最后输出这个二维数组。 需要一个队列,进入队列(push)和弹出队列(shift) // 二维数组,用于输出。 var res = []; if (!pRoot) { return res; } // 一个用于中间过渡的队列。 var queue = []; // 二叉树中的每一个节点都需要经过这个队列,先把根元素放进去。 queue.push(pRoot); // 一旦队列为空,说明所有元素都被打印,那么结束。 while (queue.length != 0) { // 这里每循环一次,代表进入了新的一层,并开始打印。 // 建立一个指向最开始的指针。 var p = 0; // 建立一个一维数组用于输出本层所有元素。 var arr = []; // 获取这一层元素的个数 var len = queue.length; // 循环打印出结果,并且push进入这一层的子元素,以便于下一次循环输出。 // 注意这里的len是固定的,而不是动态变化的,只要打印出这一层即可 。 while (p++ < len) { var node = queue.shift(); arr.push(node.val); if (node.left) { queue.push(node.left); } if (node.right) { queue.push(node.right); } } // 将这一层的一维数组push到res中。 res.push(arr); } return res; } module.exports = { Print : Print };
2 请实现两个函数,分别用来序列化和反序列化二叉树
主要思想: 用什么方式序列化,就用什么方式来反序列化,这里使用的时先序遍历。
function TreeNode(x) { this.val = x; this.left = null; this.right = null; } var arr = []; function Serialize(pRoot) { // write code here // 如果节点不存在,直接返回。 if (!pRoot) { arr.push('$'); return; } // 这里采用线序遍历的方式进行序列化 arr.push(pRoot.val); Serialize(pRoot.left); Serialize(pRoot.right); } function Deserialize(s) { // write code here // 首先建立一个节点。 var node = null; if (arr.length < 1) { return node; } var number = arr.shift(); if (typeof number == 'number') { node = new TreeNode(number) node.left = Deserialize(arr); node.right = Deserialize(arr); } return node; } module.exports = { Serialize : Serialize, Deserialize : Deserialize };
3、重建二叉树
function TreeNode(x) { this.val = x; this.left = null; this.right = null; } function reConstructBinaryTree(pre, vin) { // write code here // 所有的编程题的第一步就是处理输入错误的情况。 if (pre.length == 0 || vin.length == 0) { return null; } var binaryTree = new TreeNode(pre[0]); var pre_left = [], pre_right = [], vin_left = [], vin_right = []; var index = vin.indexOf(pre[0]); pre_left = pre.slice(1, index + 1); pre_right = pre.slice(index + 1); vin_left = vin.slice(0, index); vin_right = vin.slice(index + 1); binaryTree.left = reConstructBinaryTree(pre_left, vin_left); binaryTree.right = reConstructBinaryTree(pre_right, vin_right); return binaryTree; }
4、反转链表
/*function ListNode(x){ this.val = x; this.next = null; }*/ function ReverseList(pHead) { // 第一步,就是判断输入是否有问题,所有的编程题都是如此 if (pHead == null) { return null; } // 用于使得链表反转 var pre; // 记住后面的链表,防止断开 var next; // 如果pHead不是null就循环继续 while (pHead != null) { // 让next记住后面的,防止断开 next = pHead.next; // 使得链表改变方向。 pHead.next = pre; // 使得pre指向pHead pre = pHead; // pHead指向next,这样就可以一步一步地反转链表了 pHead = next; } return pre; } module.exports = { ReverseList : ReverseList };javascript:void(0);
5、请给Array本地对象增加一个原型方法,它用于删除数组条目中重复的条目(可能有多个),返回值是一个包含被删除的重复条目的新数组。
数组都是可以使用forEach来实现的,这里也用到了incluedes方法,就非常方便了。 并且关键是数组的 splice 方法,第二个参数表明删除的个数,返回一个删除的元素的数组。
Array.prototype.deleteArr = function () {
// 返回的最终被删除元素的数组
var deleted = [];
res = [],
that = this;
this.forEach(function (item, index) {
// 如果res没有包含这一项,就push到res中; 否则,就push到deleted中。
if (!res.includes(item)) {
res.push(item);
} else {
// 删除这一项。
deleted.push(that.splice(index, 1)[0]);
}
});
return deleted;
}
var a = [3,3,5,4,7,8,7,1];
console.log(a.deleteArr()) // [3, 7]
console.log(a); // [3, 5, 4, 7, 8, 1]
6、题目如下:
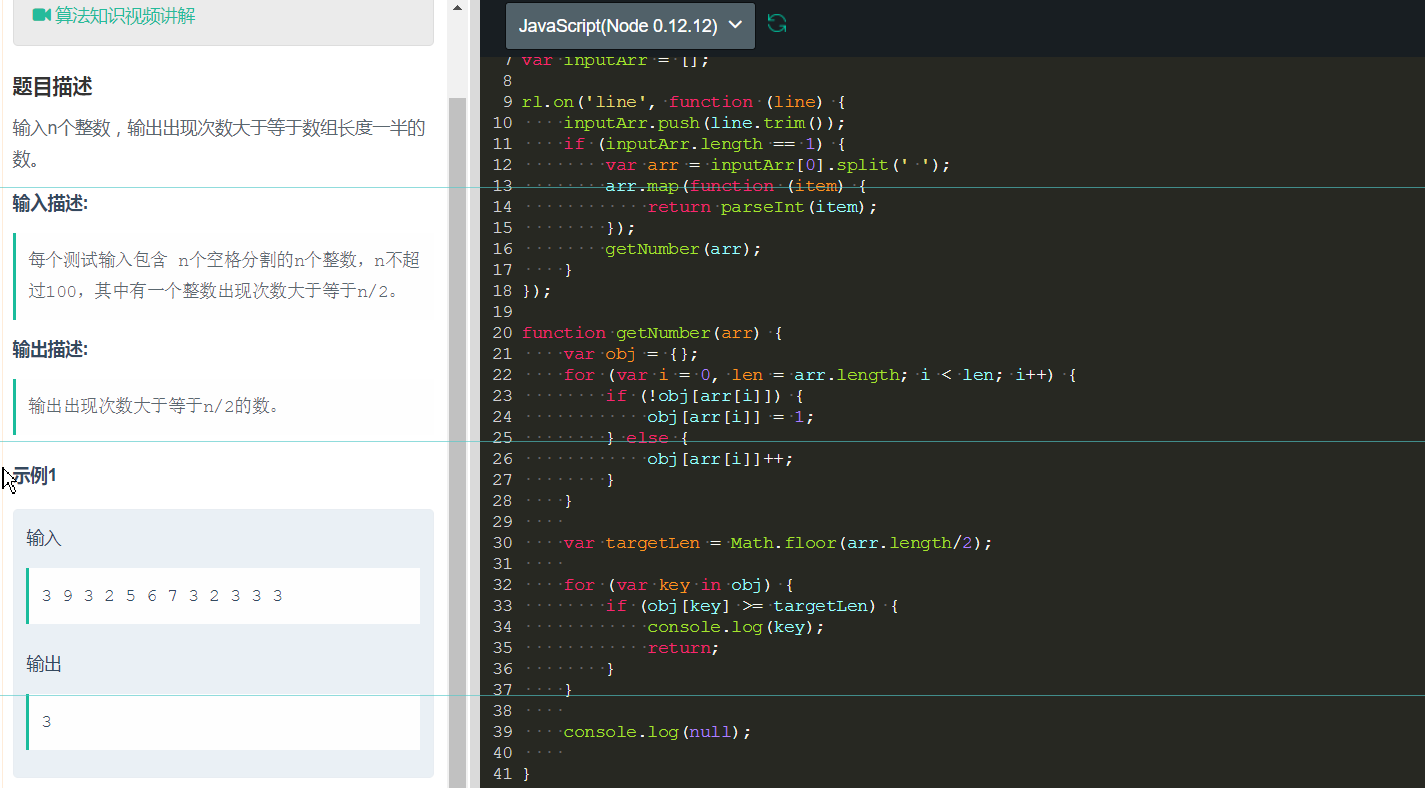
这里,我们首先通过map来将字符串处理为了一般的数字,然后,又通过调用一个函数,来返回值。 这个函数中,主要用到的特性就是对象属性的唯一性。
var readline = require('readline'); var rl = readline.createInterface({ input: process.stdin, output: process.stdout }); var inputArr = []; rl.on('line', function (line) { inputArr.push(line.trim()); if (inputArr.length == 1) { var arr = inputArr[0].split(' '); arr.map(function (item) { return parseInt(item); }); getNumber(arr); } }); function getNumber(arr) { var obj = {}; for (var i = 0, len = arr.length; i < len; i++) { if (!obj[arr[i]]) { obj[arr[i]] = 1; } else { obj[arr[i]]++; } } var targetLen = Math.floor(arr.length/2); for (var key in obj) { if (obj[key] >= targetLen) { console.log(key); return; } } console.log(null); }
7、题目如下所示:
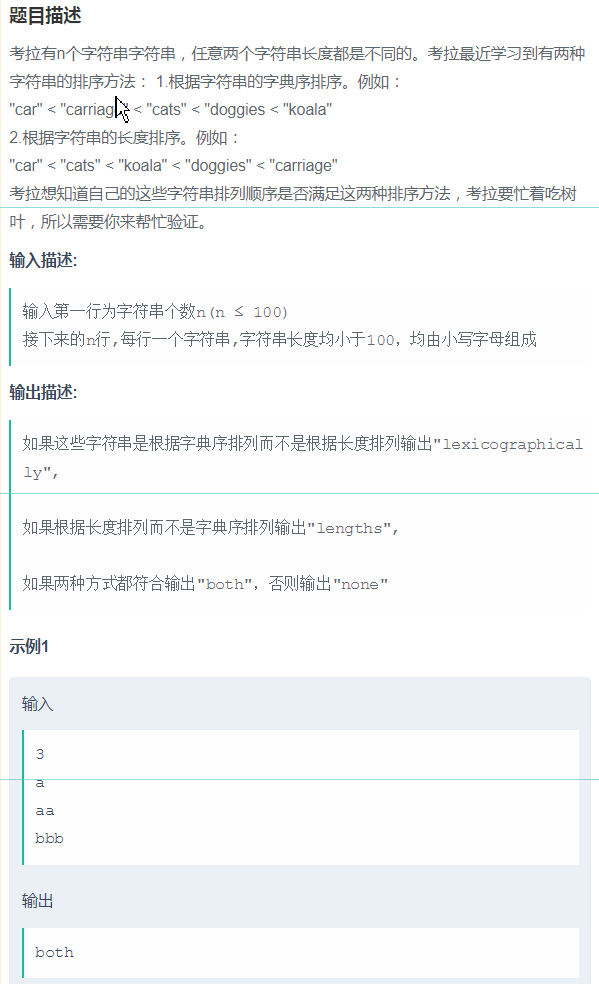
解决方法如下所示:
var readline = require('readline'); var rl = readline.createInterface({ input: process.stdin, output: process.stdout }); var inputArr = []; rl.on('line', function (line) { inputArr.push(line); var len = parseInt(inputArr[0]); if (inputArr.length == len + 1) { var arr = inputArr.slice(1); // doSomething... tellSortType(arr); } }); function tellSortType(arr) { // 通过冒泡排序,我们就可以对字符串数组进行字典排序! 重大发现! // 通过深克隆获取到两个新的数组,这样在改变他们的时候不会影响原数组 var arr1 = JSON.parse(JSON.stringify(arr)); var arr2 = JSON.parse(JSON.stringify(arr)); // 对arr1进行字典排序。 for (var i = 0; i < arr1.length; i++) { for (var j = 0; j < arr1.length - i - 1; j++) { if (arr1[j] > arr1[j + 1]) { var temp = arr1[j]; arr1[j] = arr1[j + 1]; arr1[j + 1] = temp; } } } // 对arr2进行长度排序。 for (var i = 0; i < arr2.length; i++) { for (var j = 0; j < arr2.length - i - 1; j++) { if (arr2[j].length > arr2[j + 1].length) { var temp = arr2[j]; arr2[j] = arr2[j + 1]; arr2[j + 1] = temp; } } } // 判断两个数组的内容是否相同。 function isSame(arrA, arrB) { for (var i = 0; i < arrA.length; i++) { if (arrA[i] != arrB[i]) { return false; } } return true; } var dicBool = false; var lenBool = false; dicBool = isSame(arr, arr1); lenBool = isSame(arr, arr2); if (dicBool == true && lenBool == true) { console.log('both'); } else if (dicBool == false && lenBool == false) { console.log('none'); } else if (dicBool == true && lenBool == false) { console.log('lexicographically'); } else if (dicBool == false && lenBool == true) { console.log('lengths'); } }
这里有几个关键点:
- 如何正确的处理多行输入(inputArr[0])。
- 如何对字符串数组做到字典排序(冒泡排序 --- 还是稳定的,不错)。
- 如何可以不影响原数组(这里进行浅拷贝或者是深拷贝都是可以的)。
- 对于按照长度排序字符串数组,如何做到? (同样是冒泡排序,只要在比较的时候,添加一个length属性即可)。
8、动态规划
题目如下所示:

这就是一道典型的动态规划问题,但是,动态规划问题求解的前身都是使用暴力求解的方法,即穷举并且不记忆每次计算的结果(已经计算过一遍之后,如果后面还需要计算,就再计算一遍,第一次计算的结果没有保留下来,所以说这种方法是暴力的), 而动态规划是前人在暴力求解的基础上通过优化、找规律而得到的一种算法。 下面我们分别介绍:
暴力求解:
暴力求解就是穷举, 即对于本题而言,就是循环套循环,第一步先使用最大的100元的,然后剩下的再使用50的,依次类推,并且这种方式会遍历所有的情况,所以是暴力算法。如下
var readline = require('readline'); var rl = readline.createInterface({ input: process.stdin, output: process.stdout }); rl.on('line', function (line) { var N = parseInt(line); // 记录可能的数量。 var count = 0; // 这道题是典型的动态规划类的问题,但是呢,要知道动态规划类的问题都是从暴力求解(无记忆)的方式演变而来的,所以,使用暴力求解的方法。 // 从100开始,即先用100的 for (var a = 0; a <= Math.floor(N/100); a++ ) { var N1 = N - 100 * a; // 接着使用50的。 for (var b = 0; b <= Math.floor(N1/50); b++) { var N2 = N1 - b * 50; // 接着使用20的。 for (var c = 0; c <= Math.floor(N2/20); c++) { var N3 = N2 - c * 20; // 接着使用10元的。 for (var d = 0; d <= Math.floor(N3/10); d++) { var N4 = N3 - d * 10; // 接着使用5元的 for (var e = 0; e <= Math.floor(N4/5); e++) { var N5 = N4 - e * 5; // 最后,剩下的都用1元的来补充,并且只有这一种方法,所以方法数量加1. count++; } } } } } console.log(count) });
这里的思路还是很清楚的,应该记牢。
下面使用的是动态规划的方法:
var readline = require('readline'); var rl = readline.createInterface({ input: process.stdin, output: process.stdout }); rl.on('line', function (line) { var N = parseInt(line); var money = [1, 5, 10, 20, 50, 100]; var result = []; result[0] = 1; // 注意dp的矩阵永远都是一个矩形,即x方向是x是钱的种类的方向,即【1,5,10,20,50,100】,而y方向是输入的面额的值。 // 下面这种方式的求解实际上就是竖着的遍历,即在 面额为1 时总数的遍历,然后把一直到N都遍历完了之后,再开始面额为包含 1 和 5 (或者说面额最大为5时的遍历)。 接着,会开始遍历 money 最大值为 10 的所有种可能性。 for (var i = 0; i < money.length; i++) { // 这里使用j的初始值为money[i],那么就可以保证下面的状态转移方程是一定可以用的了。 for (var j = money[i]; j <= N; j++) { if (i == 0) { // 当i为0时,显然,这些面额只能由1块钱来组成,所以result[j]的值永远都是1。 result[j] = 1; } else { // 当i不为0时,那么使用的纸币的类型就多了。 // 共有两种可能 // 一种是不用这个新的类型(money[i]),那么result[j]就是上次求解出来的result[j]; // 还有一种可能就是,我使用这个新的类型(money[i]),那么使用了之后,我就有result[j - money[i]]的面额需要凑出来。 // 一共就上面两种可能,所以,我们最终就可以得到下面的这样的一个状态转移方程了。 result[j] = result[j] + result[j - money[i]]; } } } console.log(result[N]); });
感悟: 代码要写出来,才能有收获。
9、动态规划(类似于上一题)
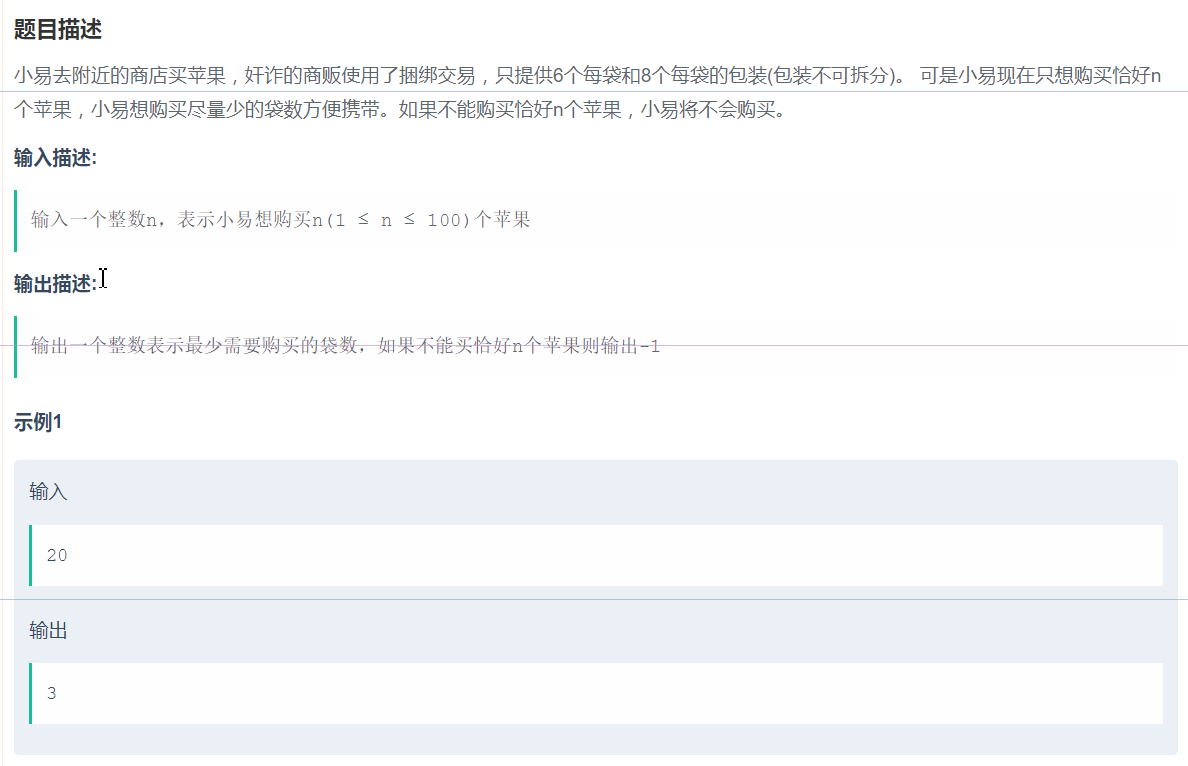
对于上面的问题,我们的方法就是暴力的枚举所有的可能,即8个每袋的0个时需要多少6个每袋的、8个每袋的1个时需要多少6个每袋的、8个每袋的2个时需要多少6个每袋的。。。 这就是暴力解法:
var readline = require('readline'); var rl = readline.createInterface({ input: process.stdin, output: process.stdout }); rl.on('line', function (line) { var number = parseInt(line); getBags(number); }); // @params [number] 一共需要买的苹果数 // @return 需要返回一个数字,即需要的袋子个数; 如果不符合条件,返回-1; function getBags(number) { // 需要的袋子的数量。 var res = []; var N = number; for (var i = 0; i <= Math.floor(N/8); i++) { var N1 = N - i * 8; for (var j = 0; j <= Math.floor(N1/6); j++) { if (N1 - j * 6 == 0) { res.push(i + j); } } } if (res.length == 0) { console.log(-1); return; } else { res.sort(function (a, b) { return a - b; }); console.log(res[0]); } }
通过这种方式,把所有的可能性枚举出来之后Push到一个数组里,然后输出数组中的最小值即可。
但是对于这种暴力解法的情况,我们都可以使用动态规划的方法来解决,关键是状态转移方程的寻找:
var readline = require('readline'); var rl = readline.createInterface({ input: process.stdin, output: process.stdout }); rl.on('line', function (line) { var number = parseInt(line); getBags(number); }); // @params [number] 一共需要买的苹果数 // @return 需要返回一个数字,即需要的袋子个数; 如果不符合条件,返回-1; function getBags(number) { // 需要的袋子的数量。 var n = number; // 即对于n个苹果所需要的最少的袋数 var bags = [];
// 一般都需要一个初始化。 bags[0] = 0; function min(a, b) { if (typeof a === 'undefined') { return b; } if (typeof b === 'undefined') { return a; } return a > b ? b : a; } // 使用动态规划来解决这个问题。 for (var i = 0; i <= n; i++) { if (typeof bags[i] == 'undefined') { bags[i] = -1; } else { bags[i + 6] = min(bags[i + 6], bags[i] + 1); bags[i + 8] = min(bags[i + 8], bags[i] + 1); } } console.log(bags[n]); }
这又是动态规划的题目,可以看到什么规律呢? 就是我们需要设置最终的需要的为d[], 即这里是对于n个苹果,我们知道需要多少个袋子,这里我们就设置d[i]为i个苹果需要d[i]个袋子。
这道题目有几个关键点:
- 这里要单独封装一个min函数,如果直接使用Math.min是会出错的。
- 动态规划的题目就是d[i]就是我们最终要的结果。 找出合适的状态转移方程是最重要的。
- 这里多个函数的封装是很好的,使得代码比较清晰。
10、 找规律。
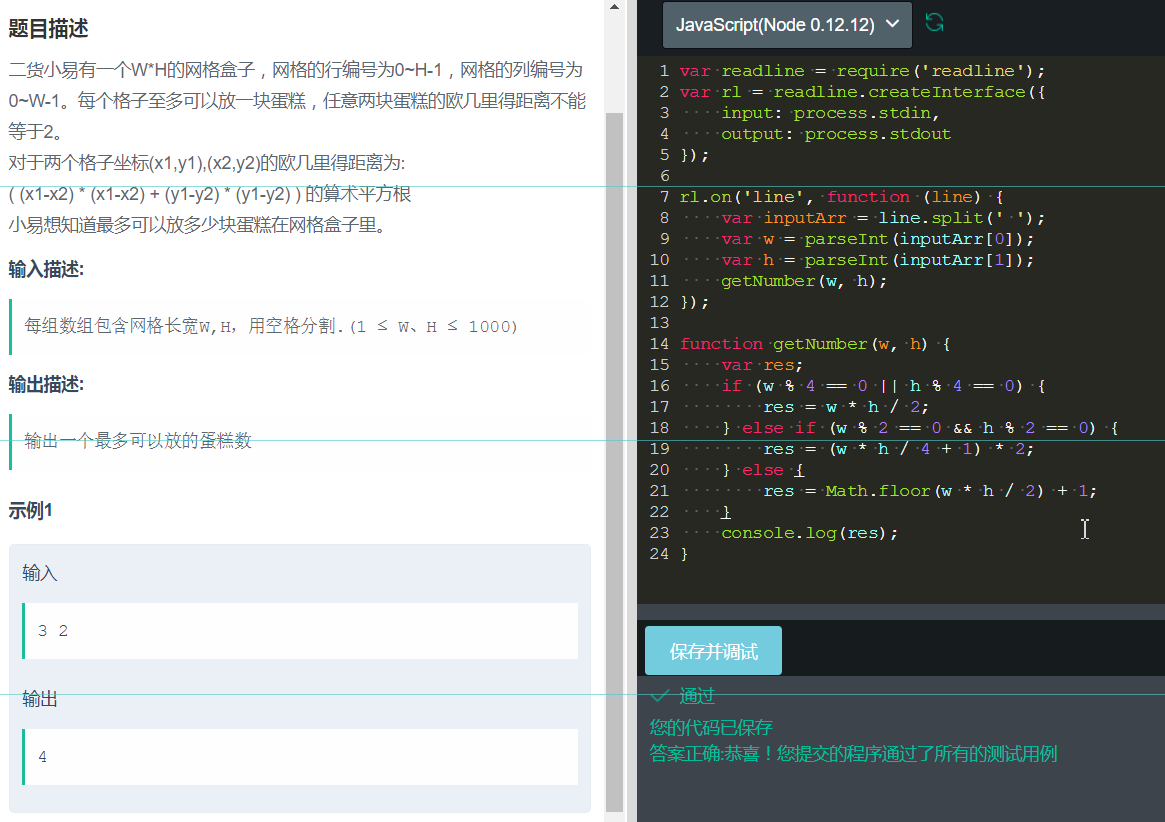
这里,实际上就没有什么高深莫测的用法了,而是通过题目的描述,找出蛋糕可能会存在于哪些格子上,然后,通过找规律,完成计算,只要规律照的好,就没有什么问题了。
11、 经典的寻找最大长度的题。
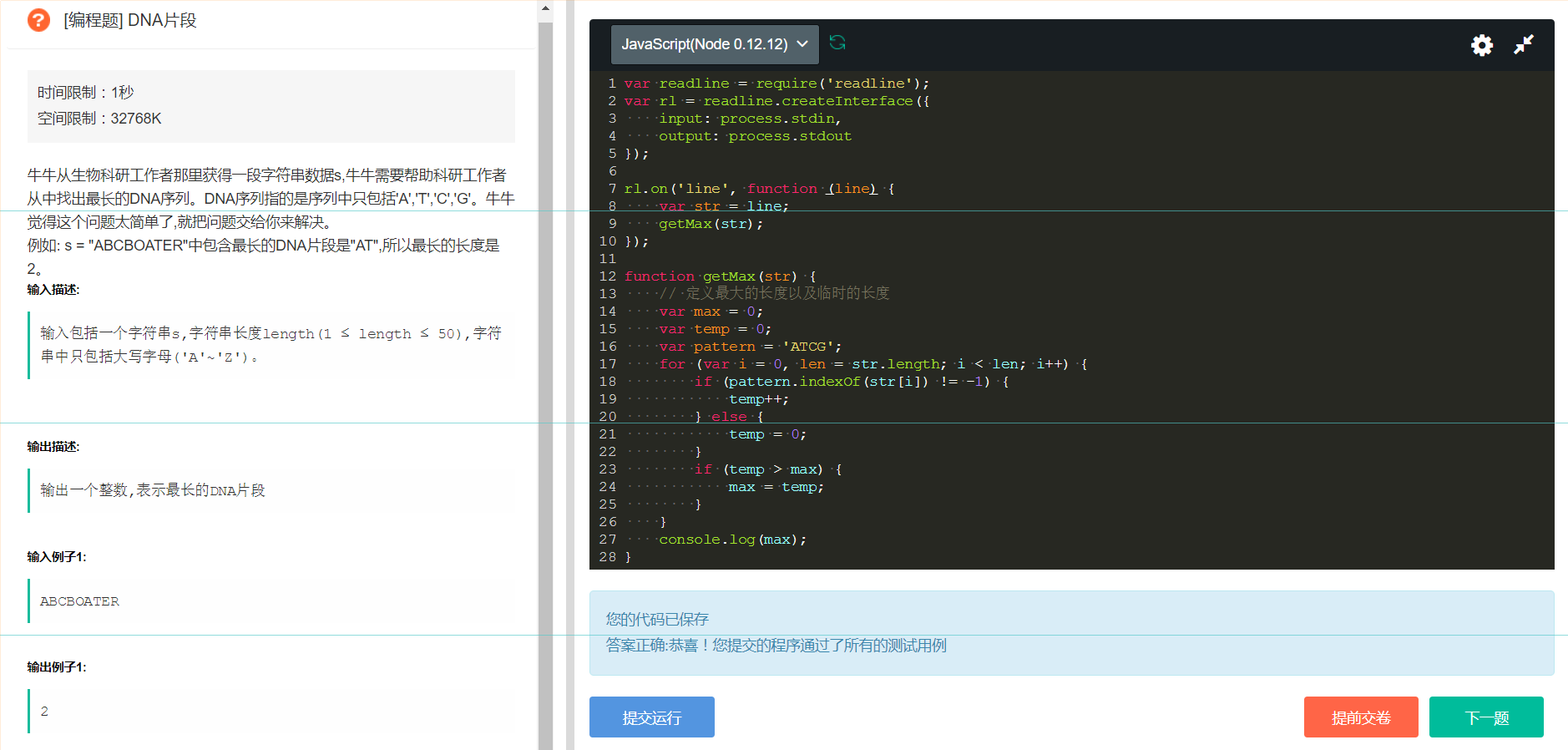
这种题非常经典,做法也是套路,就是定义一个temp,一个max,然后开始遍历,如果符合,就加1,否则,就置0. 然后再和max比较,求出最大值即可。
12、 偶串
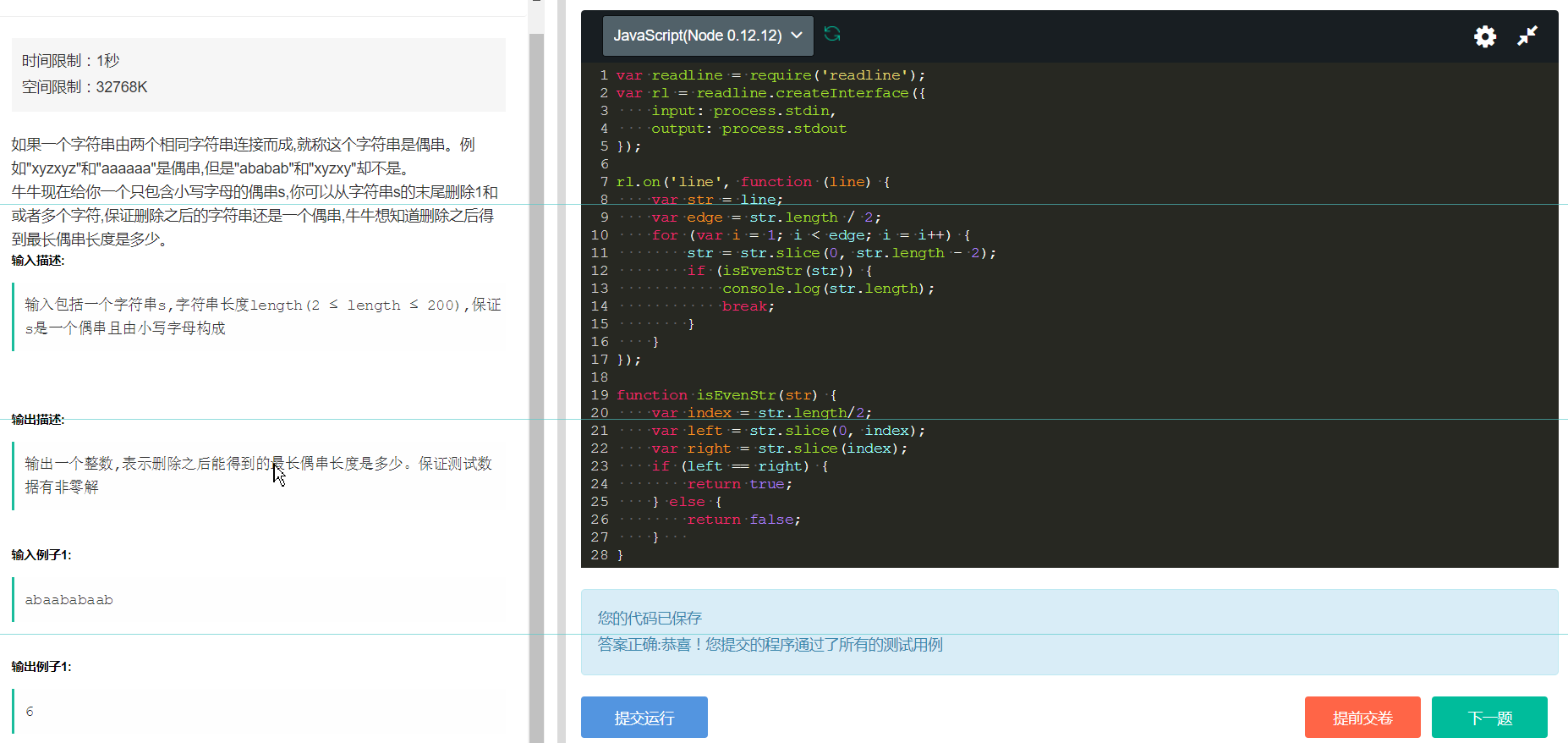
这个例子也是比较简单的,主要是要学会把一些处理的步骤封装成函数,然后合理地利用字符串的一些方法即可完成了。
13、下面这个题还是非常有意思的。
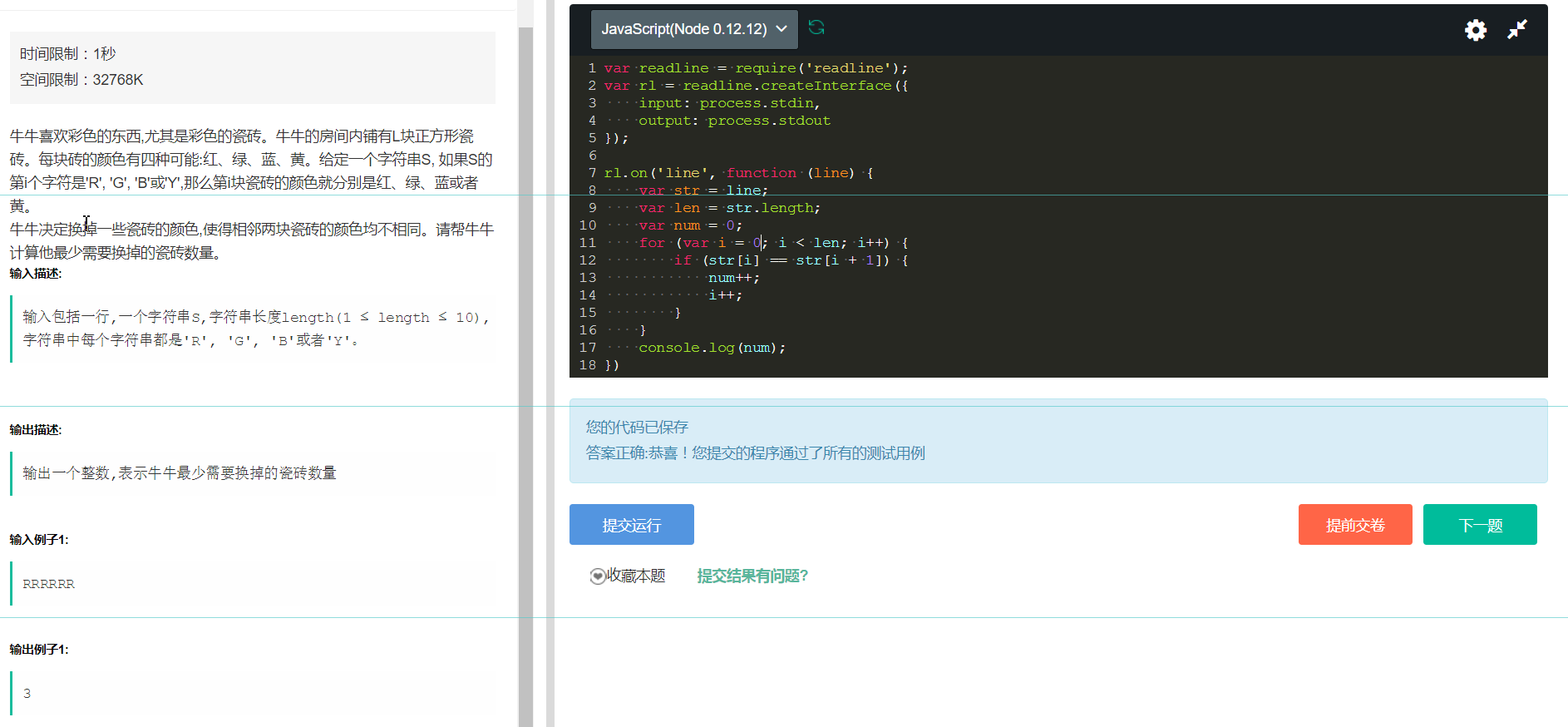
注意: 这道题看似不知道该怎么去替换,但是只要思考一下,其实还是很容易。
即比较当前和下一个数,如果重复,则替换,将下一个替换为当前的和下一个的下一个都不一样的数(一共有4个,显然是可以做到的,只是我们不关心细节,我们只关心替换的次数), 然后让i++,即跳过下一个数的比较,直接去比较下下一个即可(这里就是假设已经替换了下一个数为和当前数、下一个的下一个数都不一样的数)。
这个思路很赞。
14、使用好sort()函数也是很好的。
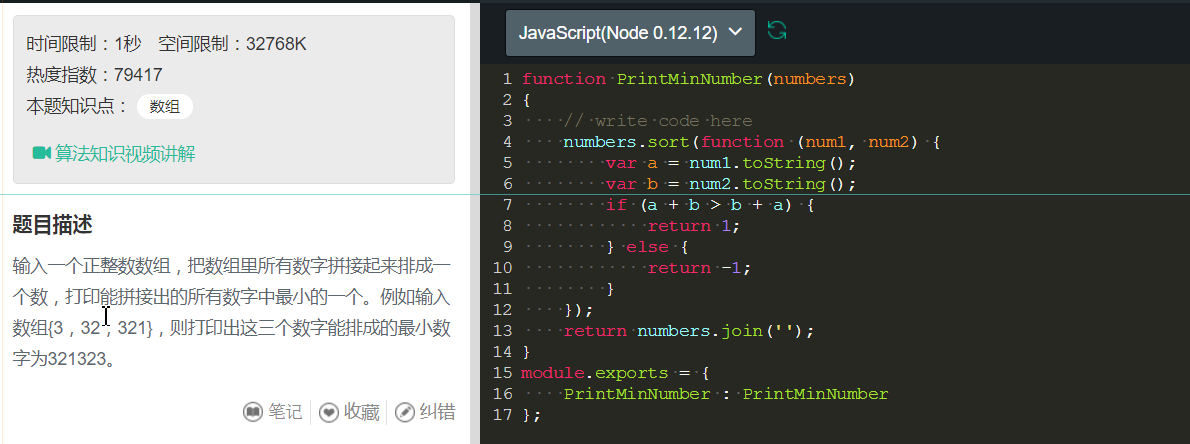
从这个sort函数可以看出: 对于字符串的处理,我们也能通过sort很好地解决。注意: 这里我们使用的规则时 a + b > b + a, 即比较和颠倒顺序之后的最大值,并且返回1,即从小打到排列即可。
15、 和为S的连续正数序列。
题目如下所示:
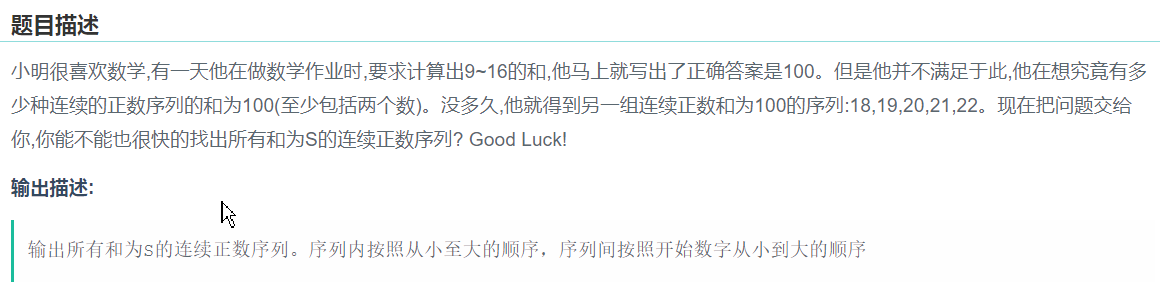
答案如下;
function FindContinuousSequence(sum) { // write code here // 最终输出res这个二维数组,数组内的每一个元素都是一个连续的和为100的序列。 var res = []; if (sum <= 2) { return res; } // 从1开始遍历,一直到50,这里的i就是每个序列的第一个元素。 但是50是不可能的,我们这里只是随意给了一个边界,不会造成死循环即可。 for (var i = 1; i <= Math.ceil(sum/2); i++) { var j = i + 1; var su = 0; var flag = false; while (su <= sum && flag == false) { su = (j - i + 1)*(i + j)/2; if (su == sum) { if (j - i >= 1) { res.push([i, j]); flag = true; } } else { j++; } } } for (var i = 0; i < res.length; i++) { var someArr = []; for (var j = res[i][0]; j <= res[i][res[i].length - 1]; j++) { someArr.push(j); } res[i] = someArr; } return res; } module.exports = { FindContinuousSequence : FindContinuousSequence };
这里的思路还是不难的,关键是 --- 每次进入的时候,都要判断是否输入是否满足条件,如果不满足,应作出相应的处理, 否则就会因为这些边界问题而出错。
另外,这里就需要我们在计算连续的和的时候通过等差数列的求和公式,这样可以极大地提高效率。
最后,对于这样的多个序列的输出,题目的意思就是要输出一个二维数组,这样才可以很好地匹配。 且本题中,我使用了flag,这也是一个很好地习惯。、
16、餐馆
题目链接:https://www.nowcoder.com/practice/d2cced737eb54a3aa550f53bb3cc19d0?tpId=85&tqId=29859&tPage=2&rp=2&ru=%2Fta%2F2017test&qru=%2Fta%2F2017test%2Fquestion-ranking
题目如下所示:
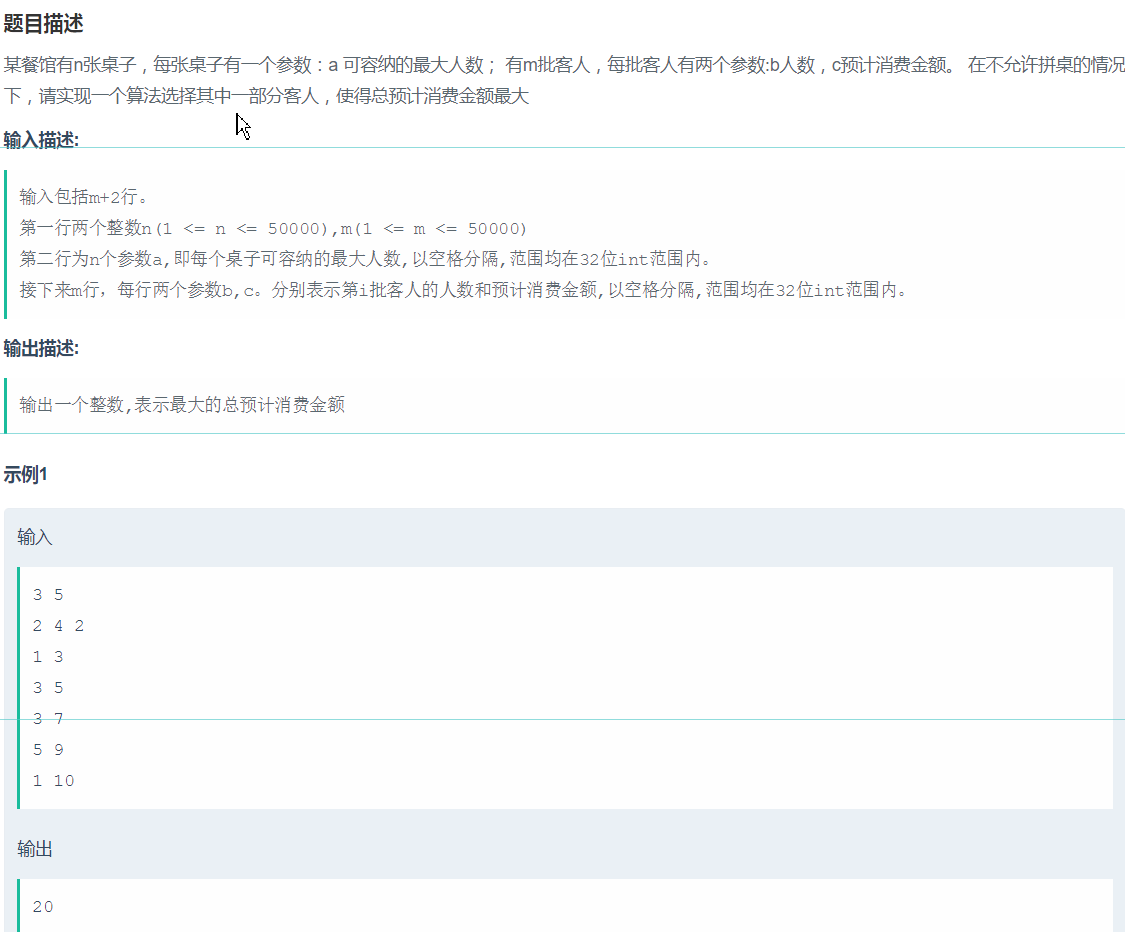
最终解决方案如下:
这里,这里可能比较费劲的就是处理输入和输出问题, 并且对于输入的字符串,我们还必须使用循环解决最终的转化为数字格式的问题。
var readline = require('readline'); var rl = readline.createInterface({ input: process.stdin, output: process.stdout }); var inputArr = []; rl.on('line', function (line) { inputArr.push(line); var len = parseInt(inputArr[0].split(' ')[1]); if (inputArr.length == len + 2) { // n --- 桌子总数 // m --- 客人批数 var n = parseInt(inputArr[0].split(' ')[0]), m = parseInt(inputArr[0].split(' ')[1]); // maxPerson数组 --- 对应地每个桌子上的最多人数 var maxPerson = inputArr[1].split(' '); maxPerson.map(function (item) { return parseInt(item); }); // 将每个桌子上的人数按照从小到大排序,这样,就可以从人最少的来安排了。 防止出现错误。 maxPerson.sort(function (a, b) { return a - b; }); // 记录所有的客人的人数以及预计消费的金额, costom是一个二维数组,数组中的每一个元素都是一个数组,保存着每一批客人人数和金额 var costom = []; for (var i = 0; i < m; i++) { costom[i] = inputArr[2 + i].split(' ').map(function (item) {return parseInt(item)}); } var total = 0; for (var j = 0, perLen = maxPerson.length; j < perLen; j++) { var temp = []; for (var k = 0; k < costom.length; k++) { if (costom[k][0] <= maxPerson[j]) { temp.push([k, costom[k][1]]); if (temp.length == 2) { if (temp[0][1] > temp[1][1]) { temp.pop(); } else { temp.shift(); } } } } if (temp.length == 1) { total += temp[0][1]; costom.splice(temp[0][0], 1); } } console.log(total); } });
整体思路还是不难的,就是将所有的桌子的固定的人数从小到大进行排列,然后遍历所有批的客人,找出在当前的桌子要求人数以下的客人的最大金额,然后total添加这个金额。这里需要注意的是: 在找桌子的过程中,我们可以放在一个数组里,一旦这个数组长度为2,我们就开始比较大小,然后丢弃掉其中一个,使用pop()方法或者是shift()方法,然后在total添加的时候,把这桌客人使用splice方法删除掉,这样,后面就不需要再进行遍历了。
但问题是,这么多个循环,没有办法避免啊。 最后的结果就是复杂度过高,然后无法通过。。。
11、使用两个栈实现一个队列。
思路: 我们知道,栈是先入后出的,而队列是先入先出的,那么我们如果使用栈来实现队列呢? 题目说的很清楚,使用两个栈就可以实现一个队列了。解法如下所示:
var stack1 = []; var stack2 = []; function push(node) { stack1.push(node); } function pop() { // 如果栈1和栈2都为空,那么就直接返回false if (stack1.length == 0 && stack2.length == 0) { return false; } else if (stack2.length == 0) { while (stack1.length != 0) { stack2.push(stack1.pop()); } } return stack2.pop(); }
即每次push的时候,我们直接push到stack1中,如果希望pop,如果直接从stack1中pop,显然就会是错的,无法实现队列,所以,我们可以判断stack2是否是空的,刚开始肯定是空的,所以我们的做法是将stack1中的所有都pop出来,并且规则是pop出来一个stack1的元素,就把这个元素push到stack2中,这样就可以实现一个队列了
12. 斐波那契数列的几种实现方式。
我们知道斐波那契数列为[0, 1, 1, 2, 3, 5 .....], 规律就是当前项的值为前两项的值的和,所以,我们很容易就可以实现递归式写法的斐波那契数列。 但是呢? 如果我们在牛客上跑,发现会超时,所以出现了下面这种非递归方式的斐波那契数列。
function Fibonacci(n) { // write code here var fib = []; fib[0] = 0; fib[1] = 1; for (var i = 2; i <= n; i++ ) { fib[i] = fib[i - 1] + fib[i - 2]; } return fib[n]; } module.exports = { Fibonacci : Fibonacci };
这样就不会超时了。
对于这种非递归的方法,我们的套路都是一样的,就是首先建立一个数组,初始化我们已知的前面几个index的值,然后在通过迭代的方式,就可以很好地完成任务了。
13、 青蛙跳
这个题和之前的斐波那契数列几乎是一模一样的。 因为之前我是按照递归的方式来写的,写出来就可以发现和斐波那契非常类似。 同样,我们就可以使用套路的方式了,当number为0时,最终的输出就是0(即没有办法); 当number为1时,就只有一种方法; 当number为2时,可以有两种方法,所以对于 res[i] = res[i - 1] + res[i - 2]这个递归式,对于前面几个不适用之外,对于其他的都是适用的。
都是套路!
14、变态台阶跳
这个答案为什么这么简洁呢?这是可以推导出来的,如下:

所以啊,只要我们有点耐心,就可以解决这个问题了,关键是: 要有善于观察、发现的眼!哈哈哈哈
15、 填充
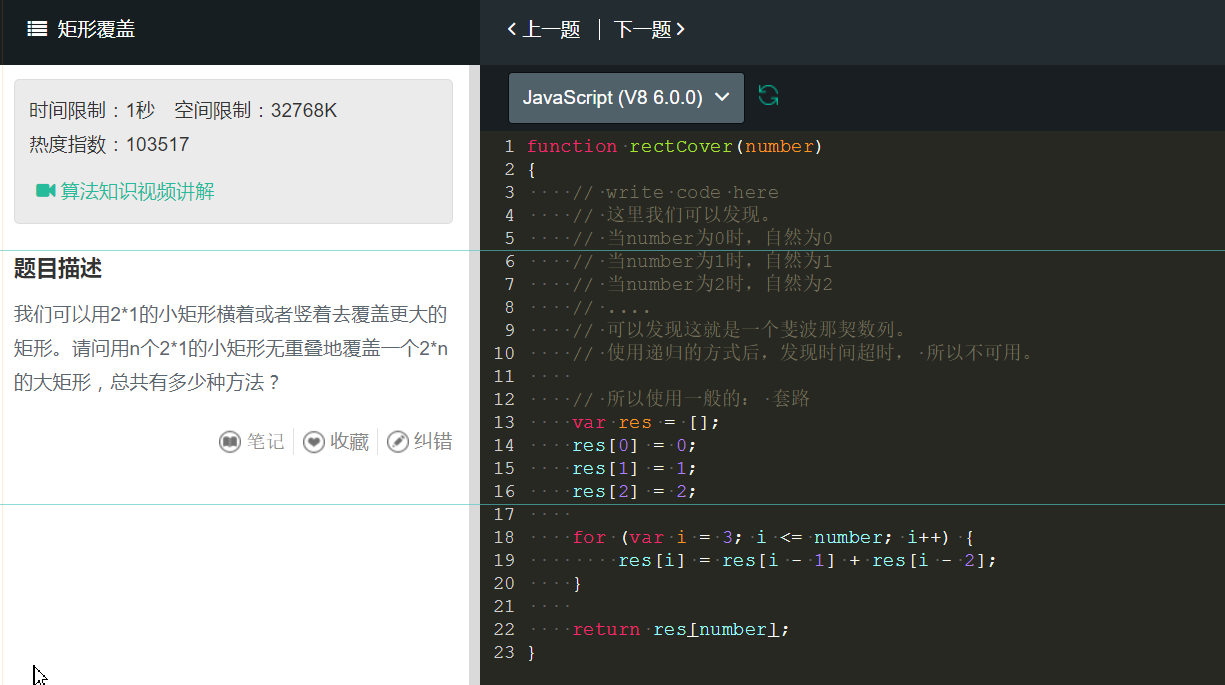
这种题如果是在没有思路的话,我们就列出前面的几项,看看能不能找到规律,如果可以找到,那么就太好了。
通过找规律,发现这和斐波那契数列是非常类似的,但是用递归的方式不行,所以使用非递归的方式,正常通过。
关键点:
- 没思路,找规律。
- 使用递归耗时,则使用一般的非递归的方式。
16、使用二进制位。
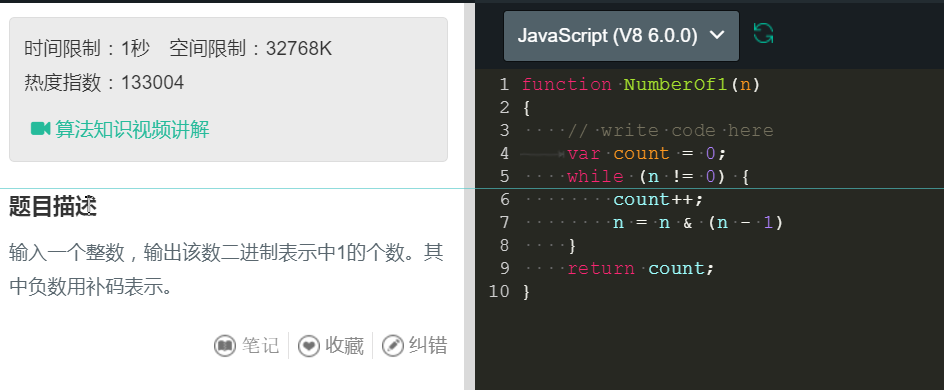
这道题的解题思路是非常巧妙的,可以看到,我们输入这个n,然后呢,初始化一个count,然后如果n不为0,我们就count++,然后使用与运算,通过与运算,就可以让其中的1减少一个,分析如下:

这样,我们就可以很轻松地解决这个问题了。 当我们使用 & 这种二进制的运算符的时候,就会自动转化为二进制数来计算,并且,对于负数而言,也会自动使用补码,所以,这就可以很好地解决问题了。
17、给定一个double类型的浮点数base和int类型的整数exponent。求base的exponent次方。
答案: 对于这道题,显然,我们可以通过简单的Math.pow()来实现,但是呢,这种方法实现为什么还需要算法呢? 所以,我们写出了下面的算法 。
function Power(base, exponent) { // write code here // 这里使用的是JavaScript中的库函数,当然,我们也可以不使用库函数,而是使用其他的方法。 // return Math.pow(base, exponent) if (exponent == 0) { return 1; } if (exponent > 0) { if (exponent == 1) { return base; } var total = base; for (var i = 2; i <= exponent; i++) { total = total * base; } return total; } if (exponent < 0) { if (exponent == -1) { return 1/base; } var total = base; for (var i = exponent + 1; i < 0; i++) { total = total * base; } return 1/total; } }
这里的思路呢,非常简单,就是:
- 先判断 exponent 是否为0, 如果为0,那么我们直接就返回1。
- 接着判断exponent的值是否大于0,因为大于0和小于0的处理方式是不一样的。 如果大于0,我们就根据exponent,循环乘相应的次数,最后返回。
- 如果exponent的值小于0, 我们还是可以循环,只是边界条件发生了变化, 最后,要返回 1 / total,除此之外,就没有区别了。
18、输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分,所有的偶数位于位于数组的后半部分,并保证奇数和奇数,偶数和偶数之间的相对位置不变。
如下:
function reOrderArray(array) { // write code here var left = [], right = [], res = []; for (var i = 0, len = array.length; i < len; i++) { if (array[i] % 2 == 1) { left.push(array[i]); } else { right.push(array[i]); } } res = left.concat(right); return res; }
这里的思路还是很简单的,颇有快速排序的感觉,就是对于奇数,push到left数组中; 对于偶数,push到right数组中; 最后拼接left和right数组即可。
19、输入一个链表,输出该链表的倒数第k个节点。
function ListNode(x){ this.val = x; this.next = null; } function FindKthToTail(head, k) { // write code here if (!head) { return null; } // 建立一个数组,用于存放所有的节点,因为我们在遍历节点的过程中,不可能记住他们的index,所以唯一的方法是在遍历的过程中,存储起来,最后就可以取出任意的节点了。 var temp = []; while (head != null) { temp.push(head); head = head.next; } return temp[temp.length - k]; }
这里的思路也很简单,因为,我们在遍历的过程中,无法知道还有多少个没有遍历完,所以,我们可以建立一个数组,然后遍历节点的时候,把每个节点都push到数组中,这样,最后我们就可以知道这个链表的长度已经倒数第k个节点是多少了。 这样的做法时间复杂度为O(n), 空间复杂度为 O(n),因为我们额外建立了一个数组。 最后在return temp[temp.length - k];的时候,我们只需要带入特值就可以了,比如k为1,那么就是输出链表的倒数第1个节点,所以最终就是 temp[temp.length - 1],如果不带入特值,或者代入的这个特值不是1而是2或者是3等,就会增加出错的概率,所以特值的选取也是很重要的。
20、 输入一个链表,反转链表后,输出这个链表。
代码如下:
/*function ListNode(x){ this.val = x; this.next = null; }*/ function ReverseList(pHead) { // write code here // 如果这个链表为空,则直接返回空。 if (!pHead) { return null; } // 定义pre的作用是为了反转。 // 定义next的作用是为了防止链表因断裂而丢失。 var pre, next; while (pHead) { // 记住,防止丢失 next = pHead.next; // 开始反向。 pHead.next = pre; // 开始向右移动 pre = pHead; // pHead也向右移动 pHead = next; } // 关键: 最后却是是输出pre。 // 比如,我们的链表是 1 -> 2 -> 3 -> 4 -> 5,开始pHead指向的时值为1的节点。 最后,我们再反转链表,结束的时候,pre指向了最后一个,即值为5的节点。 // 而pHead指向的是null。 所以,最后就成了 5 -> 4 -> 3 -> 2 -> 1。 所以return 5就会得到反转之后的节点了。 return pre; }
理解还是不难的,只要知道 pre、 next各自的作用就可以了。
21、 输入两个非递增的链表,合并成一个非递减的链表。
/*function ListNode(x){ this.val = x; this.next = null; }*/ // 这个用递归的方式来做要简单的多 function Merge(pHead1, pHead2) { // write code here if (pHead1 == null && pHead2 == null) { return null; } else if (pHead1 == null || pHead2 == null) { return pHead1 || pHead2; } // 建立一个节点,即最后要返回的合成的链表 // 初始化为一个对象,因为最后要指向某个节点,所以不需要new一个新的出来。 var head = null; if (pHead1.val > pHead2.val) { head = pHead2; head.next = Merge(pHead1, pHead2.next); } else { head = pHead1; head.next = Merge(pHead1.next, pHead2); } return head; }
这里有几个关键点:
- 合并单链表可以使用递归的方式, 会大大地简化运算过程。
- 在创建新的链表的时候,直接 var head = null; 然后后面再将这个head指向某个节点,这样,就构建出一个新的链表了。
22、一个树中是否包含另一个树,即一个树是否是另一个树的子树。
输入两棵二叉树A,B,判断B是不是A的子结构。(ps:我们约定空树不是任意一个树的子结构)
最终正确的如下
/* function TreeNode(x) { this.val = x; this.left = null; this.right = null; } */ function HasSubtree(pRoot1, pRoot2) { // write code here // 首先设置flag var flag = false; // 只有两者都不是null的情况下才继续执行,否则一定是不包含的 if (pRoot1 != null && pRoot2 != null ) { // 如果根节点相等,我们就可以使用hava来精确的判断根节点相等的两棵树是否包含了。 if (pRoot1.val == pRoot2.val) { // 这里必须要返回值,因为后面要用啊。 flag = have(pRoot1, pRoot2); } // 如果上面的不成立。即两种不成立的情况,一种是根节点值相等,但是更深的不等; 另一种是根节点就直接不等了。 if (!flag) { // 然后我们再使用pRoot1.left继续判断,这个游客是包含的啊,因为最终都是需要利用到have方法的。 即无论是深层次包含,还是浅的,都得用到have方法。 flag = HasSubtree(pRoot1.left, pRoot2); } if (!flag) { // 右边。 flag = HasSubtree(pRoot1.right, pRoot2); } } return flag; } // 即根节点的值相等的两个树判断是否具有包含关系。 function have(node1, node2) { // 如果为null,我们也认为这是包含(因为之前判断过一次了,不是完全为null),所以返回true。 if (node2 == null) { return true; } // 如果node2不是null,而node1都成了null了,显然不包含,返回false if (node1 == null) { return false; } // (递归时使用)如果不等,显然false,这是递归可能用到的。 if (node1.val != node2.val) { return false; } // 最后再递归的判断。 return have(node1.left, node2.left) && have(node1.right, node2.right); }
这是我认为的一种比较好理解的方式。
我们也可以看到这种套路,就是判断一个节点是否为空,需要通过 if (node == null) 的这种方式。
这里用到了两个函数,其中一个是用来判断一个树是否包含另一个树(根节点不一定一样);另一个是在根节点的值相同的情况下,来判断一个树是否是另一个树的子树。 整体还是使用了递归的方式。
23、 获得一个二叉树的镜像。
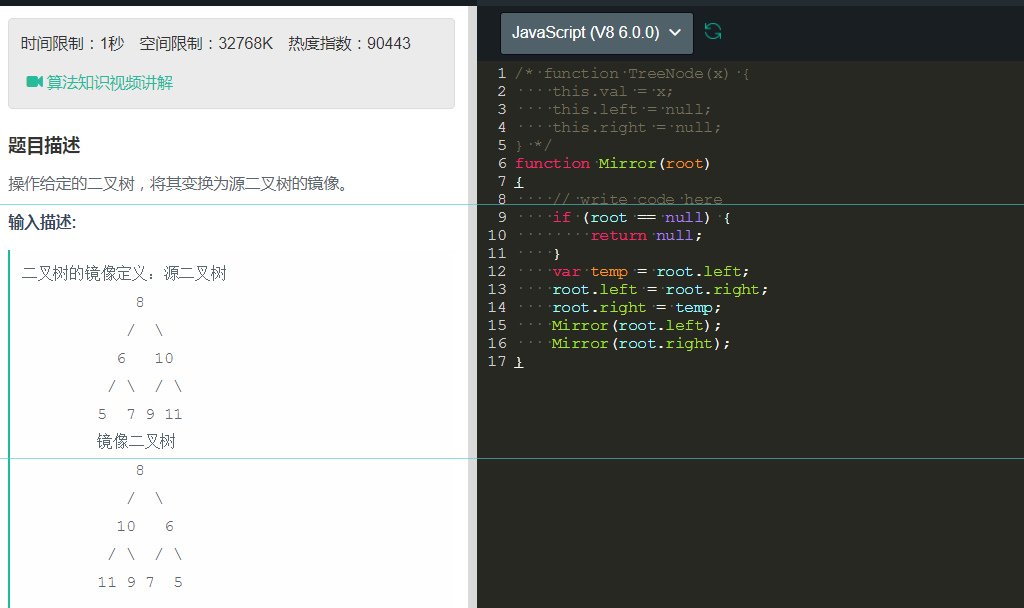
如上所示,思想非常简单,就是通过简单的将node的左右子树进行交换,交换之后,我们再使用递归的方式即可,只要最后有一个出口就行。
24 定义栈的数据结构,请在该类型中实现一个能够得到栈最小元素的min函数。
var stack = []; function push(node) { // write code here stack.push(node); } function pop() { // write code here stack.pop(); } function top() { // write code here return stack[stack.length - 1]; } function min() { // write code here var min = stack[0]; for (var i = 1; i < stack.length; i++) { if (stack[i] < min) { min = stack[i]; } } return min; }
如上,很简单地就可以实现了,并不需要更多的想法。
25、 输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈序列对应的一个弹出序列,但4,3,5,1,2就不可能是该压栈序列的弹出序列。(注意:这两个序列的长度是相等的)。
function IsPopOrder(pushV, popV) { // write code here // 关键:辅助栈 // 整体思路;就是遍历pushV,对于其中的某个元素都push到辅助栈里面,push进去之后,在判断栈顶元素是否和弹出序列的相等,如果相等,就弹出,并且把弹出序列的index后移。 // 如果最后,最后辅助栈不空,说明顺序不对; 如果为空,说明对。 // 注意:我们需要知道的是:辅助栈的入栈出站实际上就是在模仿弹出序列,所以,这样的高度一致,才能进行下一步的判断。 var stack = []; var popIndex = 0; for (var i = 0; i < pushV.length; i++) { stack.push(pushV[i]); while (stack.length != 0 && stack[stack.length - 1] == popV[popIndex]) { stack.pop(); popIndex++; } } if (stack.length == 0) { return true; } else { return false; } }
判断一个弹出序列是否是一个输入序列的弹出序列,关键是利用一个辅助栈,使用这个辅助栈来模仿压入栈的过程,如果最后辅助栈的Length为0,说明弹出站是的,否则,不是。
这里的思路还是非常好的。
26、 从上往下打印出二叉树的每个节点,同层节点从左至右打印。(实际上就是二叉树的层序遍历)
/* function TreeNode(x) { this.val = x; this.left = null; this.right = null; } */ function PrintFromTopToBottom(root) { // write code here // 这里实际上就是层序遍历了,或者是宽度优先遍历的方式。 // 层序遍历的关键是借助一个队列,最开始,我们把节点push到队列里,然后每次我们shift的时候,再把他的左右两个节点push进入队列中。 var queue = []; var data = []; if (root != null) { queue.push(root); } else { return data; } while (queue.length != 0) { var node = queue.shift(); if (node.left != null) { queue.push(node.left); } if (node.right != null) { queue.push(node.right); } data.push(node.val); } return data; }
整体的思路也是非常简单的,就是使用一个辅助队列,然后每次从这个队列中拿出一个值来,接着,我们再把这个节点的左右子节点push到队列中就可以了。就可以获取到一个层序遍历的二叉树的值了。
27、搜索二叉树的后续遍历是否是正确的。
function VerifySquenceOfBST(sequence) { // write code here、 // 二叉搜索树又称为二叉排序树,这种树有下面的四个特点: // 1、如果根节点它有左子树,那么左子树上所有节点的值都是小于根节点的值的。 // 2、如果根节点他有右子树,那么右子树上所有节点的值都是大于根节点的值的。 // 3、搜索二叉树的所有的子树也都是搜索二叉树。 // 4、对于任意的节点,他们的值一定是不相等的。 // 显然,对于这个二叉搜索树的最终结果,一定是 左子树 -> 右子树 -> 根节点。所以,最终的排列是小 - 大 - 中。 // 并且对于左子树和右子树而言,也是同样的道理,我们直接使用递归的方式来定义就可以了。 // 整体思路: 就是拿到这个二叉搜索树的数组之后,分成左右两个部分,左边的部分通过小于来获取到,右边的部分检测是否都小于根节点,如果满足,则递归左右两边的。 // 最开始对特殊情况进行判断。 // 如果没有输入,则返回false if (sequence.length == 0) { return false; } return verify(sequence); } function verify(sequence) { if (sequence.length <= 3 ) { return true; } var root = sequence[sequence.length - 1]; var left = [], right = []; for (var i = 0; i < sequence.length; i++) { if (sequence[i] < root) { left.push(sequence[i]); } else { right = sequence.slice(i, sequence.length - 1); // 关键: 这里一定要break,否则,right可能就会接着被连续的改变,而不是我们想要的了。 break; } } if (right.length == 0) { return true; } for (var j = 0; j < right.length; j++) { if (right[j] < root) { return false; } } return verify(left) && verify(right); }
如上所示,判断还是挺简单的,利用搜索二叉树后序遍历的特点: 左边的小于root、右边的大于root,我们就可以利用递归的形式来判断了。一般,这种套路是: 由于直接没法判断,所以,我们要另外写一个专门用于递归的函数。
28. 输入一颗二叉树和一个整数,打印出二叉树中结点值的和为输入整数的所有路径。路径定义为从树的根结点开始往下一直到叶结点所经过的结点形成一条路径。
/* function TreeNode(x) { this.val = x; this.left = null; this.right = null; } */ var paths, temp; function FindPath(root, expectNumber) { // write code here paths = []; temp = []; if (!root) { return []; } cal(root, expectNumber); return paths; } function cal(root, expectNumber) { temp.push(root.val); if (root.val == expectNumber && root.left == null && root.right == null) { paths.push(temp.slice()); } else { if (root.left != null) { cal(root.left, expectNumber - root.val); } if (root.right != null) { cal(root.right, expectNumber - root.val); } } temp.pop(); }
如上所示,我们的目标也很简单,就是通过吧值push到数组中,然后判断节点值和我们期待的值是否相等,然后,我们再递归的进行计算即可。 这道题需要多做几遍啊。
29、输入一个复杂链表(每个节点中有节点值,以及两个指针,一个指向下一个节点,另一个特殊指针指向任意一个节点),返回结果为复制后复杂链表的head。(注意,输出结果中请不要返回参数中的节点引用,否则判题程序会直接返回空)
对于树、链表这些很多都是可以使用递归的方式完成的,既然要复制,那么我们就不能使用引用的方式,而是每次都需要new出来一个节点,指向 pHead ,然后两者同时next就可以了。 如下所示:
function RandomListNode(x){ this.label = x; this.next = null; this.random = null; } function Clone(pHead) { // write code here if (!pHead) { return null; } // 注意:之前也遇到过拿一个普通的变量指向这个链表的,但是那是引用,而这里需要创建 // 一个新的链表,所以需要new出来一个。 var CloneHead = new RandomListNode(pHead.label); // 下面一句是不需要的,因为我在上面构造函数new的时候就已经传入了label了。 // CloneHead.label = pHead.label; CloneHead.random = pHead.random; CloneHead.next = Clone(pHead.next); return CloneHead; }
这里的代码是非常简单的, 就是利用递归的方式,并且有一个出口。 先创建一个节点, 然后因为初始化的时候,已经传入了pHead.label,所以,下面只要把 random 的指向弄清楚就可以了。
总之,对于链表和树,多想想如何使用递归的方式来完成。
30、 HZ偶尔会拿些专业问题来忽悠那些非计算机专业的同学。今天测试组开完会后,他又发话了:在古老的一维模式识别中,常常需要计算连续子向量的最大和,当向量全为正数的时候,问题很好解决。但是,如果向量中包含负数,是否应该包含某个负数,并期望旁边的正数会弥补它呢?例如:{6,-3,-2,7,-15,1,2,2},连续子向量的最大和为8(从第0个开始,到第3个为止)。你会不会被他忽悠住?(子向量的长度至少是1)。
这道题其实还是不难理解的,如下所示:
function FindGreatestSumOfSubArray(array) { // write code here // 动态规划类似的题。 // 每次开始时都要首先考虑特殊情况。 if (array.length == 0) { return 0; } var max = array[0], temp = array[0]; for (var i = 1; i < array.length; i++) { temp = temp > 0 ? temp + array[i] : array[i]; max = max > temp ? max : temp; } return max; }
这里的思路还是挺巧妙的,就是max和temp是必须要先设立的两个值。 然后每次再相加时,先判断 temp 的值是否大于0,如果大于0,那么temp = temp + array[i], 这样,我们加上array[i]才是有意义的。否则,就是没有意义的。
而每次,我们还是需要和max进行比较的,如果temp > max,我们就更改这个max。
31、求出1~13的整数中1出现的次数,并算出100~1300的整数中1出现的次数?为此他特别数了一下1~13中包含1的数字有1、10、11、12、13因此共出现6次,但是对于后面问题他就没辙了。ACMer希望你们帮帮他,并把问题更加普遍化,可以很快的求出任意非负整数区间中1出现的次数。答案如下:
function NumberOf1Between1AndN_Solution(n) { // write code here if (n < 1) { return 0; } // 对于第一个1一定是有的。 var count = 1; // 之前已经有1了,所以,我们从2开始计算。 for (var i = 2; i <= n; i++) { count = count + (i.toString().split('1').length - 1); } return count; }
这里有一个比较关键的地方就是: i.toString().split('1').length - 1, 通过这个js代码就可以很容易的计算中字符串中含有某个字符的数量。
32、 输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。例如输入数组{3,32,321},则打印出这三个数字能排成的最小数字为321323。
对于这种排序题,一般我们都是可以通过JavaScript中的sort函数来解决的,如下所示:
function PrintMinNumber(numbers) { // write code here // 先处理异常。 if (numbers.length == 0) { return ''; } numbers.sort(function (a, b) { var a = a.toString(); var b = b.toString(); return a + b > b + a; }); return numbers.join(''); }
即在排序的时候,我们比较的是正序和逆序之间的关系,通过转化为字符串,就会按照字典顺序来排序了。
33、在一个字符串(1<=字符串长度<=10000,全部由字母组成)中找到第一个只出现一次的字符,并返回它的位置。
对于这种在一个字符串中出现的字符的个数,我们就可以使用下面这种套路:
function FirstNotRepeatingChar(str) { // write code here if (str == '') { return -1; } for (var i = 0; i < str.length; i++) { if (str.split(str[i]).length - 1 == 1) { return i; } } } module.exports = { FirstNotRepeatingChar : FirstNotRepeatingChar };
即使用str.split(字符).length - 1得到某个字符的个人。
34、输入两个链表,找出它们的第一个公共结点。
关键是理解题意,两个链表的公共节点是说第一个链表中从某个节点一直到最后是和第二个链表中的某个节点到最后是一模一样的,
但是这两个完整的链表并不能保证是一样长的。
/*function ListNode(x){ this.val = x; this.next = null; }*/ function FindFirstCommonNode(pHead1, pHead2) { // write code here // 这道题的思路还是不难的。 但是首先要理解题意: 即存在公共节点,那么在第一个链表中这个节点之后的链表和第二个链表中这个节点之后的链表是一样的,这样,才能称为公共节点。 // 异常处理 if (pHead1 == null || pHead2 == null) { return null; } // 因为链表不容易处理,所以,我们放在数组中来处理。 var arr1 = [], arr2 = []; // 建立两个指针,分别指向pHead1和pHead2 var p1 = pHead1, p2 = pHead2; // 将两个链表的值都push到两个数组中。 while (p1) { // 注意: 这里push进入的一定要是val值,因为我们在后面是在遍历比较值,而不是节点。 arr1.push(p1.val); p1 = p1.next; } while (p2) { arr2.push(p2.val); p2 = p2.next; } // 循环遍历以确定公共节点在链表1中的index // 首先初始化index var index = -1; // 循环遍历。 for (var i = 0; i < arr1.length; i++) { var str1 = arr1.slice(i).join('-'); var str2 = arr2.join('-'); // 注意: 这里如果我们找到了之后,要立马break,否则, // 这个节点就是最后的节点,而不是第一个了,可以想象,最后输出的是空的。 if (str2.indexOf(str1) > -1) { index = i; break; } } if (i == -1) { return null; } var p = pHead1; while (i > 0) { p = p.next; i--; } return p; } module.exports = { FindFirstCommonNode : FindFirstCommonNode };
35、统计一个数字在排序数组中出现的次数。
function GetNumberOfK(data, k) { // write code here // [3,5,6,72,31] 5的index是1 var index = data.indexOf(k); if (index == -1) { return 0; } // 即如果index不是-1,那么count就已经是1了。 var count = 1; for (var i = index; i < data.length; i++) { if (data[i + 1] == data[i]) { count++; } else { return count; } } } module.exports = { GetNumberOfK : GetNumberOfK };
这里的关键是排序数组,所以,我们可以首先确定下来index,然后再从这个index开始去判断, 这样可以最大可能地减少运算。
36、输入一个递增排序的数组和一个数字S,在数组中查找两个数,是的他们的和正好是S,如果有多对数字的和等于S,输出两个数的乘积最小的。
function FindNumbersWithSum(array, sum) { // write code here // 整体的思路应该是: 先设置好第一个数,然后在后面去寻找 sum - 当前数 的那个值,找到就push到数组中。 if (array.length <= 1) { return []; } var res = []; for (var i = 0; i < array.length; i++) { var remain = sum - array[i]; for (var j = i + 1; j < array.length; j++) { if (array[j] == remain) { res.push([array[i], array[j]]); break; } } } if (res.length == 0) { return []; } var min = res[0][0] * res[0][1]; var index = 0; for (var k = 1; k < res.length; k++) { var temp = res[k][0] * res[k][1]; if (temp < min) { index = k; } } return [res[index][0], res[index][1]]; } module.exports = { FindNumbersWithSum : FindNumbersWithSum }; 这里有几个点: 1、有序,所以可以从左往右的遍历。 2、两个数,可以去寻找remain。 3、最小。 首先把第一个设置为最小的,然后遍历比较。 4、异常处理。每次执行函数的时候,都需要做异常处理。
37、LL今天心情特别好,因为他去买了一副扑克牌,发现里面居然有2个大王,2个小王(一副牌原本是54张^_^)...他随机从中抽出了5张牌,想测测自己的手气,看看能不能抽到顺子,如果抽到的话,他决定去买体育彩票,嘿嘿!!“红心A,黑桃3,小王,大王,方片5”,“Oh My God!”不是顺子.....LL不高兴了,他想了想,决定大\小 王可以看成任何数字,并且A看作1,J为11,Q为12,K为13。上面的5张牌就可以变成“1,2,3,4,5”(大小王分别看作2和4),“So Lucky!”。LL决定去买体育彩票啦。 现在,要求你使用这幅牌模拟上面的过程,然后告诉我们LL的运气如何。为了方便起见,你可以认为大小王是0。
function IsContinuous(numbers) { // write code here // 关键一定要思考实现的规律、特征。 // 思路如下: // 1: 这个数组的长度一定是5,否则,返回false // 2: 这个数组中除了0之外,其他的数是不能重复的。 // 3: 最终排序之后,除去0之外,他们的差值不能大于4(或者是小于5) // 实现方式: if (numbers.length != 5) { return false; } // 对数组进行排序(有小到大) numbers.sort(function (a, b) { return a - b; }); // 分为有0和没有0的两种情况。 if (numbers[0] == 0) { // 把不是0的元素push到数组arr中。 var arr = []; for (var i = 0; i < numbers.length; i++) { if (numbers[i] != 0) { arr.push(numbers[i]); } } // 如果最大值减去最小值大于4,则返回false if (arr[arr.length - 1] - arr[0] > 4) { return false; } // 判断这几个数中是否有重复的值,如果有,返回false for (var j = 1; j < arr.length; j++) { if (arr[j - 1] == arr[j]) { return false; } } // 如果上述条件都满足,则返回true return true; } else { for (var k = 1; k < numbers.length; k++) { if (numbers[k] - numbers[k - 1] != 1) { return false; } } return true; } } module.exports = { IsContinuous : IsContinuous }; 注意: 这里,我们需要注意的是把握规律,首先,只能是5个数,否则返回false。 其次,因为这里的0充当着重要的作用,所以可以在排序之后,分为有0和没有0的两种情况,然后再做决定。 最后,通过两种情况的判断即可完成。 关键点:max - min < 5 、 不重复。
38、 每年六一儿童节,牛客都会准备一些小礼物去看望孤儿院的小朋友,今年亦是如此。HF作为牛客的资深元老,自然也准备了一些小游戏。其中,有个游戏是这样的:首先,让小朋友们围成一个大圈。然后,他随机指定一个数m,让编号为0的小朋友开始报数。每次喊到m-1的那个小朋友要出列唱首歌,然后可以在礼品箱中任意的挑选礼物,并且不再回到圈中,从他的下一个小朋友开始,继续0...m-1报数....这样下去....直到剩下最后一个小朋友,可以不用表演,并且拿到牛客名贵的“名侦探柯南”典藏版(名额有限哦!!^_^)。请你试着想下,哪个小朋友会得到这份礼品呢?(注:小朋友的编号是从0到n-1)
这道题的思路也是很简单的,就是对于输入的数据,现在纸上画出来,然后去判断。
关键就是建立数组,然后合适的删除和index的重置,做到这些,就基本上没哟问题了。
function LastRemaining_Solution(n, m) { // write code here // 思路:将数组形成一个循环,用while来实现,每次到了 m - 1 的时候,我们就把去除其中的一个小朋友。最后输出这个小朋友。 if (n == 0 || m == 0) { return -1; } // 小朋友数组 var children = []; for (var i = 0; i < n; i++) { children.push(i); } // 数字数组 var numbers = []; for (var j = 0; j < m; j++) { numbers.push(j); } // 循环删除。 // k为numbers的下标。 var k = -1; // p为children的下标。 var p = -1; while (children.length > 1) { // 如果children已经到头了,那就从头再来 if (p == children.length - 1) { p = 0; } else { // 如果没有到头,就继续加。 p++; } // 这里的k一直加就可以了。 k++; // 这里是一个关键点。 if (k == m - 1) { // 删除其中一个小朋友。 children.splice(p, 1); // 让p回退一个。 p = p - 1; // 重置k,因为一会要从0开始了。 k = -1; } } // 返回最终剩下的这个元素。 return children[0]; } module.exports = { LastRemaining_Solution : LastRemaining_Solution };
39、写一个函数,求两个整数之和,要求在函数体内不得使用+、-、*、/四则运算符号。
function Add(num1, num2) { // write code here // 但是我们可以使用循环啊。 var count = 0; function jing(num) { if (num > 0) { add(num); } else if (num < 0){ sub(num); } } function add(num) { for (var i = 0; i < num; i++ ) { count++; } } function sub(num) { for (var j = num; j < 0; j++) { count--; } } jing(num1); jing(num2); return count; } module.exports = { Add : Add };
40、 具有12个关键字的有序表,折半查找的平均查找长度是多少:
将12个数画成完全二叉树, 第一层有1个,第二个有两个、第三层有三个、第四层有5个。
查找一次: 6
查找两次: 3、 9
查找三次:1、 4、 7、 11
查找四次: 2、 5、 8、 10、 12
如下所示(这里有一些问题,因为对于偶数个数字,我们采取的应该是向下取整):
41、
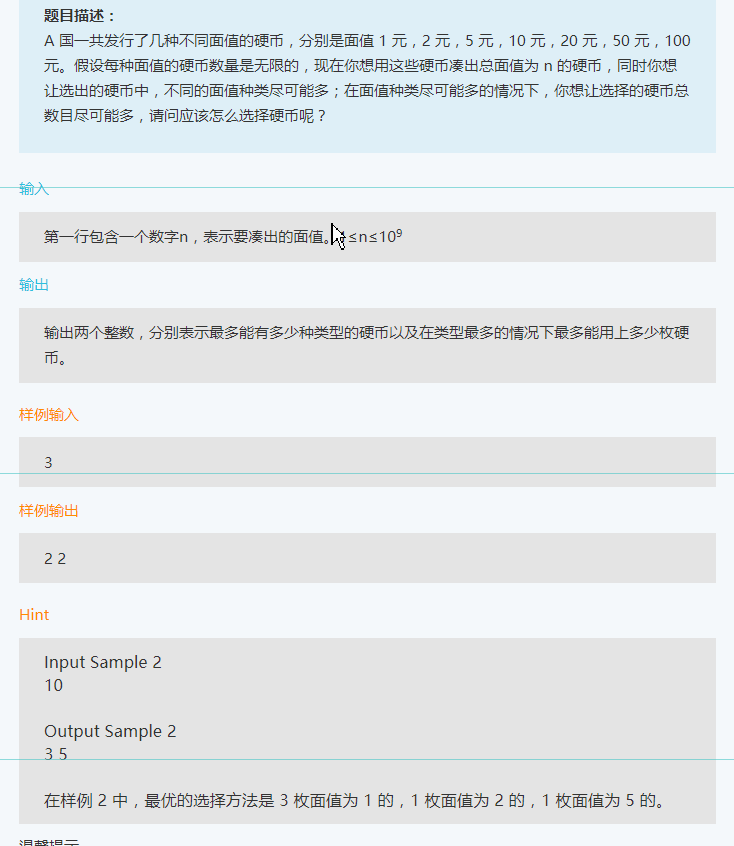
最终答案如下(本地测试用例都通过了,但是只ac了10%,是因为边界条件没有考虑到? 有什么边界条件也不能只是10%啊??)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>使用</title> </head> <body> <script> var N = 10; var res = []; // 这道题是典型的动态规划类的问题,但是呢,要知道动态规划类的问题都是从暴力求解(无记忆)的方式演变而来的,所以,使用暴力求解的方法。 // 从100开始,即先用100的 for (var a = 0; a <= Math.floor(N/100); a++ ) { var N1 = N - 100 * a; // 接着使用50的。 for (var b = 0; b <= Math.floor(N1/50); b++) { var N2 = N1 - b * 50; // 接着使用20的。 for (var c = 0; c <= Math.floor(N2/20); c++) { var N3 = N2 - c * 20; // 接着使用10元的。 for (var d = 0; d <= Math.floor(N3/10); d++) { var N4 = N3 - d * 10; // 接着使用5元的 for (var e = 0; e <= Math.floor(N4/5); e++) { var N5 = N4 - e * 5; for (var f = 0; f <= Math.floor(N5/2); f++) { var N6 = N5 - f * 2; var g = N6; res.push([a, b, c, d, e, f, g]); } // 最后,剩下的都用1元的来补充,并且只有这一种方法,所以方法数量加1. } } } } } var max = 0; for (var i = 0; i < res.length; i++) { var count = 0; for (var j = 0; j < res[i].length; j++) { if (res[i][j] != 0) { count++; } } res[i].count = count; if (count > max) { max = count; } } var real = []; for (var j = 0; j < res.length; j++) { if (res[j].count == max) { real.push(res[j]); } } var mm = 0; for (var k = 0; k < real.length; k++) { var good = real[k].reduce(function (a, b) { return a + b; }); if (good > mm) { mm = good; } } console.log( max + ' ' + mm ); </script> </body>
主要的思路还是使用暴力方法来求出所有的可能性,然后再根据题目的条件进行筛选,关键是赛码网的代码编译执行的优点太慢了。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号